
Preface
The previous article talked about Dalexthe specific reasoning process that can be used to explore and explain the model. In this article, we continue to talk about the AIsecurity challenges that the model encounters in the face of ambiguity bias, adversarial sample attacks, and privacy leaks.
safety
The security of artificial intelligence is a new field, with risks such as ambiguity bias, adversarial sample attacks, and privacy leaks.
ambiguity bias
In reinforcement learning, we generally need to set an incentive goal as a reward, and then punish wrong behavior. However, the deviation in the definition of the reward function will cause unexpected errors in specific scenarios. Since this specific scenario is difficult to detect, it will give people the illusion of "very reliable" in the actual production environment.
For example, in OpenAIthe research project of , CoastRunnersreinforcement learning training was performed on this game. The object of the game is to complete the rowing race quickly, preferably ahead of other opponents, and the winner is determined by hitting the targets along the way to get the highest score.
Intuitively speaking, the boat has 上下左右4 actions, which are obviously 击中目标的分数the first incentive, 领先对手the second incentive, and the penalty is to travel to the remaining empty positions.

During the training RLprocess of the model, some unexpected behaviors occurred. The agent finds an isolated loop where it can turn in a large circle and knock down three targets repeatedly, and controls the gaps in movement so that it always hits when the reward target refreshes. Despite repeatedly catching fire, bumping into other boats, and taking the wrong turn on the course, the model managed to use this strategy to achieve a higher score than it could have achieved by completing the course in the normal way. The reinforcement learning model achieved better scores than humans. The average player score is 20% higher.
Obviously, this game has an implicit victory goal, which is that you must complete the game. Although this is just a small game, harmless and fun, it exposes a major pitfall of reinforcement learning. It is difficult or even completely unclear what the trained agent wants to do. If the reward refresh time or the map changes slightly along the way, maybe this model can pass the verification of the test set perfectly and cause damage in the production environment.
To prevent this kind of ambiguity in the design of the incentive function, OpenAIseveral research directions have been proposed:
Avoid taking rewards directly from the scene and instead learn to mimic human behavior.
In addition to imitating humans, you can also add evaluation nodes at key locations (such as punishment for not progressing for a period of time), or even add human intervention in an interactive way.
Perhaps transfer learning can be used to train many similar games and infer the "common sense" reward function for this game. This kind of reward might prioritize completing a match based on the classic game, rather than focusing on that specific game reward, thus being more in line with how humans play the game.
These methods may have their own shortcomings, and the transfer learning method itself may be wrong. For example, an agent trained on many racing video games might incorrectly conclude that driving in a new, higher-risk environment is less of a problem.
Solving these problems will be complicated. In reality, the objective function approaches multiple value targets at the same time, which makes it exponentially more difficult to design a reliable incentive function. At this stage, it is difficult to implement reinforcement learning. More simulation tests will enable us to quickly discover and solve new failure modes, and ultimately develop a system whose behavior can be truly trusted.
Adversarial sample attacks
In the field of computer vision, using deep neural networks for classification is almost the best choice. The recognition rate of most current mainstream models can easily exceed that of the human eye. But if you can know lossthe function of the classification model, you can design the gradient function in a targeted manner to generate the corresponding attack sample in reverse.
These adversarial examples are perturbed only so slightly that the human visual system cannot detect the perturbation (the images look almost the same). Such an attack would cause the neural network to completely change its classification of the image.

This kind of adversarial attack network carries great risks whether in the field of face recognition or autonomous driving scenarios. Do you dare to imagine that the car in front can be perfectly blended into the background with a sticker; or that a traffic turn sign can cause a car accident if it is covered with a translucent film that humans cannot detect...
To defend against this kind of attack, attack samples are generally generated first, and then mixed into the training set. By replacing the category variables in the adversarial perturbation with the category with the smallest recognition probability (target category), and then subtracting the perturbation from the original image, the original image becomes It becomes an adversarial sample and can output the target category.
