O Apache Solr é um mecanismo de pesquisa amplamente utilizado. Existem várias plataformas conhecidas que usam o Solr; Netflix e Instagram são alguns dos nomes. Temos usado Solr e ElasticSearch no aplicativo de tajawal. Neste artigo, darei algumas dicas sobre como escrever arquivos Schema otimizados. Não discutiremos os fundamentos do Solr, mas espero que você entenda como ele funciona.
Embora você possa definir campos e alguns valores padrão no arquivo Schema, não obterá o aumento de desempenho necessário. Você deve estar ciente de certas configurações de teclas. Neste post, discutirei essas configurações, que você pode usar para obter o máximo do Solr em termos de desempenho.
Sem mais delongas, vamos começar a entender o que são essas configurações.
1. Configurar cache
Um cache Solr está associado a uma instância específica de um pesquisador de índice e uma exibição específica do índice não muda durante o tempo de vida desse pesquisador.
Para maximizar o desempenho, configurar o cache é a etapa mais importante.
Configure `filterCache`:
O cache do filtro é usado pelo SolrIndexSearcher para filtros. O cache de filtro permite controlar como as consultas de filtro são processadas para maximizar o desempenho. O principal benefício do FilterCache é que, quando um novo buscador é aberto, seu cache pode ser pré-preenchido ou "autoaquecido" com dados do cache do buscador antigo. Portanto, definitivamente ajuda a maximizar o desempenho. Por exemplo:
<filterCache
class="solr.FastLRUCache"
size="512"
initialSize="512"
autowarmCount="0"
/>Classe: SolrCache implementa LRUCache (LRUCache ou FastLRUCache)
size: O número máximo de entradas no cache
initialSize: A capacidade inicial do cache (número de entradas). (Consulte java.util.HashMap)
autowarmCount: O número de entradas a serem pré-preenchidas do cache antigo.
Configure `queryResultCache` e `documentCache`:
O cache queryResultCache contém os resultados de pesquisas anteriores: uma lista ordenada (DocList) de IDs de documentos com base na consulta, classificação e escopo do documento solicitado.
O cache documentCache contém objetos Lucene Document (campos de armazenamento para cada documento). Como os IDs de documentos internos do Lucene são transitórios, esse cache não é aquecido automaticamente.
Você pode configurá-los de acordo com sua aplicação. Ele fornece melhor desempenho nos casos em que você usa principalmente casos de uso somente leitura.
Digamos que você tenha um blog, um blog pode ter postagens e comentários nas postagens. No caso do Post, podemos habilitar esses caches, pois nesse caso, as leituras do banco de dados superam em muito as gravações. Portanto, neste caso, podemos habilitar esses caches para Posts.
Por exemplo:
<queryResultCache
class="solr.LRUCache"
size="512"
initialSize="512"
autowarmCount="0"
/><documentCache
class="solr.LRUCache"
size="512"
initialSize="512"
autowarmCount="0"
/>Se você estiver usando principalmente casos de uso somente gravação, desabilite queryResultCache e documentCache em cada soft commit, esses caches são liberados e não têm muito impacto no desempenho. Portanto, tendo em mente o exemplo do blog mencionado acima, podemos desativar esses caches em caso de comentários.
2. Configure o SolrCloud
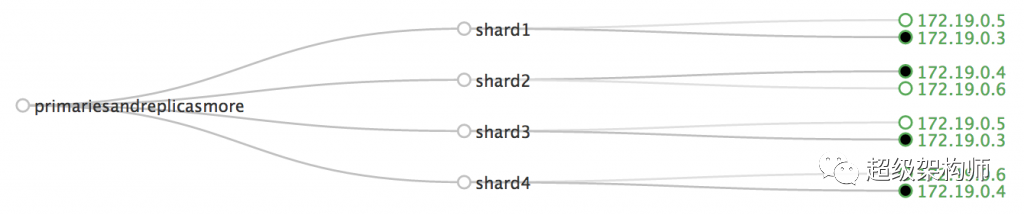
A computação em nuvem é muito popular hoje em dia e permite gerenciar escalabilidade, alta disponibilidade e tolerância a falhas. O Solr permite configurar clusters de servidores Solr que combinam tolerância a falhas e alta disponibilidade.
