Article directory
0. Basic theory
Before explaining the specific solution, we need to understand some basic theoretical knowledge involved in distributed transactions.
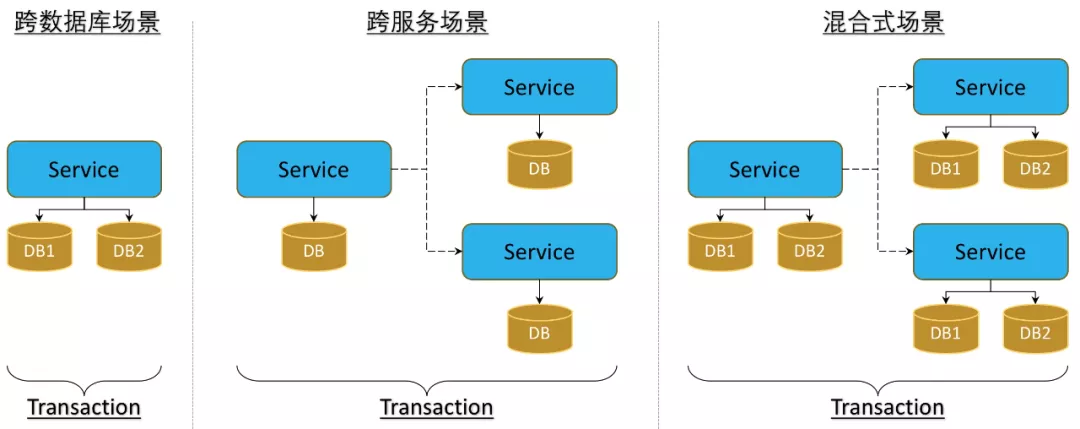
Distributed transactions mean that transaction participants, transaction-supporting servers, resource servers, and transaction managers are located on different nodes in different distributed systems. For example, in large-scale e-commerce systems, the ordering interface usually deducts inventory, discounts, and generates order IDs. The order service, inventory, discounts, and order IDs are all different services. The success of the ordering interface depends not only on Depends on local db operations and relies on the results of third-party systems. At this time, distributed transactions ensure that these operations either all succeed or all fail. Essentially, distributed transactions are to ensure data consistency in different databases.
consistency principle
-
Strong consistency: It is the most stringent consistency model, requiring all nodes in the distributed system to obtain the latest written data for the same data no matter when reading it at any time. That is to say, when the update operation is completed, any subsequent read operations entering the system will return this value. For example, in a distributed database, after a write operation is completed, all read operations should return the latest data.
-
Weak consistency: Compared with strong consistency, weak consistency does not require the latest updates to be seen on all nodes immediately, thus allowing transient data inconsistencies. As long as the system can ultimately ensure data consistency when there are no new update operations, weak consistency is satisfied. The advantage of weak consistency is that it improves the concurrency performance of the system, but the disadvantage is that expired data may be read.
-
Eventual consistency: Eventual consistency is a special case of weak consistency. Its core idea is that the system will ensure that in the absence of subsequent updates, all data copies will eventually reach a consistent state. That is, after an infinite length of time, all replicas will reach consensus. In this consistency model, when no new update operations occur, the system will gradually try to repair inconsistent copies until all copies are consistent. For example, the DNS system adopts the eventual consistency model.
CAP principles
The CAP principle is a basic theoretical model for distributed system design, in which C, A, and P respectively represent:
-
C (Consistency): Consistency, all nodes should see the same data at the same time.
-
A (Availability): Availability, ensuring that every request can get a response, but not guaranteeing that every request can get the latest data.
-
P (Partition tolerance): Partition tolerance, that is, the system can still ensure external consistency and availability even if the network is partitioned (network disconnection).
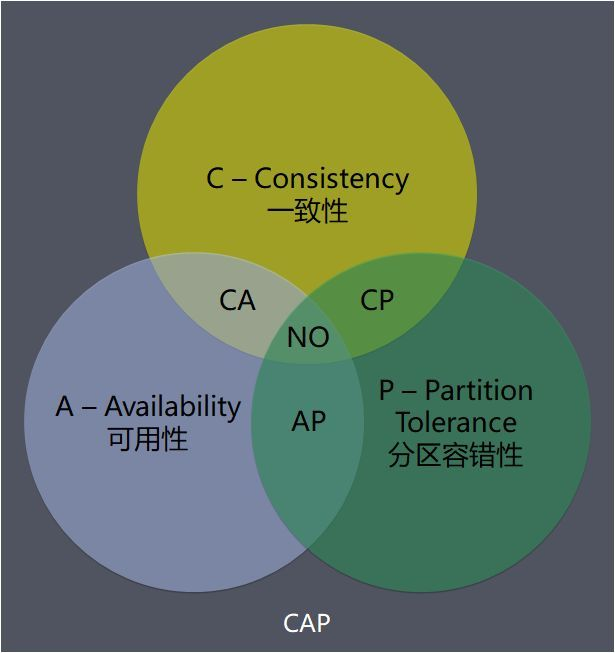
The CAP principle points out that for a distributed system, it is impossible to meet the three requirements C, A, and P at the same time, and it can only meet two of them at most. The mutual exclusivity of these three characteristics constitutes a basic trade-off framework for designing and selecting distributed systems. For example, if you design a system that meets both consistency and availability, when encountering partition fault tolerance, some nodes may become unavailable, so partition fault tolerance cannot be met.
