Drive&Act:A Multi-modal Dataset for Fine-grained Driver Behavior Recognition in Autonomous Vehicles
Summary
- This paper introduces a new domain-specific Drive&Act benchmark for fine-grained classification of driver behavior.
- The dataset contains 12 hours and more than 9.6 million frames of people engaging in distracting activities during manual and autonomous driving.
- Color , infrared , depth and 3D body pose information are captured from six views and the videos are densely labeled using a hierarchical annotation scheme, resulting in 83 categories.
- The main challenges facing the dataset are: (1) identifying fine-grained behaviors
within vehicle cabins ; (2) multi-modal activity recognition, focusing on multiple data streams; (3) cross-view recognition benchmarks , where models deal with unfamiliar field data because the type of sensors and their location in the cabin may change between vehicles. - Finally, challenging benchmarks are provided by employing prominent video- and body pose-based action recognition methods.
1 Introduction
- While the rise of automation has encouraged driver distraction, most computer vision research has focused on understanding what's going on outside the car.
- At the same time, observing people in the car has great potential to improve human-vehicle communication, dynamic driving adaptability and safety.
- It is estimated that most traffic accidents involve secondary activities behind the wheel, and 36% of collisions could have been avoided if distractions did not occur.
- While future drivers will gradually transition away from autonomous vehicles, the transition to full levels of automation is a long-term process.
- Over-reliance on automation could have disastrous consequences, and drivers will need to intervene in uncertain situations for a long time to come.
- In addition to identifying driver distractions for safety reasons, driver activity recognition can increase comfort, for example, when the person is drinking coffee, turning on the lights, or reading a book, and can adjust the driving style.
- Driver behavior recognition is closely related to the broader field of action recognition, where performance data are increasing rapidly due to the rise of deep learning.
- Such models require large amounts of data and are often evaluated on large color-based datasets, often sourced from Youtube, carefully selected for highly discriminatory operations.
- Possibly due to insufficient data sets for training such models, research on driver activity understanding lags far behind.
- Existing work is often limited to classifying few low-level actions (e.g., whether a person is holding the steering wheel or changing gears ). None of the existing benchmarks cover higher-level activities (such as changing clothes), especially in the context of highly autonomous driving.
- The goal of the paper is to promote activity recognition research in realistic driving conditions, such as low light and limited body visibility, and proposes a new Drive&Act dataset .
- Drive&Act addresses various potential challenges related to the practical application of activity recognition models and is the first publicly available dataset that combines the following properties: (1) Driver secondary in autonomous and manual driving
environments Activities (83 categories in total).
(2) Multi-modality : color, depth, infrared and body posture data, because traditional RGB-based action recognition data sets ignore low-light situations.
(3) Multi-view : Six synchronized camera views cover the vehicle cabin to handle limited vehicle body visibility.
(4) Hierarchical activity tags : at three levels of abstraction and complexity including contextual annotations.
(5) Fine-grained distinctions between individual classes (such as open and closed bottles), high diversity in action duration and complexity , which pose additional challenges to action recognition methods. (For example, opening a door from the inside usually takes less than a second, while reading a magazine can take several minutes) - In addition to autonomous driving applications, this dataset fills the gap of large multi-modal benchmarks for concise recognition at multiple levels of abstraction.
- An extensive evaluation of state-of-the-art methods for video- and body pose-based action recognition demonstrates the difficulty of benchmarking, highlighting the need for further extensive action recognition research.
2. Other driver action data sets
3. Drive&Act data set
To address the lack of domain-specific behavioral recognition benchmarks, we collected and publicly released the Drive&Act dataset, which consists of 12 hours of data on drivers engaged in secondary tasks while driving in manual and automated modes.
3.1 Data collection
- Dataset collected in a static driving simulator.
- Use SILAB simulation software 1 to simulate and project the environment around the vehicle on multiple screens around your modified Audi A3.
- Manual, autopilot and takeover can all be induced in our setup.
- To encourage diverse and proactive behavior, drivers were instructed to complete 12 different tasks during each session (two examples of instructions are illustrated in Figure 1).
