It mainly includes virtual memory and physical memory, process memory space, memory mapping of user state and kernel state.
Segmentation mechanism
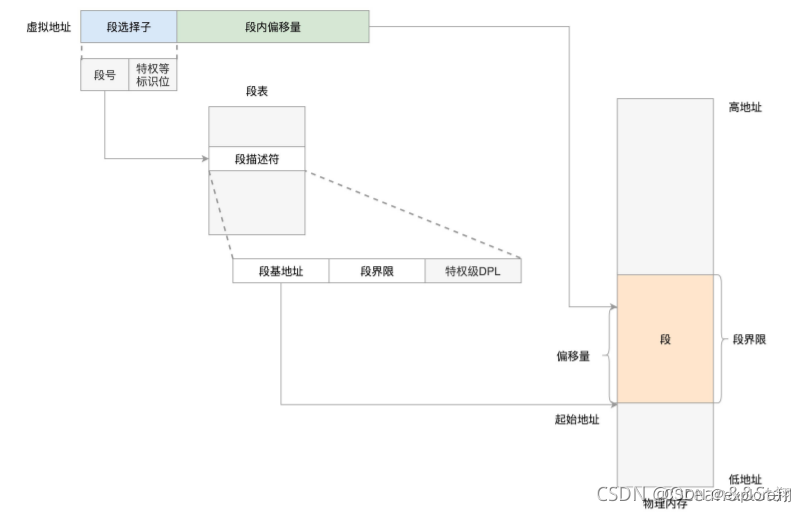
The segmentation mechanism is more logical, for example, the program can be divided into code segment, global variable segment, stack segment, etc.
The segmented virtual address mainly includes a segment selection factor and an offset within the segment. The segment selector is stored in the segment register. There is a segment number in the segment selector, which can be used as an index of the segment table. The segment table stores the base address of the segment, segment boundaries, privilege levels, etc.
So physical address = segment base address + offset.
In fact, Linux tends to another way of converting from virtual address to physical address, called paging (high efficiency).
For physical memory, the operating system divides it into pages of the same size, which is more convenient to manage. For example, if some memory pages are not used for a long time, they can be temporarily written to the hard disk, which is called swapping out; once they are needed, they can be loaded in again, which is called swapping in. This can expand the size of available physical memory and improve the utilization of physical memory (swapping in and swapping out technology)
This swap-in and swap-out are performed in units of pages. The page size is generally 4KB . In order to be able to locate and access each page, there needs to be a page table, which stores the starting address of each page, and adds the offset in the page to form a linear address, so that each location in the memory can be accessed up
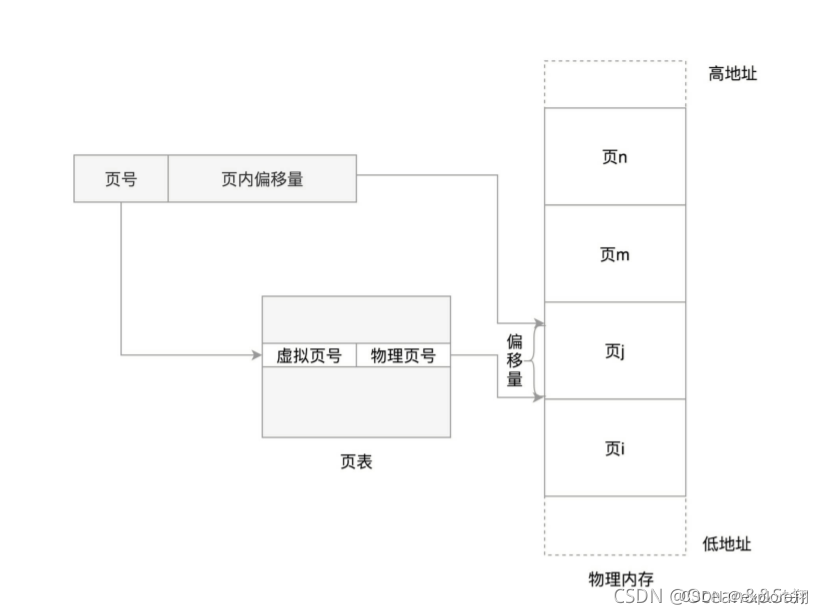
Similarly, physical address = page number + offset. (The page number will be mapped to the block number)
The memory management system mainly does the following three things:
First, the management of the virtual memory space divides the virtual memory into pages of equal size.
Second, the management of the physical memory divides the physical memory into pages. Pages of equal size
Third, memory mapping, which can be converted by mapping virtual memory and physical memory, and can be swapped out to the hard disk when the memory is tight
The virtual memory space of the process
The virtual address space of the process is actually viewed from the task_struct .
