Although the pre-training data of Llama2 has doubled compared to the first generation LLaMA, the proportion of Chinese pre-training data is still very small, accounting for only 0.13%, which also leads to the weak Chinese ability of the original Llama2. In order to improve the Chinese ability of the model, two paths, fine-tuning and pre-training, can be used, among which:
- Fine-tuning requires less computing resources and can quickly implement a prototype of Chinese Llama. But the shortcomings are also obvious. It can only stimulate the existing Chinese capabilities of the base model. Since Llama2 has less Chinese training data, the capabilities it can stimulate are also limited, and it treats the symptoms but not the root cause.
- Pre-training based on large-scale Chinese corpus is expensive and requires not only large-scale and high-quality Chinese data, but also large-scale computing resources. But the advantage is also obvious, that is, it can optimize Chinese capabilities from the bottom of the model, truly achieve the root cause of the problem, and inject powerful Chinese capabilities into large models from the core.
The following is a comparison from seven aspects: main goal, training data, weight update, data conversion and preprocessing, task type, sample application and typical scenarios, as shown below (ChatGPT):
| feature | Pretraining | Continuous Pretraining | Fine-tuning | Post-Pretrain (after pre-training) |
|---|---|---|---|---|
| main target | Learn universal representations | Continue learning on universal representations | Tune the model on a specific task | Additional learning and tasks after pre-training |
| training data | Large-scale text data sets | additional text data set | Task-specific datasets | Additional optimization, domain adaptation or task migration |
| Weight update | Weight update | Continue to update model parameters | Perform weight updates on task data | Weight updates for specific needs |
| Data transformation and preprocessing | Usually includes data standardization, mask prediction, etc. | Preprocessing similar to pretraining | Adapt to mission needs | Data processing and optimization for specific needs |
| Task type | Unsupervised learning, self-supervised learning | Usually self-supervised learning | supervised learning | It can include various tasks such as optimization, domain adaptation, task migration, etc. |
| Sample application | BERT, GPT, etc. | Additional pre-training | Text classification, named entity recognition, etc. | Model optimization, domain adaptation, multi-task learning, etc. |
| Typical scenario | language understanding and production | Continue model learning | specific text tasks | Next steps and tasks to customize and optimize the model |
Note: The environment of this article is Windows 10, Python 3.10, CUDA 11.8, GTX 3090 (24G), and 24G memory.
1. Model pre-training script
There are many parameters in the model pre-training script, which can only be digested in practice. Because I am using a Windows 10 system, running shell scripts is more troublesome, so I won’t go into too much detail about this part. As follows:
train/pretrain/pretrain.sh
output_model=/mnt/data1/atomgpt # output_model:输出模型路径
if [ ! -d ${output_model} ];then # -d:判断是否为目录,如果不是目录则创建
mkdir ${output_model} # mkdir:创建目录
fi
cp ./pretrain.sh ${output_model} # cp:复制文件pretrain.sh到output_model目录下
cp ./ds_config_zero*.json ${output_model} # cp:复制文件ds_config_zero*.json到output_model目录下
deepspeed --num_gpus 1 pretrain_clm.py \ # deepspeed:分布式训练,num_gpus:使用的gpu数量,pretrain_clm.py:训练脚本
--model_name_or_path L:/20230903_Llama2/Llama-2-7b-hf \ # model_name_or_path:模型名称或路径
--train_files ../../data/train_sft.csv \ # train_files:训练数据集路径
../../data/train_sft_sharegpt.csv \
--validation_files ../../data/dev_sft.csv \ # validation_files:验证数据集路径
../../data/dev_sft_sharegpt.csv \
--per_device_train_batch_size 10 \ # per_device_train_batch_size:每个设备的训练批次大小
--per_device_eval_batch_size 10 \ # per_device_eval_batch_size:每个设备的验证批次大小
--do_train \ # do_train:是否进行训练
--output_dir ${output_model} \ # output_dir:输出路径
--evaluation_strategy steps \ # evaluation_strategy:评估策略,steps:每隔多少步评估一次
--use_fast_tokenizer false \ # use_fast_tokenizer:是否使用快速分词器
--max_eval_samples 500 \ # max_eval_samples:最大评估样本数,500:每次评估500个样本
--learning_rate 3e-5 \ # learning_rate:学习率
--gradient_accumulation_steps 4 \ # gradient_accumulation_steps:梯度累积步数
--num_train_epochs 3 \ # num_train_epochs:训练轮数
--warmup_steps 10000 \ # warmup_steps:预热步数
--logging_dir ${output_model}/logs \ # logging_dir:日志路径
--logging_strategy steps \ # logging_strategy:日志策略,steps:每隔多少步记录一次日志
--logging_steps 2 \ # logging_steps:日志步数,2:每隔2步记录一次日志
--save_strategy steps \ # save_strategy:保存策略,steps:每隔多少步保存一次
--preprocessing_num_workers 10 \ # preprocessing_num_workers:预处理工作数
--save_steps 500 \ # save_steps:保存步数,500:每隔500步保存一次
--eval_steps 500 \ # eval_steps:评估步数,500:每隔500步评估一次
--save_total_limit 2000 \ # save_total_limit:保存总数,2000:最多保存2000个
--seed 42 \ # seed:随机种子
--disable_tqdm false \ # disable_tqdm:是否禁用tqdm
--ddp_find_unused_parameters false \ # ddp_find_unused_parameters:是否找到未使用的参数
--block_size 4096 \ # block_size:块大小
--overwrite_output_dir \ # overwrite_output_dir:是否覆盖输出目录
--report_to tensorboard \ # report_to:报告给tensorboard
--run_name ${output_model} \ # run_name:运行名称
--bf16 \ # bf16:是否使用bf16
--bf16_full_eval \ # bf16_full_eval:是否使用bf16进行完整评估
--gradient_checkpointing \ # gradient_checkpointing:是否使用梯度检查点
--deepspeed ./ds_config_zero3.json \ # deepspeed:分布式训练配置文件
--ignore_data_skip true \ # ignore_data_skip:是否忽略数据跳过
--ddp_timeout 18000000 \ # ddp_timeout:ddp超时时间,18000000:18000000毫秒
| tee -a ${output_model}/train.log # tee:将标准输出重定向到文件,-a:追加到文件末尾
# --resume_from_checkpoint ${output_model}/checkpoint-20400 \# resume_from_checkpoint:从检查点恢复训练
2. Pre-training implementation code
The Llama Chinese community provides the pre-training code of the Llama model, as well as Chinese corpus (refer to Part 6). This article performs pre-training on the basis of Llama-2-7b released by meta. For pretrain_clm.pythe Chinese comments of the code, please refer to [0]. The execution script is as follows:
python pretrain_clm.py --output_dir ./output_model --model_name_or_path L:/20230903_Llama2/Llama-2-7b-hf --train_files ../../data/train_sft.csv ../../data/train_sft_sharegpt.csv --validation_files ../../data/dev_sft.csv ../../data/dev_sft_sharegpt.csv --do_train --overwrite_output_dir
Note: When using GTX 3090 24G graphics card, an OOM error is still reported, but it does not affect debugging and learning. For the output log, refer to [2].
