Table of contents
1. Configure the virtual environment
2. Library version introduction
a. Two-dimensional cross-correlation operation (corr2d)
b. Two-dimensional convolution layer class (Conv2D)
1. Experiment introduction
This experiment implements the functions of setting step size, filling, input and output channels of the convolution layer of the two-dimensional convolutional neural network .
2. Experimental environment
This series of experiments uses the PyTorch deep learning framework. The relevant operations are as follows:
1. Configure the virtual environment
conda create -n DL python=3.7 conda activate DLpip install torch==1.8.1+cu102 torchvision==0.9.1+cu102 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
conda install matplotlib conda install scikit-learn2. Library version introduction
| software package | This experimental version | The latest version currently |
| matplotlib | 3.5.3 | 3.8.0 |
| numpy | 1.21.6 | 1.26.0 |
| python | 3.7.16 | |
| scikit-learn | 0.22.1 | 1.3.0 |
| torch | 1.8.1+cu102 | 2.0.1 |
| torchaudio | 0.8.1 | 2.0.2 |
| torchvision | 0.9.1+cu102 | 0.15.2 |
3. Experimental content
ChatGPT:
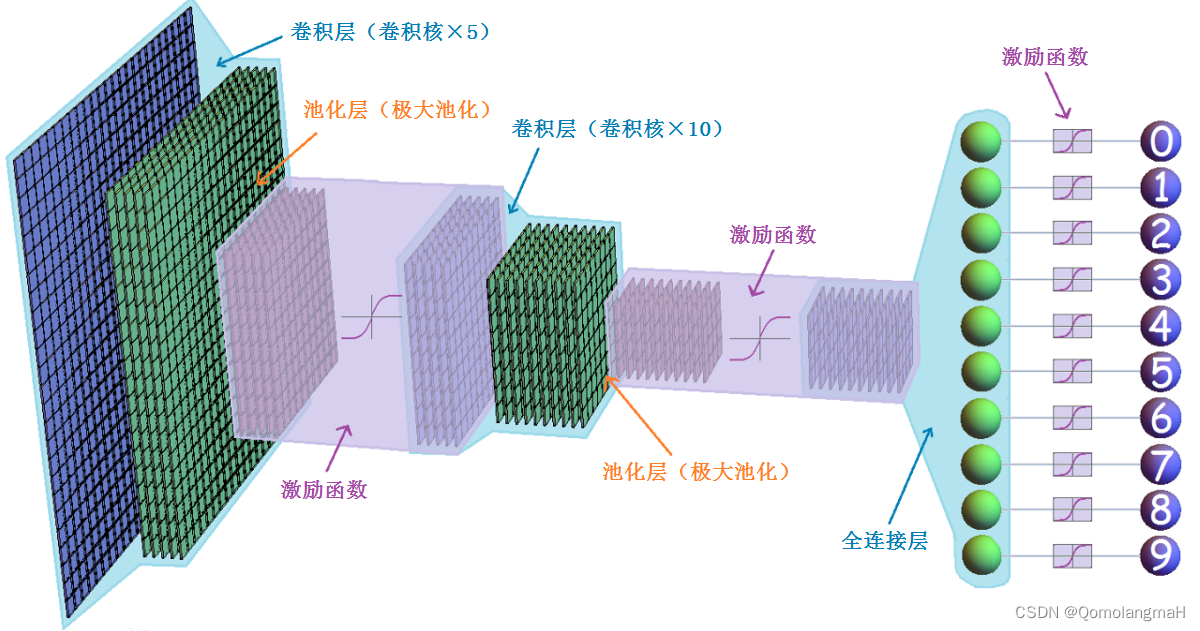
Convolutional Neural Network (CNN) is a deep learning model that is widely used in image recognition, computer vision, pattern recognition and other fields. Its design is inspired by how the visual cortex works in biology.
The convolutional neural network consists of multiple convolutional layers, pooling layers and fully connected layers .
- The convolution layer is mainly used to extract local features of the image. Through the processing of convolution operations and activation functions, the feature representation of the image can be learned.
- The pooling layer is used to reduce the dimension of the feature map and reduce the number of parameters while retaining the main feature information.
