The Evolution of Large Language Models
Based on the topic of the last technology tree pruning, "Large language model pruning again for the artificial intelligence technology tree" , let us take a look at how the branch of the large language model grows. The result of several wars in the company.
first round
In June 2017, Google's 65 million parameter Transformer model was released, and the Google Brain team (Google Brain) published an article called "Attention is all you need" at the Neural Information Processing System Conference (NeurIPS). All You Need" essay. This paper is regarded as the pioneering work of the large language model.
In June 2018, OpenAI released GPT-1 with 117 million parameters. GPT-1 adopts two stages of pre-training + FineTuning. It uses Transformer's decoder as a feature extractor and stacks a total of 12. At the same time, the paper "Improving Language Understanding by Generative Pre-training" was published (using generative pre-training to improve the language understanding of the model)
In October 2018, Google proposed the BERT (Bidirectional Encoder Representation from Transformers) with 300 million parameters, which is the "bidirectional encoding representation from Transformers" model.
At this time, BERT works better than GPT-1 because it is a two-way model that can be analyzed using context. GPT is a one-way model, which cannot use contextual information, but can only use the above.
second round
In February 2019, OpenAI launched GPT-2, with a maximum model of 48 layers and 1.5 billion parameters. At the same time, they published the paper "Language Models are Unsupervised Multitask Learners" (Language Models are Unsupervised Multitask Learners) introducing this model.
In 2021, Dario Amodei, vice president of OpenAI, broke with the company with 10 employees and established his own research laboratory Anthropic, which launched the product Claude.
In October 2019, Google proposed a new pre-training model T5 (Transfer Text-to-Text Transformer) in the paper "Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer", with a parameter volume of 11 billion , becoming a brand new NLP SOTA pre-training model.
At this time, T5 won by an absolute advantage, and Google still took the lead.
third round
In May 2020, OpenAI released GPT-3 with 175 billion parameters, and published the paper "Language Models are Few-Shot Learner" (Language Model for Small Sample Learners)
In January 2021, the Google Brain team launched the super language model Switch Transformer, which has 1.6 trillion parameters, 9 times the parameters of GPT-3.
In January 2021, OpenAI released the DALL-E model for generating images from text, a step beyond the language model towards multimodality.
In May 2021, Google demonstrated the LaMDA (Language Model for Dialogue Applications) dialogue application language model with 137 billion parameters.
In June 2021, OpenAI and GitHub jointly released a new AI code completion tool GitHub Copilot, launching a Codex with 12 billion parameters.
In March 2022, OpenAI released InstructGPT, introducing a human feedback mechanism. And published the paper "Training language models to follow instructions with human feedback" (combined with human feedback information to train the language model so that it can understand instructions). Compared with GPT3 with 175 billion parameters, people prefer the reply generated by InstructGPT with 1.3 billion parameters. Not bigger is better.
In July 2022, OpenAI released DALL-E 2;
At that time, the industry still recognized Google's big model more.
fourth round
On November 30, 2022, OpenAI released ChatGPT with about 200 billion parameters, which is a dialogue robot developed after fine-tuning the GPT-3 model (also known as GPT-3.5). The token limit of ChatGPT3 is about 4096, which is equivalent to about 3072 English words. The last update time of its training data is September 2021.
ChatGPT is not a product of intentional planting of flowers, but the result of unintentional planting of willows. At first, the team used it to improve the GPT language model. Because OpenAI found that in order for GPT-3 to produce what users want, reinforcement learning must be used to allow the artificial intelligence system to learn through trial and error to maximize rewards to improve the model. And chatbots could be ideal candidates for this approach, because constant feedback in the form of a human conversation would make it easy for the AI software to know when it's doing well and where it needs to improve. So, in early 2022, the team started building ChatGPT.
On January 23, 2023, Microsoft stated that it is expanding its partnership with OpenAI, continuing to invest approximately US$10 billion at a valuation of US$29 billion, and obtaining a 49% stake in OpenAI.
On February 7, 2023, Google released the next-generation dialogue AI system Bard, a ChatGPT-like product based on the large language model LaMDA.
On March 14, 2023, OpenAI released GPT-4, and did not announce the number of parameters. The maximum number of tokens is 32768, equivalent to about 24576 words, and the text length is expanded eight times. Multimodal input is supported, and the database was last updated in September 2021.
