Original address: https://blog.csdn.net/yuruixin_china/article/details/80037873
Solr is a search engine framework based on the lucene search library, which encapsulates lucene and implements an enterprise-level application framework. There is a complete cluster and index library optimization solution.
Solr can run independently, running in Servlet containers such as Jetty, Tomcat, etc. The implementation method of Solr index is very simple. Use the POST method to send an XML document describing the Field and its content to the Solr server. Solr adds, deletes, and updates according to the XML document. index. Solr search only needs to send an HTTP GET request, and then parse the query results returned by Solr in Xml, json and other formats to organize the page layout. Solr does not provide the function of building UI. Solr provides a management interface, through which you can query the configuration and operation of Solr.
Installation and
download address: http://archive.apache.org/dist/lucene/solr/
(The server is abroad, the download will be slower. You can use solr6.1.0 to download )Download complete and unzip the compressed package
start solr
- Visit the solr background management interface
http://127.0.0.1:8983/solr/#/ - Create core (can be understood as a database in mysql, that is, a service can have multiple libraries)
solr create -c gxl_core- 1
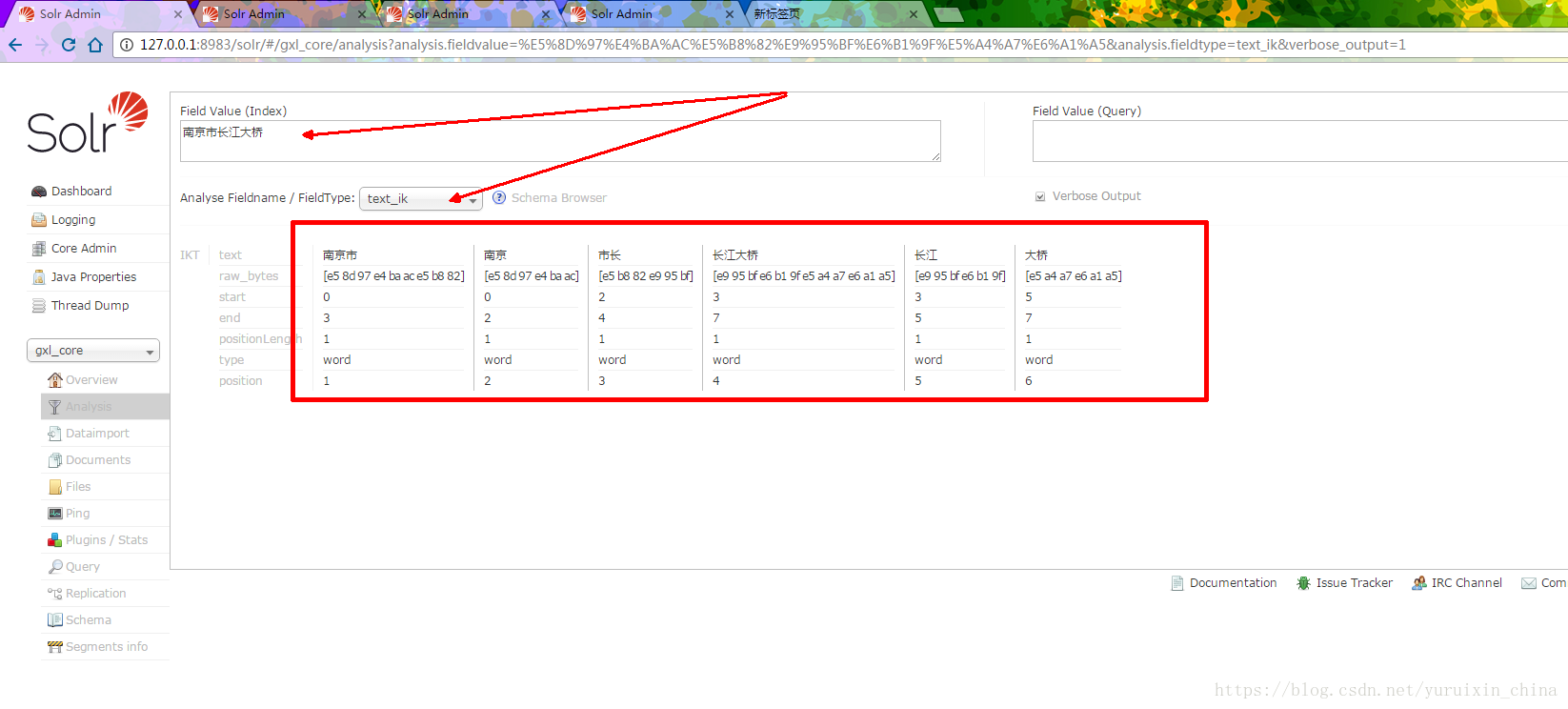
6. Enter the core you just created and test the word segmentation
. Since the word segmenter that comes with solr cannot segment Chinese according to semantics, you need to introduce the Chinese word segmenter IKAnalyzer
a. Put the jar of ik into the solr-6.1.0\server\solr-webapp\webapp\WEB-INF\lib directory
b. Modify the managed-schema.xml file and add the following code to the schema tag
<!-- IKAnalyzer-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>- 1
- 2
- 3
- 4
c. restart solr
solr restart -p 8983- 1
After the above operations, look at the word segmentation effect