- The fully connected layer is used to map the extracted features to the probabilities of different categories for classification or regression tasks.
Convolutional neural networks have strong advantages in image processing. They can automatically learn feature representations with hierarchical structures and have certain invariance to image transformations such as translation, scaling, and rotation . These characteristics make convolutional neural networks the model of choice for tasks such as image classification, target detection, and semantic segmentation. In addition to image processing, convolutional neural networks can also be applied to other fields, such as natural language processing and time series analysis. By converting text or time series data into a two-dimensional form, convolutional neural networks can be used to process related tasks.
0. Import necessary toolkits
import torch
from torch import nn
import torch.nn.functional as F1. Step size, padding
Continuing from above:
- The convolution operator adds stride and zero padding
-
Improved cross-correlation function
corr2d, -
Improved convolution operator
Conv2D, -
In
forwardthe method,xa padding operation is applied to the input, which is handled by adding zero-valued pixels around the edges of the input. This ensures that the convolution kernel can perform effective convolution operations at the edge positions of the input, thereby maintaining consistency between the output size and the input size. -
When using
Conv2Dclasses to create objects, you can flexibly set the stride and padding by passing different parameters. In this way, the step size and filling method of the convolution operation can be adjusted according to the needs of specific tasks to obtain better performance and adaptability.
a. Two-dimensional cross-correlation operation (corr2d)
change into:
def corr2d(X, K, s):
h, w = K.shape
Y = torch.zeros(((X.shape[0] - h + 1)//s , (X.shape[1] - w + 1)//s))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i*s:i*s + h, j*s:j*s + w] * K).sum()
return Y Added a step parameter s. By specifying the step size, you can control the sliding step size of the convolution operation on the input, thereby adjusting the output size. In the original code, the step size is equivalent to being fixed at 1, while the modified code can s change the step size by adjusting the value.
b. Two-dimensional convolution layer class (Conv2D)
change into:
class Conv2D(nn.Module):
def __init__(self, kernel_size, stride=1, padding=0, weight=None):
super().__init__()
if weight is not None:
self.weight = weight
else:
self.weight = nn.Parameter(torch.rand(kernel_size))
self.bias = nn.Parameter(torch.zeros(1))
self.stride = stride
self.padding = padding
def forward(self, x):
new_x = torch.zeros((x.shape[0] + 2*self.padding, x.shape[1] + 2*self.padding))
new_x[self.padding:x.shape[0] + self.padding,self.padding:x.shape[1] + self.padding] = x
return corr2d(new_x, self.weight, self.stride) + self.bias- Added stride and padding parameters:
- The step parameter
stridecontrols the sliding step size of the convolution kernel on the input. - The padding parameter
paddingadds zero-valued pixels around the edges of the input to control the output size.- In
forwardthe method,xa padding operation is applied to the input, which is handled by adding zero-valued pixels around the edges of the input. (This ensures that the convolution kernel can perform effective convolution operations at the edge positions of the input, thereby maintaining the consistency of the output size and input size.)
