Let us have a look at the below diagram which shows us the different memory allocators present on linux based systems and discuss it later.
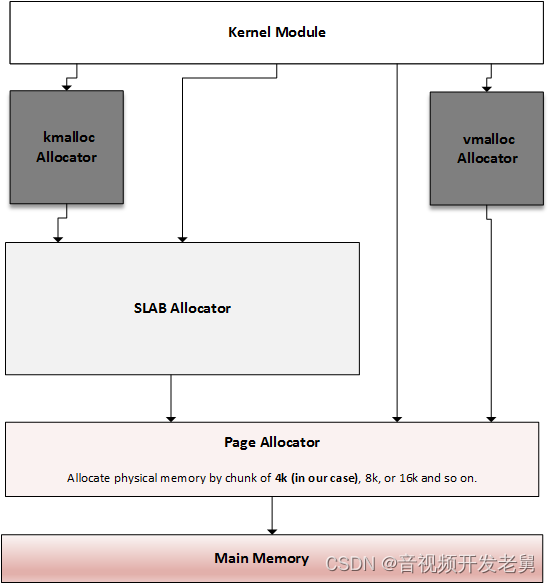
Kernel memory allocator overview
There is an allocation mechanism that can satisfy any kind of memory request. Depending on what kind of memory you need, you can choose the one closest to your goals. The main allocator is the page allocator, which only handles pages (the page is the smallest unit of memory it can deliver). Then there is the SLAB allocator, which is built on top of the page allocator, taking pages from it and returning smaller memory entities (via SLAB and caching). This is the allocator that the kmalloc allocator depends on.
page allocator
The page allocator is the lowest level allocator in the Linux system and is relied upon by other allocators. The system's physical memory consists of fixed-size blocks called page frames. In the kernel, a page frame is represented in the kernel as an instance of the structure struct page. A page is the smallest unit of memory that the operating system can grant any low-level memory request.
Page allocation API
We know that the kernel page allocator uses the buddy algorithm to allocate and free page blocks. Pages are allocated in blocks with a size that is a power of 2 (to get the best results from the buddy algorithm). This means it can allocate 1 page, 2 pages, 4 pages, 8 pages, 16 pages, etc.:
1. alloc_pages(mask, order) applies for 2 pages to the power of order, and returns an instance of the struct page structure, pointing to the first page of the applied block. If only one page of memory is requested, the value of order should be 0. The following is the implementation of alloc_page(mask):
struct page *alloc_pages(gfp_t mask, unsigned int order)
#define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0)__free_pages() is used to release the memory allocated by the alloc_pages() function. It accepts as argument a pointer to an allocated page, in the same order as when allocated:
void __free_pages(struct page *page, unsigned int order);2. There are other functions that work in the same way but are not instances of struct page and they return the address of the reserved block (virtual address). For example, __get_free_pages(mask, order) and __get_free_page(mask):
unsigned long __get_free_pages(gfp_t mask, unsigned int order);
unsigned long get_zeroed_page(gfp_t mask);free_pages() is used to release pages allocated with __get_free_pages(). The address addr parameter indicates the starting area of the allocated page, and the parameter order should be the same as when allocated:
free_pages(unsigned long addr, unsigned int order);Linux memory management project development tutorial→ Click to learn
In both cases above, the mask specifies details about the request, namely the memory area and the behavior of the allocator. The optional values for mask are as follows:
- GFP_USER: used for user memory allocation.
- GFP_KERNEL: Common flag for kernel memory allocation.
- GFP_HIGHMEM: Request memory from the HIGH_MEM area.
- GFP_ATOMIC: Allocate memory atomically without sleepability. Used when memory needs to be allocated from the interrupt context.
