Table of contents
4 Fine-tuning model based on RWKV
1 Introduction
Recently, artificial intelligence has been extremely hot. The emergence of ChatGPT has greatly promoted the development of natural language processing. Only two months after its launch, its monthly active users have reached 100 million, making it the fastest growing consumer application in history. OpenAI has been researching generative models, released GPT in June 2018, and released GPT3 in May 2020. The model parameters of GPT3 also reached 175 billion. But why did ChatGPT suddenly become popular now?
As we all know, the emergence capability of the model will only appear when it reaches a certain amount of parameters, but the parameters of the strong model have reached 175 billion in two years, which shows that the simple heap model parameters cannot achieve the desired effect. Perhaps the answer can be found in a paper InstructGPT (Training language models to follow instructions with human feedback) by OpenAI. Next, this article will briefly introduce InstructGPT, and then reproduce it based on RWKV. The reason for choosing RWKV is because of its fast speed and low GPU memory usage, which is convenient for quick experiments.
2 GPT model decoding
Here I feel that it is necessary to talk about the decoding output of the generative model separately. Only by understanding the principle of answer generation can we better understand the work done by InstructGPT.
GPT belongs to the generative pre-training language model. It only uses the Decoder structure of Transformers, and makes some changes to the Decoder, and removes the second Multi-Head Attention. The inferential decoding process is the process of predicting the next token by using the current token and the state matrix of all previously input tokens until the bit terminator is output. For example, the input token sequence is [u1,u2,u3,u4,u5], the dictionary size is 20000, then the output
In the above formula, the state matrix of all words is input for the front, that is, the word vector of each word is saved, which
is a 1*20000 matrix. If the model at this time has not undergone any fine-tuning, the distribution at this time is relatively scattered , how to choose a suitable word from 20,000 words has several options:
The first type: greedy search (greedy search), take the highest probability every time. Greedy search is a local optimum, but it cannot guarantee a global optimum.
The second type: beam search (beam search), each time the top-b sentences with the highest score are taken. The calculation of the score is very important, but this is not the focus of what I want to talk about. If you are interested, you can find out by yourself. This approach is slightly better than greedy search.
The third type: random sampling, each time one is randomly selected according to the probability, the higher the probability, the more likely it is to be sampled. Based on this, there are improved solutions such as temperature sampling, top-k sampling and top-p sampling. Random adoption is a relatively frequent method currently used, here is a brief introduction.
temperature sampling : Set a temperature parameter to control the degree of dispersion of the probability distribution. The closer the temperature is to 0, the difference between the values will be enlarged exponentially, and the range of the sampled values will be smaller. It is reflected in the answer that the result of multiple decodings will not be different. too much change.
top-k sampling: Take the top-k words with the highest probability as candidate sampling words, and set the rest to 0.
top-p sampling: Sort the words according to the probability from large to small, and accumulate from the first word until the cumulative sum is greater than or equal to top-p, as candidate sampling words, and the rest are set to 0.
Random selection is generally a combination of several methods, but sometimes no matter how the combination is adjusted, the model still encounters a situation where the terminator cannot be generated, that is, an infinitely long sequence with a probability of zero is generated, and the longest length limit or As the output length increases, increase the probability of terminators, etc.
Based on the above problems, the academic community has been exploring new methods that can make the correct answer (the answer people want) generated with a higher probability, so that it can be decoded more easily, and InstructGPT uses artificial feedback reinforcement learning to explore.
3 InstructGPT
Address of InstructGPT paper: https://arxiv.org/pdf/2203.02155.pdf
To sum it up: large language models can generate simple answers that are untrue, harmful, and unhelpful to users. InstructGPT reduces the probability of this invalid output by instructing fine-tuning on various tasks and reinforcement learning with human feedback (RLHF).