So far, OpenAI's GPT-4 has won. But there is also another hidden worry. GPT has become a fully enclosed large language model, and no detailed information is disclosed. The outside world can only use it through API.
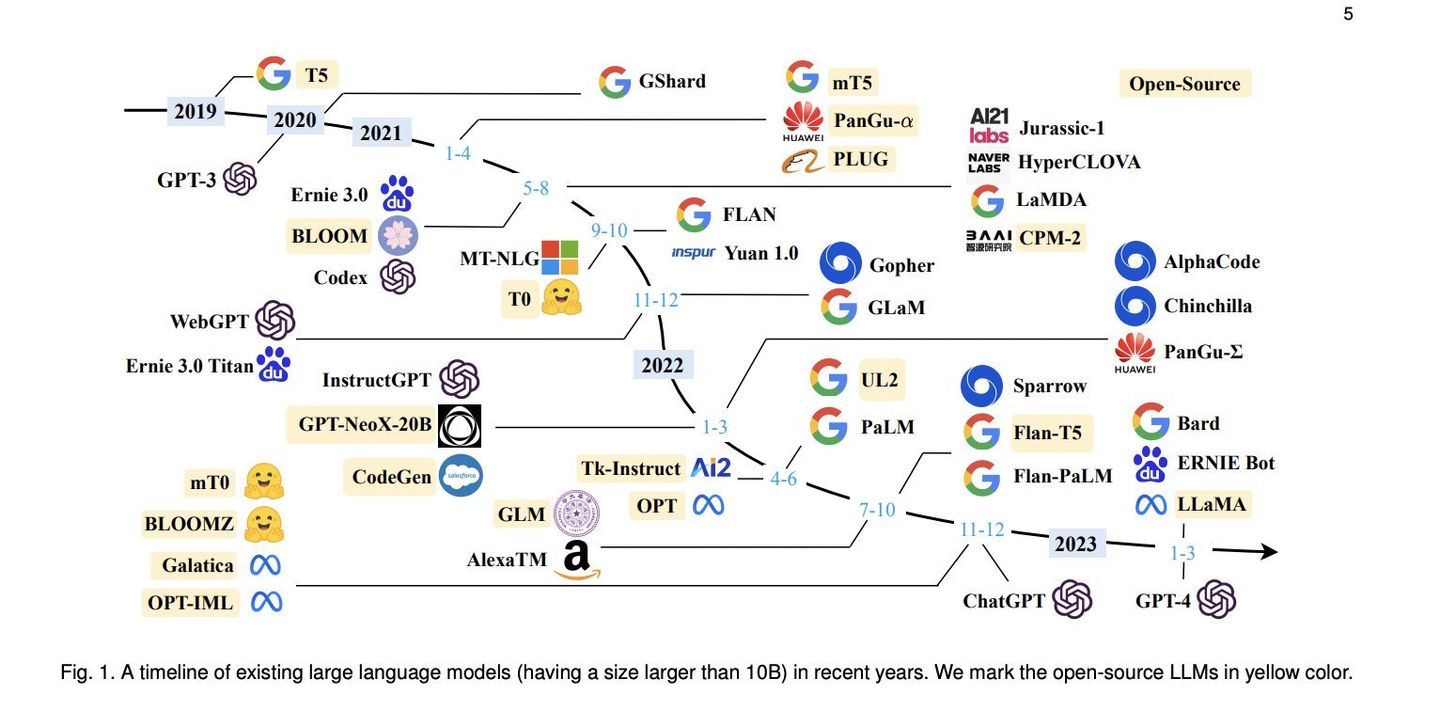
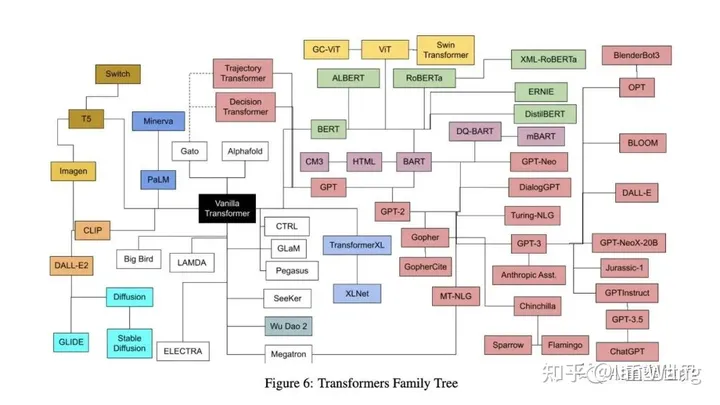
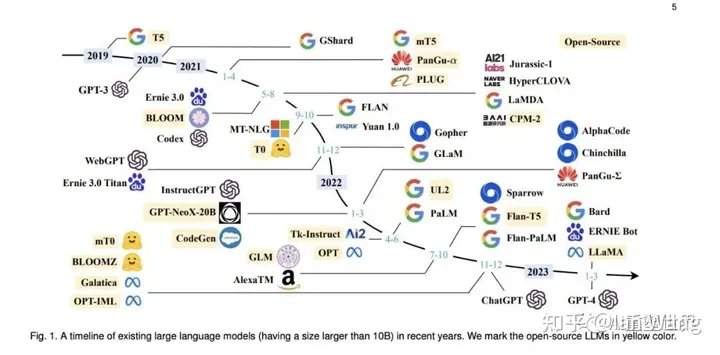
For the historical development process of the large model and the development of this technology tree, please refer to the figure below:
Open source large language model market: the big ones can't compete, let's fight for the small ones
On February 24, 2023, Meta released a new artificial intelligence large-scale language model LLaMA. The LLaMA model was trained on 20 languages, including Latin and Cyrillic languages. At present, there are four models with parameter scales of 7 billion, 13 billion, 33 billion and 65 billion. The performance of LLaMA-13 billion, which is only one-tenth of the parameter, is better than that of GPT3 (175 billion parameters) launched by OpenAI, that is, it supports ChatGPT is the predecessor of GPT3.5.
On March 14, 2023, Stanford University released Alpaca, a brand-new model fine-tuned by Meta's LLaMA with 7 billion parameters, using only 52k data, and its performance is about equal to GPT-3.5. Training costs less than $600.
