This article was originally published on the Apache Flink official website, authorized by the original author Kostas Kloudas, and translated and shared on the InfoQ Chinese website.
Numerous platforms aim to simplify internal Application submission by reducing all operational burdens on end users. In order to submit Flink applications, these platforms usually only expose a centralized or low-parallel endpoint (such as a web front end) for application submission, and we will call the Deployer.
One of the obstacles often mentioned by platform developers and maintainers is that Deployer can be a large resource consumer that is difficult to configure. If configured according to the average load, it may cause the Deployer service to be overwhelmed by deployment requests (in the worst case, this is the case for all production applications in a short period of time), and planning according to the highest load will cause problems. The necessary cost. According to this observation, Flink 1.11 introduced Application mode (application mode) as a deployment option, which allows a lightweight and more scalable application submission process, so that the application deployment load is more evenly distributed across the cluster Node.
In order to understand this problem and how the Application pattern solves it, we first briefly outline the current state of application execution in Flink, and then explain the architectural changes introduced by the deployment pattern and how to use them.
Application execution in Flink
Executing an application in Flink mainly involves three entities: Client (client), JobManager (job manager) and TaskManager (task manager). The Client is responsible for submitting the application to the cluster, the JobManager is responsible for the necessary bookkeeping during execution, and the TaskManager is responsible for the actual calculations. For more details, please refer to Flink's architecture document.
Current deployment mode
Before the Application mode was introduced in version 1.11, Flink allowed users to execute applications on Session or Per-Job clusters. The difference between the two is related to the cluster life cycle and the resource isolation guarantees they provide.
Session mode
Session mode (session mode) assumes that the cluster is already running and uses the resources of the cluster to execute any submitted applications. Applications executing in the same (Session) cluster use the same resources and therefore compete with each other. The advantage of this is that you do not need to allocate the resource overhead of the entire cluster for each submitted job. However, if one of the jobs behaves abnormally or closes the TaskManager, all jobs running on the TaskManager will be affected by the failure. In addition to having a negative impact on the job that caused the failure, this also means a potentially large-scale recovery process where all restarted jobs access the file system at the same time and make it unavailable for other services. In addition, running multiple jobs in a single cluster means that JobManager has a greater load, which is responsible for the bookkeeping of all jobs in the cluster. This mode is very suitable for starting short jobs, such as interactive queries.
Per-Job mode
In Per-Job mode, the available cluster manager framework (such as YARN or Kubernetes) is used to start the Flink cluster for each submitted job, and the cluster is only available for that job. When the job is complete, the cluster will be shut down and all delayed resources (such as files) will be cleaned up. This mode allows for better resource isolation, because a misbehaving job will not affect any other jobs. In addition, since each application has its own JobManager, it spreads the bookkeeping load to multiple entities. Considering the resource isolation problem in Session mode mentioned earlier, users often choose Per-Job mode for long-running jobs, because these jobs are willing to accept a certain degree of start-up delay increase to support flexibility.
In short, in the Session mode, the cluster life cycle is independent of any job running in the cluster, and all jobs running in the cluster share its resources. Per-Job mode chooses to allocate a cluster for each submitted job, which already provides better guarantee of resource isolation, because resources will not be shared between jobs. In this case, the life cycle of the cluster is related to the life cycle of the job.