There is a struct mm_struct structure to manage memory:
struct mm_struct mm;
in struct mm_struct, there is such a member variable:
unsigned long task_size; / size of task vm space */
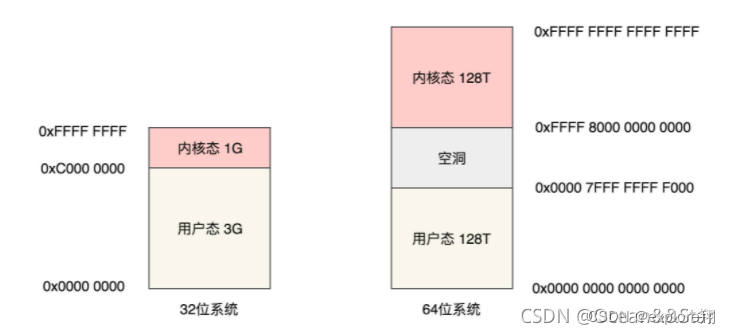
The entire virtual memory space should be divided into two parts, one part is One part of the user mode address space is the kernel mode address space. Where is the dividing line between these two parts? This requires task_size to define.
The source code is defined by macros. #ifdef CONFIG_X86_32 If it is a 32-bit system, the default user mode is 3G, and the kernel mode is 1G.
If it is a 64-bit system, #define TASK_SIZE_MAX ((1UL << 47) - PAGE_SIZE) actually only uses 48 bit. Both user mode and kernel mode are 128T.
Next, we need to understand what mm_struct mainly has to manage memory.
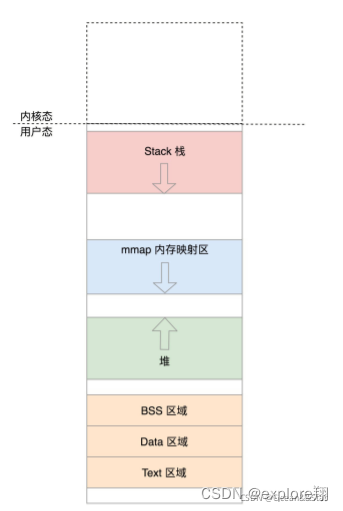
There are several types of data in the user mode virtual space, such as code, global variables, heap, stack, memory mapping area , etc. In the struct mm_struct, the following variables define the statistical information and locations of these areas:
total_vm: the total number of mapped pages. We know that such a large virtual address space cannot have real memory correspondence, so here is the number of mappings. When the memory is tight, some pages can be swapped out to the hard disk, and some pages cannot be swapped out because they are more important. locked_vm is locked and cannot be swapped out, and pinned_vm cannot be swapped out or moved.
And the starting position of the data and the number of pages, as well as the stack and code.
mmap_base represents the starting address for memory mapping in the virtual address space. In general, this space grows from high address to low address just like the stack.
When malloc applies for memory, it uses mmap to map an area to physical memory (less than 128K or brk allocated in the heap)
to load the dynamic link library so file, and also maps an area to the so file in this area.
In addition to location information, there is a special structure vm_area_struct in struct mm_struct to describe the attributes of these areas:
struct vm_area_struct mmap; / list of VMAs */
struct rb_root mm_rb;
This is a singly linked list for stringing these areas stand up. In fact, it refers to the areas of code, data, BSS, and stack memory mapping.
Each node will have pointers to the upper and lower areas, as well as the start and end positions of the area, and an entity (red-black tree, representing the entity of mm_struct)
In addition, there is a red-black tree, which can quickly find a memory area, and can be quickly modified when it needs to be changed. Each node is a mm_struct. (We already know that red-black trees are not only used for mm_struct entities, but also for entities that implement CFS scheduling)
There are also some memory-mapped, including to physical memory and files.
How do these vm_area_struct manage with the above memory area?
This thing is implemented in load_elf_binary . (load_elf_binary can be used to load the kernel, start the first user-mode process, and exec to run a binary program) When exec runs a binary program, in addition to parsing the ELF format, another important thing is to establish a memory map
Summary: Memory management, that is, the memory space layout of the process has a mm_struct structure, which contains the starting position of each area and the number of pages (stack data code memory mapping, etc.). And the linked list structure that manages these areas, and the red-black tree. Useful for quickly finding and easily modifying these areas. The allocation of each area is realized by the load_elf_binary function. Allocate space with the given starting location. The linked list can easily find the upper and lower areas and delete and add, and the red-black tree can easily find the entities of the area.
After the mapping is completed, under what circumstances will it be modified?
The first case is a function call, which involves the change of the function stack, mainly changing the top pointer of the stack. The
second case is to apply for a heap memory through malloc. Of course, the bottom layer either executes brk or mmap.
How does brk do it?
