1. Background
Without further ado, let's go to the picture first
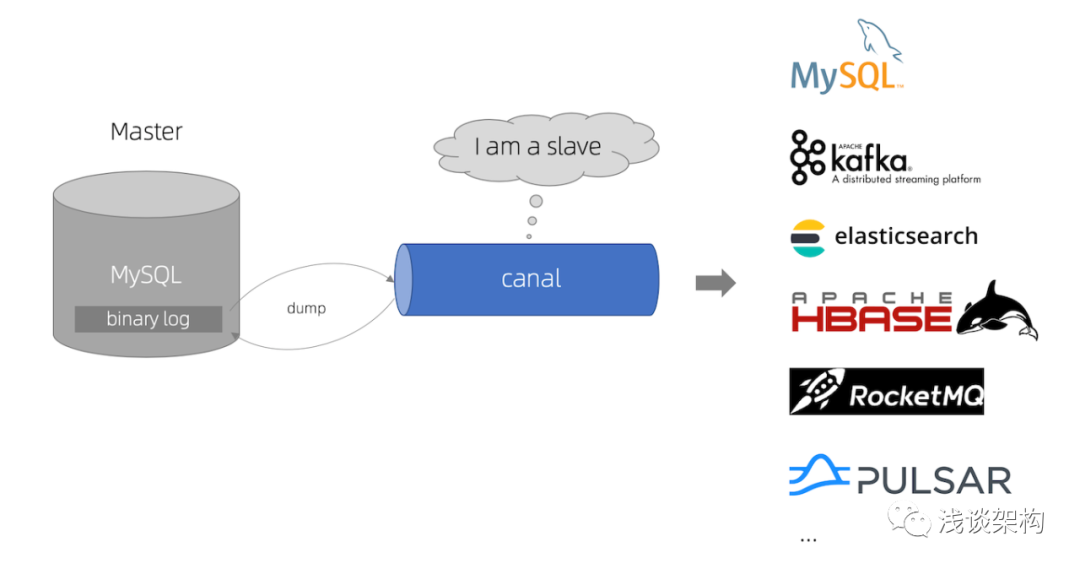
The picture above comes from the official website (https://github.com/alibaba/canal), which basically covers the current production environment usage scenarios. As we all know, Canal's data synchronization is already a benchmark in the industry. Our production environment also uses Canal to monitor binlog data changes, and then parses the corresponding data and sends it to MQ (RocketMQ). For some non-main process businesses, asynchronous scenarios can consume MQ for processing.
But in this article, I mainly want to talk about the usage scenarios of Canal when the data of the old and new systems are synchronized in two directions during system refactoring.
Note: I will not describe the introduction of system refactoring here. You can read the series of articles I wrote before: Talking about system refactoring
2. About two-way synchronization
What is two-way sync?
The so-called two-way synchronization means that the old system database data is synchronized to the new system database, and the new system database is also synchronized to the old system database. In order to ensure that the new system and the old system database data are completely consistent. If there is a problem when the system is restructured, it can be switched back to the original old system at any time, which also provides the underlying guarantee for the grayscale solution.
How to do general synchronization? What are the advantages and disadvantages of each?
Solution 1: Dao layer interception solution
Solution description: Drill holes in the Dao layer to intercept all write requests (insert, update, delete), then write to the MQ queue, and then write to the corresponding database by consuming the MQ queue.
Advantages: This solution is relatively simple to implement.
Disadvantages: For the old system database, there may be many services writing. If it is intercepted from the Dao layer, many places may need to be modified, and the changes will be relatively large.
Solution 2: Use Canal subscription to parse Binlog
Solution description: Use Canal to subscribe to Binlog, parse it into data, and then write it to the corresponding database (here you can write directly, or you can write to MQ first, and then consume MQ to write, the latter is recommended).
Advantages: It can solve the problem of multiple writes in the system.
Disadvantages: The introduction of a new component, Canal, increases the complexity.
Next, let's take a look at the second option in practice.
3. Environment preparation (Centos system as an example)
1. Install MySQL
wget https://dev.mysql.com/get/mysql80-community-release-el8-1.noarch.rpm
yum install mysql80-community-release-el8-1.noarch.rpm
#禁用centos自带的mysql
yum module disable mysql -y
#安装
yum install mysql-community-server -y
#启动
systemctl start mysqld
#查看启动状态 提升 Active: active (running) 表示成功
systemctl status mysqld
#查看初始密码
grep 'temporary password' /var/log/mysqld.log
#初始密码登录
mysql -uroot -p'AXXXXX' -hlocalhost -P3306
#修改ROOT密码
ALTER USER 'root'@'localhost' IDENTIFIED BY 'BXXXXX';2. Environment deployment
1) Check whether the binlog mode is currently enabled in mysql. If the value of log_bin is OFF, it is not enabled, and if it is ON, it is enabled.