Application submission
Flink 应用程序的执行包括两个阶段:pre-flight,即当用户的 main() 方法被调用时;runtime,即用户代码调用execute()时立即触发。main() 方法使用 Flink 的 API(DataStream API、Table API、DataSet API)之一构造用户程序。当 main() 方法调用 env.execute() 时,用户定义的管道将被转换成一种 Flink 运行时可以理解的形式,称为 Job Graph(作业图),并将其传递给集群。
尽管它们方法有所不同,Session 模式和 Per-Job 模式都会在 Client 执行应用程序的 main() 方法,即pre-flight阶段。
对于已经在本地拥有作业的所有依赖项,然后通过在其机器上运行的 Client 提交其应用程序的单个用户来说,这通常不是问题。但是,对于通过远程实体(如 Deployer)提交的情况下,这个过程包括:
本地下载应用程序的依赖项;
执行 main() 方法提取 Job Graph;
将 Job Graph 及其依赖项发送到集群以便执行;
等待结果。
这使得 Client 消耗了大量的资源,因为它可能需要大量的网络带宽来下载依赖项或将二进制文件发送到集群,并且需要 CPU 周期来执行 main() 方法。随着越来越多的用户共享同一个 Client,这个问题甚至会变得更加突出。
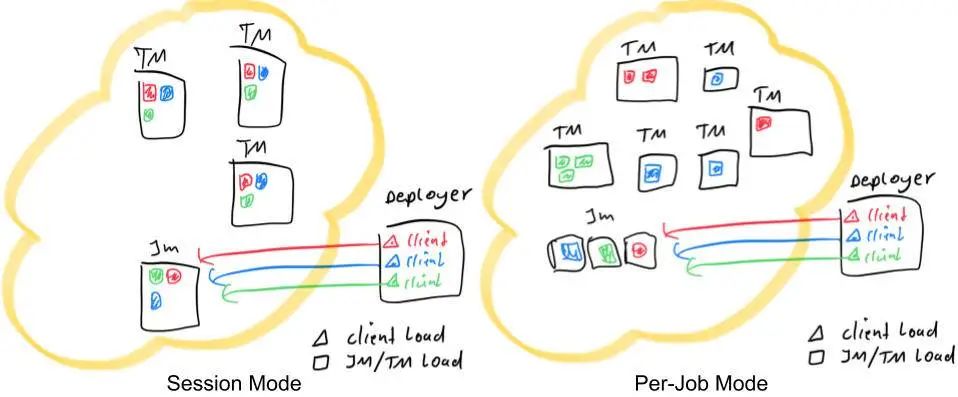
上图展示了使用红色、蓝色和绿色表示的三个应用程序的两种部署模式。每个矩形都有三个并行项。黑色矩形表示不同的进程,分别是 TaskManager、JobManager 和 Deployer。我们假设在所有情况下只有一个 Deployer 进程。彩色三角形表示提交进程的负载,而彩色矩形表示 TaskManager 和 JobManager 进程的负载。如图所示,Per-Job 模式和 Session 模式下的 Deployer 共享相同的负载。它们的不同之处在于任务的分配和 JobManager 负载。在 Session 模式下,集群中的所有作业都有一个 JobManager,而在 Per-Job 模式下,每个作业都有一个 JobManager。此外,Session 模式下的任务会随机分配给 TaskManager,而在 Per-Job 模式下,每个 TaskManager 只能有单个作业任务。
Application 模式
Application 模式建立在上述观察结果的基础上,并尝试将 Per-Job 模式的资源隔离与轻量级且可伸缩的应用提交过程结合起来。为实现这一点,它为每个提交的应用程序创建一个集群,但是这一次,应用程序的 main() 方法在 JobManager 上执行。
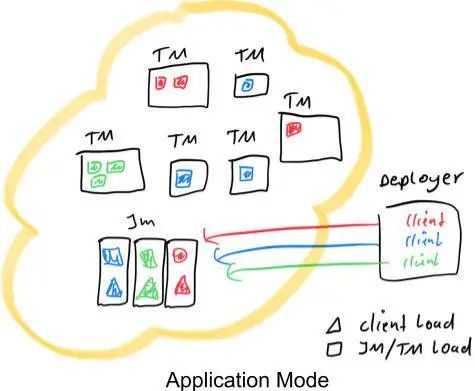
为每个应用程序创建一个集群可以看作是创建一个只在特定应用程序的作业之间共享的 Session 集群,并在应用程序结束时关闭。使用这种架构,Application 模式提供与 Per-Job 模式相同的资源隔离和负载平衡保证,但在整个应用程序的粒度上。这是有道理的,因为属于同一应用程序的工作应该相互关联,并被视为一个单元。
在 JobManager 上执行 main() 方法不仅可以节省提取 Job Graph 所需的 CPU 周期,也可以节省 Client 本地下载依赖项并将 Job Graph 及其依赖项发送到集群所需的带宽。此外,由于每个应用程序只有一个 JobManager,因此,它可以更均匀地分散网络负载。上图对此进行了说明,其中我们具有与 “Session 和 Per-Job 部署模式” 部分中相同的场景,但是这一次 Client 负载已经转移到了每个应用程序的 JobManager。
注:在 Application 模式下,
main()方法是在集群上执行的,而不是像在其他模式中那样在 Client 上执行。和可能对代码产生影响,例如,使用regsiterCachedFile()在环境中注册的任何路径都必须由应用程序的 JobManager 进行访问。