1. Code structure
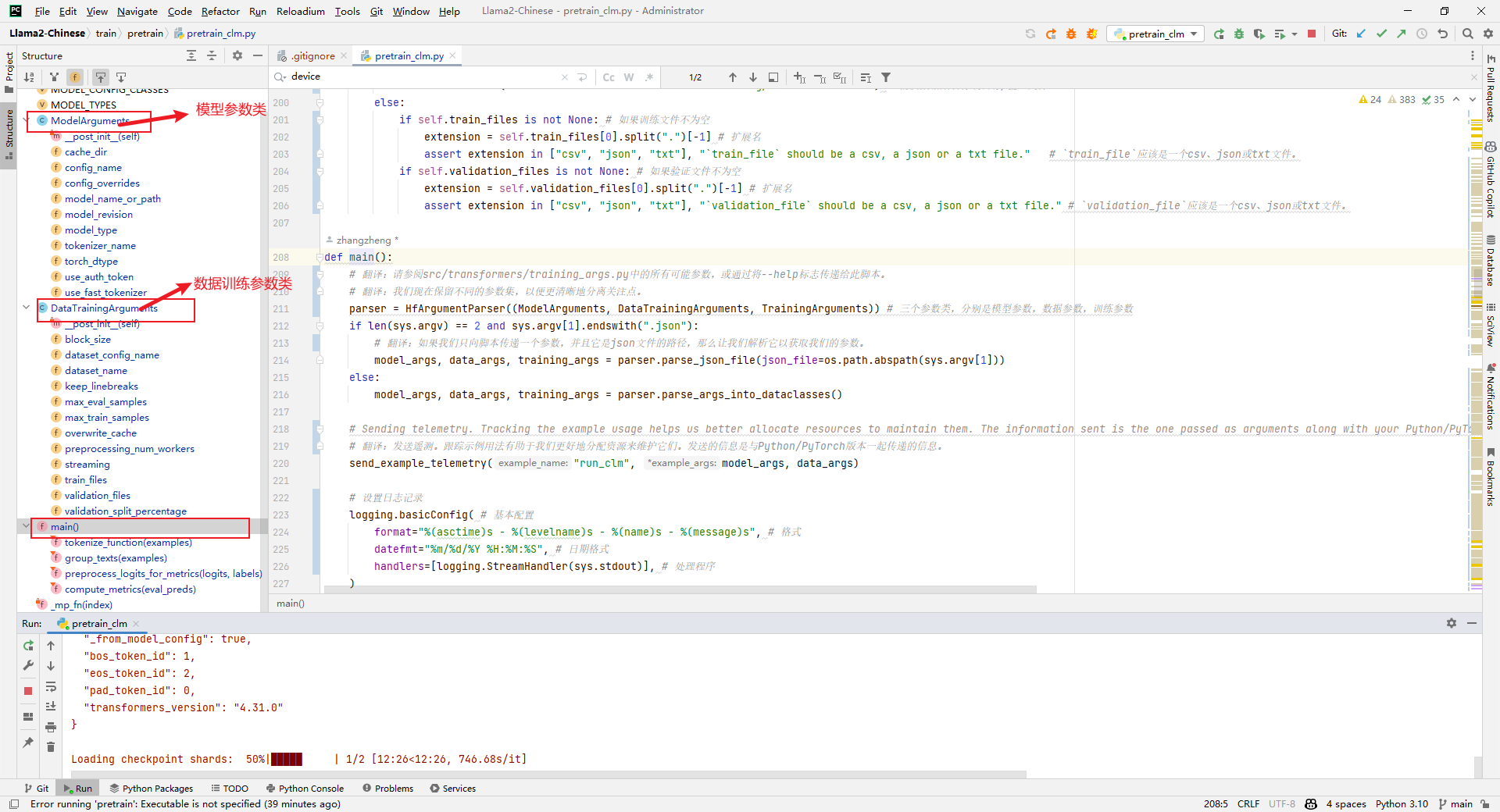
(1) ModelArguments: model parameter class
(2) DataTrainingArguments: data training parameter class
(3) TrainingArguments: training parameter class
2.model_args, data_args, training_args = parser.parse_args_into_dataclasses()
Analysis: load model parameters, data training parameters and training parameters, as shown below:

3.raw_datasets = load_dataset(...)