No ambiente setupSolrCloud, você pode configurar a replicação "master" e "slave". Use uma instância "mestre" para indexar informações e use vários escravos (com base na demanda) para consultar informações. No arquivo solrconfig.xml no servidor mestre, inclua a seguinte configuração:
<str name="confFiles">
solrconfig_slave.xml:solrconfig.xml,x.xml,y.xml
</str>Confira o Solr Docs para mais detalhes.
3. Configure `Commits`
Para que os dados sejam pesquisáveis, devemos submetê-los ao índice. A confirmação pode ser lenta em alguns casos quando você tem bilhões de registros, o Solr usa diferentes opções para controlar o tempo de confirmação, dando a você mais controle sobre quando enviar dados, você deve baseá-lo nas opções de seleção do programa de seu aplicativo.
"commit" ou "soft commit":
Você pode simplesmente enviar dados para o índice enviando o parâmetro commit=true com uma solicitação de atualização, ele fará um hard commit de todos os arquivos de índice Lucene para armazenamento estável, garantirá que todos os segmentos de índice sejam atualizados e pode ser caro quando Quando você tem big data.
Para tornar os dados imediatamente disponíveis para pesquisa, você pode usar o sinalizador adicional softCommit=true, que confirma rapidamente suas alterações nas estruturas de dados do Lucene, mas não garante que os arquivos de índice do Lucene sejam gravados no armazenamento estável. Essa implementação é chamada de Near Tempo real, uma melhoria na visibilidade do documento porque você não precisa esperar que as mesclagens e o armazenamento em segundo plano (ZooKeeper se estiver usando o SolrCloud) sejam concluídos antes de fazer qualquer outra coisa.
Confirmação automática:
A configuração autoCommit controla com que frequência as atualizações pendentes são enviadas automaticamente para o índice. Você pode definir um limite de tempo ou um limite máximo de documento atualizado para acionar esse commit. Também pode ser definido com o parâmetro `autoCommit` ao enviar uma solicitação de atualização. Você também pode definir em Request Handler da seguinte forma:
<autoCommit>
<maxDocs>20000</maxDocs>
<maxTime>50000</maxTime>
<openSearcher>false</openSearcher>
</autoCommit>maxDocs: O número de atualizações que ocorreram desde o último commit.
maxTime: O número de milissegundos desde a atualização não confirmada mais antiga
openSearcher: Se deve abrir um novo buscador ao executar uma confirmação. Se for falso, a confirmação liberará as alterações recentes do índice no armazenamento estável, mas não fará com que novos buscadores sejam abertos para tornar essas alterações visíveis. O padrão é verdadeiro.
Em alguns casos, você pode desativar o autoCommit completamente, por exemplo, se estiver migrando milhões de registros de uma fonte de dados diferente para o Solr e não quiser confirmar os dados em cada inserção, nem mesmo em lote. Envie os dados abaixo. Você não precisa dele a cada 2, 4 ou 6 mil inserções porque ainda vai desacelerar a migração. Nesse caso, você pode desabilitar `autoCommit` completamente e confirmar no final da migração, ou pode definir um valor maior, como 3 horas (ou seja, 3*60*60*1000). Você também pode adicionar <maxDocs>50000000</maxDocs>, o que significa que o autocommit só ocorrerá após adicionar 50 milhões de documentos. Depois que todos os documentos forem publicados, chame um commit manualmente ou do SolrJ - o commit demora um pouco, mas geralmente é muito mais rápido.
Além disso, depois de fazer a importação em massa, reduza maxTime e maxDocs para que qualquer postagem incremental que você fizer no Solr seja confirmada mais rapidamente.
4. Configurar campos dinâmicos
Um recurso incrível do Apache Solr é dynamicField. É muito útil quando você tem centenas de campos e não quer definir todos eles.