The first thing to do is to align the address of the original heap top and the current heap top according to the page, and then compare the size . If the two are the same, it means that the amount of heap added this time is very small, and it is still in one page. There is no need to allocate another page, just transfer to set_brk and set mm->brk to the new brk; if you find the old and
new If the top of the heap is not in a page, it means that it needs to cross pages. If it is found that the top of the new heap is smaller than the top of the old heap, it means that the memory is not newly allocated, but the memory is freed . The freed is not small, at least one page is released, so call do_dupmap to remove the memory map of this page.
If it is allocated For memory, it depends on the red-black tree. Find the next vm_area_struct of the original vm_area_struct where the top of the heap is located, and see if a complete page can be allocated between the current top of the heap and the next vm_area_struct (in fact, how much space is left between the heap and the memory mapping area) If you can’t, you have no choice but to exit and return directly, and the memory space is full.
If there is still space, call do_brk to further allocate the heap space. Starting from the top of the old heap, allocate the calculated number of pages between the old and new heap tops.
In do_brk, call find_vma_links to find the position of the future vm_area_struct node in the red-black tree, and find its parent node and preorder node.
Next call vma_merge to see if this new node can be merged with the nodes in the existing tree.
If the addresses are connected and can be merged, there is no need to create a new vm_area_struct, just jump to out and update the statistical value;
if they cannot be merged, create a new vm_area_struct and add it to the anon_vma_chain linked list and the red In the black tree.
(Summary brk: It’s not just about moving the top of the heap up and allocating a block of memory on the heap. First, check whether the old and new heap tops are in one page. If so, you don’t need to allocate a page, just return to the new top of the heap; if you cross pages, just It is necessary to consider whether there is enough space between the two areas . If there is no allocation, it will fail. If there is, calculate the number of allocated pages and check whether the areas can be merged. To create an area and add it to the linked list and red-black tree.
In fact, in order to avoid this problem, malloc allocates a large space in the form of mmap, directly takes a piece of memory, and must be recycled when it is used up; while brk only allocates small memory, and What is allocated is not the actual one. For example, 1 byte will be allocated 100 bytes, and it will be used in the buffer pool next time when it is used up, so frequent system calls are avoided; mmap avoids memory fragmentation.
You can realize that regional entities are not just data code segments, etc. For example, brk may involve memory release and recycling fragments and memory alignment. The allocated space is not continuous, so new regional nodes need to be added, which are linked lists and red-black trees. meaning of existence. Areas can be quickly found and area content updated.
You can also realize that the linux process actually combines segment page memory management. First, the basic addressing of virtual memory is in the form of pages. The page number is converted into a block number + virtual address through the page table to find the physical address. Some areas of the memory management data structure of the mm_strcut process are divided into segments, and the segments contain page numbers.
)
The layout of the virtual space in the memory state
The virtual space in the kernel state has nothing to do with a certain process. After entering the kernel only through the system call, the virtual address space seen is the same.
The first 1M space of the kernel has been occupied by the BIOS initialization programs; the
32-bit kernel state virtual address space is only 1G in total, accounting for most of the first 896M, which we call the direct mapping area. Most of them are placed here, such as the task_struct we often say, the mm_struct data structure related to process scheduling memory management is placed here, and the page table is also placed here.
In addition, the kernel also has space for the kernel stack. As mentioned earlier, when the system call enters the kernel state, the kernel stack is required. The feature of the kernel stack is that thread_info is used to store information related to the architecture (task_struct is common), and there is also a piece of memory to store The CPU context information of the user mode is used to restore the scene.
In addition, there is a kernel mapping area vmalloc, which is equivalent to the kernel's heap and memory mapping; and fixed mapping to meet specific needs.
Summary (kernel virtual space: initialization program, 896M direct mapping area, storage of user page table, process management structure, etc., vmalloc, special area)
There is one point that needs to be discriminated: where is the page table placed?
There is no doubt that the page table is placed in the direct mapping area of the kernel, because it cannot be changed at will, otherwise the random mapping will not achieve the protection and isolation effect.
In particular, the kernel also has its own page tables, such as the page table of the initialization program, the page table of the kernel malloc, etc., which are placed in their own kernel area. When the process is switched, only the user's page table will be switched, and the kernel page table will not change. (that is, scheduling, find the next task_struct)
So does the page table need to fall into the kernel every time it is queried?
not really. Designers have thought of this a long time ago. It would be too inefficient to enter the kernel every time virtual memory is converted to physical memory.
Therefore, this address translation work is done by hardware, no code participation is required, and there is no performance loss.
So will the addition and deletion of page table entries enter the kernel?
This is true. For protection, for safety. But in fact, the malloc/free function has already encapsulated a layer. Free will not reclaim memory immediately but put it in the buffer pool, and malloc (1) will not only allocate 1 byte, but allocate a little more. It is for frequent system calls;
The TLB block table is in memory, very quickly. The page table is in physical memory, that is, external memory.