Flexible affairs
Flexible transactions are a more flexible transaction processing mechanism than traditional transactions (ACID transactions). The ACID transaction model may not meet the needs well in some distributed systems or big data applications because it requires all operations in an operation sequence to succeed before a transaction can be committed, which may be difficult in large-scale and distributed environments. accomplish. Flexible transactions improve availability and performance by reducing consistency and isolation requirements.
Flexible transactions in practical applications often adopt the BASE (Basically Available, Soft State, Eventually Consistent) theory, which means basically available, soft state, and eventual consistency. In this model, the system allows data inconsistency over a period of time as long as the final data can reach a consistent state.
For example, if a flash sale event on an e-commerce platform uses the traditional ACID transaction processing model, the system may crash due to the large amount of concurrency. If flexible transactions are used, the system can first return information about a successful order after the user places an order, and the inventory deduction can be processed later. This way, the system maintains basic availability even under heavy concurrency, while inventory consistency can be guaranteed later via background processes.
BASE theory
BASE theory is a theoretical model proposed to solve the problem that the three characteristics of the CAP principle cannot be satisfied at the same time. BASE is the acronym for the phrases Basically Available, Soft state, and Eventually consistent.
-
Basically Available: When a system failure occurs, partial availability is allowed to be lost, but the system will not become completely unavailable. For example, response times may be slower, or some features may not be available, but there will never be a situation where the entire system crashes.
-
Soft state: The state of the system can be inconsistent for a period of time, or the system can be in an intermediate state, and this intermediate state can be used for system availability and consistency.
-
Eventually consistent: The system guarantees that the data will eventually reach a consistent state after a period of time without new data updates. During this period, all copies of the system's data may become temporarily inconsistent.
The essence of BASE theory is to adopt eventual consistency in order to solve the problems caused by the strong consistency of relational databases and obtain high availability of the system by sacrificing real-time performance. This theory is suitable for systems that do not have very strict requirements on data consistency, such as product inventory on e-commerce websites.
Idempotent operations
An idempotent operation means that no matter how many times an operation is performed, the result is always the same. This concept is very important in fields such as computer science, distributed systems, and network protocols.
For example, an operation to delete a file is idempotent because no matter how many times you perform the delete operation, the file will always be deleted and the result will always be the same. Similarly, the HTTP GET method is also idempotent, because no matter how many times you retrieve it, the resource status returned by the server is always the same.
It is important to note that idempotence does not mean that the operation has no effect. For example, the above-mentioned file deletion operation results in the file being deleted, which has practical effects. Idempotence emphasizes that no matter how many times the operation is performed, the result is the same.
1. Basic introduction
1.1. Definition of distributed transactions
Distributed transactions refer to transactions completed collaboratively by two or more nodes in a distributed system. Since these nodes may be physically distributed on different machines or even on the cloud, coordination and communication are required among all relevant nodes to ensure the correct execution of transactions. In a distributed transaction, all operations either succeed or fail. This is the atomicity of distributed transactions.
1.2. Distributed transaction usage scenarios
Distributed transactions are widely used in various scenarios that require cross-system or cross-database operations, such as e-commerce, finance, logistics, etc. For example, in online shopping, different systems may be involved in user ordering, payment, warehouse delivery, logistics and distribution. Only when all links are successful can the entire order be completed.
The importance of distributed transactions is mainly reflected in its ability to ensure data consistency. In a distributed environment, the status of each node needs to be consistent, otherwise it may lead to data inconsistency, business logic errors and other problems. Distributed transactions ensure that operations between different nodes can achieve consistent results through transaction consistency and atomicity.
In modern Internet applications, distributed transactions are used in many scenarios. The following are two specific examples:
-
E-commerce shopping process, in the e-commerce platform, the user's shopping operation may involve multiple systems such as inventory system, order system, payment system, etc. These systems may be deployed on different servers, forming a distributed environment. In this case, if the user places an order to purchase a product, then this operation requires reducing the quantity of the product in the inventory system, creating a new order in the order system, and performing payment operations in the payment system. These three operations need to form a distributed transaction, either all succeed or all fail. Otherwise, there may be data inconsistencies, such as inventory reduction, but the order is not created successfully, or the order is created successfully, but the payment fails.