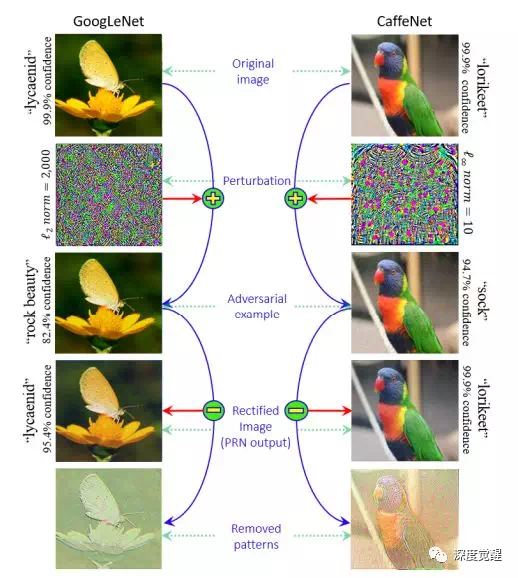
A few years ago, I participated in a competition that was used to confuse military satellites to identify our own military targets. Here I would like to share the competition plan that ultimately won the runner-up.

First use the original images to train the baseline model
Xception,The data set is then augmented with an adversarial neural network;
Then use the real battle data set to remove noise and add pseudo labels;
Next, transfer learning is used to train the baseline model into
EfficientNeta model;Finally, images of two scales are used for multi-model fusion output.
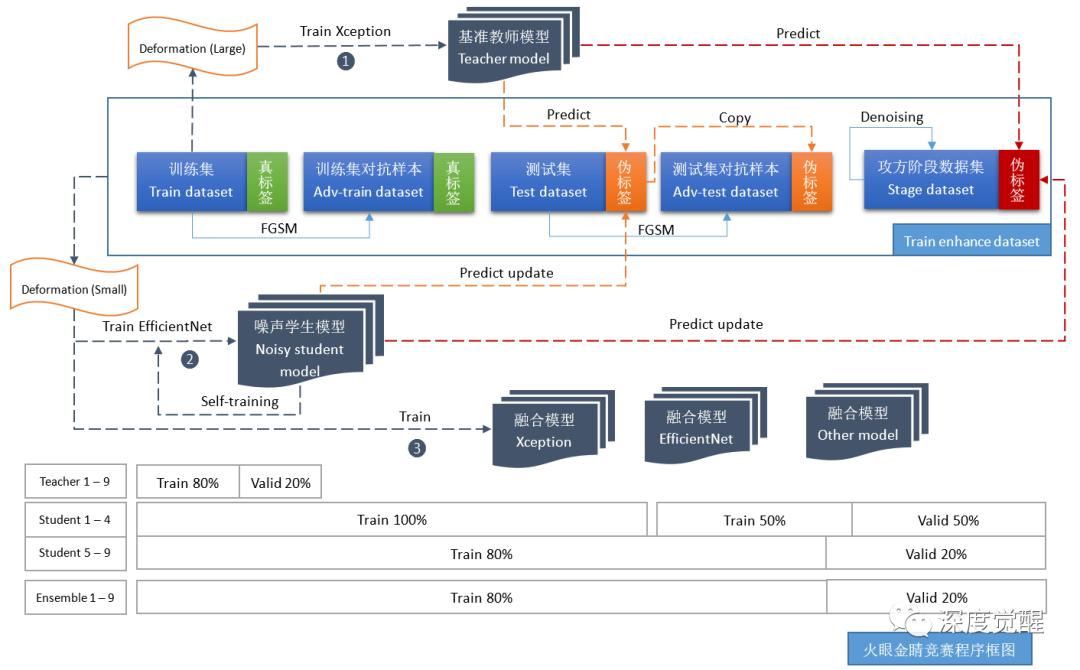
Among them, FGSMimage de-noising, image multi-scale, transfer learning and model fusion can effectively defend against adversarial sample attacks.
However, these require high computing power costs, and many methods can only be used in competitions. In actual business environments, they still face many challenges.
privacy protection
Privacy protection is another security area that is receiving more and more attention. Sensitive data mainly includes high-value data such as personal privacy information, passwords, keys, and sensitive pictures. In the past, Chinese people generally did not pay much attention to privacy, which objectively helped the development of artificial intelligence in China. After all, without data as fuel, it is impossible to generate high-quality basic models.