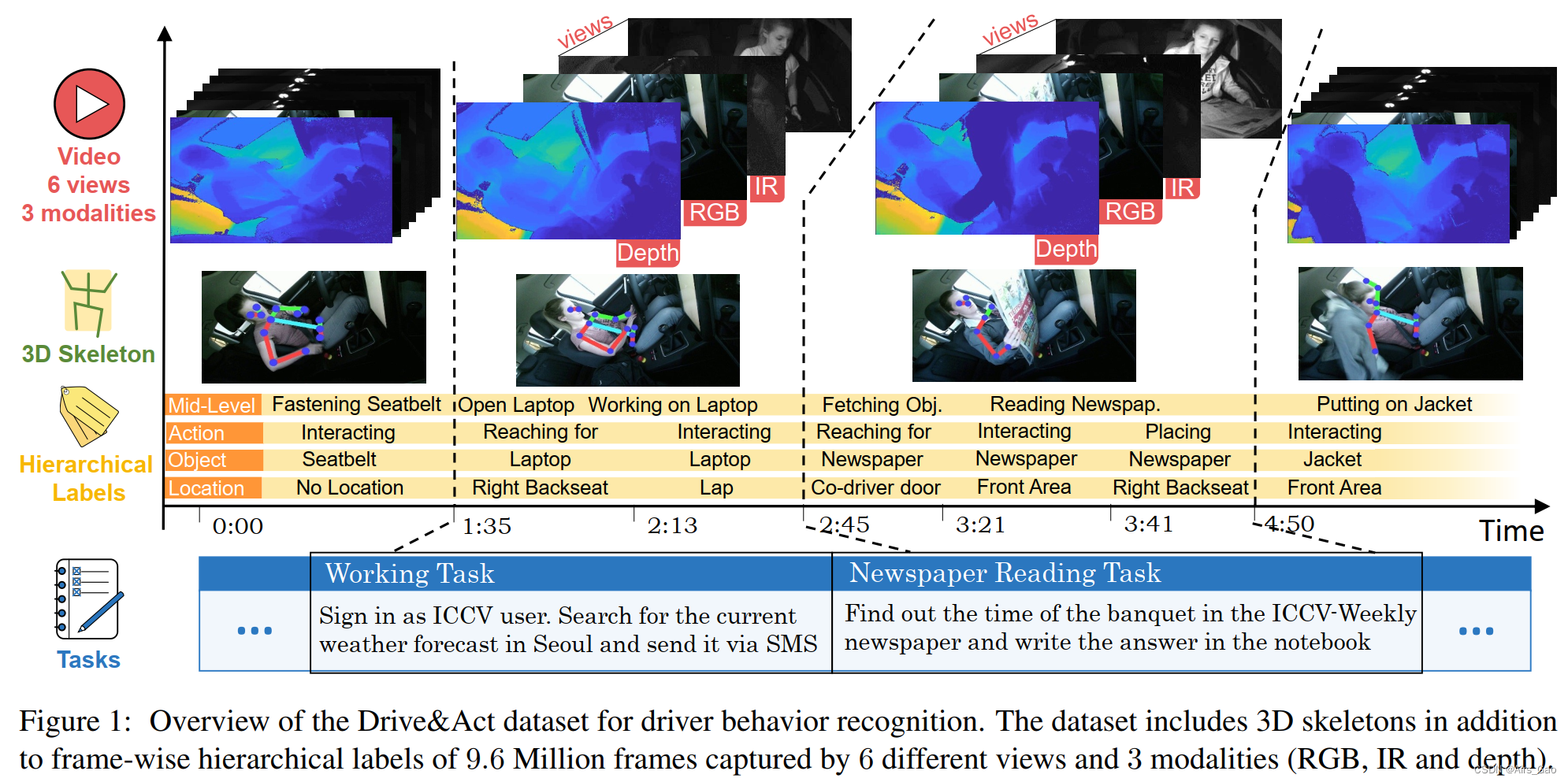
The first task involves getting into the car, making adjustments, starting manual driving, and switching to automatic mode after a few minutes.
All instructions below (e.g., use laptop to find current weather forecast and report via SMS), are given in random order on the installed tablet.
While most tasks were completed while on autopilot, four unexpected takeover requests were triggered during each session.
Therefore, this journey takes at least a minute by hand. While the sequence of coarse tasks is explicitly given, the exact manner in which they are performed (i.e., fine-grained activities) is left to the agent. - Fifteen people , 4 women and 11 men, participated in data collection. To promote diversity, we selected participants with different heights and weights, different driving styles, and familiarity with assistance systems and automation modes. All participants were recorded twice, resulting in 30 drives with an average duration of 24 minutes.
