Article directory
Summary
The development of machine language intelligence, especially large-scale pretrained language models (PLMs), is discussed. This review details the evolution of language models from statistical language models, neural language models to pretrained language models (PLMs). The authors emphasize that model extension of large-scale LLMs beyond a certain parameter size leads to the emergence of new capabilities. This phenomenon has led to the creation of powerful AI chatbots, such as ChatGPT, that can solve complex tasks and exhibit excellent conversational abilities with humans. This review highlights the need to evaluate and understand the performance of LLMs, including their pre-training, adaptation, utilization, and capacity assessment. This paper explains that the development of LLMs is not limited to academic research, but also involves practical experience in large-scale data processing and distributed parallel computing. This review provides a comprehensive review of the literature on LLMs and is a useful resource for both researchers and engineers.
introduce
Language is the most important means of communication for human beings, but machines cannot naturally grasp and use human language. Language modeling is one of the main approaches to improving machine language intelligence, which aims to predict the probability of future (or missing) tokens. LM research has gone through four stages of development. Achieving machines that read, write, and communicate like humans has long been a research challenge.
- Statistical language models (SLMs) are word prediction models based on the Markov assumption, which improve task performance by predicting the next word, and are widely used in information retrieval (IR). N-gram language models are a special kind of SLMs in which the context length n is fixed, such as bigram and trigram language models. However, there is a data sparsity problem in high-order language model estimation, which makes it difficult to accurately estimate transition probabilities, thus requiring specially designed smoothing strategies such as backoff estimation and Good-Turing estimation.
- A neural language model (NLM) is a model that represents the probability of a sequence of words through a neural network. The development of NLM has gone through many milestone researches, such as the introduction of the concept of distributed representation of words, the development of a general neural network method by extending the idea of learning effective features of words or sentences, and the construction of a simplified shallow neural network. Network word2vec to learn distributed word representations. These studies pioneered the application of language models in representation learning and had an important impact on the field of natural language processing.
- The pre-trained language model (PLM) is an important tool in NLP tasks. Early attempts such as ELMo and BERT, a highly parallelized Transformer architecture based on a self-attention mechanism, were proposed. These pre-trained context-aware word representations are very effective as general-purpose semantic features and can greatly improve the performance bar of NLP tasks. Subsequent work introduced a variety of different architectures and improved pre-training strategies. PLM usually needs to be fine-tuned for different downstream tasks.
- Scaling large language models (PLMs) often improves model capacity and performance, and the research community has coined the term "Large Language Models (LLM)" for these large PLMs. Although scaling is mainly on model size, large PLMs exhibit different behaviors from small PLMs and show surprising capabilities in solving complex tasks. ChatGPT2 is a remarkable application of LLM, which enables amazing conversations with humans.
This paper introduces the latest progress in natural language generation models (LLM), focusing on the techniques and methods for its development and use, and gives an overview of the latest progress in four aspects: pre-training, adaptation, utilization, and capability assessment. LLM has three main differences from small PLMs, including showing surprising emergent capabilities, changing the way humans develop and use AI algorithms, and involving engineering problems such as large-scale data processing and distributed parallel training in training. Despite the progress and impact of LLM, its underlying principles are still not well explored. In addition, due to the huge cost of model pre-training and many details not disclosed to the public, it is difficult for the research community to train a capable LLM for it. The article points out that the research and development of LLM has the characteristics of both opportunities and challenges, which deserves attention. Finally, the article summarizes the main findings of this survey and discusses remaining issues for future work.
review
In this section, we introduce the background of LLM, including key terms, capabilities, and techniques.
Background A large-scale language model refers to a language model with hundreds of billions of parameters that is trained on a large amount of text data. It uses the Transformer architecture and pre-training targets, and improves understanding of natural language and Ability to generate high-quality text. The increase in model size roughly follows a scaling law, but some capabilities are only observed when the model size exceeds a certain level.
LLM has emergent capabilities whose emergent capabilities appear in large models but not in small ones. When the emergent ability appears, when the equivalence reaches a certain level, its performance is significantly higher than the random level. The emergent mode of LLM is closely related to the phenomenon of phase transition in physics. LLM has three typical emergent abilities, which can be applied to the general ability to solve multiple tasks.
- GPT-3 can learn in-context by completing the word sequence of the input text to generate the expected output for the test instance without additional training or gradient updates;
- Through instruction tuning, it is able to perform new tasks by understanding task instructions without using explicit examples, thereby improving generalization;
- Using the chain of thought reasoning strategy, complex tasks can be solved using a hint mechanism that includes intermediate reasoning steps. This ability may be acquired through code training.
The key technology of LLM LLMs is a machine learning model with high learning ability. After a long period of development, its key technology has been continuously improved and the ability of LLMs has been improved. Several successful important technologies include: technology improves the accuracy of LLMs and efficiency.