Foreign privacy protection is somewhat excessive, which has spawned a large number of data collectors to go deep into the grassroots level in my country to purchase data sets. In the long run, it actually poses a high risk to national security. Can we protect privacy while sharing data and improving model quality?
Data desensitization
First of all, the most direct method is to desensitize the sampled data set and achieve the purpose of protecting privacy by irreversibly transforming the sensitive data without destroying the data characteristics.

Commonly used desensitization algorithms include:
Hash desensitization: Irreversible, suitable for passwords or scenarios that require confirmation of sensitive data through comparison.
Masking desensitization: Irreversible, suitable for front-end display or sensitive data sharing scenarios, use special symbols * or # to mask part of the text to achieve desensitization of sensitive data.
Replacement desensitization: Partially reversible algorithm, suitable for desensitization of fields with fixed rules such as document numbers. Use a replacement code table for mapping replacement (reversible), or use a random interval for random replacement (irreversible) to achieve desensitization of the entire or partial content of the field.
Encryption desensitization: a reversible algorithm, suitable for scenarios where fields that need to be returned to the source are encrypted. Supports common symmetric encryption algorithms
DES,AESetc.Shuffling desensitization: irreversible, suitable for data desensitization scenarios at the column level of structured data. After extracting data from the source data table and confirming the value range, the field (within the range) is scattered, rearranged and randomly selected at the column level to achieve confusion and desensitization.
sklearnIt can be used when cleaning the data set LabelEncoderor OnehotEncoderpreprocessing string type features (irreversible replacement desensitization).
Face recognition can also be applied to the collected pictures to partially blur the detected faces.
Differential privacy protection
While personally identifiable information can be protected through data desensitization, some private information is inherent in the data itself.
For example, when it comes to a bank fraud risk application or a medical cancer diagnosis application, due to the extreme imbalance of samples, the accuracy rate is significantly improved after training a certain type of data or a certain type of data. That has a high probability of indicating that the user is a high-risk user or a disease patient.

Differential privacy is Dworka new privacy definition proposed in 2006 to address the problem of privacy leakage in statistical databases. Under this definition, the calculation and processing results of the database are insensitive to changes in a specific record. Whether a single record is in the data set or not in the data set has minimal impact on the calculation results. Therefore, the risk of privacy leakage caused by adding a record to the data set is controlled within a very small and acceptable range, and attackers cannot obtain accurate individual information by observing the calculation results.
加盐This kind of hidden privacy leakage is difficult to detect, so the training values can be corrected in a similar way during gradient calculation loss. This method is called 差分隐私保护(differential privacy).
Tensorflow Privacy
Tensorflow Privacy (TF Privacy)It is Googlean open source library developed by the research team. This library contains implementations of some common TensorFlowoptimizers that can be used to DPtrain machine learning models.
pip install tensorflow_privacyimport tensorflow as tf
from tensorflow_privacy.privacy.optimizers.dp_optimizer_keras_vectorized import (
VectorizedDPKerasSGDOptimizer,
)
# Select your differentially private optimizer
optimizer = VectorizedDPKerasSGDOptimizer(
l2_norm_clip=l2_norm_clip,
noise_multiplier=noise_multiplier,
num_microbatches=num_microbatches,
learning_rate=learning_rate)
# Select your loss function
loss = tf.keras.losses.CategoricalCrossentropy(
from_logits=True, reduction=tf.losses.Reduction.NONE)
# Compile your model
model.compile(optimizer=optimizer, loss=loss, metrics=['accuracy'])
# Fit your model
model.fit(train_data, train_labels,
epochs=epochs,
validation_data=(test_data, test_labels),
batch_size=batch_size)federated learning framework
The above privacy protection measures are generally only effective for users and visible to developers. Federated learning Federated Learningis a distributed machine learning framework that can train models on multiple distributed edge devices, exchanging only model parameters and weights without exchanging data sets. Since the data remains on the user's device and cannot be accessed even by developers, the highest standards of physical security can be achieved.
Here we introduce a very easy-to-use federated learning framework Flowerthat supports both Tersonflowand and PyTorchheterogeneous edge devices.