To sum up:
the function of virtual memory is: multi-tasking system, which plays the role of process isolation; in addition, swapping in and swapping out technology expands logical memory;
each process will have its own task_struct, which is stored in the kernel space. This structure has a lot of information, including scheduling, memory management, file system management, statistical information, pid affinity information, permission management, signal processing, kernel stack, and so on.
For memory, mm_struct will record the information of each area (linked list + red-black tree), the process will have its own page table, stored in the kernel space, so fork a process is to fork its task structure and Assignment, which contains the page table;
when the process is switched, it is to find another task structure to execute, and the user's page table will also be switched. This will cause the cache to not be hot and the hit rate to become lower.
Physical memory management
The organization of physical memory
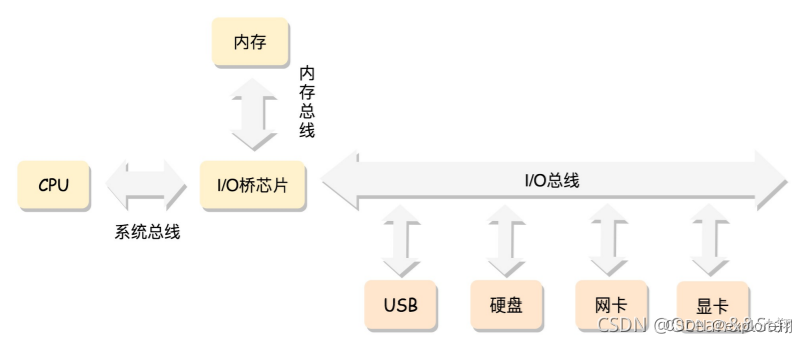
The most classic way of using memory: The CPU accesses memory through the bus
Flat memory model (the most classic model):
Memory is composed of continuous page-by-page blocks. We can start numbering the physical page process from 0, so that each physical page will have a page number. All the memory sticks form a large memory. On the other side of the bus, all CPUs access the memory through the bus, and the distance is the same. This mode is called SMP (Symmetric multiprocessing), that is, symmetrical multiprocessing.
Of course, the disadvantage is that the bus will become a bottleneck, because data must go through it.
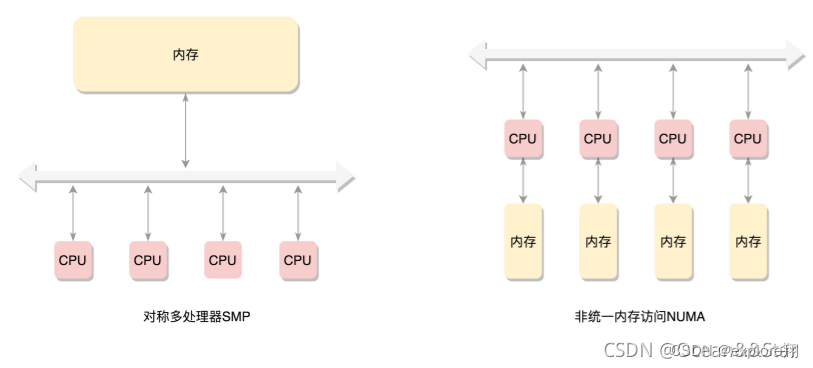
In order to improve performance and scalability, a more advanced mode, NUMA (Non-uniform memory access), non-uniform memory access: every Each CPU has its own local memory, and the CPU accesses the local memory without going through the bus, so the speed is much faster. Each CPU core is stored together, which is called a NUMA node. However, when the local memory is insufficient, each CPU can go to another NUMA node to apply for memory, and the access delay will be relatively long at this time.
Later, the memory technology became better, and it can support hot plugging. At this time, discontinuity becomes the norm, so there is a sparse memory model.
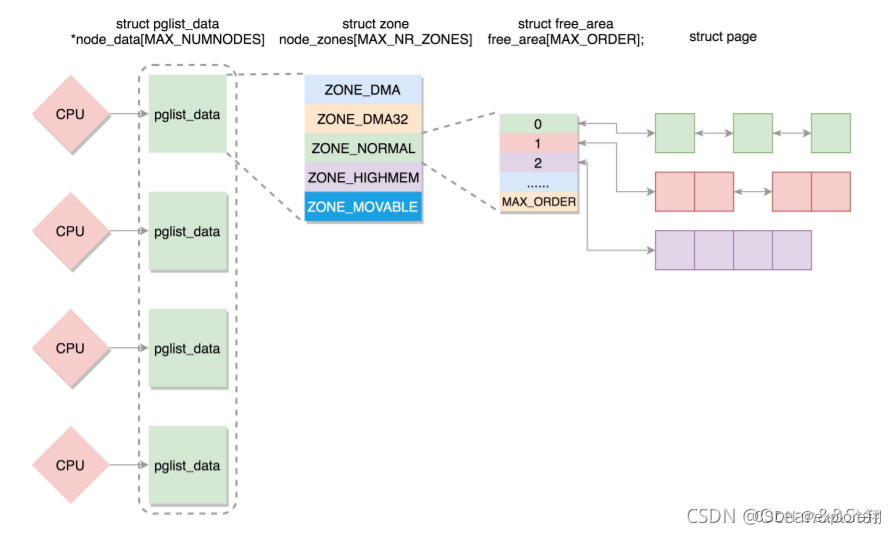
If there are multiple CPUs, there are multiple nodes. Each node is represented by struct pglist_data and placed in an array.