- In
- The step parameter
c. Model testing
# 由于卷积层还未实现多通道,所以我们的图像也默认是单通道的
fake_image = torch.randn((5,5))
# 需要为步长和填充指定参数,若未指定,则使用默认的参数1和0
narrow_conv = Conv2D(kernel_size=(3,3))
output1 = narrow_conv(fake_image)
print(output1.shape)
wide_conv = Conv2D(kernel_size=(3,3),stride=1,padding=2)
output2 = wide_conv(fake_image)
print(output2.shape)
same_width_conv = Conv2D(kernel_size=(3,3),stride=1,padding=1)
output3 = same_width_conv(fake_image)
print(output3.shape)
Output:
torch.Size([3, 3])
torch.Size([7, 7])
torch.Size([5, 5])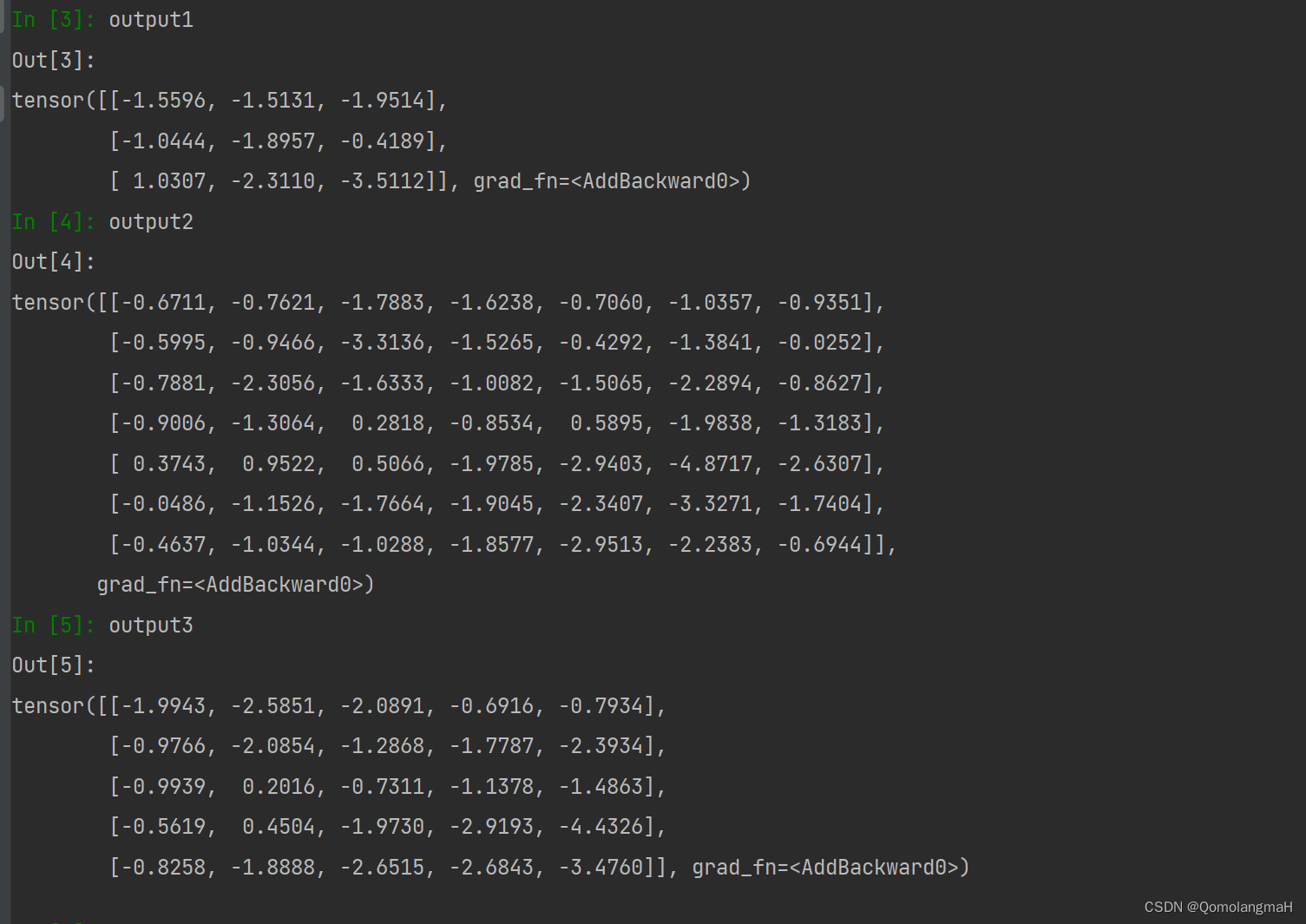
d. Code integration
# 导入必要的工具包
import torch
from torch import nn
import torch.nn.functional as F
# 修改后的互相关函数
def corr2d(X, K, s):
h, w = K.shape
Y = torch.zeros(((X.shape[0] - h + 1)//s , (X.shape[1] - w + 1)//s))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i*s:i*s + h, j*s:j*s + w] * K).sum()
return Y
# 修改后的卷积算子
class Conv2D(nn.Module):
def __init__(self, kernel_size, stride=1, padding=0, weight=None):
super().__init__()
if weight is not None:
self.weight = weight
else:
self.weight = nn.Parameter(torch.rand(kernel_size))
self.bias = nn.Parameter(torch.zeros(1))
self.stride = stride
self.padding = padding
def forward(self, x):
new_x = torch.zeros((x.shape[0] + 2*self.padding, x.shape[1] + 2*self.padding))
new_x[self.padding:x.shape[0] + self.padding,self.padding:x.shape[1] + self.padding] = x
return corr2d(new_x, self.weight, self.stride) + self.bias
# 由于卷积层还未实现多通道,所以我们的图像也默认是单通道的
fake_image = torch.randn((5,5))
# 需要为步长和填充指定参数,若未指定,则使用默认的参数1和0
narrow_conv = Conv2D(kernel_size=(3,3))
output1 = narrow_conv(fake_image)
print(output1.shape)
wide_conv = Conv2D(kernel_size=(3,3),stride=1,padding=2)
output2 = wide_conv(fake_image)
print(output2.shape)
same_width_conv = Conv2D(kernel_size=(3,3),stride=1,padding=1)
output3 = same_width_conv(fake_image)
print(output3.shape)
2. Input and output channels
a. corr2d_multi_in
def corr2d_multi_in(X, K, s):
# 先遍历“X”和“K”的第0个维度(通道维度),再把它们加在一起
return sum(corr2d(x, k, s) for x, k in zip(X, K))