Flower
https://flower.dev/It is used grpcto form a master-slave distributed network to support research on various servers and devices including mobile devices. AWS, GCP, Azure, Android, iOS, Raspberry Pi, Nvidia Jetson, are all Flowercompatible with .
conda create -n fed python=3.7
conda activate fed
pip install flwr
pip install torch torchvision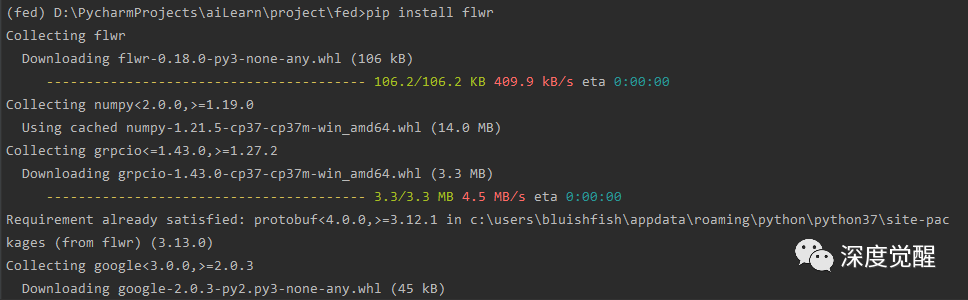
Create client
The client code is very different from the usual training model code. Import the library file.
from collections import OrderedDict
import warnings
import flwr as fl
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR10Build the network, read the data, and train the model. The only difference is that it needs to be encapsulated in a Clientclass.
def main():
"""Create model, load data, define Flower client, start Flower client."""
# Load model
net = Net().to(DEVICE)
# Load data (CIFAR-10)
trainloader, testloader, num_examples = load_data()
# Flower client
class CifarClient(fl.client.NumPyClient):
def get_parameters(self):
return [val.cpu().numpy() for _, val in net.state_dict().items()]
def set_parameters(self, parameters):
params_dict = zip(net.state_dict().keys(), parameters)
state_dict = OrderedDict({k: torch.tensor(v) for k, v in params_dict})
net.load_state_dict(state_dict, strict=True)
def fit(self, parameters, config):
self.set_parameters(parameters)
train(net, trainloader, epochs=1)
return self.get_parameters(), num_examples["trainset"], {}
def evaluate(self, parameters, config):
self.set_parameters(parameters)
loss, accuracy = test(net, testloader)
return float(loss), num_examples["testset"], {"accuracy": float(accuracy)}
# Start client
# fl.client.start_numpy_client("[::]:8080", client=CifarClient())
fl.client.start_numpy_client("localhost:8080", client=CifarClient())
It should be noted here that if this is Windowsthe case, grpcglobal addresses are not supported, and the connection address needs to be explicitly specified, such as localhostor the corresponding IPaddress.
Create server side
Import library file
from typing import List, Tuple, Optional
import numpy as np
import flwr as fl
from collections import OrderedDict
import torch
from client import NetThe server-side program mainly uses aggregate_fitthis hook function to collect client messages from each training model. Here, all parameters will be summarized each time, converted into corresponding weights, and checkpointmodel files will be generated and saved to the server.
DEVICE = "cuda:0"
class SaveModelStrategy(fl.server.strategy.FedAvg):
def aggregate_fit(
self,
rnd: int,
results: List[Tuple[fl.server.client_proxy.ClientProxy, fl.common.FitRes]],
failures: List[BaseException],
) -> Optional[fl.common.Weights]:
aggregated_parameters = super().aggregate_fit(rnd, results, failures)
if aggregated_parameters is not None:
# Convert `Parameters` to `List[np.ndarray]`
aggregated_weights: List[np.ndarray] = fl.common.parameters_to_weights(aggregated_parameters[0])
# Load PyTorch model
net = Net().to(DEVICE)
# Convert `List[np.ndarray]` to PyTorch`state_dict`
params_dict = zip(net.state_dict().keys(), aggregated_weights)
state_dict = OrderedDict({k: torch.tensor(v) for k, v in params_dict})
net.load_state_dict(state_dict, strict=True)
# Save PyTorch `model` as `.pt`
print(f"Saving round {rnd} aggregated_model...")
torch.save(net, f"round-{rnd}-aggregated_model.pt")
return aggregated_parametersBy default, there are at least 2 clients and 3 rounds of training. Each client updates 50% of the gradient value during each training.