3.2 Recorded data flow

Sensor setup and video streaming
- Two types of static positioning cameras cover the vehicle cabin: 5 near-infrared cameras (NIR) (resolution 1280 × 1024 pixels, 30 Hz), 1 Microsoft Kinect for color acquisition (950 × 540 pixels, 15HZ), infrared (512 × 424 at 30 Hz) and depth data (512 × 424 at 30 Hz).
- The settings are specifically designed for realistic driving conditions such as low lighting.
- The goal is to free activity recognition models from traditional color inputs, thus favoring lightweight near-infrared cameras, which are also effective at night.
- Still, it's via the Kinect sensor, which is less practical in terms of size but popular in the research community.
3D Body Pose
- To determine a 3D upper body skeleton with 13 joints, we use OpenPose, a popular choice for 2D body pose estimation.
- The 3D pose is obtained by triangulating the 2D poses of 3 frontal views (upper right, upper front, upper left).
- Additional post-processing is applied to fill in missing joints using interpolation of adjacent frames.
3D Head Pose
- To obtain the driver's 3D head pose, we adopt the popular OpenFace neural architecture.
- Since this model has significant difficulty with head rotation, we determined the head pose for all views except the rear camera.
- For each frame, only a subset of all cameras predict successful head rotation.
- From these candidates, we select the result of the camera with the most frontal view and convert it to world coordinates.
Interior Model
- We also provide car interior features based on 3D primitives that describe the driver's interaction with the surrounding environment.
- This representation includes location information of different storage spaces in the car (e.g. seats or footrests) and car controls (e.g. steering wheel, seat belts and gear levers), which has been successfully applied to driver observations in the past.
Activity Classes
- The recorded video frames are manually labeled by human annotators at three levels of abstraction, resulting in a total of 83 action classes .
- It targets high-level scenarios, fine-grained activities (preserving semantic meaning) and low-level atomic operation units (representing environment and object interactions).
Data Splits
- Since our goal is to rate generalization to new drivers, we only evaluate the model on people the classifier has not seen before.
- We randomly divide the dataset into 3 Splits based on the identity of the driver.
- For each Split, we use 10 subjects ' data for training, 2 subjects ' data for validation, and 3 drivers ' data for testing (i.e., 20, 4, and 6 driving sessions respectively).
- Since the annotated action durations vary, we divide each action segment into 3s or less and use them as samples in the benchmark.
- Evaluation scripts are provided to facilitate comparison of results.
4. Hierarchical vocabulary of driver actions
-
To fully represent real driving situations, we conducted a comprehensive review of secondary tasks during human driving using three types of sources:
(1) driver interviews, (2) police review of accidents, (3) natural car Research. -
Key factors in selecting in-car scenes are the frequency of activities involved in driving and the impact of the behavior on the driver's attention (e.g., by increasing the chance of an accident).
-
Results showed that students were interested in categories such as talking on the phone, working on a laptop, searching for something, and identifying basic body movements (
such as reaching for something on the floor), while actions such as smoking were considered less useful. -
Some categories, such as sleep, were omitted due to technical feasibility.
-
Vocabulary related to driver activities is defined from eight aspects: eating, drinking, clothing and accessories, work, entertainment, entry and exit and vehicle adjustments, body movements, object manipulation and use of vehicle interior equipment .
-
Our final vocabulary included 83 activity tags at three levels of granularity , building a three-level hierarchy based on complexity and duration.
4.1 Scenario/Task
- The 12 tasks that our subjects had to complete at each stage (Section 3.1) form the first level of our hierarchy and are either typical scenarios when driving manually (e.g. eating and drinking) or are highly distributed Attention scenarios, which are becoming common with increased automation (e.g. using a laptop).
- Figure 4 shows a frame rate analysis of the scene, showing that our subjects spent most of their time (23%) on entertainment tasks (i.e. watching videos) and spent the least amount of time driving manually after receiving a takeover request.