-
Bank transfer operations usually involve two accounts, one is the payment account and the other is the collection account. The two accounts may be on different databases or servers. The transfer operation requires the corresponding amount to be reduced on the payment account and the corresponding amount to be added to the receiving account. These two operations need to form a distributed transaction, either all succeed or all fail. Otherwise, there may be data inconsistencies, such as the amount in the payment account decreasing, but the amount in the receiving account not increasing.
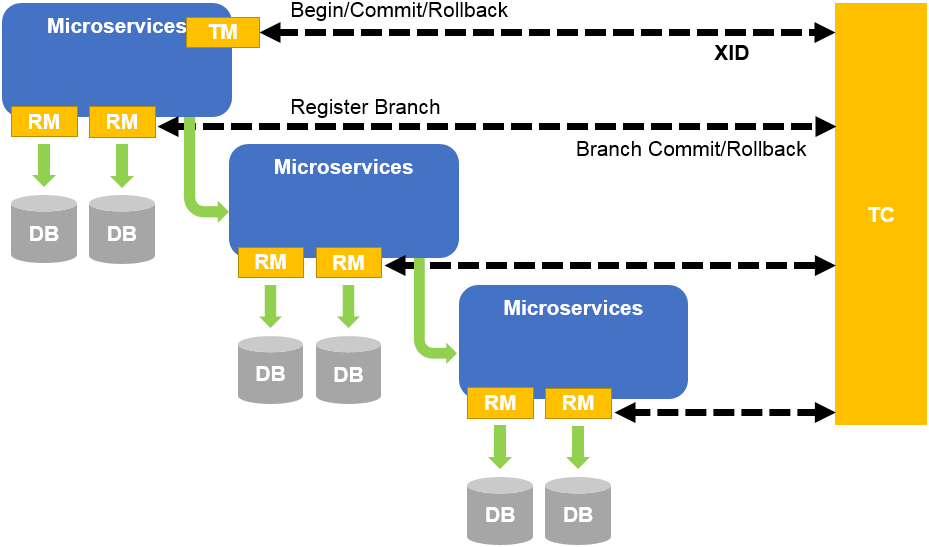
2. How distributed transactions work
Mainstream implementation solutions for distributed transaction implementation generally require the following subjects, but this is not a standard. In some simplified distributed transaction implementations, transaction participants and resource managers may be merged into one subject. 比如在微服务架构下的Saga事务模式,服务本身就是事务的参与者,同时也管理着自己的数据库资源。也就是说,服务本身既是事务参与者,又是资源管理器.
In the Saga transaction mode, each service performs local transactions and publishes events to other services. If a service's local transaction fails, the service publishes a compensation event to compensate for all previous successful transactions. In this mode, transaction participants and resource managers are merged into one subject, which is completed by the service itself.
Let’s introduce the responsibilities of several subjects in distributed transactions.
Transaction Coordinator: The transaction coordinator is responsible for coordinating and managing the execution of distributed transactions. It is mainly responsible for the start, submission and termination of transactions.
Transaction Participants: Transaction participants perform the actual operations of distributed transactions. They execute their own local transactions within a distributed transaction and decide to commit or rollback the transaction based on instructions from the transaction coordinator.
Resource Manager: The resource manager is responsible for managing and controlling resources accessed and operated by distributed transactions, such as databases, message queues, etc.
Communication System: The communication system is responsible for communication between the coordinator and participants, including request sending and response reception.
Log System: The log system is used to record the operation process of distributed transactions, including transaction start, end, commit and rollback information, to provide support for fault recovery and transaction consistency.
Lock Manager: The lock manager is responsible for managing and controlling concurrent access to resources in a distributed environment to ensure data consistency and transaction isolation.
In addition to solving the problems of transaction submission and rollback, the implementation process of distributed transactions must also consider the following two issues
- Concurrency control
Concurrency control is mainly used to solve data inconsistency problems that may be caused by concurrent operations. There are two common methods: one is a lock-based method, such as exclusive lock, shared lock, etc.; the other is a timestamp-based method, which determines the number of transactions by assigning a globally unique timestamp to each transaction. execution sequence.
