Talk about the pre-training task used in video-text pre-training. First, we introduce some popular pre-training tasks. For example, dual-encoder models are often optimized through video-text contrastive learning . For fused encoder models, two popular pre-training tasks are Masked Language Modeling (MLM) and Video Text Matching (VTM). We then discuss pre-training tasks designed to model the unique characteristics of video inputs, such as frame-order modeling (FOM) and different variants of masked video modeling (MVM).
1. Video text comparison learning (VTC)
In VTC, the goal of the model is to learn the correspondence between video and text. VTC is widely adopted to train dual-encoder models, where video and text inputs are fused together via lightweight inner products. This simple dot product is also used to calculate video-to-text and text-to-video similarities in the dual-encoder model. Specifically, given a batch of N video-text pairs, VTC aims to predict N matching pairs from all possible video-text pairs.

The normalized representation of video vectors and text vectors in a training batch is: and
, where σ is the learned temperature hyperparameter. The video-to-text contrastive loss is
, and the text-to-video contrastive loss is
.
The simple formulation of VTC assumes that correct video and text alignment exists in the pre-training data , but this is not always the case. A huge challenge in large-scale contrastive pre-training on existing video-text data is the inherent misalignment between visual frames and speech-transcribed subtitles. To solve the problem of visually misaligned narratives, MIL-NCE proposes a method that combines multi-instance learning and contrastive learning to exploit the weak and noisy training signals in narrative videos. VideoCLIP constructs pairs of temporally overlapping video and text segments to improve the quality and quantity of the pre-training corpus compared to the fixed length in Miech et al. Furthermore, they compare not only different clips within the same video, but also harder negative examples retrieved from other videos that are similar to clips within the batch.
Furthermore, traditional contrastive learning calculates the loss after aggregating all words in the text and frames in the video. In TACo, the authors propose to make it token-aware, i.e. only use a small subset of words (such as nouns and verbs) to calculate the loss to improve the rooting of individual words in the video. TACo combines token-aware VTC with naive VTC applied on a dual-encoder architecture and further adds a third VTC loss enhanced by deep multi-modal fusion. Specifically, the similarity between the video and text inputs is the result of the Transformer block operating on top of the dual encoder, which corresponds to the multi-modal fusion output of the [CLS] token of the fused encoder architecture. To reduce the complexity of computing the VTC loss of the fused encoder, they adopt a cascade sampling strategy to only sample a small number of hard-to-negative examples based on token-aware VTC and naive VTC losses.
2. Masked Language Modeling (MLM)
MLM directly adopts the model used for language model pre-training, except that the input is a video-text pair. Formally, the inputs to MLM include:
(i) sub-word tokens from input sentence w;
(ii) visual input (e.g. frame patches/features) v aligned with w;
(iii) Mask index . N is a natural number, M is the number of mask markers, and m is the set of mask indices.
In practice, we randomly mask out input words with 15% probability and replace the masked token wm with a special token [MASK]. Following BERT's approach, the 15% words that were randomly masked were further broken down into 10% random words, 10% unchanged and 80% [MASK]. The goal is to predict these masked words based on their surrounding words and the visual input v that is aligned with the sentence, by minimizing the negative log-likelihood:
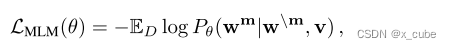
where θ represents a trainable parameter. Each pair (w, v) is sampled from the training set D.
Similar to image-text pre-training, video-text pre-training methods also use variations of language modeling where word-by-word generation is interpreted, such as UniVL and Support-Set. Specific to video-to-text pretraining, speech-transcribed texts are often more informal, containing utterances or repeated mentions of key objects. To avoid masking on unfounded words, MERLOT provides a simple heuristic solution to mask words based on learned attention weights, and its advantages over random masking are empirically verified.
3. Video Text Matching (VTM)
In VTM, the model is given a batch of positive sample video-text pairs and negative sample video-text pairs, which are constructed by replacing the video/text input in the positive sample video-text pairs. The goal of VTM is to identify video and text pairs of positive samples. VTM is usually formulated as a binary classification task. Specifically, a special token (i.e., [CLS]) is inserted at the beginning of the input sentence, and its learned vector representation is used as a cross-modal representation of the input video-text pair. We then feed matching or non-matching video-text pairs v,w with equal probability to the model and learn a classifier to predict a binary label y indicating whether the sampled video-text pair is positive or negative. Specifically, represented by the output score sθ(w, v), we apply a binary cross-entropy loss for optimization:

Different VTM variants have been proposed to capture alignment in the temporal dimension at different levels of granularity. For example, HERO considers global alignment (predicting whether text matches the input video) and local temporal alignment (retrieving the moment in the video clip where the text should be positioned), which has been shown to be effective for downstream video corpus moment retrieval.
4. Other pre-training tasks
In addition to the pre-training tasks discussed above, there are some attempts to exploit the unique characteristics of video inputs for self-supervised pre-training.
4.1 Frame Order Modeling(FOM)
FOM aims to model the temporal sequence of events or actions that occur in a video. During training, we randomly select a percentage of input frames (or frame features) to shuffle and train the model to explicitly recover the correct temporal order. Two variants are explored, including reconstructing the absolute temporal order of these shuffled frames, like HERO, and predicting the relative order between each pair of frames, like MERLOT. In both articles, FOM is applied to videos paired with temporally based text such as subtitles or ASR output.
FOM with absolute timing order
At time t, let us label the video frame input as and the sentence with temporal basis as
. The inputs to FOM are: (i) all subtitle sentences
; (ii) visual frames
; (iii) reordering indices
, where R is the number of reordering frames and r is the set of reordering indices. During training, 15% of frames are randomly selected for shuffling, with the goal of reconstructing their original order along the temporal dimension, denoted as
. FOM is formulated as a classification problem, where t is the baseline label of the reordered frames. The ultimate goal is to minimize the negative log-likelihood:
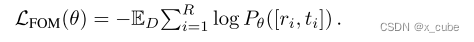
FOM with relative timing order
During training, 40% of the time, an integer n is first randomly selected from [2, T], representing the number of frames to be randomly shuffled, given T input frames. Then, n frames are randomly selected for random shuffling. After shuffling, the frames are fed into the model along with the text input to learn a joint video-language representation. For each pair of frames at time steps ti and tj (after shuffling), we concatenate their hidden states and pass the result through a two-layer multilayer perceptron to predict whether ti is smaller than tj or whether ti is larger than tj. Similarly, cross-entropy loss can be used to optimize FOM with relative temporal order.
4.2 Masked Video Modeling (MVM)
Since consecutive frames may contain similar spatial information, MVM is introduced to reconstruct a certain proportion of the high-level semantics or low-level details of the "masked" visual input (i.e., features or patches), given the high-level semantics or low-level details from adjacent frames and paired text descriptions. Full video token/characteristic. Specifically, the model is trained to reconstruct the masked patch or feature vm, given the remaining visible patches or features v\m and the paired text w. That is to say,

A similar objective has been proposed for image-text pre-training, known as Masked Image Modeling (MIM).
4.2.1 MVM with intra-batch negative samples
MVM with intra-batch negative samples was explored in HERO, using noise construction estimation loss to supervise the model to identify the correct frame features corresponding to the masked frames and compare them with all negative distributions in the same batch.
4.2.2 MVM with discrete visual markers
First, MVM with discrete visual markers is introduced in VideoBERT. VideoBERT uses hierarchical k-means to segment the continuous S3D features extracted from the input video frames into discrete "visual markers". These visual markers are then used as the video input to the model and the prediction target of the MVM. MVM is formulated as a classification task and is performed in the same way as MLM. Similarly, 15% of the input visual markers are randomly masked, and the model is trained to recover these masked visual markers. Recently, VIOLET draws inspiration from self-supervised learning methods on visual Transformers, utilizing pre-trained DALL-E to extract discrete visual markers as MVM targets. VIOLET randomly masks patches of original input video frames and trains the model to predict the corresponding visual landmarks of these masked patches in an end-to-end manner.
4.2.3 MVM with other vision targets
In addition to discrete visual markers, Fu et al. also actually investigated seven other reconstruction objectives of MVM, including low-level pixel values and directional gradients, high-level depth maps, optical flow predictions, and various potential visual features from deep neural networks. Likewise, blocks of original input video frames are randomly masked, and model training is supervised with an l1 loss between MVM predictions and the consecutive visual targets of these masked blocks.