Parsing: Load the original data set, as shown below:

4.config = AutoConfig.from_pretrained(model_args.model_name_or_path, **config_kwargs)
Parsing: Load config, as shown below:
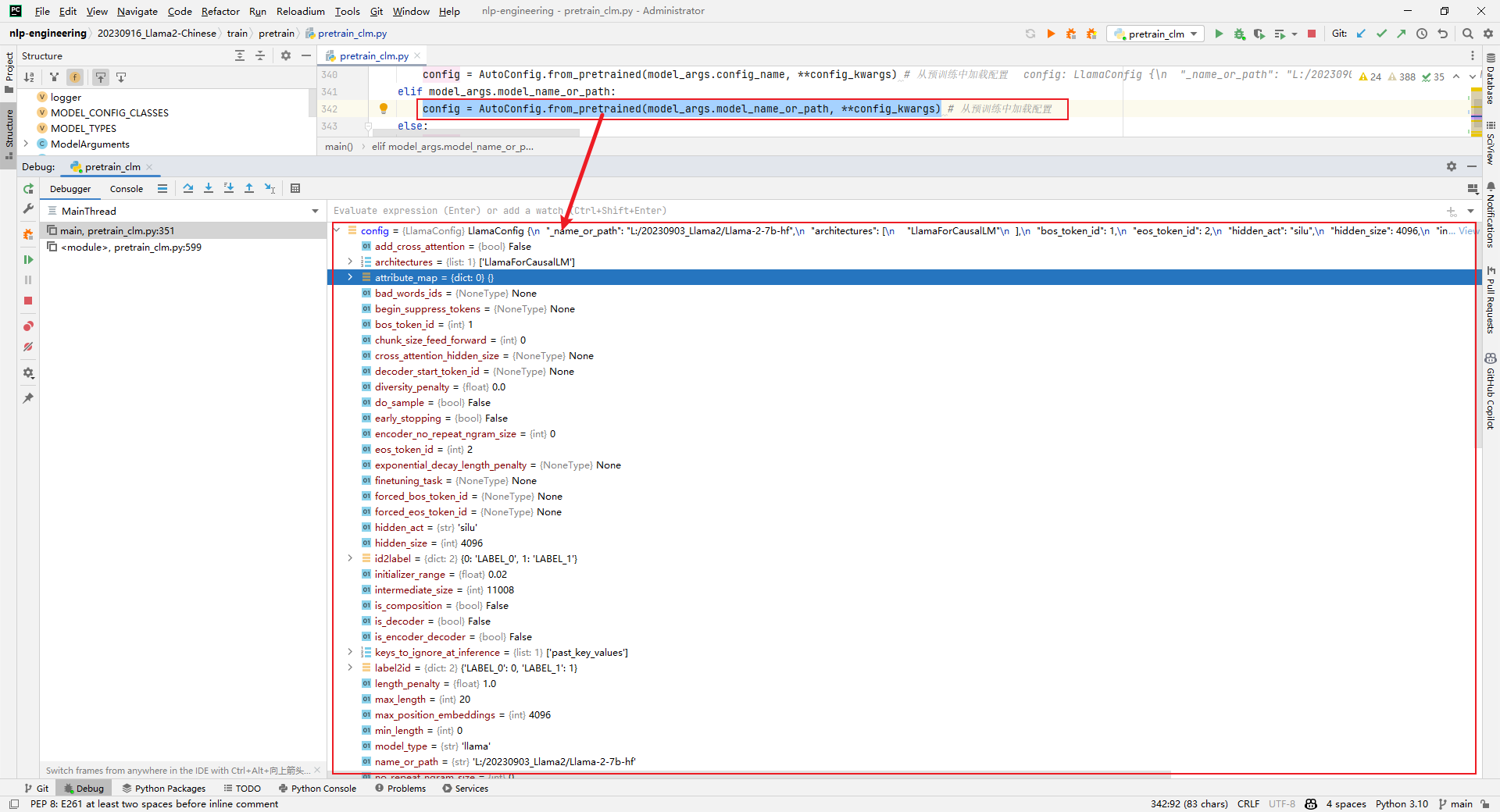
5.tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, **tokenizer_kwargs)
Parsing: Load tokenizer, as shown below:
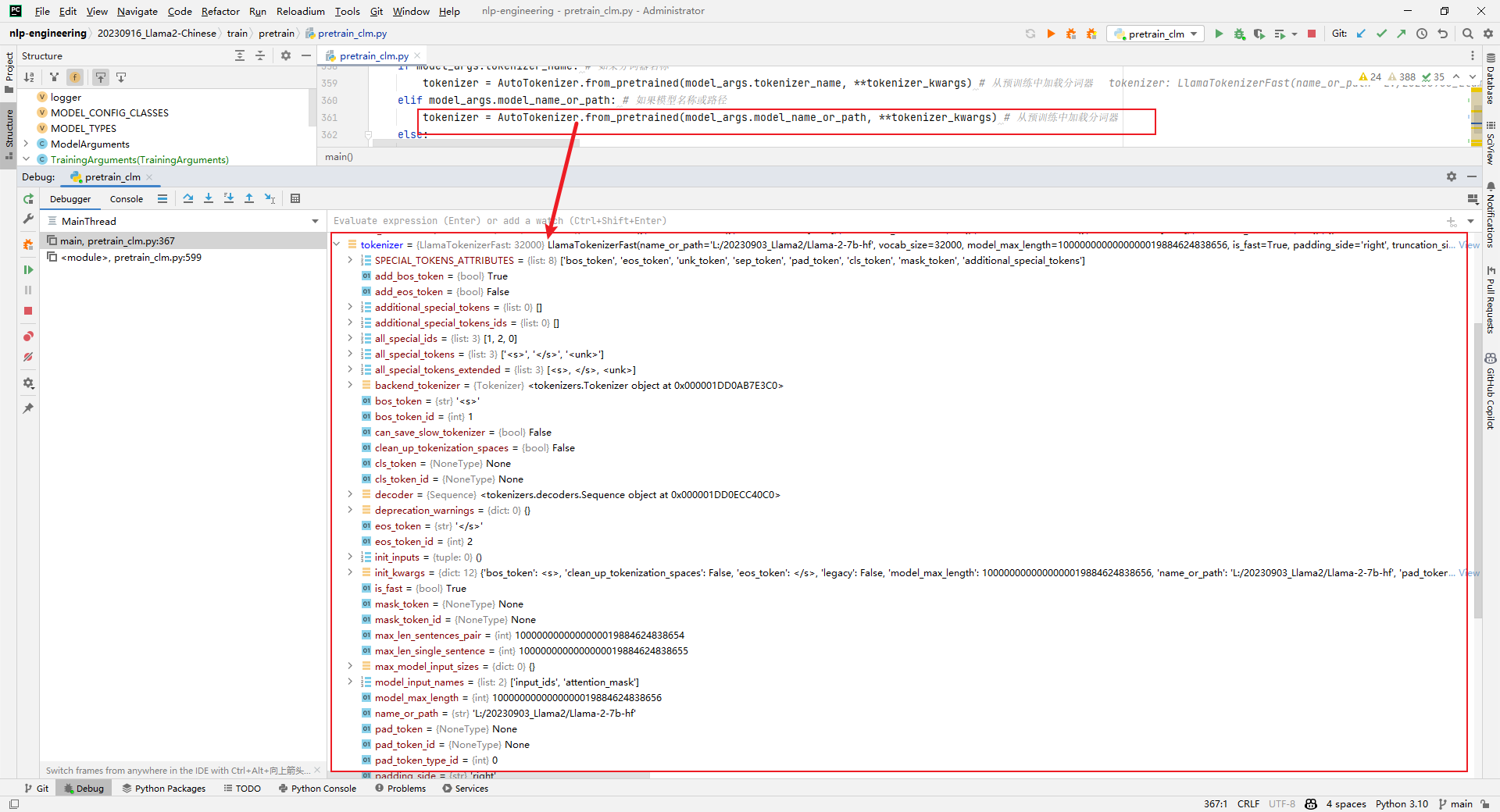
6.model = AutoModelForCausalLM.from_pretrained()
Analysis: Load the model. This step is very time-consuming, as shown below:

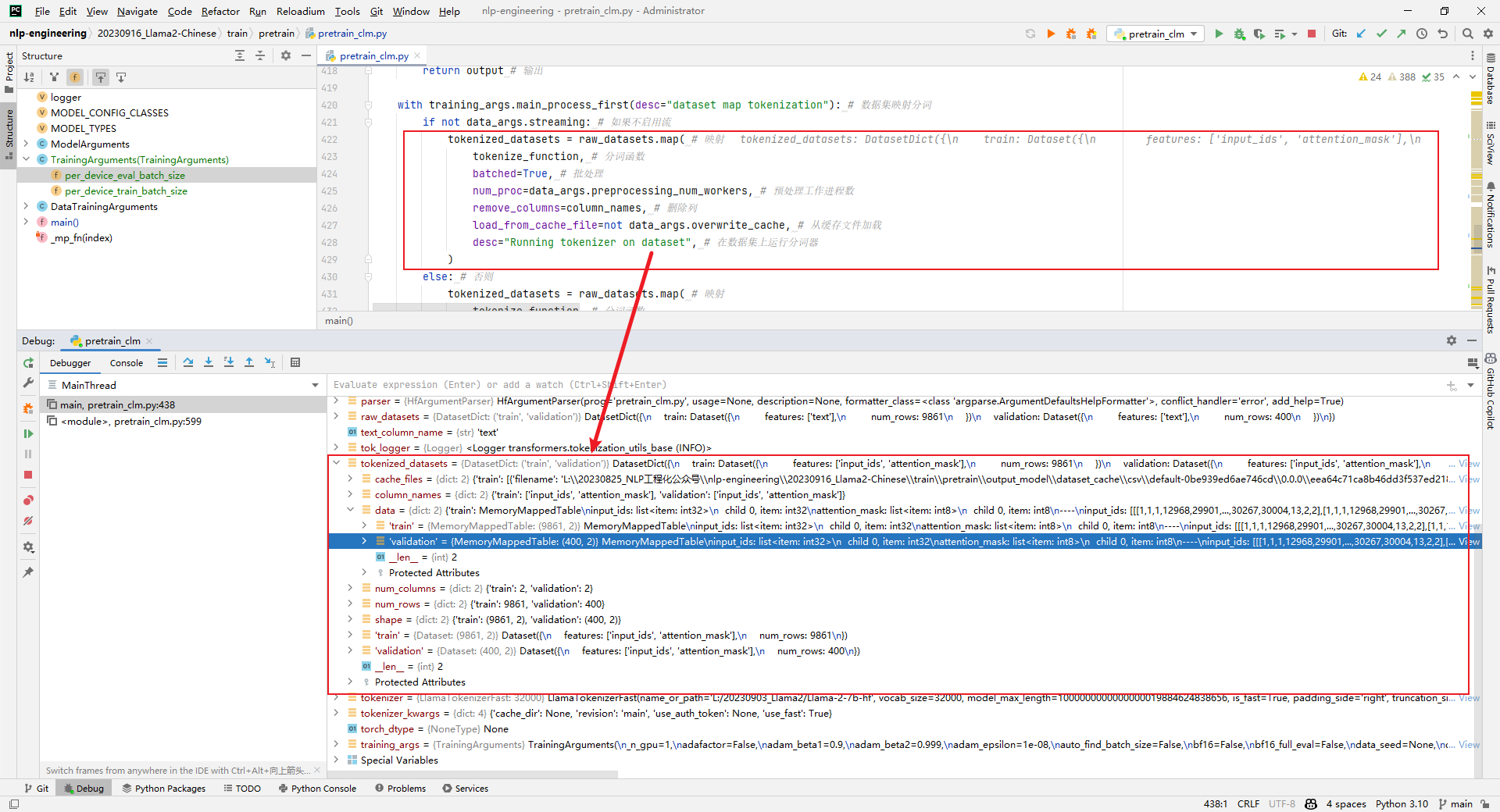
7.tokenized_datasets = raw_datasets.map()
Parsing: Original data set processing, such as encoding, etc., as shown below:
8.trainer = Trainer()
Parsing: Instantiate a trainer for subsequent training or evaluation. When I got to this step, I reported OOM. As follows:
trainer = Trainer( # 训练器
model=model, # 模型
args=training_args, # 训练参数
train_dataset= IterableWrapper(train_dataset) if training_args.do_train else None, # 训练数据集
eval_dataset= IterableWrapper(eval_dataset) if training_args.do_eval else None, # 评估数据集