- Deadlock handling
In distributed systems, the deadlock problem is more complex. There are usually two methods for deadlock detection: one is a timeout-based method, if a transaction cannot obtain the lock for a long time, a deadlock is considered to have occurred; the other is a graph-based method, which combines the transaction and its requested resources. Treat it as nodes and edges in the graph, and determine whether there is a deadlock by detecting whether there is a cycle in the graph. The method usually used to relieve deadlock is to abort or roll back part of the transaction to release the locked resources. There are usually several strategies for choosing which transactions to abort or roll back, such as aborting transactions with the longest or shortest running time first, aborting transactions with the largest or smallest amount of modified data first, aborting transactions with the lowest priority first, etc.
3. Distributed transaction protocol
3.1. Two-Phase Commit Protocol (2PC)
The two-phase commit protocol is a classic distributed transaction commit protocol. It is divided into two phases: preparation phase and submission phase. In the preparation phase, the coordinator asks all participants whether they are ready to commit the transaction; in the commit phase, if all participants indicate they are ready, the coordinator will notify them to submit the transaction, otherwise they will be notified to terminate the transaction.

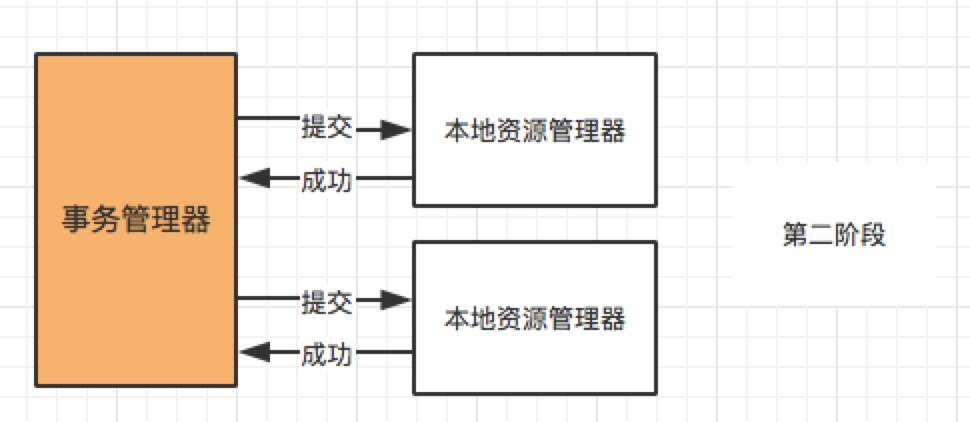
3.2. Three-Phase Commitment Protocol (3PC)
The three-phase commit protocol is an improved version of the two-phase commit protocol, in order to solve the blocking problem in the two-phase commit protocol. In addition to the preparation phase and submission phase in the two-phase submission protocol, a pre-commitment phase is also added. In the pre-submission phase, the coordinator asks all participants whether they can submit. Only when all participants agree to submit, the preparation phase and submission phase are entered.