Um campo dinâmico é como um campo regular, exceto que possui curingas em seu nome. Os campos que não correspondem a nenhum campo definido explicitamente podem ser comparados com campos dinâmicos ao indexar documentos.
Por exemplo, suponha que seu esquema contenha um campo dinâmico chamado *_i. Se você tentar indexar um documento com um campo cost_i, mas o campo cost_i não estiver explicitamente definido no esquema, o campo cost_i terá o tipo de campo e a análise definidos para *_i.
Mas você tem que ter cuidado ao usar dynamicField, não o use extensivamente, porque também tem algumas desvantagens, se você usar projeção (como "abc.*.xyz.*.fieldname") para obter uma coluna de campo dinâmico específica, use regex A análise de campos leva tempo. Também aumenta o tempo de análise ao retornar os resultados da consulta. Veja a seguir um exemplo de criação de um campo dinâmico.
<dynamicField
name="*.fieldname"
type="boolean"
multiValued="true"
stored="true"
/>Usar campos dinâmicos significa que você pode ter um número ilimitado de combinações em nomes de campo, desde que você especifique curingas, o que às vezes pode ser caro porque o Lucene aloca memória para cada nome de campo (coluna) exclusivo, o que significa que se você tiver uma linha Contém colunas A, B, C, D e outra linha tem E, F, C, D, o Lucene alocará 6 blocos de memória em vez de 4, porque existem 6 nomes de colunas exclusivos, portanto, mesmo que existam 6 nomes de colunas exclusivos, dez mil 1 milhão de linhas, pode travar o heap porque usará 50% de memória extra.
5. Configure os campos de índice e armazenamento
Indexar um campo significa que você está tornando o campo pesquisável, indexed="true" torna o campo pesquisável, classificável e facetável, por exemplo, se você tiver um campo chamado test1 com indexed="true", poderá fazer algo como q= pesquisá-lo como test1:foo, onde foo é o valor que você deseja pesquisar, portanto, defina apenas os campos necessários para a pesquisa como indexed="true" e o restante dos campos deve ser indexed="false" se necessário na pesquisa resultados. Por exemplo:
<field name="foo" type="int" stored="true" indexed="false"/>Isso significa que podemos reduzir o tempo de reindexação, porque a cada reindexação, o Solr aplica filtros, tokenizadores e analisadores, o que adiciona algum tempo de processamento, se tivermos um pequeno número de índices.
6. Configure o campo de cópia
O Solr fornece um recurso muito bom chamado copyField, que é um mecanismo para armazenar cópias de vários campos em um único campo. A utilização de copyField depende do cenário, mas o mais comum é criar um único campo "pesquisa" que será utilizado como campo de consulta padrão quando o usuário ou cliente não especificar um campo a ser consultado.
use copyField para todos os campos de texto comuns e copie-os em um campo de texto e use-o para pesquisa, reduzirá o tamanho do índice e proporcionará melhor desempenho, por exemplo, se você tiver dados dinâmicos como ab_0_aa_1_abcd e deseja copiar todos os campos com o sufixo _abcd para um campo. Você pode criar um copyField em schema.xml assim:
<copyField source="*_abcd" dest="wxyz"/>source: o nome do campo a ser copiado
dest: o nome do campo copiado
7. Use a consulta de filtro 'fq'
Usar o parâmetro Filter Query fq na pesquisa é útil para maximizar o desempenho, ele define uma consulta que pode ser usada para limitar o superconjunto de documentos que podem ser retornados sem afetar a pontuação, ele armazena a consulta em cache de forma independente.
O filtro Queryfq é útil para acelerar consultas complexas, pois as consultas especificadas com fq são armazenadas em cache independentemente da consulta principal. Quando uma consulta subsequente usa o mesmo filtro, ocorre uma ocorrência no cache e os resultados do filtro são retornados rapidamente do cache.
Aqui está um exemplo de curl usando uma consulta de filtro:
POST
{
"form_params": {
"fq": "id=1234",
"fl": "abc cde",
"wt": "json"
},
"query": {
"q": "*:*"
}
}Os parâmetros da consulta de filtro também podem ser usados várias vezes em uma única consulta de pesquisa. Confira a documentação do Solr Filter Query para obter mais detalhes.