tokenizer=tokenizer, # 分词器
# Data collator will default to DataCollatorWithPadding, so we change it.
# 翻译:数据收集器将默认为DataCollatorWithPadding,因此我们将其更改。
data_collator=default_data_collator, # 默认数据收集器
compute_metrics=compute_metrics if training_args.do_eval and not is_torch_tpu_available() else None, # 计算指标
preprocess_logits_for_metrics=preprocess_logits_for_metrics if training_args.do_eval and not is_torch_tpu_available() else None, # 为指标预处理logits
# callbacks=([SavePeftModelCallback] if isinstance(model, PeftModel) else None),
)
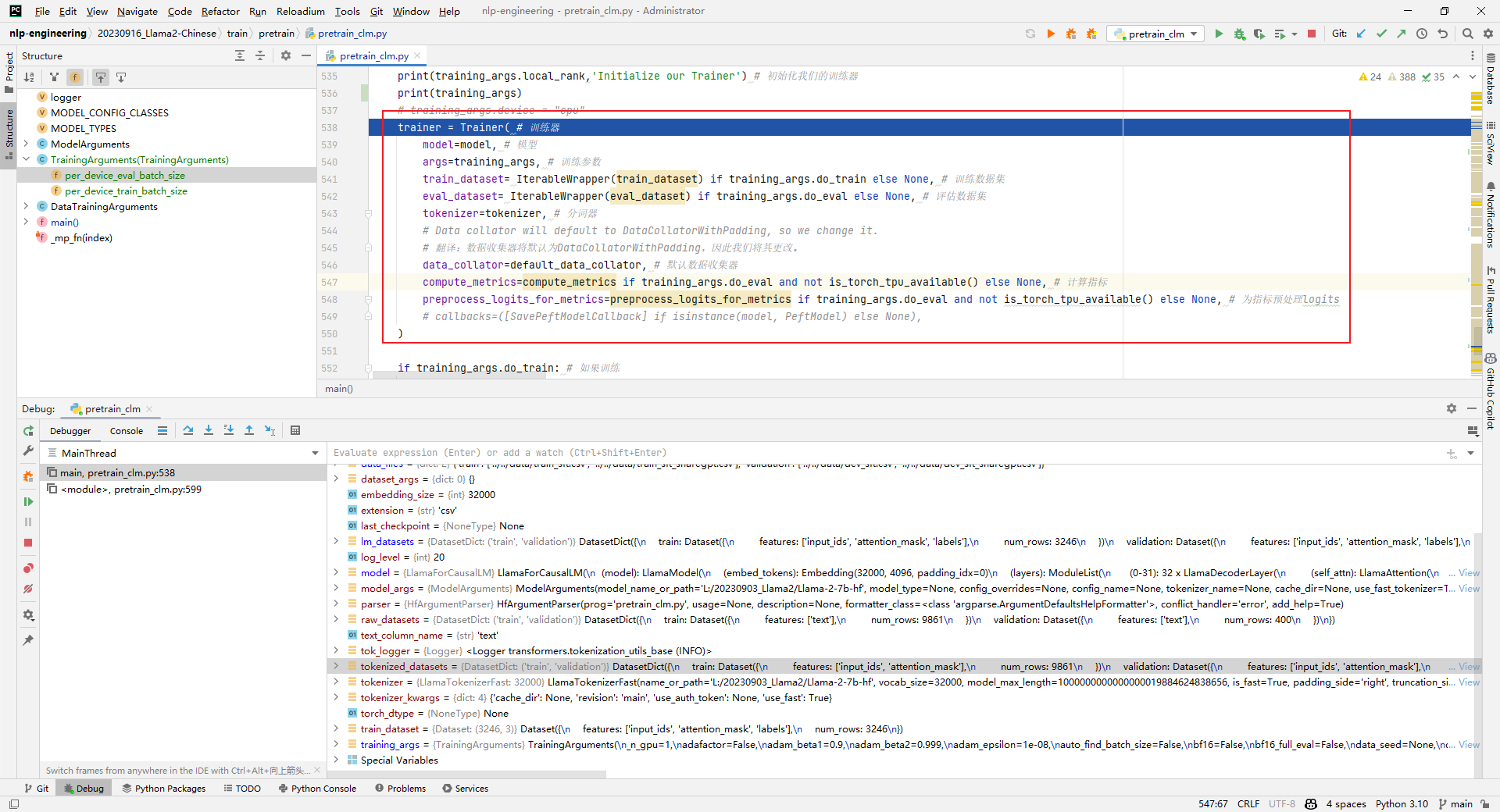
Said: pretrain_clm.pyI have several questions when reading the code: What is the expansion of the Chinese vocabulary? How to increase the context length? How to pretrain text data? I will write an article to share later.
3. DeepSpeed acceleration
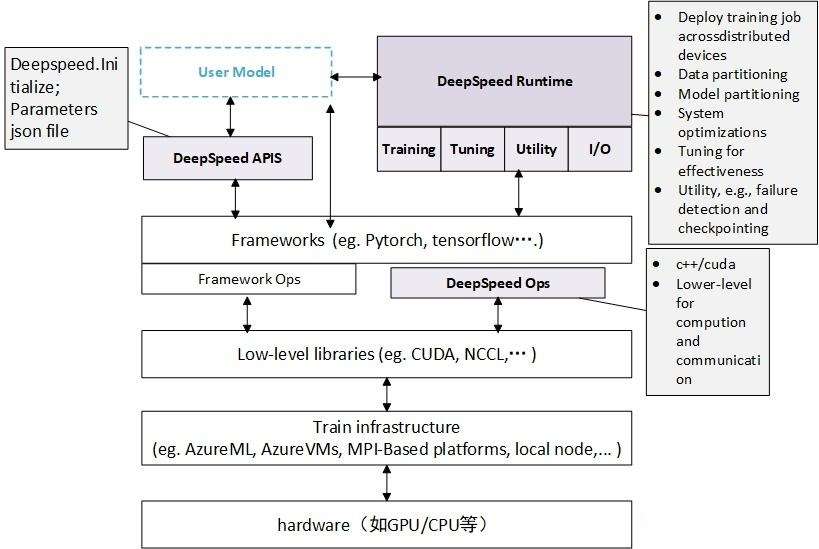
DeepSpeed is an open source deep learning optimization library developed by Microsoft, designed to improve the efficiency and scalability of large-scale model training. It accelerates training through a variety of technical means, including model parallelization, gradient accumulation, dynamic accuracy scaling, local mode mixed accuracy, etc. DeepSpeed also provides some auxiliary tools, such as distributed training management, memory optimization and model compression, to help developers better manage and optimize large-scale deep learning training tasks. In addition, deepspeed is built on pytorch and can be migrated with only simple modifications. DeepSpeed has been used in many large-scale deep learning projects, including language models, image classification, target detection, etc.