3.3. Paxos protocol
The Paxos protocol is mainly used to solve the consensus problem in distributed systems, that is, in a system composed of multiple nodes, how to make these nodes agree on a value. The Paxos protocol is widely used in many distributed systems and databases.
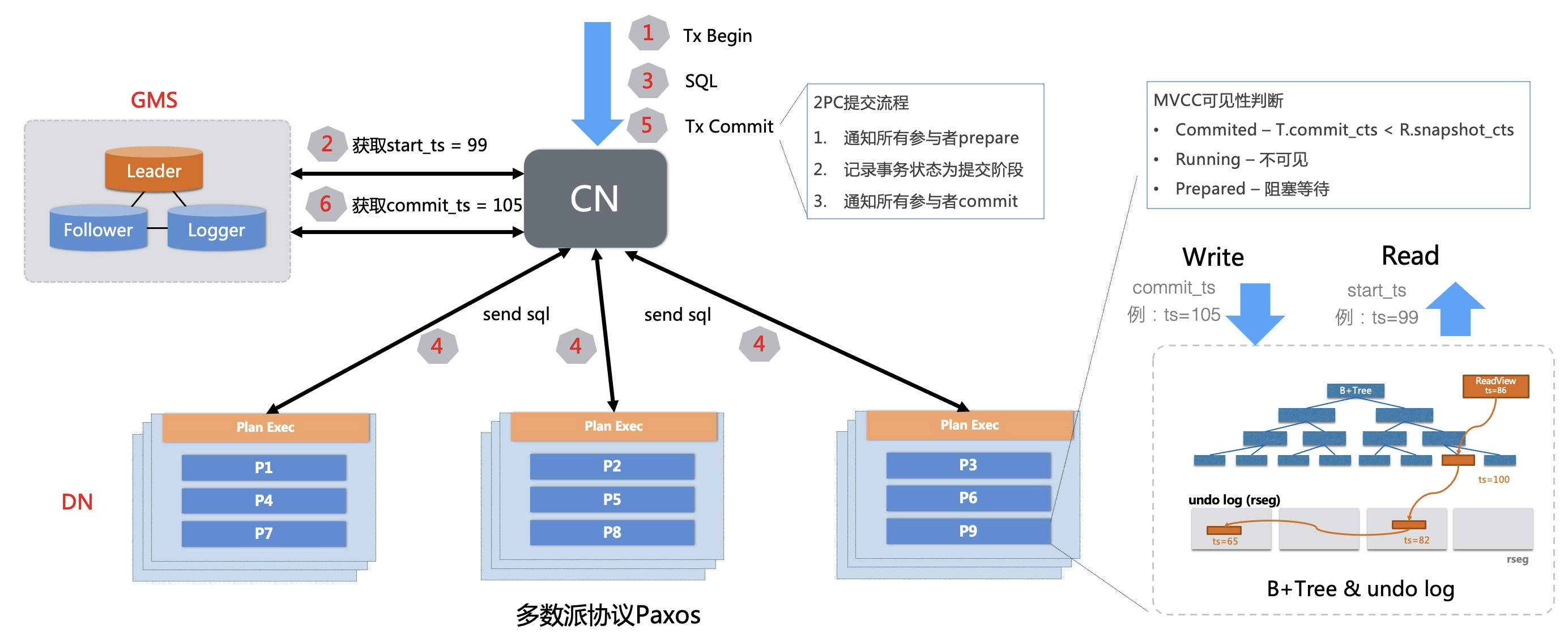
使用PolarDB举例。通过引入中心授时服务(TSO),结合多版本并发控制(MVCC),确保读取到一致的快照,而不会读到事务的中间状态。如下图所示,提交事务时,计算节点(CN)执行事务时从TSO获取到时间戳,随着数据一同提交到存储节点(DN)多版本存储引擎上,CN通过读取快照时间戳去DN上读取相应版本的数据.
3.4. Raft protocol
It is based on the Raft protocol to achieve transaction consistency. The Raft protocol is designed to solve the consensus problem in distributed systems. It is an easier-to-understand and implement alternative to the Paxos protocol. The Raft protocol selects a leader through elections, and the leader determines and maintains the state of the system. I actually have a rough understanding of the specific implementation, so I won’t go into it here. We’ll just talk about which databases use the raft protocol to achieve distributed consistency.
There are many distributed systems based on the Raft protocol to achieve transaction consistency.
TiDB: TiDB, which became popular some time ago, is a distributed SQL database developed by PingCAP. Its distributed transaction model is based on Google's Percolator model and uses the Raft protocol for data replication.
CockroachDB: A highly scalable, transaction-enabled distributed SQL database that uses the Raft protocol to ensure distributed consistency.
4. Distributed transaction implementation technology
4.1. XA interface
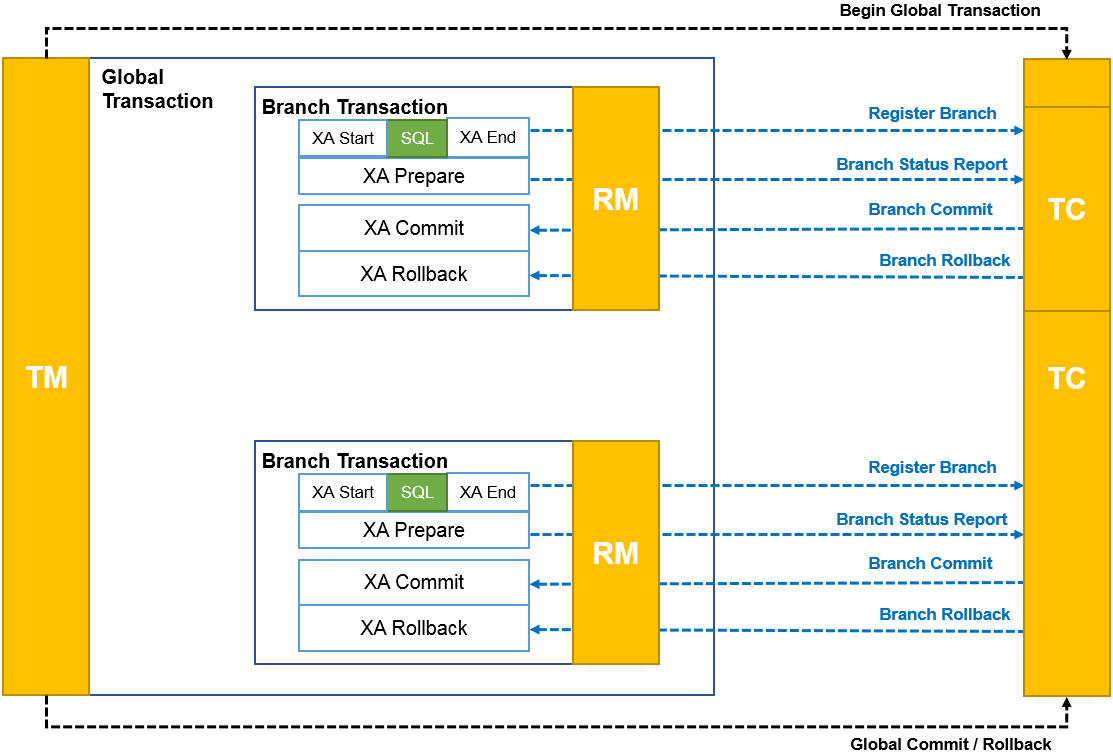
The XA interface is a distributed transaction standard interface proposed by X/Open. It mainly defines the interactive interface between the coordinator and participants in the two-phase submission protocol. In a distributed system, if a transaction needs to operate across multiple resources (such as databases, message queues, etc.), these resources can be coordinated through the XA interface to implement distributed transactions.