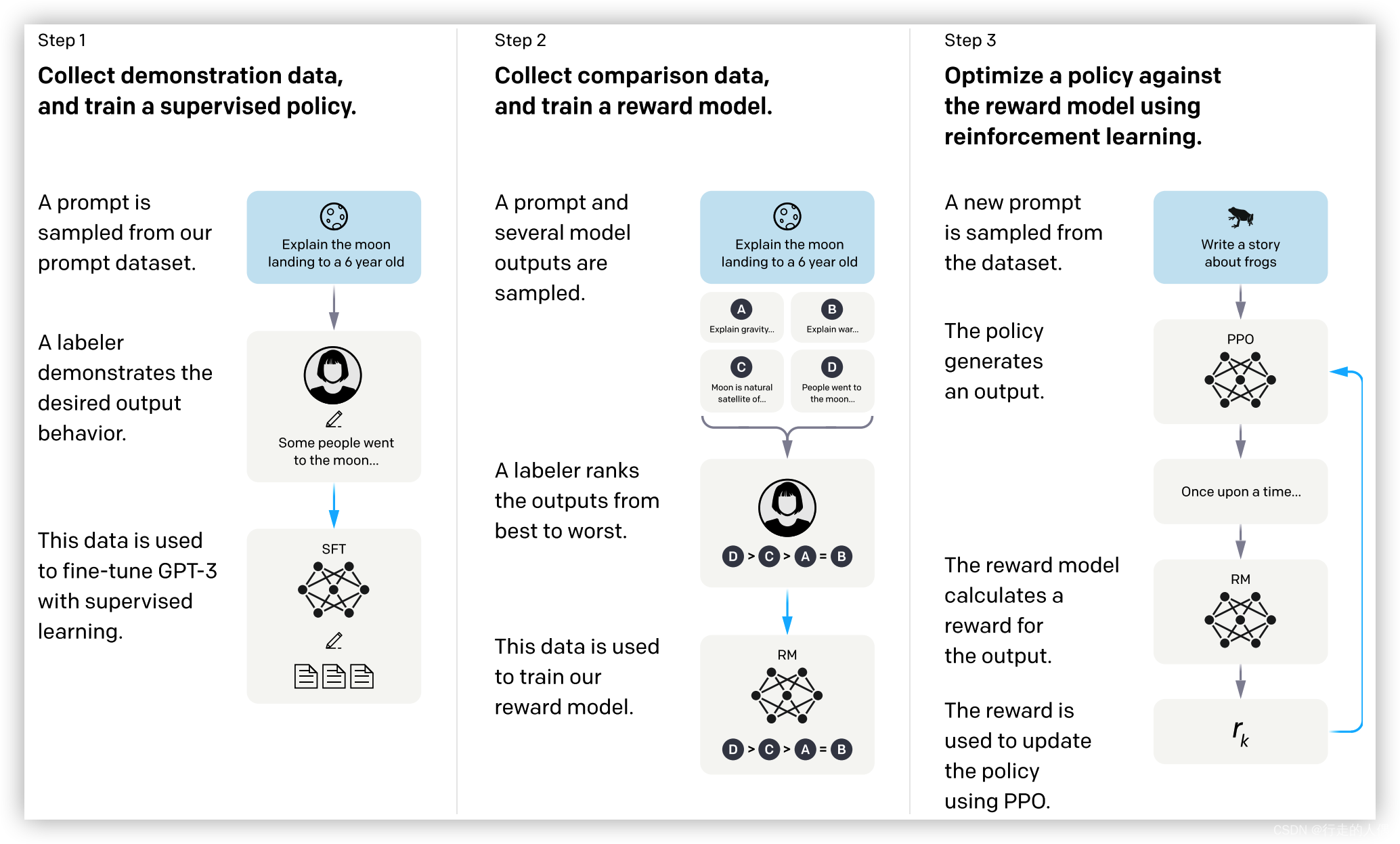
As can be seen from the figure, the two processes are carried out in three steps. Supervised fine-tuning SFT (supervised fine-tuning), training reward model (RM) and reinforcement learning (RL) fine-tuning.
SFT: Some people call this stage instruction fine-tuning and model fine-tuning, but these are not important. The purpose of this stage is only one, which is to enable the model to recognize instructions. After the training is completed, it is reflected in the decoding that there may be many answers to the instructions, and the probability of these answers is very high. After multiple random decodings, each decoding is basically inconsistent. If there is no fine-tuned model, the ability of the language model can only be used through the prompt to make the model understand the instructions. At this time, it is easier to answer the wrong question.
RM: Train a scoring model, that is, you can score the output of the model, which is convenient for later training PPO. The scoring model needs to manually label the data. The same prompt needs to have a good answer, and a bad answer constitutes a training corpus (it can also be understood that one is better than the other).