DeepSpeed mainly consists of three parts:
- Apis: Provides an easy-to-use API interface. Training models and inference models only require simple calls to a few interfaces. The most important one is the initialize interface, which is used to initialize the engine and configure training parameters and optimization technology in the parameters. Configuration parameters are generally saved in the config.json file.
- Runtime: Runtime component is the core component of DeepSpeed management, execution and performance optimization. For example, deploy training tasks to distributed devices, data partitioning, model partitioning, system optimization, fine-tuning, fault detection, checkpoints saving and loading, etc. This component is implemented using Python language.
- Ops: Use C++ and CUDA to implement the underlying kernel and optimize computing and communication, such as ultrafast transformer kernels, fuse LAN kernels, customary deals, etc.
1. Windows 10 installation DeepSpeed
analysis: Administrator starts cmd:
build_win.bat
python setup.py bdist_wheel
2. Install the compilation tool.
Check "Desktop development using C++" in the Visual Studio Installer, as shown below:

3. error C2665: torch::empty: There is no overloaded function that can convert all parameter types.

The solution is as follows:

4 .Element "1": Conversion from "size_t" to "_Ty" requires shrinking conversion.
Analysis: The specific error is as follows:
csrc/transformer/inference/csrc/pt_binding.cpp(536): error C2398: 元素"1": 从"size_t"转换为"_Ty"需要收缩转换
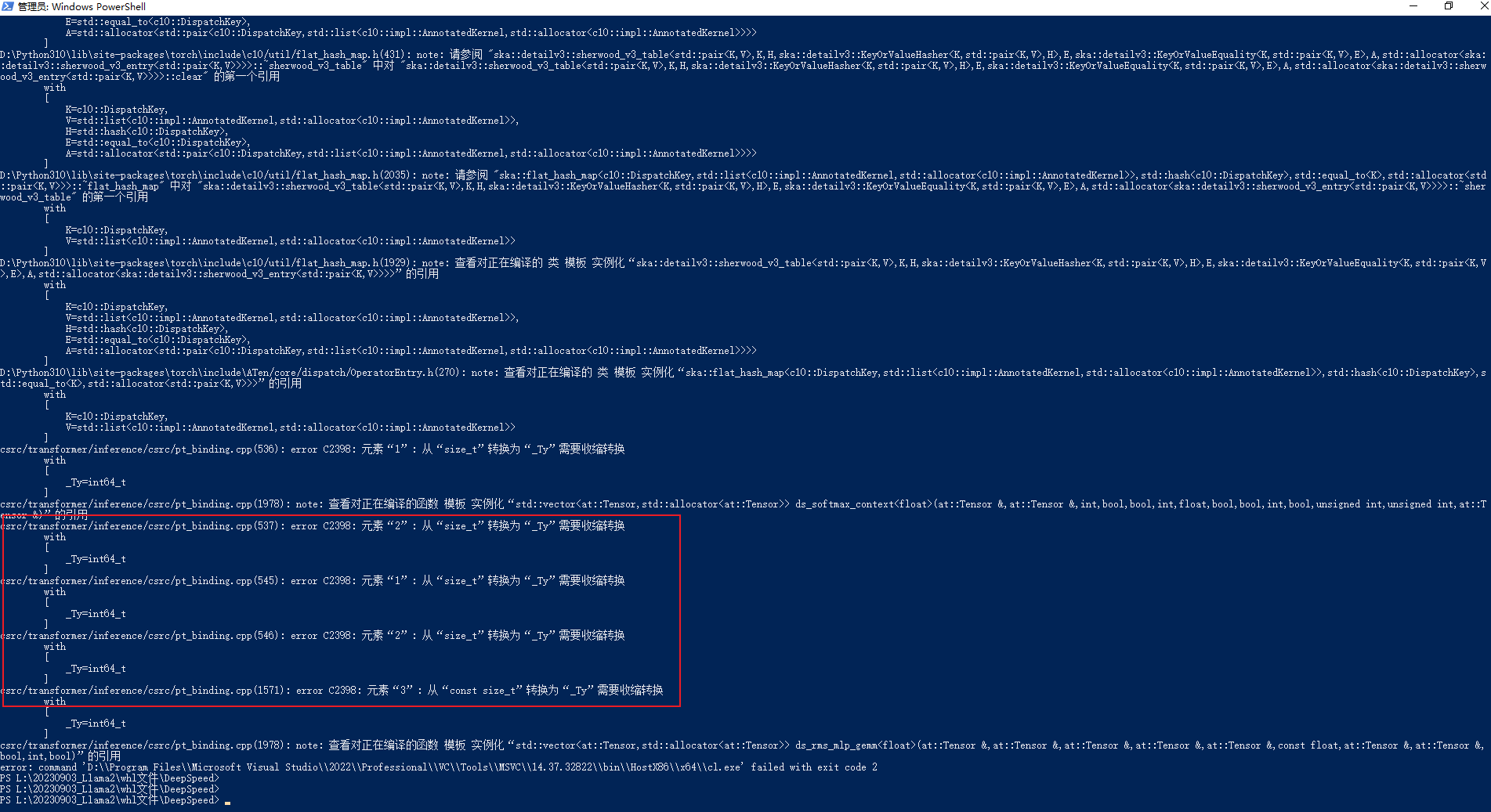
The parsing scheme is as follows:
536:hidden_dim * (unsigned)InferenceContext
537:k * (int)InferenceContext
545:hidden_dim * (unsigned)InferenceContext
546:k * (int)InferenceContext
1570: input.size(1), (int)mlp_1_out_neurons

The successful compilation is as follows:

5. Install the class library
PS L:\20230903_Llama2\whl文件\DeepSpeed\dist> pip3 install .\deepspeed-0.10.4+180dd397-cp310-cp310-win_amd64.whl
Note: Since DeepSpeed is not user-friendly on Windows, this part is for learning purposes only.