与 Per-Job 模式相比,Application 模式允许提交由多个作业组成的应用程序。作业执行的顺序不受部署模式的影响,而是受用于启动作业的调用的影响。使用阻塞 execute() 方法建立一个顺序,并将导致下一个作业的执行被延迟到“这个”作业完成为止。相反,一旦提交了当前作业,非阻塞executeAsync() 方法将立即继续提交“下一个”作业。
降低网络需求
如上所述,通过在 JobManager 上执行应用程序的 main() 方法,Application 模式可以节省以前在提交作业时所需的大量资源。但仍有改进的余地。
重点关注 YARN,它已经支持所有提到的 here 2,即使 Application 模式已经就绪,Client 仍然需要发送用户 jar 到 JobManager。此外,对于每个应用程序,Client 必须将 “flink-dist” 目录发送到集群,该目录包含框架本身的二进制文件,包括 flink-dist.jar 、 lib/ 和 plugin/ 目录。这两者可能会在 Client 占用大量带宽。此外,在每次提交时发送相同的 flink-dist 二进制文件既是对带宽的浪费,也是对存储空间的浪费。只需允许应用程序共享相同的二进制文件即可减少存储空间的浪费。
在 Flink 1.11 中,我们引入了医学选项,允许用户进行如下操作:
指定一个目录的远程路径,在该目录中,YARN 可以找到 Flink 分发二进制文件,以及
指定一个远程路径,YARN 可以在其中找到用户 jar。
对于第一步,我们利用了 YARN 的分布式缓存,并允许应用程序共享这些二进制文件。因此,如果一个应用程序碰巧在它的 TaskManager 的本地存储中找到了 Flink 的副本,由于之前的一个应用程序在同一个 TaskManager 上执行,它甚至都不需要在内部下载它。
注:这两种优化都可以用于 YARN 上的所有部署模式,而不仅仅是 Application 模式。
示例:YARN 上的 Application 模式
有关完整说明,请参阅 Flink 的官方文档,更具体地说,请参阅引用集群管理框架的页面,例如 YARN 或 Kubernetes。接下来我将给出一些关于 YARN 的例子,其中上述所有功能都是可用的。
要以 Application 模式启动用用程序,可以使用:
./bin/flink run-application -t yarn-application ./MyApplication.jar
使用这条命令,所有的配置参数,例如用于引导应用程序状态的保存点的路径,或者所需的 JobManager/TaskManager 内存大小,都可以通过它们的配置选项(以 -d 作为前缀)来指定。有关可用配置选项的目录,请参阅 Flink 的 配置页面。
例如,指定 JobManager 和 TaskManager 内存大小的命令如下所示:
./bin/flink run-application -t yarn-application \
-Djobmanager.memory.process.size=2048m \
-Dtaskmanager.memory.process.size=4096m \
./MyApplication.jar
最后,为了进一步节省提交应用程序 jar 所需的带宽,可以预先将其上传到 HDFS,并指定指向./MyApplication.jar 的远程路径,如下所示:
./bin/flink run-application -t yarn-application \
-Djobmanager.memory.process.size=2048m \
-Dtaskmanager.memory.process.size=4096m \
-Dyarn.provided.lib.dirs="hdfs://myhdfs/remote-flink-dist-dir" \
hdfs://myhdfs/jars/MyApplication.jar
这将使作业提交变得更加轻量级,因为所需的 Flink jar 和应用程序 jar 将从指定的远程位置提取,而不是由 Client 发送到集群。Client 将唯一提供给集群的是应用程序的配置,其中包括上述提到的所有路径。
总结
我们希望本文的讨论能够帮助你理解 Flink 提供的各种部署模式之间的差异,并且能够帮助你作出明智的决定,究竟哪一种模式适合你自己的设置。