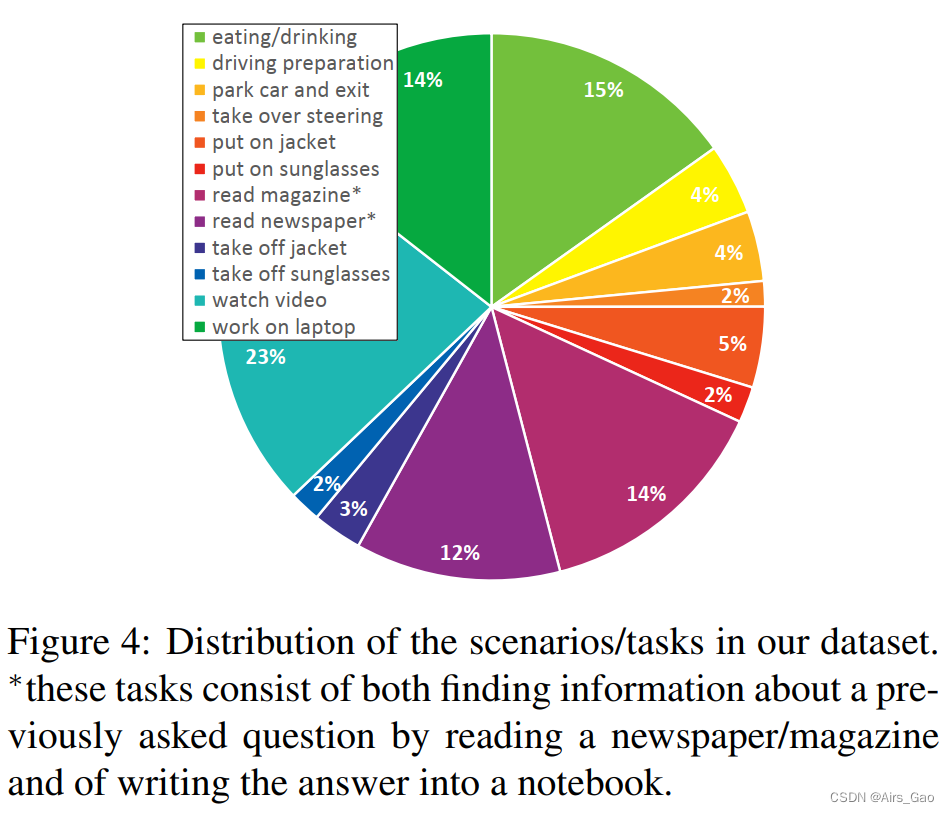
- The takeover scene was special because the subject was unexpectedly asked to interrupt what he was doing, take over and switch to manual driving.
- Analyzing responses to such events (e.g. in relation to previous activity or an individual's age) is a potential safety-related research direction.
4.2 Fine-grained Activities
- The second level represents fine-grained Activities, which breaks down scenarios/tasks into 34 concise categories.
- Second-level classes retain explicit semantics compared to the upcoming third-level atomic action units.
- These fine-grained activities alternate freely within the scene, i.e. the driver is not told how to perform the task in detail.
- Of course, there is a strong causal relationship between different levels of abstraction, since combinatorial behavior often consists of multiple simpler operations.
- A key challenge in recognition at this level is the simplicity of categories, much like we distinguish between closing a bottle and opening a bottle, or between eating and preparing food.
- We believe that this detailed distinction is important for applications because the coarse components of a scene (i.e., vehicle cabins or loose body positions) often remain similar, and relevant class differences occur at a smaller scale than traditional action recognition benchmarks. .
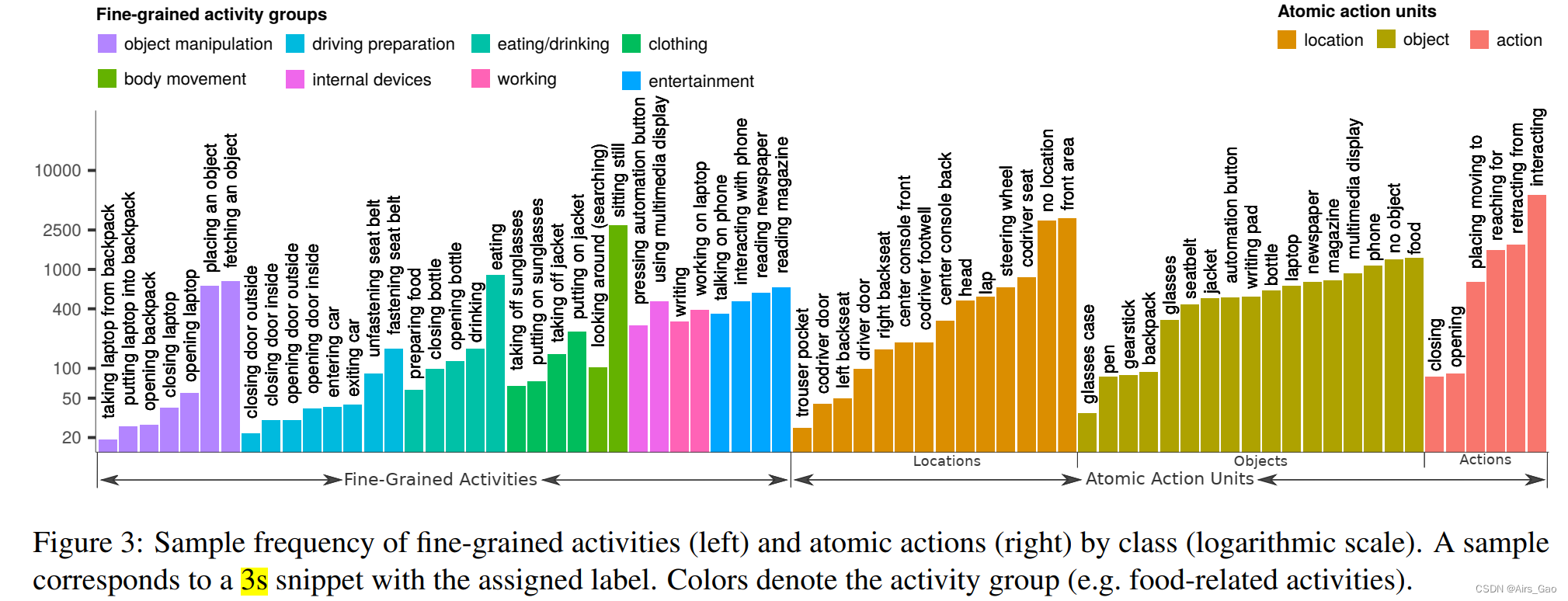
- Due to such detailed annotation, the frequency of individual classes is variable, as shown in Figure 3, which shows the analysis of class distribution.
- Our dataset has an average of 303 samples per category, with taking a laptop from a backpack being the least common (19 samples) and sitting still being the most common category (2797 samples).
- Although we use 3s as our sample (Section 3.3), the duration of a complete segment varies from activity to activity.
4.3 Atomic Action Units
- Annotations for Atomic Action Units describe the lowest level of abstraction, the basic driver interaction with the environment.
- Action units are detached from long-term semantic meaning and can be seen as building blocks of complex activities at the previous level.
- We define an atomic action unit as a triplet of action , object , and position .
- We cover 5 types of actions (e.g. reaching out), 17 object classes (e.g. writing pad) and 14 position annotations (e.g. co-pilot footwell), the distribution of which is shown in Figure 3.