6. Single-card training and multi-card training
(1) For single-card training, the ZeRO-2 method can be used. For parameter configuration, see train/pretrain/ds_config_zero2.json
{
"fp16": { // 混合精度训练
"enabled": "auto", // 是否开启混合精度训练
"loss_scale": 0, // 损失缩放
"loss_scale_window": 1000, // 损失缩放窗口
"initial_scale_power": 16, // 初始损失缩放幂
"hysteresis": 2, // 滞后
"min_loss_scale": 1 // 最小损失缩放
},
"optimizer": { // 优化器
"type": "AdamW", // 优化器类型
"params": { // 优化器参数
"lr": "auto", // 学习率
"betas": "auto", // 衰减因子
"eps": "auto", // 除零保护
"weight_decay": "auto" // 权重衰减
}
},
"scheduler": { // 学习率调度器
"type": "WarmupDecayLR", // 调度器类型
"params": { // 调度器参数
"last_batch_iteration": -1, // 最后批次迭代
"total_num_steps": "auto", // 总步数
"warmup_min_lr": "auto", // 最小学习率
"warmup_max_lr": "auto", // 最大学习率
"warmup_num_steps": "auto" // 热身步数
}
},
"zero_optimization": { // 零优化
"stage": 2, // 零优化阶段
"offload_optimizer": { // 优化器卸载
"device": "cpu", // 设备
"pin_memory": true // 锁页内存
},
"offload_param": { // 参数卸载
"device": "cpu", // 设备
"pin_memory": true // 锁页内存
},
"allgather_partitions": true, // 全收集分区
"allgather_bucket_size": 5e8, // 全收集桶大小
"overlap_comm": true, // 重叠通信
"reduce_scatter": true, // 减少散射
"reduce_bucket_size": 5e8, // 减少桶大小
"contiguous_gradients": true // 连续梯度
},
"activation_checkpointing": { // 激活检查点
"partition_activations": false, // 分区激活
"cpu_checkpointing": false, // CPU检查点
"contiguous_memory_optimization": false, // 连续内存优化
"number_checkpoints": null, // 检查点数量
"synchronize_checkpoint_boundary": false, // 同步检查点边界
"profile": false // 档案
},
"gradient_accumulation_steps": "auto", // 梯度累积步骤
"gradient_clipping": "auto", // 梯度裁剪
"steps_per_print": 2000, // 每次打印步骤
"train_batch_size": "auto", // 训练批次大小
"min_lr": 5e-7, // 最小学习率
"train_micro_batch_size_per_gpu": "auto", // 每个GPU的训练微批次大小
"wall_clock_breakdown": false // 墙上时钟分解
}
(2) For multi-card training, the ZeRO-3 method can be used. For parameter configuration, see train/pretrain/ds_config_zero3.json
{
"fp16": { // 混合精度训练
"enabled": "auto", // 是否开启混合精度训练
"loss_scale": 0, // 损失缩放
"loss_scale_window": 1000, // 损失缩放窗口
"initial_scale_power": 16, // 初始缩放幂
"hysteresis": 2, // 滞后
"min_loss_scale": 1, // 最小损失缩放
"fp16_opt_level": "O2" // 混合精度优化级别
},
"bf16": { // 混合精度训练
"enabled": "auto" // 是否开启混合精度训练
},
"optimizer": { // 优化器
"type": "AdamW", // 优化器类型
"params": { // 优化器参数
"lr": "auto", // 学习率
"betas": "auto", // 衰减因子
"eps": "auto", // 除零保护
"weight_decay": "auto" // 权重衰减
}
},
"scheduler": { // 学习率调度器
"type": "WarmupDecayLR", // 学习率调度器类型
"params": { // 学习率调度器参数
"last_batch_iteration": -1, // 最后批次迭代
"total_num_steps": "auto", // 总步数
"warmup_min_lr": "auto", // 最小学习率
"warmup_max_lr": "auto", // 最大学习率
"warmup_num_steps": "auto" // 热身步数
}
},
"zero_optimization": { // 零优化
"stage": 3, // 零优化阶段
"overlap_comm": true, // 重叠通信
"contiguous_gradients": true, // 连续梯度
"sub_group_size": 1e9, // 子组大小
"reduce_bucket_size": "auto", // 减少桶大小
"stage3_prefetch_bucket_size": "auto", // 阶段3预取桶大小
"stage3_param_persistence_threshold": "auto", // 阶段3参数持久性阈值
"stage3_max_live_parameters": 1e9, // 阶段3最大活动参数
"stage3_max_reuse_distance": 1e9, // 阶段3最大重用距离
"gather_16bit_weights_on_model_save": true // 在模型保存时收集16位权重
},
"gradient_accumulation_steps": "auto", // 梯度累积步数
"gradient_clipping": "auto", // 梯度裁剪
"steps_per_print": 2000, // 每次打印步数
"train_batch_size": "auto", // 训练批次大小
"train_micro_batch_size_per_gpu": "auto", // 训练每个GPU的微批次大小
"wall_clock_breakdown": false // 墙上时钟分解
}
A comparison between ZeRO-2 and ZeRO-3 is shown below (ChatGPT):
| feature | Zero2 (version 0.2) | Zero3 (version 0.3) |
|---|---|---|
| Memory usage optimization | yes | yes |
| Dynamic calculation graph support | not support | support |
| Performance optimization | generally | better |
| Model configuration options | limited | More |
| Distributed training support | yes | yes |
| application | Non-dynamic computational graph model | Dynamic Computational Graph Model |
4.