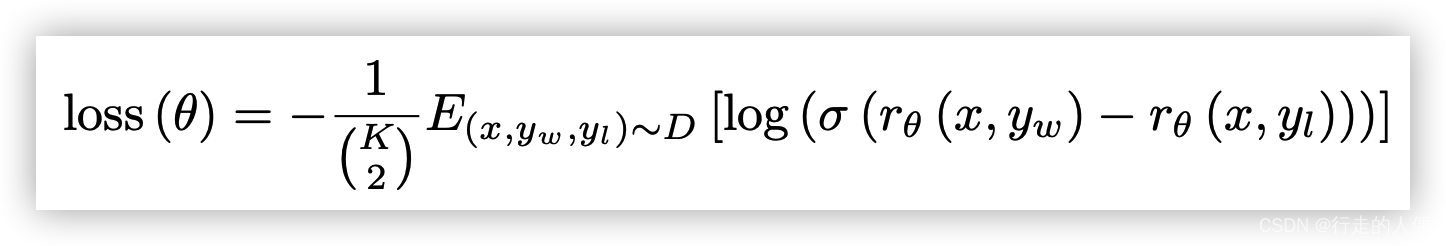
r is the scoring model, which can be obtained by adding a fully connected layer on the basis of the SFT model and transforming it into a classifier. x is the prompt, yw and yl are the two outputs of the RM model, one is a good answer and the other is a bad one. Answer, minimizing the loss is to expand the score difference between the two. Manually labeled data training will make answers that match human answers score higher.
RL: The proximal policy optimization model (reinforcement learning via proximal policy optimization) is mainly used. Refer to ColossalAI for the architecture diagram . Reinforcement learning fine-tuning will make answers with high scores have higher probability, and answers with low scores will have lower probability and increase the difference. Even if the parameters are not adjusted much during sampling, only the correct answer will be sampled.

4 Fine-tuning model based on RWKV
Based on the RWKV1.5B model as the base model, we use 100W CSDN blog articles and 30W Q&A data for incremental training in the Chinese vertical field, and use BELLE open source 50K instruction data for instruction fine-tuning. Here, the trained model is named ChatCSDN, and it is used as a reference for the Hello World of the entry-level large model.
Project address: https://gitcode.net/csdn/ai/chatcsdn
Model parameter address: zxm2023/ChatCSDN · Hugging Face .
4.1 Introduction to RWKV
In addition to the author's project, the introduction of RWKV (Receptance Weighted Key Value) has been released. For more details, please refer to the paper: https://arxiv.org/pdf/2305.13048.pdf
If you want to understand RWKV, you must first read Apple's AFT (An Attention Free Transformer) paper. It has the same structure as the standard attention algorithm and also includes the QKV structure. K and V are first combined with a set of learned position biases. Then carry out element-wise multiplication corresponding to the same element Q.

As can be seen from the above figure, the calculation of QKV is converted into linear calculation, and the speed has been greatly improved. But wt is a matrix that needs to be trained, the size is ctx_len*ctx_len, that is, the number of parameters of the model increases exponentially with the increase of the input length, and the length of sentences that the model can handle is severely limited.
RWKV is mainly improved for AFT. It can be seen from the attention calculation formula of AFT that its time complexity is, wt is changed to be calculated by the formula, and it is no longer obtained by training, so the time complexity becomes
, and can be extended to any length. It mainly introduces structures such as Position Matrix, Time-shit, TimeMix and ChannelMix . Compared with the original GPT structure, RWKV replaces self-attention with Position Encoding and TimeMix, and replaces FFN with ChannelMix.

RWKV project address: RWKV-LM/RWKV-v4neo at main BlinkDL/RWKV-LM GitHub
1.5B model parameter address: BlinkDL/rwkv-4-pile-1b5 · Hugging Face
4.2 Incremental pre-training
The RWKV model is basically trained in English. Here, Chinese CSDN blog data and question-and-answer data are used for incremental training in the vertical field, and some codes will also be introduced. If you also want to try incremental training, you can refer to the following steps.
Data preprocessing. Directly referring to the original author's data processing steps requires a lot of packages, and all the required packages have been transplanted into tools. First use the clean_ask_data and clean_blog_data methods in clean_data.py to convert the data pulled from the data warehouse into a jsonl file. Then enter the tools folder and use the following command to convert the data into idx and bin files:
python preprocess_data.py \
--input ../data/data.txt \
--output-prefix ../data/blog \
--vocab ../20B_tokenizer.json \
--dataset-impl mmap \
--tokenizer-type HFTokenizer \
--append-eodIncremental pre-training. Predict the nth word using the previous n-1 words.
x = torch.tensor(dix[:-1], dtype=torch.long)
y = torch.tensor(dix[1:], dtype=torch.long)It can be seen from the above section that x and y are just staggered by a token, for example: the tokens of the original sentence are [u1, u2, u3, u4, u5, u6], x is [u1, u2, u3, u4, u5], y is [u2, u3, u4, u5, u6].