- In total, 372 possible combinations of actions, objects, and locations were captured in our dataset.
4.4 Additional Annotations
- We further provide dense annotations of the driving environment, indicating whether the driver is in autonomous mode or driving with left, right or both hands.
- We also include timestamps of takeover requests and simulator internal signals such as steering wheel angle.
5. Action recognition model in autonomous driving scenarios
-
To better understand the performance of state-of-the-art algorithms on our dataset, we benchmarked various methods and their combinations.
-
We divide these algorithms into two categories:
(1) methods based on body pose and 3D features;
(2) end-to-end methods based on convolutional neural networks (CNN). -
While CNN-based models are often the frontrunners for traditional action recognition datasets, they handle very high-dimensional inputs and are more sensitive to the amount of training data and domain changes (such as camera view changes).
5.1 End-To-End model
- In image-based action recognition, the model operates directly on the video data, that is, no intermediate representation is clearly defined, but is learned through CNN.
- Next, we describe three prominent CNN-based action recognition architectures, which we adopted for our task.
(1) C3D
The C3D model is the first widely used CNN to utilize 3D convolution for action recognition. C3D consists of 8 convolutional layers (3 × 3 × 3 kernels) and 5 pooling layers, followed by two fully connected layers.
(2) Inflated 3D ConvNet
Currently, the most advanced action recognition technology is Inflated 3D architecture ( I3D ). The architecture builds on the Inception-v1 network by extending 2D filters with an additional temporal dimension.
(3) P3D ResNet
is different from previous models. The P3D ResNet architecture simulates 3D volumes using a 3 × 3 × 3 kernel by combining filters in the spatial domain (i.e. 3 × 3 × 1) with filters in the time dimension. product (i.e. 1 × 1 × 3). In addition, P3D ResNet utilizes residual connections due to their effectiveness in the field of action recognition.
5.2 Human body posture and car internal structure
- Compared with mid-level feature maps generated based on CNN architecture, 3D body pose is able to provide informative clues about the driver's current activity while still maintaining human interpretability.