Note when using GFP_HIGHMEM that it should not be used with __get_free_pages() (or __get_free_page()), because HIGHMEM memory is not guaranteed to be continuous, so the memory address allocated from this area cannot be returned. Globally, only a subset of GFP_* is allowed in memory-related functions:
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
{
struct page *page;
/*
* __get_free_pages() returns a 32-bit address, which cannot represent
* a highmem page
*/
VM_BUG_ON((gfp_mask & __GFP_HIGHMEM) != 0);
page = alloc_pages(gfp_mask, order);
if (!page)
return 0;
return (unsigned long) page_address(page);
}alloc_pages() /__get_free_pages() 可以分配的最大页面数是1024。这意味着在一个4KB大小的系统上,您最多可以分配1024 * 4KB = 4MB。kmalloc也是一样。
conversion function
The page_to_virt() function is used to convert a struct page (such as the page returned by alloc_pages()) into a kernel address. virt_to_page() accepts a kernel virtual address and returns its associated struct page instance (as if allocated using the alloc_pages() function). Both virt_to_page() and page_to_virt() are defined in <asm/page.h>:
struct page *virt_to_page(void *kaddr);
void *page_to_virt(struct page *pg);The virtual address returned by the page_address() macro corresponds to the starting address (logical address) of the struct page instance:
void *page_address(const struct page *page);We can see how it is used in the get_zeroed_page() function:
unsigned long get_zeroed_page(unsigned int gfp_mask)
{
struct page * page;
page = alloc_pages(gfp_mask, 0);
if (page) {
void *address = page_address(page);
clear_page(address);
return (unsigned long) address;
}
return 0;
}__free_pages() and free_pages() are easily confused. The main difference between them is that free_pages() accepts a virtual address as a parameter, while __free_pages() accepts a struct page structure as a parameter.
slab allocator
The slab allocator is what kmalloc() depends on. Its main purpose is to eliminate fragmentation caused by memory allocation/deallocation caused by the buddy system when memory allocations are small, and to speed up memory allocation of frequently used objects.
buddy algorithm
The size of the memory allocation request is rounded to a power of 2, and the buddy allocator searches the corresponding list. If the requested entry does not exist, the entries in the next parent list (whose blocks are twice the size of the previous list) are split into two parts (called buddies). The allocator uses the first half, while the other part is added to the next list. This is a recursive method that stops when the buddy allocator successfully finds a chunk that can be split, or when a chunk reaches its maximum size and no free chunks are available.
For example, if the minimum allocation size is 1 KB and the memory size is 1 MB, the buddy allocator will create an empty list of 1 KB holes, an empty list of 2 KB holes, an empty list of 2 KB holes, a 4 KB hole, 8 KB, 16 KB, 32 KB , 64 KB, 128 KB, 256 KB, 512 KB, and a list of 1 MB holes. They are all empty initially, except for the 1MB list, which only has a hole. Let's say we want to allocate a 70K size block. The buddy allocator rounds it up to 128K and eventually splits that 1MB into two 512K chunks, then 256K, and finally 128K, and then it will allocate one of the 128K chunks to the user. Here's an overview of the scenario:
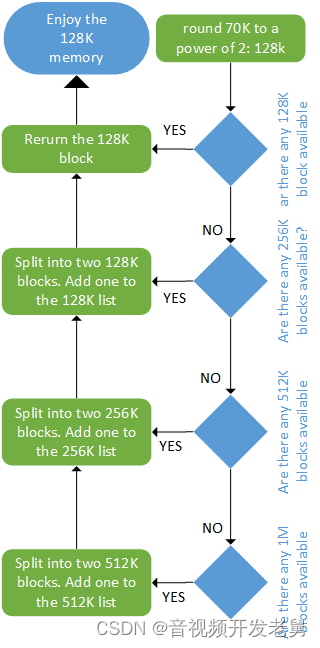
Allocation using buddy algorithm
Freeing is as fast as allocating. The following figure summarizes the recycling algorithm:

Use buddy algorithm for recycling
slab allocator analysis
- Slab: This is a contiguous physical memory consisting of several page frames. Each slab is divided into equal blocks of the same size and is used to store specific types of kernel objects, such as inodes, mutexes, etc. Each slab is an array of objects.
- Cache: It consists of one or more slabs in a linked list, which are represented in the kernel as instances of the struct kmem_cache_t structure. The cache only stores objects of the same type (for example, only inodes, or only address space structures).
Slabs may be in one of the following states:
- Empty: This is where all objects (chunks) on the slab are marked as free.
- Partial: used and free objects exist in the slab at the same time.
- Full: All objects on the slab are marked as used.