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1))Use the above code to calculate loss.
python train.py --load_model "RWKV-4-Pile-1B5-EngChn-test4-20230115.pth" --wandb "" --proj_dir "out" \
--data_file "data/blog_text_document" --data_type "binidx" --vocab_size 50277 \
--ctx_len 1024 --epoch_steps 200 --epoch_count 1000 --epoch_begin 0 --epoch_save 10 \
--micro_bsz 8 --n_layer 24 --n_embd 2048 --pre_ffn 0 --head_qk 0 \
--lr_init 1e-5 --lr_final 1e-5 --warmup_steps 0 --beta1 0.9 --beta2 0.999 --adam_eps 1e-8 \
--accelerator gpu --devices 1 --precision bf16 --strategy deepspeed_stage_2_offload --grad_cp 1Use the command above to start training. load_model represents the model to be loaded, data_type is the data type, data_file is the training data, precision is the accuracy of the data, epoch_save is how often it is saved, ctx_len is the window length, how many tokens are in each piece of data, micro_bsz is the batch size, and the gpu memory is not enough Can be set smaller.
4.3 SFT fine-tuning
Construct the instruction data for training, and the corresponding role instructions are added here.
data_list = []
for index, row in pf.iterrows():
input = row["input"]
target = row["target"]
input_instruction = f"Below is an instruction that describes a task. Write a response that appropriately " \
f"completes the request.\n\n### Instruction: {input}\n\n### Response:"
input_tokens = self.tokenizer.tokenizer.encode(input_instruction)
target_tokens = self.tokenizer.tokenizer.encode(target)
if len(input_tokens) + len(target_tokens) > self.args.ctx_len:
continue
data_list.append((input_tokens, target_tokens))The two characters of the "### Instruction" and "### Response" Q&A dialogues. It is best to construct the prompt in the same way when writing any follow-up reasoning here.
def __getitem__(self, index):
ctx_len = self.args.ctx_len
req_len = ctx_len + 1
i = np.random.randint(0, len(self.data))
question, answer = self.data[i]
text = question + answer
text = text[:req_len]
text = text + [0] * (req_len - len(text))
x = torch.tensor(text[:-1], dtype=torch.long)
y = torch.tensor(text[1:], dtype=torch.long)
z = [0] * len(question) + [1] * (ctx_len - len(question))
z = torch.tensor(z, dtype=torch.long)Construct x, y, and z, and z represents mask, which will be used to calculate loss later, and will mask out the previous instruction.
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), reduction='none')
# loss_raw = loss
loss = torch.sum(loss * mask) / sum_mask4.4 RM and PPO
The RM and PPO codes have been preliminarily improved and are yet to be tested and trained.
5 tests
Run the trained model using chat.py, and the decoding method uses random decoding. Some results are as follows:
### Instruction: 你好
### Response:Hello! Nice to meet you!
### Instruction: 用java实现冒泡排序
### Response:以下是使用Java实现冒泡排序的代码:
```java
public void bubbleSort(int[] arr) {
for (int i = 0; i < arr.length - 1; i++) {
for (int j = 0; j < arr.length - i - 1; j++) {
if (arr[j] > arr[j+1]) {
int temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}
}
```
该方法的工作方式是,首先将数组排序,然后比较相邻的两个数字是否相等,如果相等,则交换它们的位置,并重新计算下一个数字的位置
### Instruction: +++
### Response:。
在实际应用中,您可以将此方法替换为任何其他适用的排序算法,例如快速排序、归并排序或基数排序等。
### Instruction: 帮我写一段JavaScript数组去重代码
### Response:```JavaScript
function uniqueArray(arr) {
// 去重
let unique = [];
for (let i = 0; i < arr.length; i++) {
if (arr[i] === arr[i]) {
unique.push(arr[i]);
}
}
return unique;
}
```
此方法将一个数组转化为一个新的数组,在此过程中,会判断每个元素是否已经在原数组中,如果是则不会重复元素,否则则会添加到新数组中去。这样就可以将原始数组转化为新数组,避免重复元素。
### Instruction: How about JOYI Sports Company? 翻译成中文
### Response:科基力学(JOYI)是一个怎样的公司?6 Summary
1. The speed of rwkv is already very fast, a single card can reach 450token/s , but it seems a bit powerless in the face of 100 million or even larger tokens (no, it should be more vivid).
2. For a model that has not been fine-tuned by reinforcement learning, the results of multiple random adoptions will be inconsistent. To get an ideal answer, you may need to try a few more times.
3. 1.5B is limited by the limitations of the language model itself, and the language ability is weak, so it is quite good for introductory learning to make large models. In the future, we will open source the code and model parameters for everyone to study and research together.