Iterate over the first dimension (the channel dimension) of the input tensor X and kernel tensor and perform a cross-correlation operation on each channel, then add the results together.K
b. corr2d_multi_in_out
def corr2d_multi_in_out(X, K, s):
# 迭代“K”的第0个维度,每次都对输入“X”执行互相关运算。
# 最后将所有结果都叠加在一起
return torch.stack([corr2d_multi_in(X, k, s) for k in K], 0)
Used to handle multi-channel input and multi-channel output. It iterates over the first dimension of the kernel tensor K and performs a multi-channel cross-correlation operation on the input tensor X , adding all results together.
c. Conv2D
Further modifications:
class Conv2D(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=None, stride=1, padding=0, weight=None):
super().__init__()
self.in_channels = in_channels
self.out_channels = out_channels
if weight is not None:
h, w = weight.shape
weight = weight * torch.ones(in_channels, out_channels, h, w)
self.weight = nn.Parameter(weight)
else:
self.weight = nn.Parameter(torch.rand((in_channels, out_channels, kernel_size, kernel_size)))
self.bias = nn.Parameter(torch.zeros(1))
self.stride = stride
self.padding = padding
def forward(self, x):
new_x = torch.zeros((x.shape[0], x.shape[1] + 2 * self.padding, x.shape[2] + 2 * self.padding))
new_x[:, self.padding:x.shape[1] + self.padding, self.padding:x.shape[2] + self.padding] = x
return corr2d_multi_in_out(new_x, self.weight, self.stride)
-
In the constructor of the class, parameters for the number of input channels and the number of output channels
Conv2Dare added . Depending on the input parameters, convolution operators can be created with different numbers of input and output channels.in_channelsout_channels -
In
Conv2Dthe class, some modifications were made to the weight parameters. If an argument is passed inweight, it is expanded into multi-channel weights with the same shape. Otherwise, a weight with the specified number of input and output channels is randomly generated. -
In
forwardthe method, the input tensorxis expanded to accommodate the padding operation. Then call the new cross-correlation functioncorr2d_multi_in_outto perform multi-channel cross-correlation operations.