Building caches depends on the memory allocator. Initially, each slab is marked empty. When your code allocates memory for a kernel object, the system looks for a free location for that type of object in the cache's partial/free slab. If not found, the system will allocate a new slab and add it to the cache. New objects are allocated from this slab, and the slab is marked as partial. When the memory is used up (released), the object is simply returned to the slab cache in its initialized state.
That's why the kernel also provides helper functions to get memory initialized to zero, to erase previous contents. A slab keeps a reference count of how many objects are used, so when all slabs in the cache are full, and another object is requested, the slab allocator is responsible for adding the new slab:
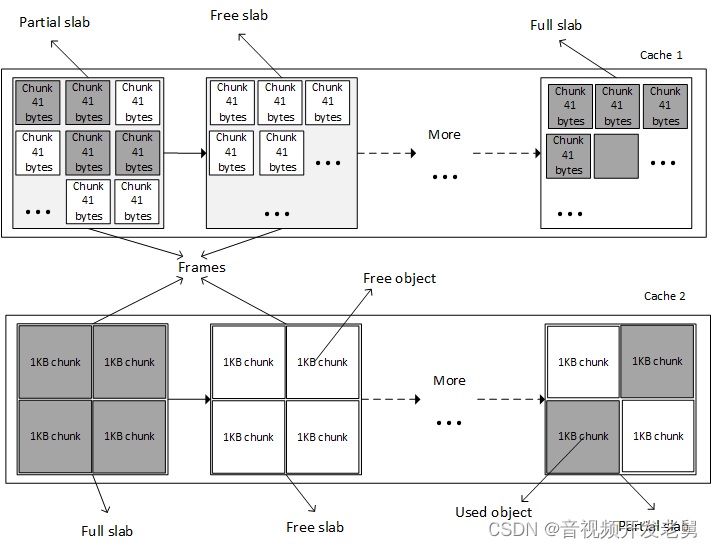
Slab cache overview
This is a bit like creating a per-object allocator, where the system allocates a cache for each type of object, and only objects of the same type can be stored in the same cache (for example, only task_struct structures).
There are different types of slab allocators in the kernel, depending on whether compactness, cache friendliness or raw speed is required:
- SLOB, which is as compact as possible
- SLAB, which is as cache-friendly as possible
- SLUB, very simple, requires less instruction overhead count
kmalloc
kmalloc is a kernel memory allocation function, such as malloc() in user space. The memory returned by kmalloc is contiguous in physical memory and virtual memory:
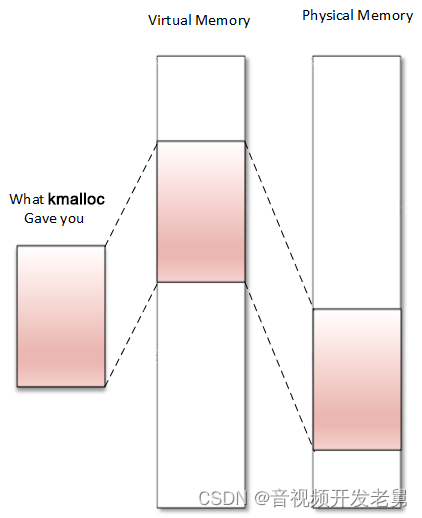
The kmalloc allocator is a common high-level memory allocator in the kernel, which relies on the SLAB allocator. The memory returned by kmalloc has a kernel logical address because it is allocated from the LOW_MEM area unless HIGH_MEM is specified. It is declared in <linux/slab.h> and should be included when using kmalloc in the driver. Here is the prototype:
void *kmalloc(size_t size, int flags);size specifies the size of memory to allocate (in bytes). flags determine how and where memory is allocated. The available flags are the same as the page allocator flags (GFP_KERNEL, GFP_ATOMIC, GFP_DMA, etc.):
- GFP_KERNEL: We cannot use this flag in interrupt handler because its code may sleep. It always returns memory from the LOM_MEM area (hence a logical address).
- GFP_ATOMIC: This guarantees atomicity of allocation. The only flag used in interrupt context. Please don't abuse it as it uses an emergency memory pool.
- GFP_USER: : This allocates memory to user space processes. It is completely different from the memory allocated to the kernel.