- Therefore, we adopt a skeleton-based approach that combines spatial flow and temporal flow to jointly model body dynamics and skeletal spatial configuration. Each stream consists of a stack of two layers of LSTM units, followed by a softmax fully connected layer.
- This architecture has been used for driver action recognition by Martin et al ., who extended the network with car interior information into a three-stream architecture.
- Describe the distribution of the three streams respectively:
(1) Temporal Stream : In order to encode the motion dynamics of the driver's body, in each time step, we unite all 13 joints through connections, and in the first part of the architecture Use the generated vector in the stream.
(2) Spatial Stream : The second stream encodes the spatial dependence of joints by providing a representation of a single joint to the recurrent network at each step. To flatten the graph-based body pose representation, a traversal scheme is used.
(3) Car-Interior Stream : Since the position of objects in the scene can provide important clues to the current action, we also provide the model with a representation of the car’s interior. To exploit this data, we determined the distance of the hands and heads to each object surface provided in the internal model of the dataset. This helps the network learn the relationship between the interior of the car and the actions it performs.
(4) Combined Models : Combine spatio-temporal flows through weighted post-fusion. This model is called Two-Stream below . Then add Car-Interior as the extended model of the third stream, which is called Three-Stream below .
6. Benchmarks and experimental results
- In the current version of the benchmark, we focus on fine-grained classification of driver behavior and extend it to multi-modal and cross-view settings.
- Given an action clip of 3 seconds or less (in the case of shorter events), our goal is to assign the correct activity label.
- We follow standard practice and adopt average per-class accuracy by using the average of the top-1 recognition rates for each class .
- Note that the random baseline is annotation level specific, varying between 0.31% and 16.67%.
6.1 Driver action recognition
- We evaluate our model separately for each hierarchy level:
12 scenarios/tasks ( first level ),
34 fine-grained activities ( second level ),
372 possible combinations of {action, Object, Location} triples Atomic operating unit ( third level ). Because the number of triples is very large, we also report the performance of correctly classifying actions, objects and locations separately (6, 17 and 14 categories).
(1) Fine-grained activities
- In Table 2, we compare a number of published methods for identifying fine-grained activities, including three CNN-based methods and four body- and internal-representation-based models.
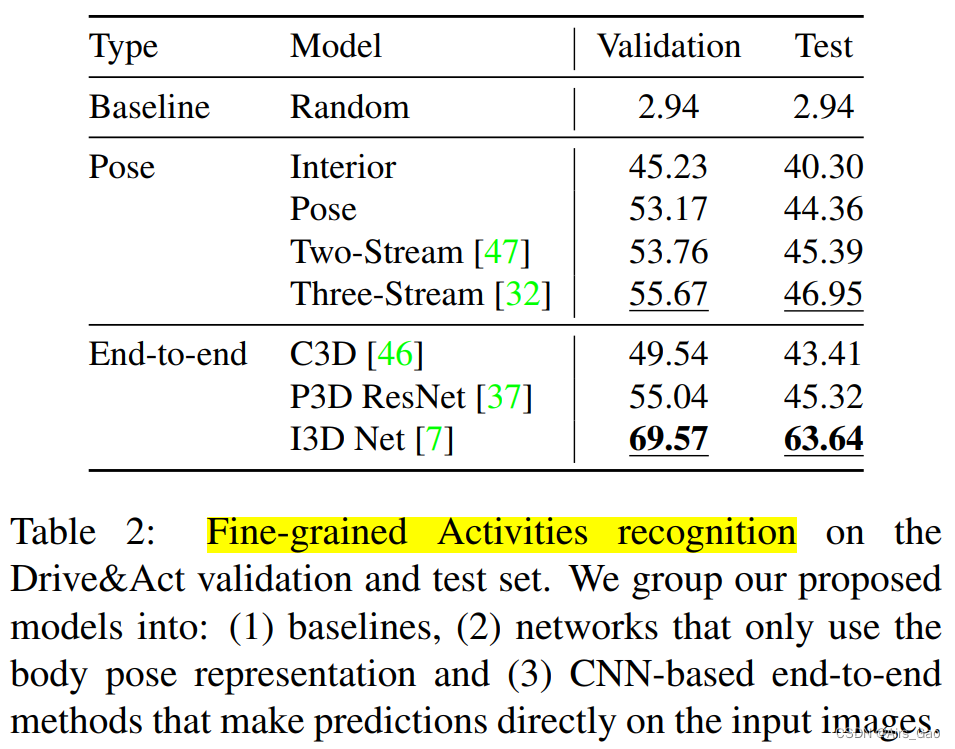
(2) Classification of atomic action units
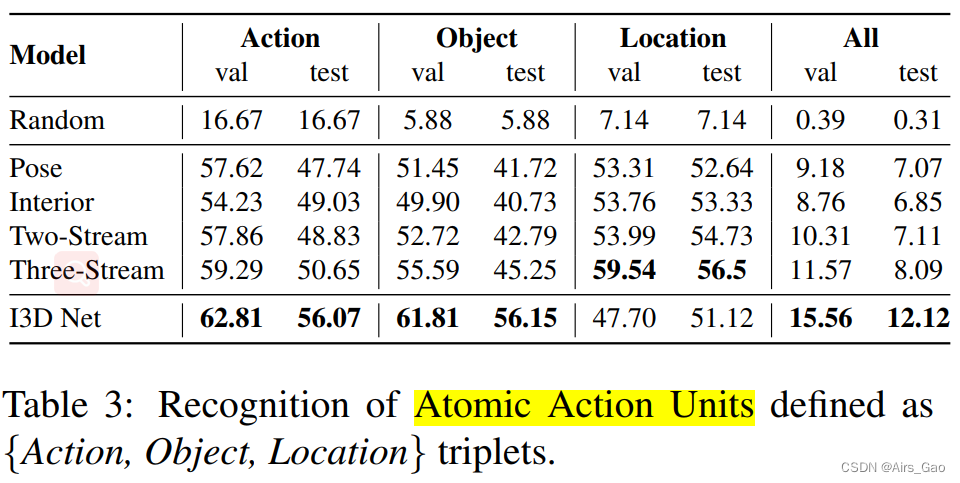
- Table 3 reports the results of the atomic operation unit classification, which shows the {action, Object, Location} triplet individually, as well as, the triplet value combination for overall accuracy.
(3) Scene recognition/task
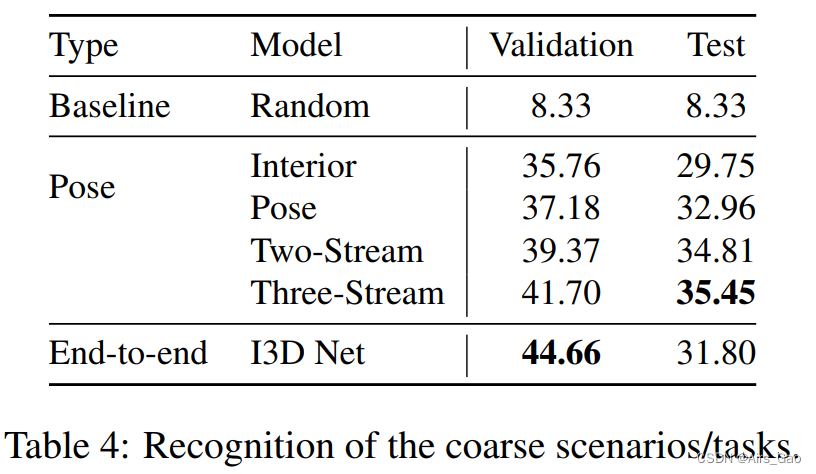
- Table 4 shows the results of task classification. Methods based on body posture work better, but the overall recognition rate is lower than other levels.