Each node is divided into multiple areas, and each area is represented by struct zone, which is also placed in an array.
Each area is divided into multiple pages. For the convenience of allocation, free pages are placed in struct free_area, managed and allocated using the buddy system , and each page is represented by struct page.
The whole is node-area-page
Page is the basic unit of physical memory, and its data structure is struct page. This is a particularly complex structure with many unions in it. The reason why union is used here is because there are many usage modes of a physical page .
In the first mode, use a full page if you want. This entire page of memory
may directly establish a mapping relationship with the virtual address space . We call this anonymous page (anonymous page)
or use it to associate a file, and then establish a mapping relationship with the virtual address space . Such a file, we call it For
the second mode of Memory-mapped File , only a small block of memory needs to be allocated.
Sometimes, we don't need to allocate so much memory at once, such as allocating a task_struct structure. The Linux system uses a technology called slab allocator. Its basic principle is to apply for a whole block of pages from the memory management module, and then divide them into storage pools of multiple small blocks, and use complex queues to maintain the state of these small blocks. It is also because the slab allocator is too complicated to maintain the queue, and then there is an allocator that does not use the queue.
Allocation of pages
Above we talked about the organization of physical memory, from nodes to areas to pages to small blocks. Next, let's look at the allocation of physical memory.
For relatively large memory allocation, such as at the allocation page level, you can use the buddy system :
The "page" size of memory management in Linux is 4KB. Group all free pages into 11 page block lists, each block list contains page blocks of many sizes, and there are 1, 2, 4, 8, 16, 32, 128, 256, 512, and 1024 consecutive pages page blocks. A maximum of 1024 consecutive pages can be applied for, corresponding to 4MB of continuous memory. The physical address of the first page of each page block is an integer multiple of the page block size.
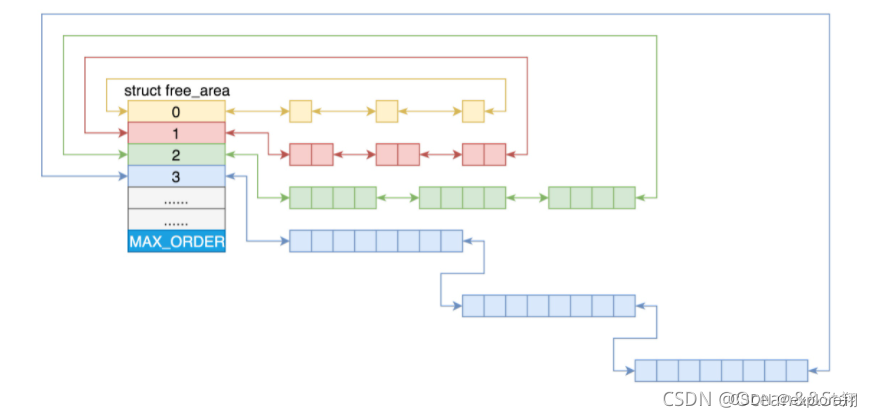
In the ith page block linked list, the number of pages in the page block is 2^i. For example, when requesting a page block of 128 pages, first check whether there is a free block in the page block linked list of 128 pages. If not, check the page block list of 256 pages; if there are free blocks, divide the page block of 256 pages into two parts, use one part, and insert one part into the page block list of 128 pages. If there is still no page block list, check the page block list of 512 pages; if there is, it will be split into three page blocks of 128, 128, and 256, one 128 is used, and the remaining two are inserted into the corresponding page block list (of the partner system) It means stealing from the rich and giving to the poor)
If a small object is encountered, the slub allocator will be used for allocation. Next, its principle will be analyzed. The principle is too complicated
Page swapping out
Under what circumstances will page swapping be triggered?
As you can imagine, the most common situation is that when you allocate memory, you find that there is no space, so you try to recycle it.
Another situation is that as a memory management system, it should take the initiative to do it instead of waiting for something to happen. This is the kernel thread kswapd. This kernel thread is created when the system is initialized. This way it goes into an infinite loop until the system stops. In this cycle, if the memory usage is not so tight, you can rest assured to sleep with it; if the memory is tight, you need to check the memory to see if you need to swap out some memory pages.