if __name__ == "__main__":
# Define strategy
strategy = SaveModelStrategy(
fraction_fit=0.5,
fraction_eval=0.5,
)
# Start server
fl.server.start_server(
# server_address="[::]:8080",
server_address="localhost:8080",
config={"num_rounds": 3},
strategy=strategy,
)Distributed training
Start the server program and wait for the client connection...
python server.py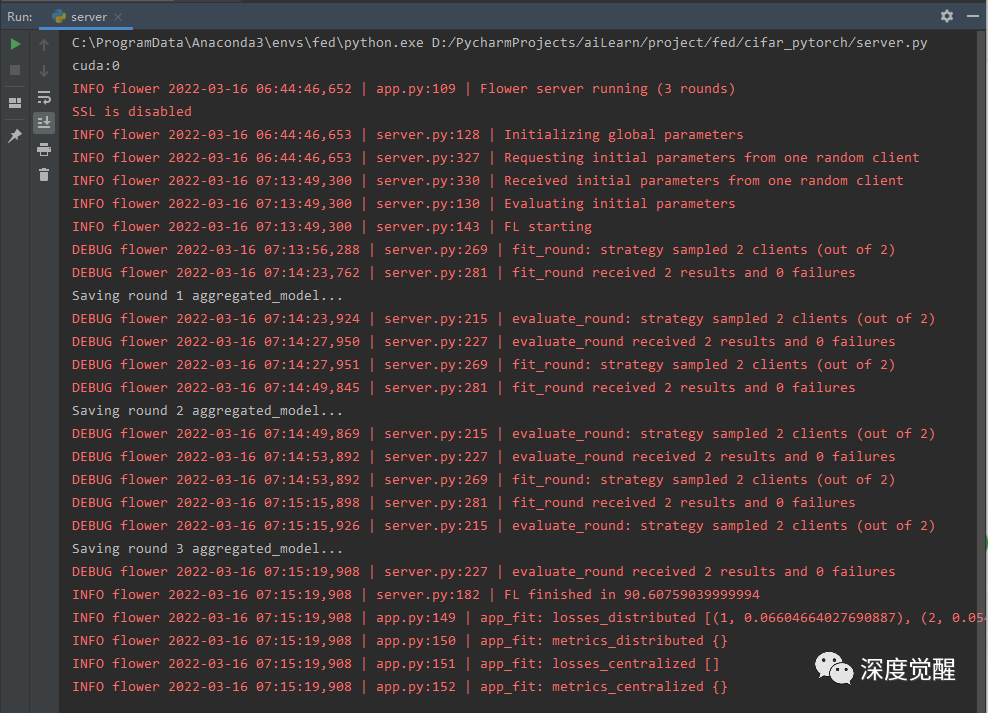
Then start 2 client programs respectively
python client.py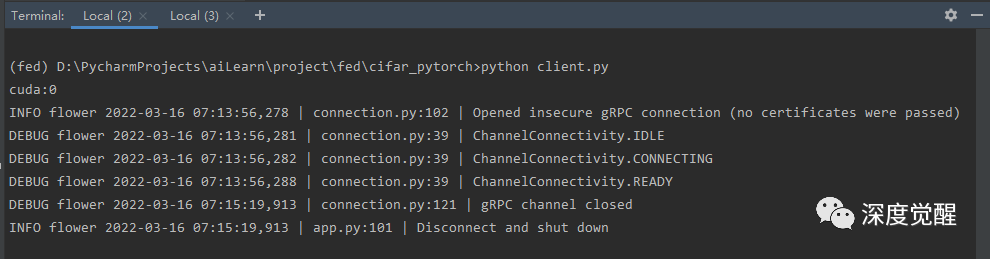
After training, you can find the saved model file on the server round-1-aggregated_model.pt, perfect!
Source code download
Relevant documents and information for this issue can be found on the public account "Deep Awakening" and reply: "explore02" in the background to obtain the download link.
Next article preview
This article mainly introduces the security aspects of the model, and tries to avoid the design of ambiguity bias, prevent adversarial sample attacks and use federated learning to protect privacy. In the next article, we will continue to explore the justice issue of artificial intelligence.