6.2 Multi-view and multi-modal action recognition
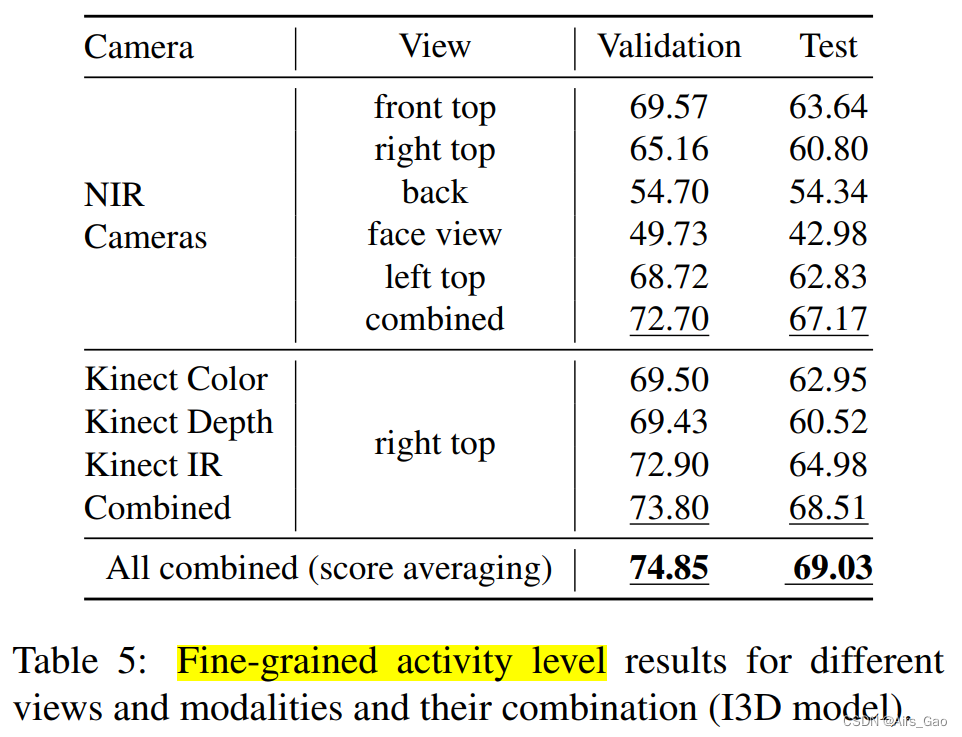
- In Table 5, we report the average of output scores via Softmax based on CNN, I3D methods for individual views and modalities and their combinations.
- As expected, recognition success correlates with general scene visibility (see the area covered by the camera in Figure 2).
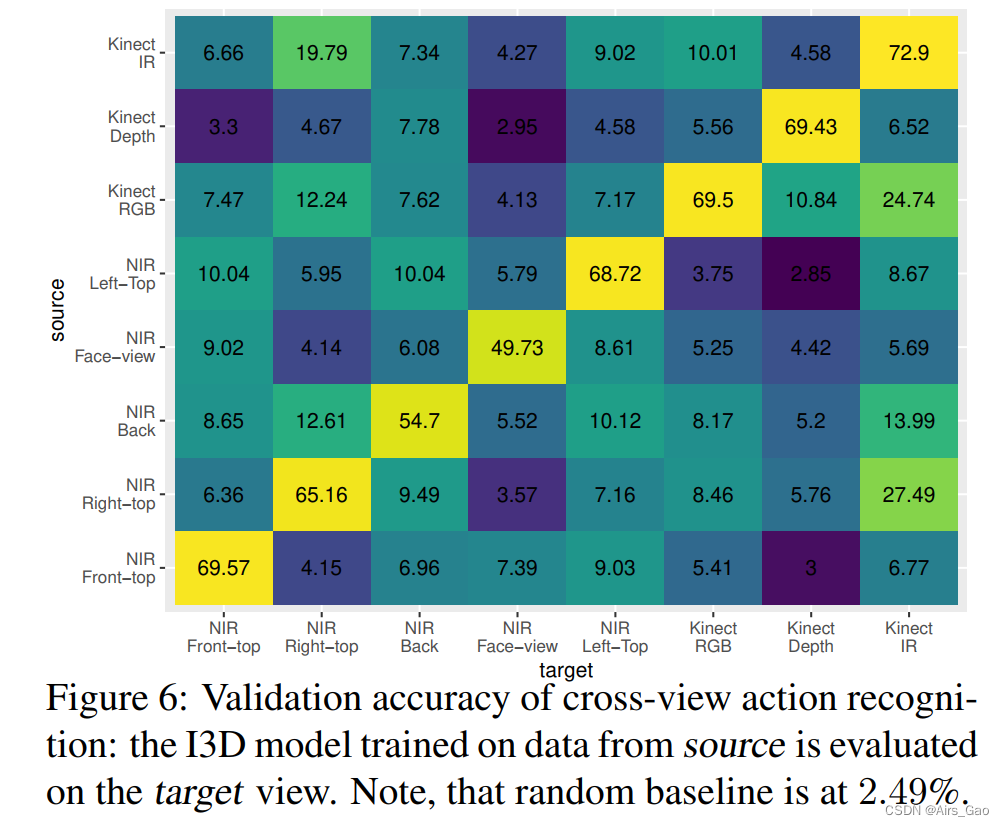
6.3 Cross-View motion recognition
- Our next area of investigation is the cross-view and cross-modal setting, where we evaluate the best performance of our end-to-end approach in views not seen during training (shown in Figure 6).
- Cross-view recognition is a very difficult task and performance degrades significantly. Nonetheless, in most cases the model achieves better results than the random baseline.