8. Usando consultas de faceta
Faceting no Apache Solr é usado para classificar os resultados da pesquisa em diferentes categorias, é muito útil realizar operações de agregação como agrupar por campo específico, contagem, agrupar por etc. fora da caixa, também será um impulsionador de desempenho, pois foi projetado exclusivamente para esse tipo de operação.
Abaixo está um exemplo de curl que envia uma solicitação de faceta para solr.
{
"form_params": {
"fq" : "fieldName:value",
"fl" : "fieldName",
"facet" : "true",
"facet.mincount": 1,
"facet.limit" : -1,
"facet.field" : "fieldName",
"wt" : "json",
},
"query" : {
"q": "*:*",
},
}fq: query de filtro
fl: lista de campos a serem retornados no resultado
facet: true/false habilitar/desabilitar contagem de facet
facet.mincount: excluir intervalos com contagem inferior a 1
facet.limit: limitar o número de grupos retornados no resultado, -1 significa todas as
facetas.campo: o campo deve ser considerado como uma faceta (para agrupar os resultados)
para concluir:
A melhoria do desempenho é uma etapa crítica ao colocar o Solr em produção. Existem muitos botões de ajuste no Solr que podem ajudá-lo a maximizar o desempenho do seu sistema, alguns dos quais discutimos neste blog, fazendo alterações no arquivo solr-config para usar a configuração ideal, atualizando o esquema com as opções de índice apropriadas ou field type, use filter queriesfq sempre que possível e use as opções de cache apropriadas, mas, novamente, isso depende do seu aplicativo.
É isso.
| Este artigo | https://architect.pub/configuring-solr-optimum-performance | |
| Discussão: Knowledge Planet [Chief Architect Circle] ou adicionar trompete WeChat [cea_csa_cto] ou adicionar grupo QQ [792862318] | ||
| Sem público |
【jiagoushipro】 【Super Arquiteto】 Brilhante gráfico e explicação detalhada da metodologia de arquitetura, prática de arquitetura, princípios técnicos e tendências técnicas. Estamos esperando por você, por favor digitalize e preste atenção. |
|
| WeChat trompete |
[cea_csa_cto] Comunidade de 50.000 pessoas, discutindo: arquitetura corporativa, computação em nuvem, big data, ciência de dados, Internet das Coisas, inteligência artificial, segurança, desenvolvimento full-stack, DevOps, digitalização. |
|
| Grupo QQ |
[792862318] Intercâmbio aprofundado de arquitetura corporativa, arquitetura de negócios, arquitetura de aplicativos, arquitetura de dados, arquitetura técnica, arquitetura de integração, arquitetura de segurança. E várias tecnologias emergentes, como big data, computação em nuvem, Internet das Coisas, inteligência artificial, etc. Junte-se ao grupo QQ para compartilhar relatórios valiosos e produtos secos. |
|
| número do vídeo | [Super Arquiteto] Entenda rapidamente os conceitos básicos, modelos, métodos e experiências relacionadas à arquitetura em 1 minuto. 1 minuto por dia, a estrutura é familiar. |
|
| planeta do conhecimento | Pergunte a grandes nomes, entre em contato com eles ou compartilhe informações privadas. | |
| Himalaia | Saiba mais sobre a mais recente experiência em informação e arquitetura de tecnologia negra na estrada ou no carro. | [Momentos inteligentes, o Sr. Arquitetura falará com você sobre a tecnologia negra] |
| planeta do conhecimento | Conheça mais amigos, local de trabalho e bate-papo técnico. | Planeta do conhecimento【Local de trabalho e tecnologia】 |
| 【Momento Inteligente】 | momento inteligente | |
| Bilibili | 【Super Arquiteto】 | |
| tik tok | 【cea_cio】Super Arquiteta | |
| trabalhador rápido | 【cea_cio_cto】Super Arquiteto | |
| livrinho vermelho | [cea_csa_cto] Super Arquiteto | |
Obrigado pela atenção, encaminhamento, curtidas e observação.