There is an lru list here. From the following definition, we can imagine that all pages are mounted in the LRU list , and LRU is the Least Recent Use, that is, the least recently used. In other words, the list will be sorted according to the degree of activity, so that it is easy to take out the memory pages that are not used very much for processing.
There are two types of memory pages, one is anonymous pages, which are managed with virtual addresses ; the other is memory mapping, which is not only managed with virtual address space, but also managed with file management .
Each of its categories has two lists, a total of active, a total of inactive. Active is relatively active, and inactive is not very active. The pages here will change. After a period of time, the active ones may become inactive, and the inactive ones may become active. If you want to swap out the memory, it is to find the least active one from the inactive list and swap it out to the hard disk.
This involves the problems of cache pollution and read-ahead failure of the LRU algorithm.
Cache pollution is to read a large amount of data at a time, but only for this access, if the LRU needs to move from beginning to end, it will take a long time. The linux operating system uses active and inactive LRUs. At the beginning, it is inactive, and only when certain conditions are met will it enter the active list. Similar to mysql, redis uses lfu instead of lru.
User-mode memory mapping
Each process has a list vm_area_struct, which points to different memory blocks in the virtual address space. The name of this encoding is mmap
struct mm_struct { struct vm_area_struct mmap; / list of VMAs */ ... } In fact, memory mapping is not only The mapping between physical memory and virtual memory also includes mapping the contents of the file to the virtual memory space. At this time, the data in the file can be accessed by accessing the memory space. And only the mapping of physical memory and virtual memory is a special case. If we want to apply for a small heap memory, use brk. If we want to apply for a large heap of memory, use mmap. The mmap here is to map the memory space to the physical memory. If a process wants to map a file to its own virtual memory space, the mmap system call is also used. At this time, mmap maps memory space to physical memory and then to files. What does the mmap system call do? Call get_unmapped_area to find an unmapped area : find the corresponding position on the vm_area_struct red-black tree representing the virtual memory area Call mmap_region to map this area : first see if you can merge with the previous one, if not, create a new vm_area_struct object , set the start and end positions, and add it to the queue. If it is mapped to a file, it is to call the file op related function. At this moment, the relationship between the file and the memory begins
up. Here we set the memory operation of vm_area_struct as a file system operation, that is, reading and writing memory is reading and writing the file system.
Finally, the vma_link function hangs the newly created vm_area_struct on the red-black tree in mm_struct.
Another thing vma_link does is __vma_link_file. For the opened file, there will be a structure struct file to represent it. It has a member pointing to the struct address_space structure, and there is a red-black tree whose variable name is i_mmap, and vm_area_struct is hung on this tree. That is to establish a file-to-memory mapping.
But it has not had any relationship with physical memory yet, is it still tossing in virtual memory?
Yes, at this time, memory management does not directly allocate physical memory, because physical memory is too precious compared to the virtual address space, and it will only start to allocate when it is actually used. malloc allocates virtual memory.