This paper discusses the optimization methods of language models, mainly including scalability, excitation ability, alignment adjustment and use of external tools. Scalability is a key factor for improving model capacity, and this method needs to consider optimal scheduling in three aspects: model size, data size, and total computation. Motivation involves devising appropriate task instructions or situation-specific strategies to develop a model's problem-solving abilities. Alignment adjustment is a method to ensure that the model is consistent with human values, and prevent the model from producing toxic, biased, and harmful content to humans. Finally, using external tools can compensate for the shortcomings of the model in terms of text generation and access to up-to-date information. Through these methods, more reliable and effective language models can be constructed.
In addition, many other factors such as hardware upgrades also contribute to the success of LLM. In the meantime, we limit our discussion to the technical approach and key findings for developing LLM.
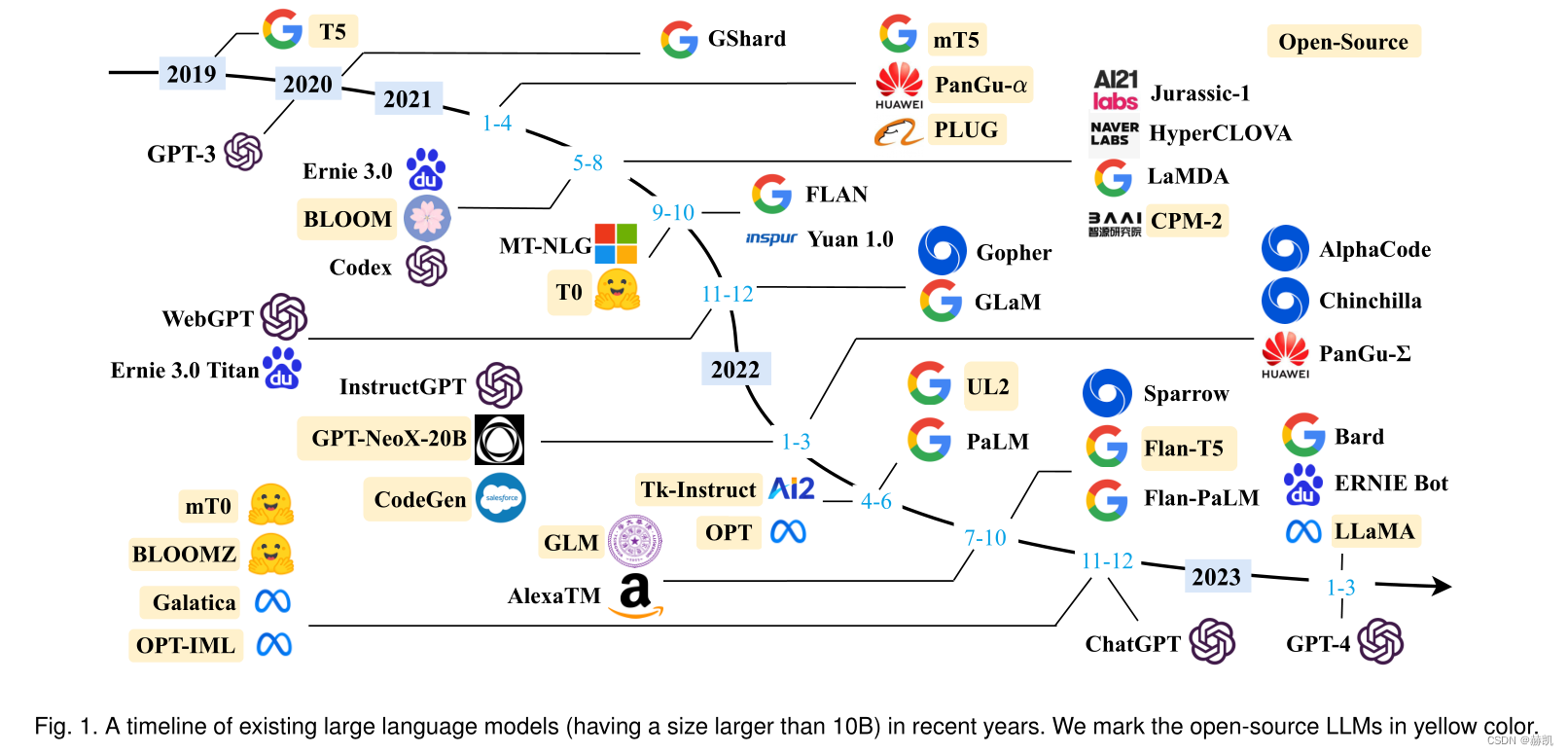
LLMS resources
Developing or replicating an LLM is not easy, given the technical issues and computational resource requirements. A feasible approach is to use existing LLM experience and public resources for incremental development or research, which includes open source model checkpoints and APIs, available corpora, and useful libraries for LLM. This section summarizes these resources.