accuracy.py Chinese annotation reference [1] for the training effect measurement indicator code. This file is mainly used in pre-training evaluation, as shown below:
train/pretrain/accuracy.py
metric = evaluate.load("accuracy.py") # 加载指标
5. Chinese test corpus
The Chinese test corpus data format is as follows:
<s>Human: 问题</s><s>Assistant: 答案</s>
For multiple rounds of corpus, just splice the single rounds together, as shown below:
<s>Human: 内容1\n</s><s>Assistant: 内容2\n</s><s>Human: 内容3\n</s><s>Assistant: 内容4\n</s>

There are three train and dev files provided in the Llama2-Chinese project, as shown below:
data\dev_sft.csv
data\dev_sft_sharegpt.csv
data\train_sft.csv
More corpora can be downloaded from the Llama Chinese community (https://llama.family/) link:
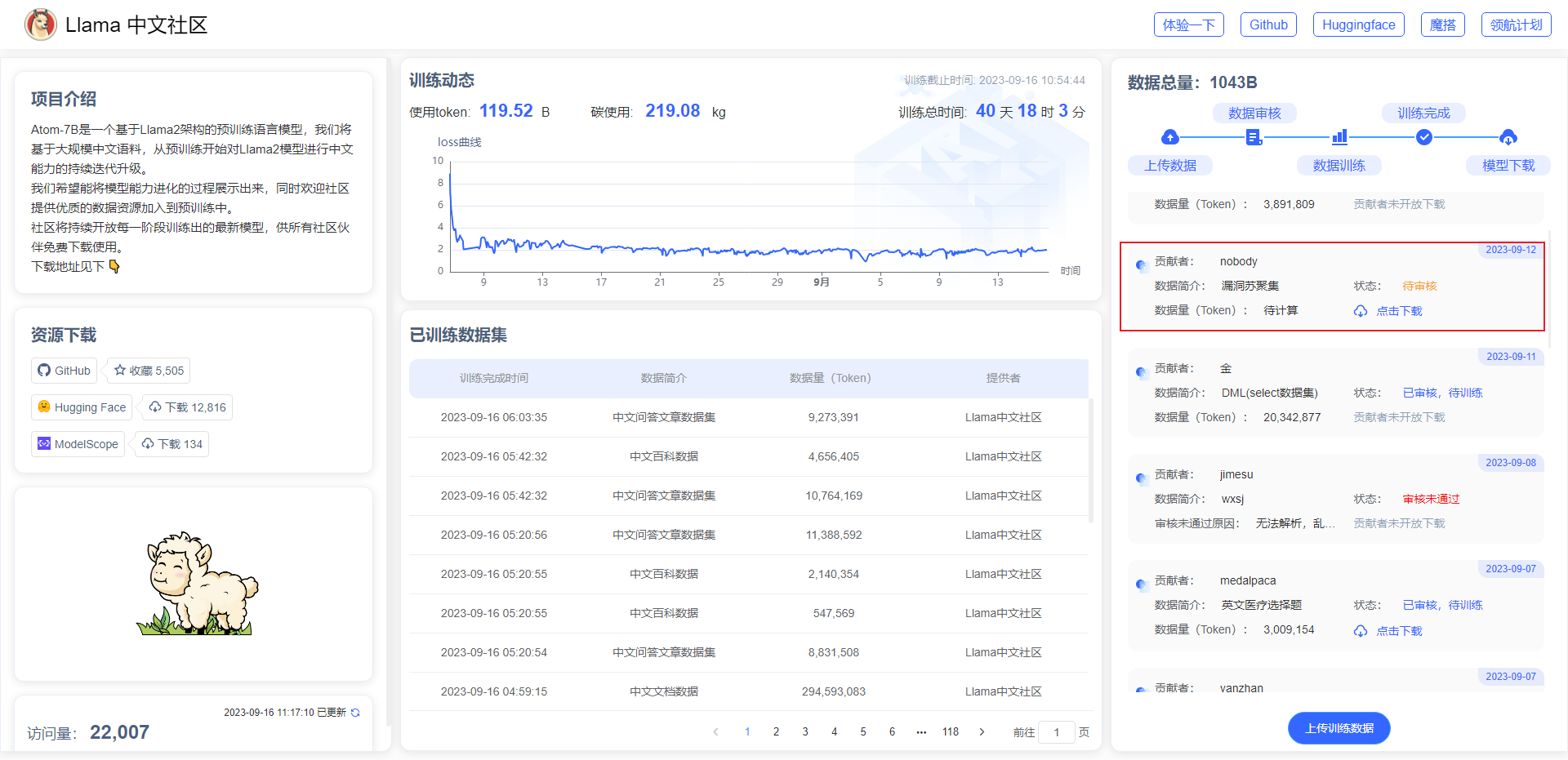
6. Chinese corpus
Atom-7B is a pre-trained language model based on the Llama2 architecture. The Llama Chinese community will continue to iteratively upgrade the Chinese capabilities of the Llama2 model starting from pre-training based on large-scale Chinese corpus. Optimize Llama2's Chinese capabilities through the following data:
| type | describe |
|---|---|
| network data | The public network data on the Internet selects high-quality Chinese data after deduplication, involving high-quality long text data such as encyclopedias, books, blogs, news, announcements, novels, etc. |
| Wikipedia | Data from Chinese Wikipedia |
| Enlightenment | Chinese Enlightenment Open Source 200G Data |
| Clue | Clue’s open Chinese pre-training data, high-quality Chinese long text data after cleaning |
| Competition dataset | Chinese natural language processing multi-task competition data sets in recent years, about 150 |
| MNBVC | Part of the data set cleaned in MNBVC |
Note: Except for the network data and competition data sets, which do not provide links, the other four provide links to the data sets.
参考文献:
[0]https://github.com/ai408/nlp-engineering/blob/main/20230916_Llama2-Chinese/train/pretrain/pretrain_clm.py
[1]https://github.com/ai408/nlp-engineering/blob/main/20230916_Llama2-Chinese/train/pretrain/accuracy.py
[2]https://github.com/ai408/nlp-engineering/blob/main/20230916_Llama2-Chinese/train/pretrain/pretrain_log/pretrain_log
[3]https://huggingface.co/meta-llama/Llama-2-7b-hf/tree/main
[4]https://huggingface.co/spaces/ysharma/Explore_llamav2_with_TGI
[5]https://huggingface.co/meta-llama/Llama-2-70b-chat-hf
[6]https://huggingface.co/blog/llama2
[7]https://developer.nvidia.com/rdp/cudnn-download
[8]https://github.com/jllllll/bitsandbytes-windows-webui
[9]https://github.com/langchain-ai/langchain
[10]https://github.com/AtomEcho/AtomBulb
[11]https://github.com/huggingface/peft
[12] When fine-tuning all parameters, it is reported that there is no target_modules variable: https://github.com/FlagAlpha /Llama2-Chinese/issues/169
[13]https://huggingface.co/FlagAlpha
[14]Win10 installation of DeepSpeed: https://zhuanlan.zhihu.com/p/636450918