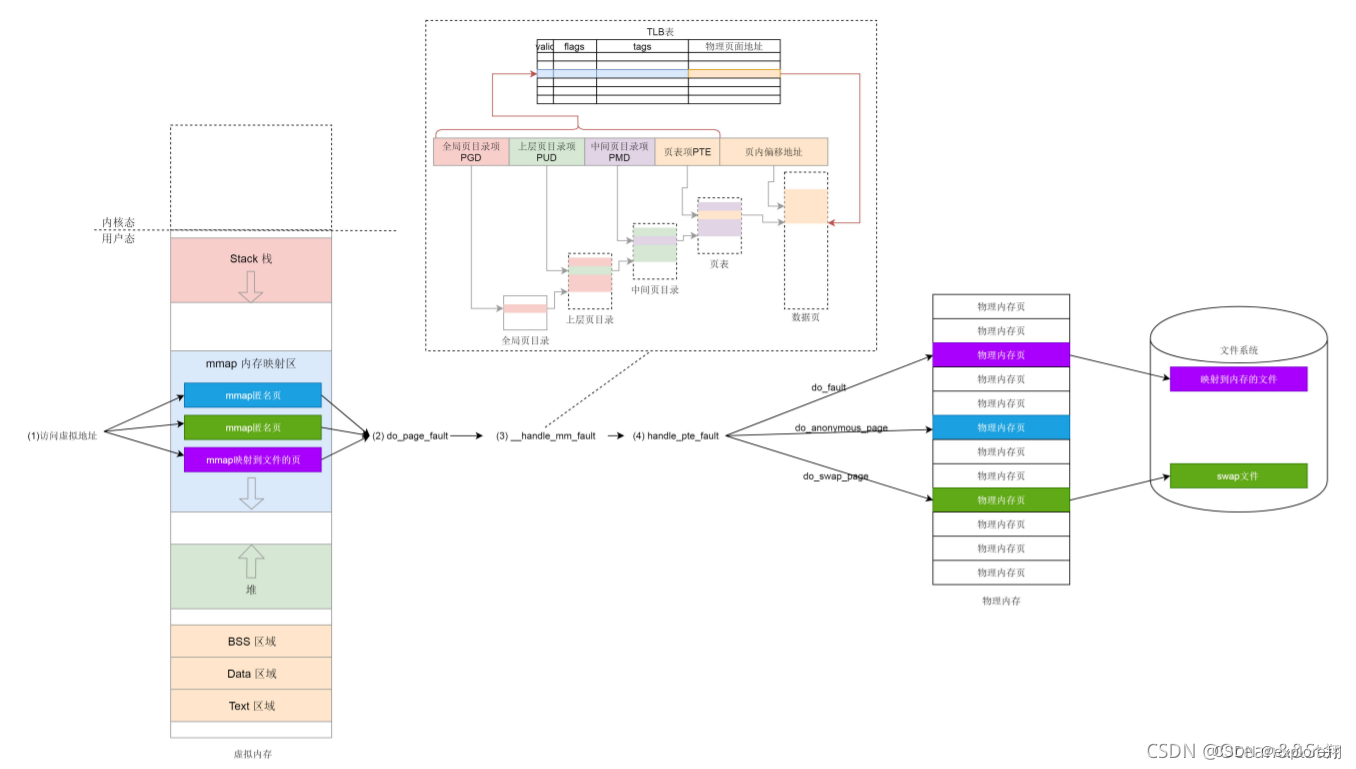
Page fault exception
Once you start to access an address in the virtual memory, if you find that there is no corresponding physical page, a page fault interrupt will be triggered. Call do_page_fault
in __do_page_fault to determine whether the page fault interrupt occurred in the kernel. If it occurs in the kernel, call vmalloc_fault. In the kernel, the vmalloc area needs to be mapped to the physical page by the kernel page table;
if it occurs in the user space, find the area vm_area_struct where the address you are accessing is located, and then call handle_mm_fault to map this area; how to What about virtual-to-physical mapping?
In this function, we see the familiar PGD, P4G, PUD, PMD, PTE, which is the concept of the four-level page table in the page table.
pgd_t is used for the global page directory entry , pud_t is used for the upper layer page directory entry , and pmd_t is used for the middle Page directory entries, pte_t for direct page table entries .
Each process has an independent address space. In order to complete the mapping independently for this process, each process has an independent process page table. The topmost pgd of this page table is stored in the pgd variable of mm_struct in task_struct.
When we fork, the task_struct of the memcpy parent process must copy the pgd variable of mm_strcut. mm_init calls mm_alloc_pgd to allocate global page directory pages. In addition to allocating PDG , pgd_alloc also does a very important thing, which is to call pgd_ctor to copy the kernel page table.
When this process is called to run on a certain CPU. That is to say, there will be a page fault interrupt. This will call load_new_mm_cr3. cr3 is a CPU register that points to the top-level pgd of the current process. If the CPU instruction wants to access the virtual memory of the process, it will automatically get the address of pgd in the physical memory from cr3, and then parse the address of the virtual memory into physical memory according to the page table inside, so as to access the data on the real physical memory . (This is why it is said that address translation is done by hardware, and the conversion process does not need to enter the kernel state)
The page fault will be abnormal for the first time, so __handle_mm_fault calls pud_alloc and pmd_alloc to create the corresponding page directory entry, and finally calls handle_pte_fault to create the page table entry. The next visit will not cause a page fault exception.
The creation of page table entries is divided into three situations: the first is that pte has appeared, indicating that the original page is in the physical memory, and then it was swapped out to the hard disk, and it should be swapped back now, calling do_swap_page . (These pages are stored in the swap partition, first check whether the swap file has cached pages, and not loaded from the hard disk.) The second
is that pte has not appeared, and it should be mapped to a physical memory page. Here, do_anonymous_page is called. (First allocate a page table entry through pte_alloc, and finally call __alloc_pages_nodemask, this function is the core function of the partner system, dedicated to allocating physical pages) If it is
mapped to a file, do_fault is called (first look at the physical memory Is there a cache of the file page table, and the content of the file is not read into the memory, and the temporary mapping of the kernel virtual address is involved here, which is troublesome)
Kernel mode memory mapping
The kernel mode memory mapping mechanism mainly includes the following parts: How do the
kernel mode memory mapping functions vmalloc and kmap_atomic work?
Where is the kernel mode page table placed and how does it work? What's the matter with swapper_pg_dir;
what should I do if there is a kernel state page fault exception?