Publicly available model checkpoints or APIs
The enormous cost required for model pre-training makes well-trained model checkpointing crucial. Since parameter scale is a key factor for using LLMs, we classify these public models into two scale levels (i.e., billions of parameters or tens of billions of parameters), which helps users choose appropriate resources according to their resource budget. Also, for inference, we can directly use public APIs to perform tasks without running the model locally. This section briefly summarizes the common checkpoints and API usage of LLMs.
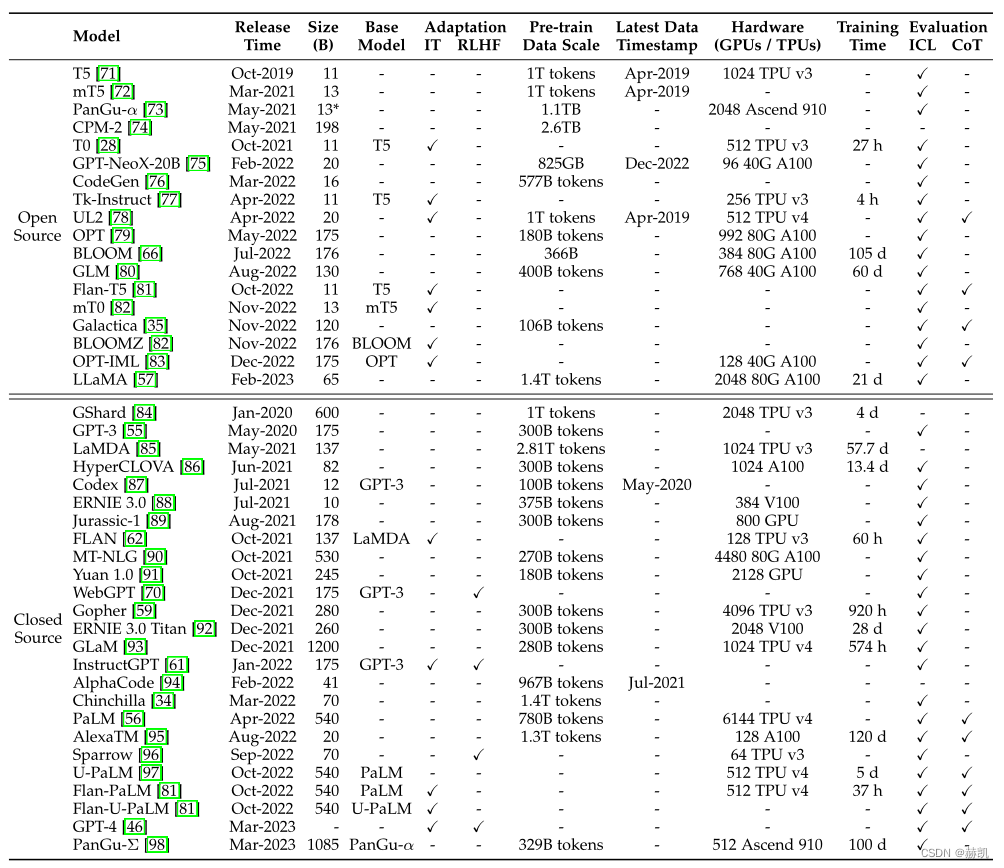
Models with Billions of Parameters
The parameter size of most open source models is between 10B-20B, while the largest version of LLaMA contains 65B parameters. Other models include mT5, T0, GPT-NeoX-20B, CodeGen, UL2, Flan-T5, mT0, and pangua. Among these models, Flan-T5 (version 11B) is suitable for instruction tuning research, and CodeGen (version 11B) is suitable for code generation. For multilingual tasks, mT0 (version 13B) can be considered. Pangu-α performs well in Chinese downstream tasks, the largest version has 200B parameters, while LLaMA requires thousands of GPUs or TPUs. For example, GPT-NeoX-20B uses 12 Supermicro servers, while LLaMA uses 2048 A100-80G GPUs. It is recommended to use FLOPS to estimate the required computing resources.
Models with hundreds of billions of parameters
For some models with hundreds of billions of parameters, only a few are publicly released, such as OPT[79], OPT-iml[83], BLOOM[66], and BLOOMZ[82], etc. Among them, OPT (version 175B) is used for open source sharing and can be used for large-scale reproducible research. These models require thousands of GPUs or TPUs for training. Galactica, GLM, and OPT-IML have been tuned using instructions and may be good candidates to study the effect of instruction tuning. BLOOM and BLOOMZ can be used as basic models for cross-lingual generalization research.