4.2. TCC(Try-Confirm-Cancel)
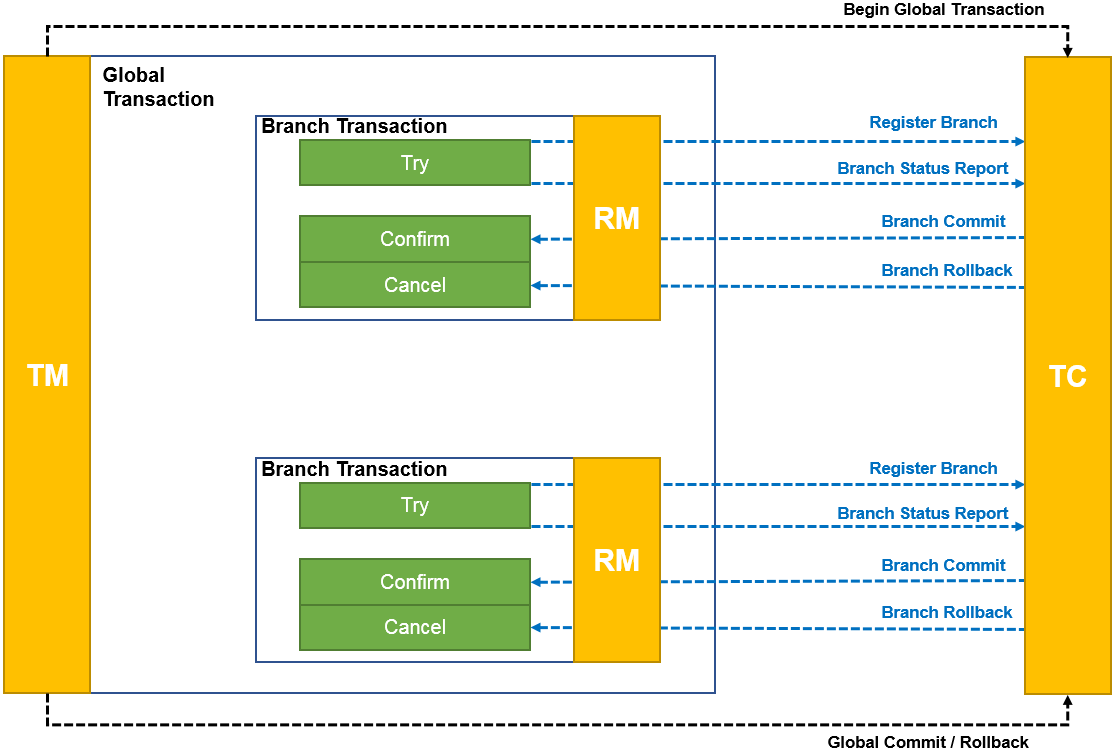
TCC is an application-level distributed transaction solution, which is divided into Try phase, Confirm phase and Cancel phase. In the Try phase, try to execute the transaction. If all participants are successful, enter the Confirm phase; in the Confirm phase, confirm the execution of the transaction. If all participants confirm, the transaction is successful; otherwise, enter the Cancel phase, cancel the transaction operation, and the rollback has been executed. operation.
4.3. Saga
Saga refers to a long-lived transaction, which consists of a series of sub-transactions, each of which can be submitted independently. If a certain stage in the Saga transaction fails, the previous sub-transaction will be executed in reverse by the compensating transaction, thereby rolling back the entire Saga transaction.