Unlike the user-mode page table, when the system is initialized, we will create the kernel page table. Next is to initialize the kernel page table, and start_kernel will call setup_arch when the system starts.
vmalloc is a dynamic mapping of the kernel, because the kernel only has 896MB direct mapping, and it will be used if a large block of memory is dynamically applied.
kmap_atomic is a temporary mapping, and the above-mentioned file mapping will use the temporary mapping of the kernel.
The model of kernel address mapping is a
32-bit process virtual memory space, 3GB is for the user, and 1GB is for the kernel. If they are all directly mapped, then the kernel can only access 1GB of physical memory. If 8GB of physical memory is installed, the 7GB kernel cannot be accessed. So it can't all be direct mapping.
So x86 is divided into three parts:
DMA, NORMAL, HIGHMEM.
DMA occupies 0-16MB: used for automatic access to devices, IO does not use CPU, and liberates CPU;
NORMAL: direct mapping area, such as storing task_strcut;
HIGHMEM: so-called High-end memory (896-1024MB) uses 124MB of memory to map all physical memory.
(In fact, it is to borrow a section of address space, establish a temporary mapping, and release it after use) What if someone does not release it all the time?
The high-end memory is actually divided into three parts:
VMALLOC part; KMAP part, FIX part
VMALLOC is used to realize dynamic mapping;
FIX part: kmap_atomic for temporary mapping
. ), different processes are the same, and the corresponding user space is the PGD global page table, which is pointed to by the CR3 register.
Now to summarize;
first: the management of process virtual memory. Section page combination. Because the virtual address space of a process is divided into regions according to segments, but the smallest unit is a page. There is a mm_stcuct management, the most important of which is the vm_area_struct structure, which contains a linked list and a red-black tree. Each area will have an entity in the red-black tree, and then placed on the linked list. For quick lookups and changes.
The second is: the organization of physical memory. Including NUMA architecture, divided into node area pages. Physical memory allocation: use the partner system (multi-level linked list) for large ones, and slab allocator for small ones. Swapping in and out of physical memory, when the memory is not enough, the kswapd kernel thread swaps out some memory pages, the classic LRU algorithm is active and inactive to solve the problem of cache pollution.
The third is the mapping of virtual addresses to physical addresses. page table to complete. There are many specific ones.
There are only two operations that can change the memory map of the process, either the function call will move the stack pointer up; one is that Malloc dynamically allocates memory. (Page table translation does not need to fall into the kernel, but a new page table entry is required, because malloc actually encapsulates a layer, allocates more at a time, and free does not recycle immediately, avoiding frequent page fault interrupts.) malloc allocation is
small The brk used for memory, summarizing brk: not just moving up the top of the heap and allocating a piece of memory on the heap. First of all , check whether the old and new heap tops are in one page. If so, you don’t need to allocate pages, just return to the new heap top; if you cross pages, you need to consider whether there is enough space between the two areas . If it fails, if there is, calculate the number of allocated pages, and check whether the regions can be merged. If the connected ones can be merged directly, if not, create regions and add them to the linked list and red-black tree.
To allocate large memory, use mmap memory mapping.
First call unmapparea to check the unmapped area, which is actually looking in the red-black tree;
after finding it, see if it can be merged with the previous one, if not, create a new one and hang it on the red-black tree;
the idea is almost the same as brk;
these are just virtual address;
then once the process is used, when the process is called to run on a certain CPU. That is to say, there will be a page fault interrupt . This will call load_new_mm_cr3. cr3 is a CPU register that points to the top-level pgd of the current process. If the CPU instruction wants to access the virtual memory of the process, it will automatically get the address of pgd in the physical memory from cr3, and then parse the address of the virtual memory into physical memory according to the page table inside, so as to access the data on the real physical memory .
Because there will only be a page fault interrupt for the first time, after accessing, __handle_mm_fault calls pud_alloc and pmd_alloc to create the corresponding page directory entry, and finally calls handle_pte_fault to create the page table entry. The next visit will not cause a page fault exception.
The creation of page table entries is also divided into three types, see the front for details.
The Linux page table is divided into four levels. The global page table of each process is different, so when the process is switched, the PGD is also different. But the kernel's global page table (swapper_pg_dir) is the same (the page table of the kernel initialization program, etc.), and is stored in the persistent mapping area.
There are PUD, PMD, and PTE under PGD. The corresponding physical block number can be found through the CR3 register.
In fact, the MMU first looks for the TLB, and then looks for the CR3. If there is no page fault, it will be abnormal.
At the same time, malloc will also allocate virtual addresses first, and when it is used, it will enter the MMU page fault exception and process it.
The fourth is the spatial layout of the kernel and the classification of the memory map of the kernel.