LLM public API
The API does not need to run the model locally, providing users with a convenient way to use it. Among them, the API of the GPT series model is widely used, including 7 main interfaces: ada, babbage, curie, davinci, text-ada-001, text-babbage-001 and text-curie-001. These interfaces can be further tuned on OpenAI's host server. Babbage, Curie, and Da Vinci correspond to different versions of the GPT-3 model, and there are also enhanced versions such as Codex-related APIs and GPT-3.5 series. The GPT-4 series of APIs has recently been released, and the specific choice depends on the application scenario and response requirements. See the project website for details.
common corpus
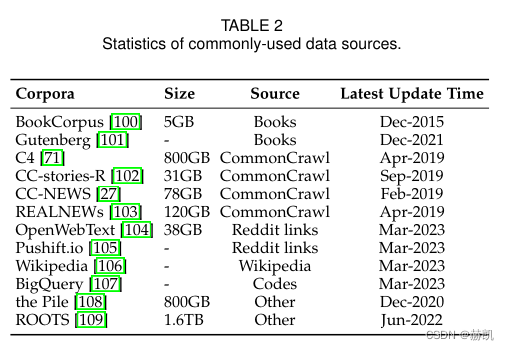
LLMs require more training data because it consists of a large number of parameters and needs to cover a wide range of content. To meet this need, more and more training datasets are released for research. These corpora are divided into six groups based on content type: Books, CommonCrawl, Reddit Links, Wikipedia, Code, and Other.
books
BookCorpus and Project Gutenberg are commonly used small-scale and large-scale book corpora, with the latter including more than 70,000 different literary books. The larger Books1 and Books2 used by GPT-3 are not yet publicly available. These datasets are widely used for training in machine translation, natural language generation, and other language processing tasks.
CommonCrawl
The open-source web crawling database CommonCrawl is one of the largest, containing gigabytes of data volume, but requires preprocessing due to noise and low-quality information in web data. There are four filter datasets commonly used in existing work: C4, CCStories, CC-News, and RealNews. Among them, C4 includes 5 variants, which have been used to train various models. CC-Stories, a subset of CommonCrawl data, is no longer available, but there are replicated versions. In addition, two news corpora REALNEWS and CC-News extracted from CommonCrawl are also often used as pre-training data.
Reddit link
Reddit is a social media platform that allows users to share links and text posts, and other users can vote on the quality of these posts. Some high-quality posts can be used to create advanced datasets such as WebText and PushShift.io. WebText is a corpus of highly liked posts from the Reddit platform, but the resource is not public. As an alternative, one can take advantage of the open source tool OpenWebText, while PushShift.io provides a dataset of real-time updates and full historical data that is easily searchable by users for initial processing and investigation.
Wikipedia
Wikipedia is a high-quality online encyclopedia covering a wide range of topics and fields and composed in an expository writing style. Its English-filtered version is often used in LLMs, including GPT-3, LaMDA, and LLaMA. At the same time, Wikipedia also has multiple language versions, which can be used in different language environments.
the code
The work mainly grabs open source licensed codes from the Internet, the main sources include GitHub and StackOverflow; Google has released the BigQuery dataset, which contains open source licensed code snippets in various programming languages, and CodeGen uses a subset of BIGQUERY to train multilingual Version.
other
Pile is a large-scale, diverse, and open-source text dataset, including over 800GB of data, consisting of 22 high-quality subsets. The Pile dataset is widely used for models of different parameter scales. ROOTS covers 59 different languages, with a total of 1.61 TB of text, used to train BLOOM.
LLMs now take multiple data sources for pre-training instead of a single corpus. The current research uses multiple off-the-shelf datasets for mixed processing, and also needs to extract data from relevant sources to enrich the pre-training data. Among them, GPT-3, PaLM, and LLaMA are representative LLMs, and their pre-training corpora include multiple sources, such as CommonCrawl, WebText2, Wikipedia, social media conversations, Github, etc. Among them, GPT-3 is trained on a mixed dataset of 175B, while the pre-training dataset sizes of PaLM and LLaMA are 540B and 1.0T~1.4T tokens, respectively.
library resources
Describes several libraries available for language model development. The most popular of these is Transformers maintained by Hugging Face, which uses the Transformer structure and provides pre-trained models and data processing tools. Both Microsoft's DeepSpeed and NVIDIA's Megatron-LM support distributed training and optimization techniques. Google Brain's JAX provides hardware acceleration support, and EleutherAI's Colossal-AI develops the ColossalChat model based on JAX. OpenBMB's BMTrain focuses on simplicity and usability, while FastMoE supports the training of Mixture-of-Experts models. In addition to these libraries, existing deep learning frameworks (such as PyTorch, TensorFlow, etc.) also provide support for parallel algorithms.