SHOW VARIABLES LIKE '%log_bin%'2), if it is not enabled, you need to modify /ect/my.cnf to enable binlog mode
[mysqld]
log-bin=mysql-bin
binlog-format=ROW
server_id=1Restart the mysql service after modification
3), create a user and authorize
create user canal@'%' IDENTIFIED by 'XXXX';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT,SUPER ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;3. Canal server installation
1), canal download address
wget https://github.com/alibaba/canal/releases/download/canal-1.1.4/canal.deployer-1.1.4.tar.gz2), unzip to the specified directory
mkdir canal-server-1.1.4
tar -zxf canal.deployer-1.1.4.tar.gz -C canal-server-1.1.4/3), modify the configuration file to view the main library binlog position
mysql> show master status;
+---------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+------------------+-------------------+
| binlog.000002 | 4526 | | | |
+---------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)Modify the configuration file conf/example/instance.properties
# position info
canal.instance.master.address={IP}:3306
# 这里对应上面的File
canal.instance.master.journal.name=binlog.000002
# 这里对应上面的Position
canal.instance.master.position=4526
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=XXXX4), start canal-server
./bin/startup.sh
# 查看日志
tail -f logs/example/example.logThe above completes the implementation of the single-instance version of Canal-Server. The production environment cluster environment is generally built for operation and maintenance. We use the single-instance version for testing.
The following is a brief introduction to Canal's HA mechanism design, which is recommended for production environments.
Canal's HA is divided into two parts, canal server and canal client have corresponding HA implementations respectively
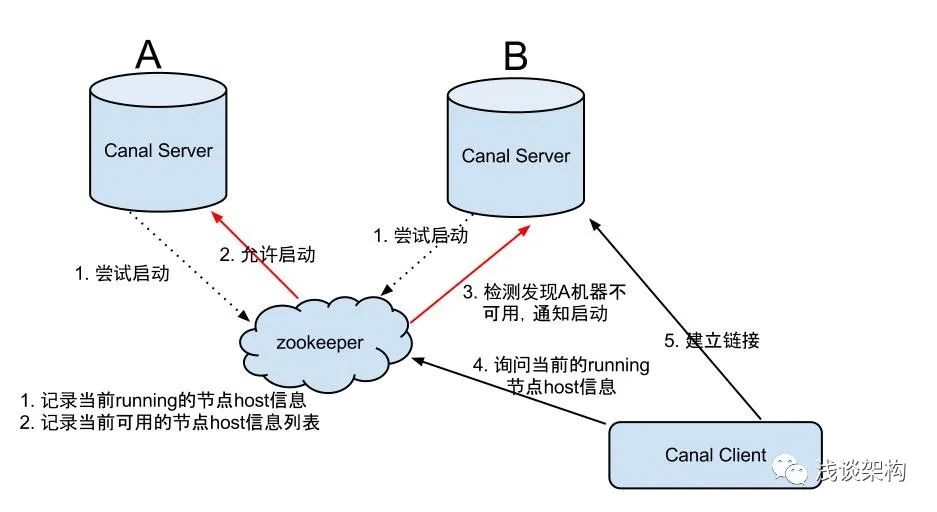
canal server:
In order to reduce requests for mysql dump, instances on different servers require only one to be running at the same time, and the others to be in standby state.
canal client:
In order to ensure the order, an instance can only be performed by one canal client at a time for get/ack/rollback operations, otherwise the order cannot be guaranteed for the client to receive. The control of the entire HA mechanism mainly relies on several features of zookeeper, watcher and EPHEMERAL nodes (bound to the session life cycle), so I won’t introduce them here. Interested students can read the official wiki.
4. Demonstration
Because the canal component encapsulates too much code, I spent a few nights writing it in my spare time (please like it), the code has been open sourced to gitee, and students who need it can clone it to see it.