- GFP_HIGHUSER: This will allocate memory from the HIGH_MEMORY area.
- GFP_DMA: Allocate memory from DMA_ZONE.
On a successful allocation of memory, kmalloc returns the virtual address of the allocated block, guaranteed to be physically contiguous. If an error occurs, it returns NULL.
kmalloc relies on the SLAB cache when allocating small memory. In this case, the kernel rounds the allocated region size to the size of the smallest SLAB cache that can accommodate it. Always use this as your default memory allocator. On ARM and x86 architectures, the maximum size of each allocation is 4MB, and the maximum size of the total allocation is 128MB.
The kfree function is used to release the memory allocated by kmalloc. The following is the prototype of kfree():
void kfree(const void *ptr)example:
#include <linux/init.h>
#include <linux/module.h>
#include <linux/slab.h>
#include <linux/mm.h>
void *ptr;
static int alloc_init(void)
{
size_t size = 1024; /* allocate 1024 bytes */
ptr = kmalloc(size, GFP_KERNEL);
if(!ptr) {
/* handle error */
pr_err("memory allocation failed\n");
return -ENOMEM;
} else {
pr_info("Memory allocated successfully\n");
}
return 0;
}
static void alloc_exit(void)
{
kfree(ptr);
pr_info("Memory freed\n");
}
module_init(alloc_init);
module_exit(alloc_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("xxx");Other similar functions are:
1 void kzalloc(size_t size, gfp_t flags);
2 void kzfree(const void *p);
3 void *kcalloc(size_t n, size_t size, gfp_t flags);
4 void *krealloc(const void *p, size_t new_size, gfp_t flags);krealloc() is the user-space realloc() function in the kernel. Because the memory returned by kmalloc() retains its previous contents, it could be a security risk if exposed to user space. To get memory with all zero values, you should use kzalloc. kzfree() is the release function of kzalloc(), and kcalloc() allocates memory for the array. Its parameters n and size represent the number of elements and the size of the elements in the array respectively.
Since kmalloc() returns a memory area that is permanently mapped by the kernel (which means physically contiguous), you can use virt_to_phys() to convert the memory address to a physical address, or virt_to_bus() to convert the memory address to an IO bus address. These macros internally call either __pa() or __va() (if necessary). The physical address (virt_to_phys(kmalloc'ed address)), shifted down by PAGE_SHIFT, will generate the PFN of the first page of the allocated block.
vmalloc
The memory requested by vmalloc() is only continuous at the virtual address and not at the physical address.
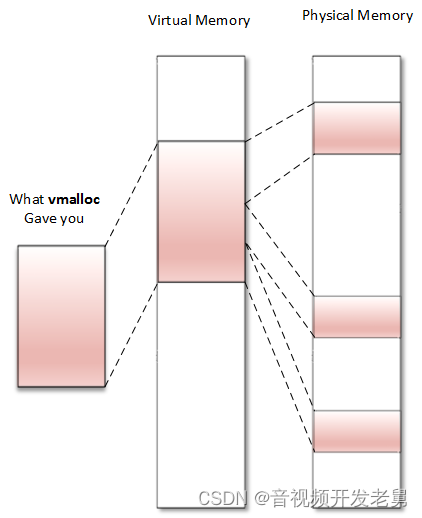
The memory returned is always from the HIGH_MEM area. The returned address cannot be translated into a physical address or a bus address because you cannot assert that the memory is physically contiguous. This means that the memory returned by vmalloc() cannot be used outside the microprocessor (you cannot easily use it for DMA purposes). It is correct to use vmalloc() to allocate memory for large sequences that only exist in software (e.g. network buffers) (e.g. there is no point in using it to allocate a page). It should be noted that vmalloc() is slower than kmalloc() or the page allocator function because it must retrieve memory, build page tables, and even remap into a contiguous range of virtual addresses, whereas kmalloc() never does this.
Before using the vmalloc API, you should include this header file in your code:
#include <linux/vmalloc.h>The following is the vmalloc family prototype:
1 void *vmalloc(unsigned long size);
2 void *vzalloc(unsigned long size);
3 void vfree( void *addr);size is the amount of memory you need to allocate. After successfully allocating memory, it returns the address of the first byte of the allocated memory block. On failure, it returns NULL. The vfree function is used to release the memory allocated by vmalloc().
