2.1 Data flow
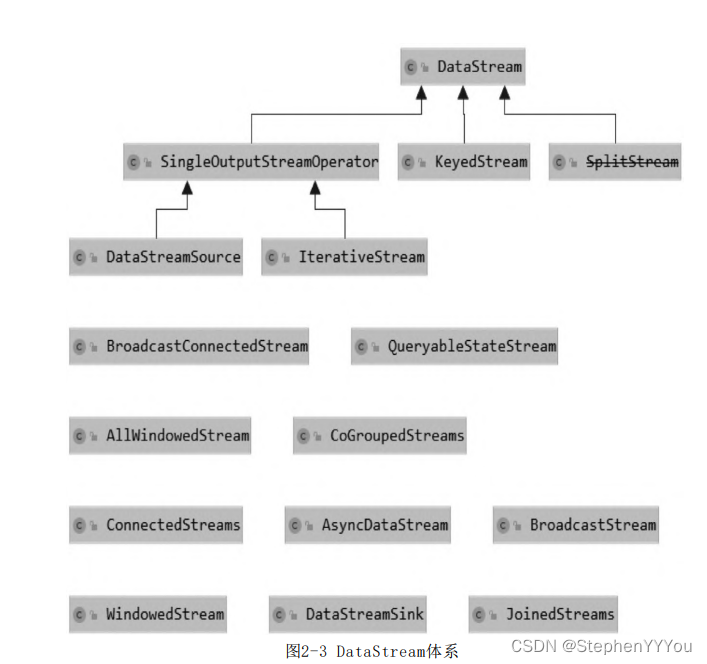

- DataStream: DataStream is the core abstraction of Flink data flow, which defines a series of operations on data flow
- DataStreamSource: DataStreamSource is the starting point of DataStream. DataStreamSource is created in StreamExecutionEnvironment and created by StreamExecutionEnvironment.addSource(SourceFunction), where SourceFunction contains the specific logic for DataStreamSource to read data from the data source.
- DataStreamSink: Data is read from DataSourceStream. After a series of processing operations in the middle, it needs to be written out to external storage. It is created by DataStream.addSink(sinkFunction), where SinkFunction defines the specific logic for writing data to external storage.
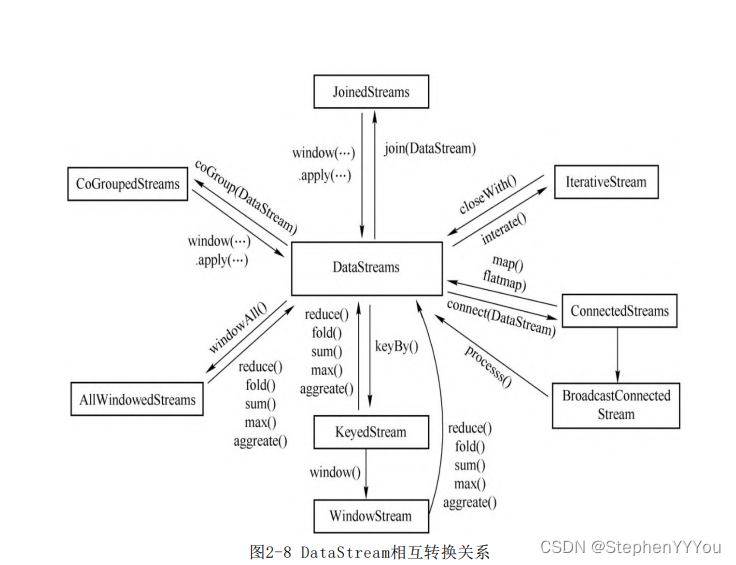
- KeyedStream: KeyedStream is used to represent the data stream grouped according to the specified key. A KeyedStream can be obtained by calling DataStream.keyBy(). Any Transformation performed on KeyedStream will be converted back to DataStream. In the implementation, KeyedStream writes key information into Transformation. Each record can only access the state of the key it belongs to, and the aggregation function on it can easily operate and save the state of the corresponding key.
- WindowedStream & AllWindowedStream: WindowedStream represents the data stream grouped by key and split into windows based on WindowAssigner. Therefore, WindowedStream is derived from KeyedStream, and any Transformation performed on WindowedStream will also be converted back to DataStream.
- JoinedStreams & CoGroupedStreams: The bottom layer of JoinedStreams is implemented using CoGroupedStreams.
- ConnectedStreams: ConnectedStreams represent the combination of two data streams, and the two data streams can be of the same type or different types.
- BroadcastStream & BroadcastConnectedStream: BroadcastConnectedStream is generally connected by DataStream/KeyedDataStream and BroadcastStream, similar to ConnectedStream.
- IterativeStream: IterativeDataStream is an iterative operation on a DataStream. Logically, the Dataflow containing IterativeStream is a directed and circular graph. At the underlying execution level, Flink performs special processing on it.
- AsyncDataStream: AsyncDataStream is a tool that provides the ability to use asynchronous functions on DataStream.
2.2 Processing function

- Map: 1 in 1 out
- FlatMap: 1 in and multiple out
- Filter: return true to continue passing
- KeyBy: for logical grouping
- Reduce: Incremental merge: Merge the current data with the last Reduce result according to the logical grouping in KeyedStream.
- Aggregation: Progressive aggregation, you can set the initial value.
- Window: For the data of KeyedStream, the time window is divided according to the Key.
- WindowAll: Time window segmentation for general DataStream, that is, one global window.
- Union: Merge two or more DataStreams, requiring consistent data types.
- connect: Only two streams can be merged, and the data types can be inconsistent. can share state
- Join: Join two DataStream data streams on the window of the same time range, and the output result is DataStream.
- Interval Join: Join two KeyedStreams that meet the time range, and the Key used when joining, and the output result is DataStream.
- WindowCoGroup: Two DataStreams apply CoGroup operations on the same time window, and the output result is DataStream. CoGroup and Join have similar functions, but are more flexible.
- Split: Segment the stream, and the data types of the front and back streams are consistent (the side output can be inconsistent)
- Select: Used in conjunction with the Split operation to select one of the multiple DataStreams split in the Split operation.
- Iterate: Creates an iterative loop in the data flow, sending downstream output to upstream for reprocessing. IteractiveStream is essentially an intermediate data stream object.
- Extract Timestamps: Extract timestamps from records and generate Watermark.
- Project: This type of operation is only applicable to DataStream of Tuple type. Using Project to select sub-Tuples can select some elements of Tuple and change the order of elements.