On March 31, 2023, UC Berkeley teamed up with CMU, Stanford, UCSD, and MBZUAI to launch Vicuna with 13 billion parameters, which can achieve 90% of the performance of ChatGPT for only $300, and can run on a single GPU.
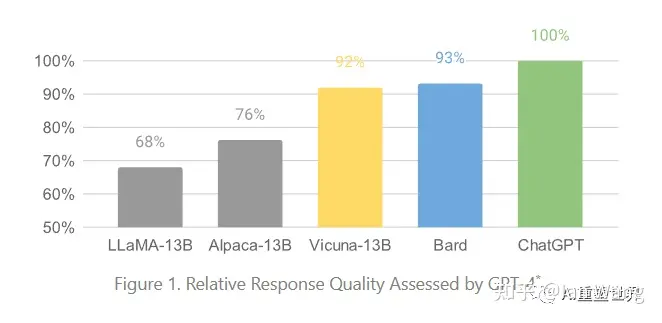
The open source model battle combination composed of LLaMA (llama), Alpaca (alpaca) and Vicuna (little alpaca) has helped those manufacturers who cannot access the GPT API to open up another broad market. See the figure below for data comparison:
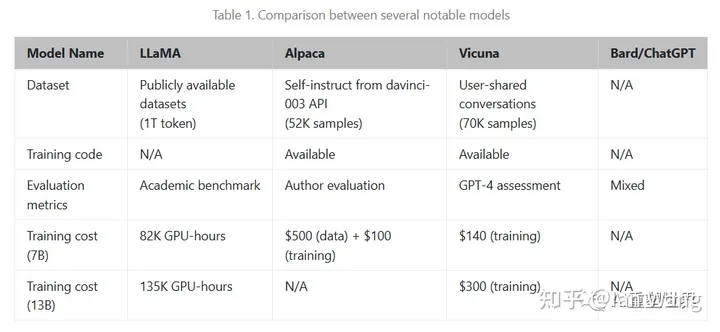
Now we generally talk about large language models, with parameters exceeding 10 billion. ChatGPT has opened a door for human beings, and let people see the dawn through the door. More and more companies will go on this road, making this branch of technology more prosperous.
Generally speaking, when it comes to large language models, the parameters exceed 10 billion. ChatGPT has opened a door for human beings, and let people see the dawn through the door. More and more companies will go on this road, making this branch of technology more prosperous.