d. Model testing
fake_image = torch.randn((3,5,5))
conv = Conv2D(in_channels=3, out_channels=1, kernel_size=3, stride=2,padding=1)
output = conv(fake_image)
print(output.shape)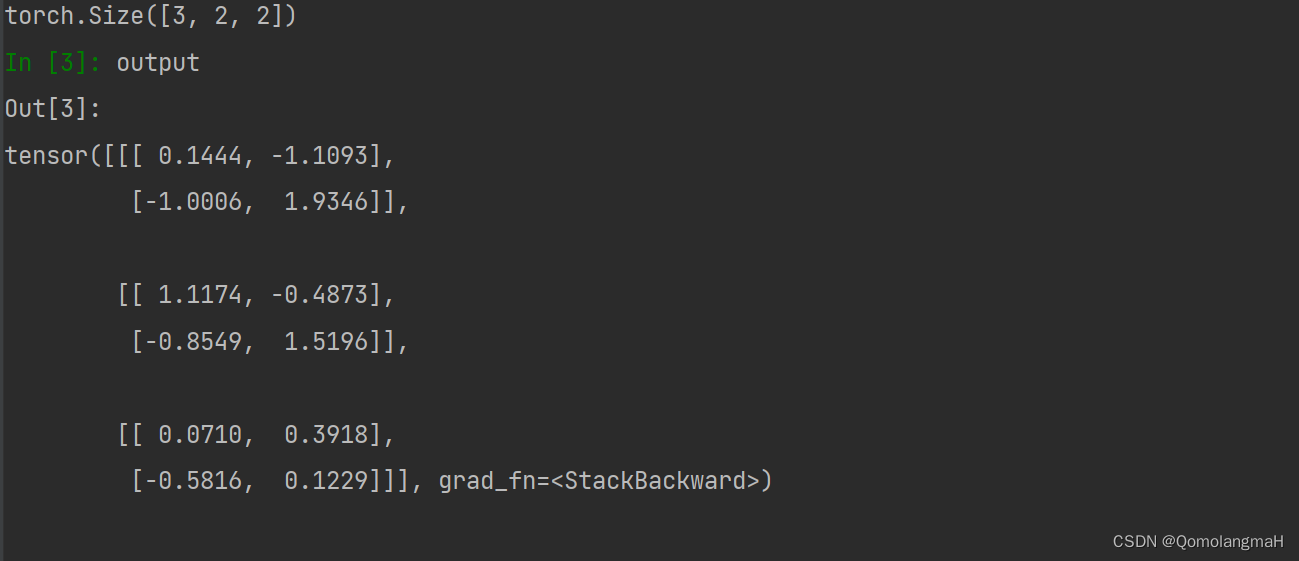
e. Code integration
# 导入必要的工具包
import torch
from torch import nn
import torch.nn.functional as F
# 修改后的互相关函数
def corr2d(X, K, s):
h, w = K.shape
Y = torch.zeros(((X.shape[0] - h + 1) // s, (X.shape[1] - w + 1) // s))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i * s:i * s + h, j * s:j * s + w] * K).sum()
return Y
# 修改后的卷积算子
# X为输入图像,K是输入的二维的核数组
def corr2d_multi_in(X, K, s):
# 先遍历“X”和“K”的第0个维度(通道维度),再把它们加在一起
return sum(corr2d(x, k, s) for x, k in zip(X, K))
def corr2d_multi_in_out(X, K, s):
# 迭代“K”的第0个维度,每次都对输入“X”执行互相关运算。
# 最后将所有结果都叠加在一起
return torch.stack([corr2d_multi_in(X, k, s) for k in K], 0)
class Conv2D(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=None, stride=1, padding=0, weight=None):
super().__init__()
self.in_channels = in_channels
self.out_channels = out_channels
if weight is not None:
h, w = weight.shape
weight = weight * torch.ones(in_channels, out_channels, h, w)
self.weight = nn.Parameter(weight)
else:
self.weight = nn.Parameter(torch.rand((in_channels, out_channels, kernel_size, kernel_size)))
self.bias = nn.Parameter(torch.zeros(1))
self.stride = stride
self.padding = padding
def forward(self, x):
new_x = torch.zeros((x.shape[0], x.shape[1] + 2 * self.padding, x.shape[2] + 2 * self.padding))
new_x[:, self.padding:x.shape[1] + self.padding, self.padding:x.shape[2] + self.padding] = x
return corr2d_multi_in_out(new_x, self.weight, self.stride)
fake_image = torch.randn((3,5,5))
conv = Conv2D(in_channels=3, out_channels=1, kernel_size=3, stride=2,padding=1)
output = conv(fake_image)
print(output.shape)