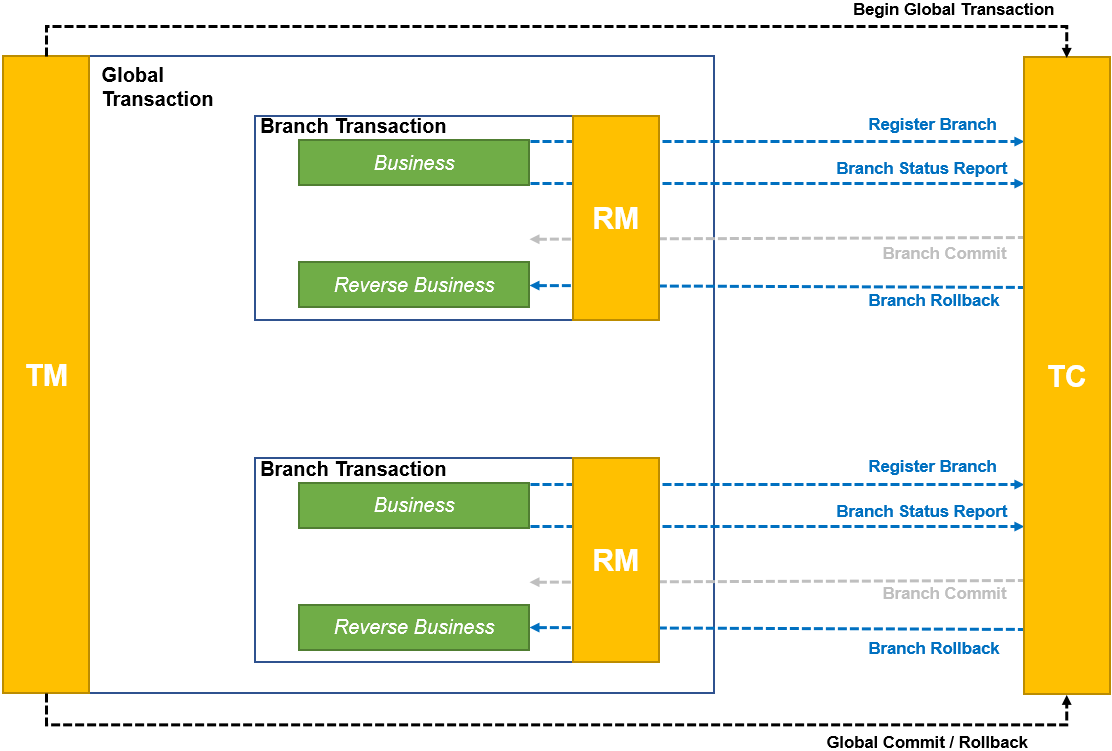
In the Saga pattern, a distributed transaction is decomposed into a series of sub-transactions, each of which can succeed or fail independently. Saga guarantees: If all sub-transactions succeed, then the entire transaction is successful; if any sub-transaction fails, then Saga starts a series of compensating operations (compensating transactions) to cancel the successful sub-transactions, so as to achieve the success of the entire transaction. eventual consistency.
The Saga distributed transaction model provides a new solution when there is no guarantee that all participants in the distributed system can commit or rollback at the same time. It is suitable for long-running transactions and allows participants to release resources during the transaction, thereby avoiding long-term locking of resources.
The core idea of Saga distributed transactions is to decompose a large transaction into a series of small transactions (local ACID transactions), and provide a corresponding compensation transaction for each small transaction. When a small transaction fails, Execute the compensation transactions corresponding to all successful small transactions to achieve the ultimate consistency of transactions in the distributed system.
The Saga distributed transaction model is widely used in microservice architecture, because in microservice architecture, each service may be deployed on different servers, and each service has its own independent database, which makes microservices Implementing distributed transactions in the architecture becomes particularly difficult. The Saga distributed transaction model provides an effective solution.
In the Saga transaction model, we use Java pseudocode to write an example to understand .