An example of vmalloc is as follows:
#include<linux/init.h>
#include<linux/module.h>
#include <linux/vmalloc.h>
void *ptr;
static int my_vmalloc_init(void)
{
unsigned long size = 8192;
ptr = vmalloc(size);
if(!ptr) {
/* handle error */
printk("memory allocation failed\n");
return -ENOMEM;
} else {
pr_info("Memory allocated successfully\n");
}
return 0;
}
static void my_vmalloc_exit(void) /* function called at the time of
*/
{
vfree(ptr); //free the allocated memory
printk("Memory freed\n");
}
module_init(my_vmalloc_init);
module_exit(my_vmalloc_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("xxx");You can use /proc/vmallocinfo to display all memory used by vmalloc on the system. VMALLOC_START and VMALLOC_END are two symbols that separate vmalloc address ranges. They are architecture dependent and are defined in <asm/pgtable.h>.
Handles memory allocation internally
Let's focus on the lower level allocator, which allocates memory pages. The kernel will report the allocation of frame pages (physical pages) until they are actually needed (when these pages are actually accessed through reading or writing). This on-demand allocation is called lazy allocation and eliminates the risk of allocating pages that will never be used.
Whenever a page is requested, only the page table is updated and in most cases a new entry is created, which means only virtual memory is allocated. Only when you access the page will an interrupt called a page fault be thrown. This interrupt has a dedicated handler, called the page fault handler, which is called by the MMU when an attempt to access virtual memory does not succeed immediately.
In fact, a page fault interrupt will be raised regardless of the access type (read, write, execute) for pages whose entries in the page table do not have the appropriate permission bits set to allow this type of access. Response to this interrupt can be done in one of three ways:
- hard fault: The page does not reside anywhere (neither in physical memory nor in a memory-mapped file), which means that the handler cannot resolve the fault immediately. The handler will perform I/O operations to prepare the physical pages needed to resolve the failure, and may suspend the interrupted process and switch to another process while the system works to resolve the problem.
- soft fault: The page resides elsewhere in memory (in another process's working set). This means that the fault handler can immediately resolve the fault by appending a page of physical memory to the appropriate page table entry, adjusting the page table entry, and resuming the interrupted instruction.
- Unresolvable fault: This will result in a bus error or segv. SIGSEGV is sent to the offending process, terminating it (the default behavior), unless a SIGSEV signal handler has been installed to change the default behavior.
Memory mapping usually starts without any physical pages attached, but instead defines a virtual address range without any physical memory associated with it. When memory is accessed, the actual physical memory is allocated later in response to a page fault exception, because the kernel provides some flags to determine whether the attempted access is legal and to specify the behavior of the page fault handler. So userspace brk(), mmap() and similar allocate (virtual) space, but the physical memory is appended later.
A page fault occurring in an interrupt context results in a double fault interrupt, which usually causes the kernel to panic (call the panic() function). That's why the memory allocated in the interrupt context is obtained from the memory pool, which does not trigger a page fault interrupt. An interruption when handling a double fault will generate a triple fault exception, causing the CPU to shut down and the operating system to restart immediately. This behavior is actually arc-dependent.
copy-on-write (CoW)
CoW (used heavily in fork()) is a kernel feature that does not allocate multiple times more memory for data shared by two or more processes until one process uses it (writes to it); in this case , the memory is allocated to its private copy. Below shows how a page fault handler manages CoW (single page case study):
- Add the PTE to the process page table and mark it as non-writable.
- Mapping will cause the VMA to be created in the process VMA list. The page is added to the VMA and the VMA is marked writable.
- On page access (first write), the error handler notices the difference, which means this is a CoW. It then allocates a physical page (to the previously added PTE), updates the PTE flags, flushes the TLB entries, and executes the do_wp_page() function, which copies the content from the shared address to the new location.
As a bonus for this article, you can receive free C++ learning materials package, technical videos/codes, and 1,000 interview questions from major manufacturers, including (C++ basics, network programming, database, middleware, back-end development, audio and video development, Qt development)↓↓↓ ↓↓↓See below↓↓Click at the bottom of the article to get it for free↓↓