gitee address: https://gitee.com/bytearch/fast-cloud
Currently supports simple direct connection mode and zookeeper cluster mode
The following demonstrates canal-client-demo
Create a new library order_center and create a table order_info
CREATE TABLE `order_info` ( `order_id` bigint(20) unsigned NOT NULL, `user_id` int(11) DEFAULT '0' COMMENT '用户id', `status` int(11) DEFAULT '0' COMMENT '订单状态', `booking_date` datetime DEFAULT NULL, `create_time` datetime DEFAULT NULL, `update_time` datetime DEFAULT NULL, PRIMARY KEY (`order_id`), KEY `idx_user_id` (`user_id`), KEY `idx_bdate` (`booking_date`), KEY `idx_ctime` (`create_time`), KEY `idx_utime` (`update_time`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;Add processor handler
@CanalHandler(value = "orderInfoHandler", destination = "example", schema = {"order_center"}, table = {"order_info"}, eventType = {CanalEntry.EventType.UPDATE, CanalEntry.EventType.INSERT,CanalEntry.EventType.DELETE}) public class OrderHandler implements Handler<CanalEntryBO> { @Override public boolean beforeHandle(CanalEntryBO canalEntryBO) { if (canalEntryBO == null) { return false; } return true; } @Override public void handle(CanalEntryBO canalEntryBO) { //1. 更新后数据解析 OrderInfoDTO orderInfoDTO = CanalAnalysisUti.analysis(OrderInfoDTO.class, canalEntryBO.getRowData().getAfterColumnsList()); System.out.println("event:" + canalEntryBO.getEventType()); System.out.println(orderInfoDTO); //2. 后续操作 TODO } }add configuration
canal: clients: simpleInstance: enable: true mode: simple servers: XXXXX:11111 batchSize: 1000 destination: example getMessageTimeOutMS: 500 #zkInstance: # enable: true # mode: zookeeper # servers: 172.30.1.6:2181,172.30.1.7:2181,172.30.1.8:2181 # batchSize: 1000 # #filter: order_center.order_info # destination: example # getMessageTimeOutMS: 500Configuration instructions:
public class CanalProperties { /** * 是否开启 默认不开启 */ private boolean enable = false; /** * 模式 * zookeeper: zk集群模式 * simple: 简单直连模式 */ private String mode = "simple"; /** * canal-server地址 多个地址逗号隔开 */ private String servers; /** * canal-server 的destination */ private String destination; private String username = ""; private String password = ""; private int batchSize = 5 * 1024; private String filter = StringUtils.EMPTY; /** * getMessage & handleMessage 的重试次数, 最后一次重试会ack, 之前的重试会rollback */ private int retries = 3; /** * getMessage & handleMessage 的重试间隔ms * canal-client内部代码 的重试间隔ms */ private int retryInterval = 3000; private long getMessageTimeOutMS = 1000;
Test insert and update operations
mysql> insert into order_info(order_id,user_id,status,booking_date,create_time,update_time) values(6666666,6,10,"2022-02-19 00:00:00","2022-02-19 00:00:00", "2022-02-19 00:00:00"); Query OK, 1 row affected (0.00 sec) mysql> update order_info set status=20 where order_id=66666; Query OK, 0 rows affected (0.00 sec) Rows matched: 0 Changed: 0 Warnings: 0 mysql>Test Results
2022-02-18 19:29:52.399 INFO 47706 --- [ lc-work-thread] c.b.s.canal.cycle.SimpleCanalLifeCycle : **************************************************** * Batch Id: [11] ,count : [3] , memsize : [189] , Time : 2022-02-18 19:29:52.399 * Start : [binlog.000003:18893:1645183792000(2022-02-18 19:29:52.000)] * End : [binlog.000003:19123:1645183792000(2022-02-18 19:29:52.000)] **************************************************** 2022-02-18 19:29:52.405 INFO 47706 --- [ lc-work-thread] c.b.s.canal.cycle.SimpleCanalLifeCycle : ----------------> binlog[binlog.000003:19056] , name[order_center,order_info] , eventType : INSERT ,tableName : order_info, executeTime : 1645183792000 , delay : 400ms event:INSERT OrderInfoDTO{orderId=6666666, userId=6, status=10, bookingDate=2022-02-19 00:00:00, createTime=2022-02-19 00:00:00, updateTime=2022-02-19 00:00:00}You're done. At this point, you have successfully completed the steps of Canal subscription and parsing binlog.
5. Precautions for data synchronization
Leaving aside two questions, you can think about it
How to solve the data loopback problem when data is synchronized in two directions?
For example, if the data generated by the new system is synchronized to the old system, it cannot flow back to the new system. How to solve it?
The problem of data order, if it is written to MQ, is it necessary to guarantee sequential consumption? How to achieve?
When the synchronization concurrency is relatively large, how to improve the synchronization speed.
Reminder: This topic is not finished. I will implement the above questions in the next article "System Refactoring Data Synchronization Tool: Canal Practical Combat-Continuation". You can think about it in advance.
Sixth, extra
Welcome everyone to pay attention to the public account of "Talking about Architecture" and share original articles from time to time
If you have any questions, please feel free to message me privately.