executeSaga()The methods are executed separately . If any of the three sub-transactions is abnormal during the execution process, the corresponding rollback logic will be executed to ensure that Consistency throughout the process.placeOrder()deductPayment()issuePoints()
public class OrderProcessingSaga {
// 下单子事务
public void placeOrder() {
try {
// 执行下订单操作的逻辑
} catch (Exception e) {
// 如果下订单操作失败,回滚之前的操作
rollbackPlaceOrder();
throw e;
}
}
// 扣款子事务
public void deductPayment() {
try {
// 执行扣款操作的逻辑
} catch (Exception e) {
// 如果扣款操作失败, 回滚之前的操作
rollbackDeductPayment();
throw e;
}
}
// 发放积分子事务
public void issuePoints() {
try {
// 执行发放积分操作的逻辑
} catch (Exception e) {
// 如果发放积分操作失败,回滚之前的操作
rollbackIssuePoints();
throw e;
}
}
// 下订单操作的回滚逻辑
public void rollbackPlaceOrder() {
// 执行下订单操作的回滚逻辑
}
// 扣款操作的回滚逻辑
public void rollbackDeductPayment() {
// 执行扣款操作的回滚逻辑
}
// 发放积分操作的回滚逻辑
public void rollbackIssuePoints() {
// 执行发放积分操作的回滚逻辑
}
// Saga事务执行方法
public void executeSaga() {
placeOrder();
deductPayment();
issuePoints();
}
}
4.4. Flexible transactions
The flexible transaction model is distinguished from the traditional distributed transaction model ACID by BASE (Basically Available, Soft state, Eventually consistent). It only requests final agreement during the settlement phase. It can also customize the final consensus solution according to business needs to adapt to various businesses. Scenarios, such as best-effort notification type, TCC type, compensable type and asynchronous guaranteed type, etc.
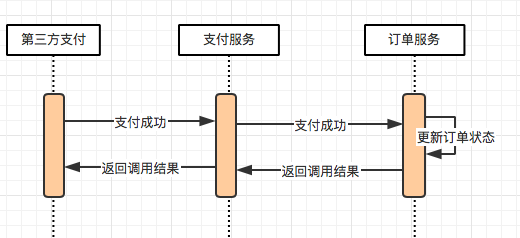
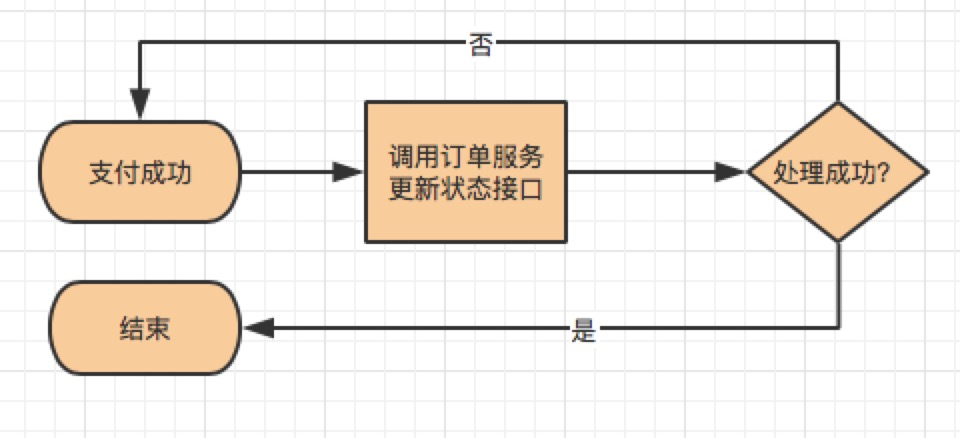
Best Effort Notification
The most common scenario of best effort notification is payment callback. After the payment service receives the payment success notification from the third-party service, it first updates the order payment status in its own library, and then synchronously notifies the order service that the payment is successful. If this synchronization notification fails, the order service interface will be called again and again through asynchronous scripts.
5. Practical applications of distributed transactions
5.1. E-commerce system
In the e-commerce system, the behavior of users placing orders to purchase goods involves multiple subsystems such as inventory management, order management, and payment systems. For example, after a user places an order, the corresponding quantity of goods needs to be deducted from inventory, an order is generated, and a payment record is generated in the payment system. These subsystems may be distributed on different servers, and operating them requires the use of distributed transactions to ensure that when abnormal situations occur, such as users canceling orders, data consistency can be achieved, inventory quantities can be rolled back, and orders can be deleted. and payment records.
5.2. Financial (payment) system
In financial systems, it involves the transfer of funds between multiple accounts. For example, a transfer operation requires debiting money from one account and adding money to another account. These two operations need to be performed in different databases, and it must be ensured that both operations succeed or both fail to ensure the consistency of funds. This requires the use of distributed transactions.
5.3. Logistics system
The logistics system includes multiple subsystems such as order management, inventory management, and distribution management. For example, when an order is placed and shipped, it needs to go through multiple steps such as inventory deduction, order generation, and delivery information generation. These steps may be distributed on different servers, and distributed transactions need to be used to ensure data consistency. sex.
6. Reference documentation
-
Introduction to distributed transactions https://zhangxiongbiao.com/post/2019-08-25/%E5%88%86%E5%B8%83%E5%BC%8F%E4%BA%8B%E5%8A%A1 .html
-
Distributed transactions http://www.cnblogs.com/savorboard/p/distributed-system-transaction-consistency.html