Article Directory
Introduction to the Llama 2 Model
On July 18, 2023, Meta released Llama 2, including 7B, 13B, and 70B parameters (34B has not yet been released).
Official: https://ai.meta.com/llama/
Paper: Llama 2: Open Foundation and Fine-Tuned Chat Models
Model: https://huggingface.co/meta-llama
github: https://github.com/ facebookresearch/llama
One of the biggest advantages of Llama 2 compared to Llama is that it allows commercialization, but it should be noted that if the number of monthly active users of enterprises using Llama 2 exceeds 700 million, they will need to apply for a specific commercial license from Meta.
The core point of Llama 2
The Llama 2 training corpus is 40% more than LLaMA , and has received 2 trillion mark training;
the Llama 2 context length has been upgraded from the previous 2048 to 4096, which can understand and generate longer texts;
Llama 2 's 34B, 70B The model uses group query attention (GQA) instead of MQA and MHA, mainly considering the trade-off between effect and scalability (GQA can improve the reasoning scalability of large models).
Llama 2 review results
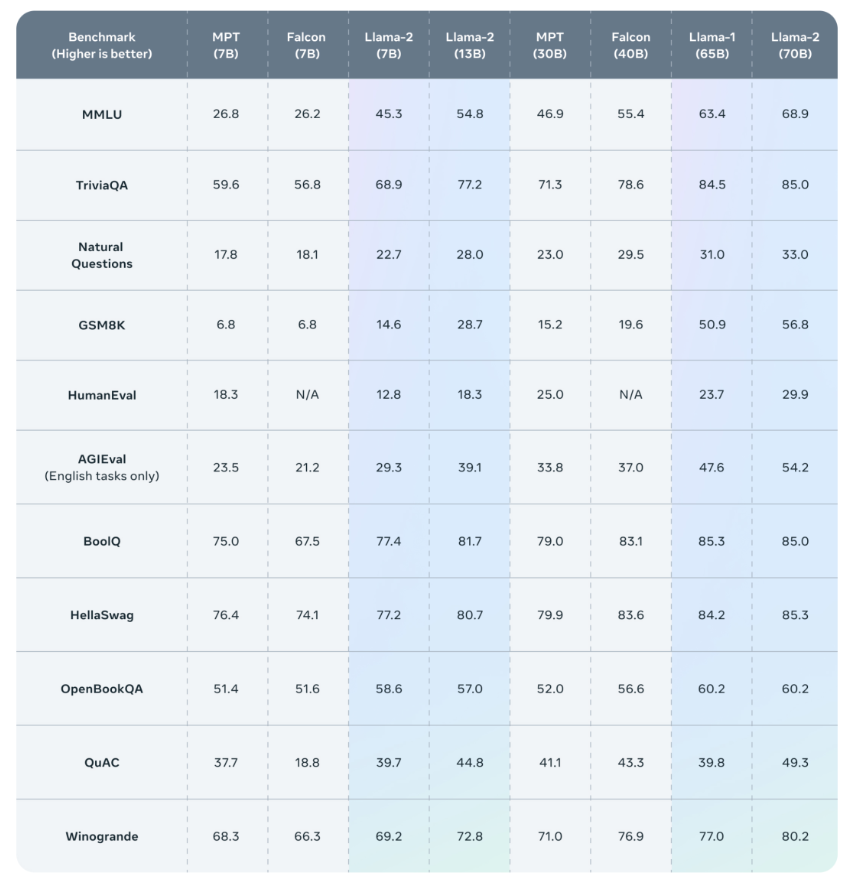
Published evaluation results show that Llama 2 outperforms other open source language models on a number of external benchmarks including inference, coding, proficiency and knowledge tests.
Pre-training for Llama 2
Llama 2 is based on the pre-training method of Llama 1, using an optimized autoregressive transformer and making some changes to improve performance.
Preprocess data
The training corpus for Llama 2 contains mixed data from publicly available sources and does not include Meta product or service related data. At the same time, relevant data was deleted from some websites that contained a large amount of personal information.
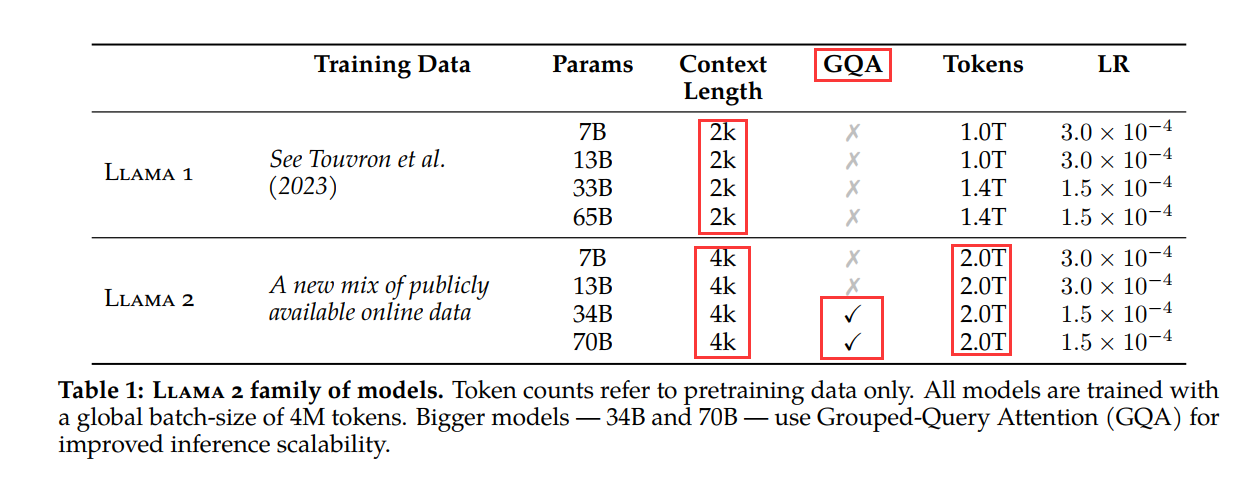
Pretraining Setup and Model Architecture
Llama 2 adopts most of the pre-training setup and model architecture from Llama 1, including the standard Transformer architecture, prenormalization using RMSNorm, SwiGLU activation function, and rotated position embedding.
The main differences from Llama 1 include increased context length (from 2048 to 4096) and group query attention (GQA).
In terms of hyperparameters, Llama 2 is trained with AdamW optimizer, where β_1 = 0.9, β_2 = 0.95, eps = 10^−5. At the same time, a cosine learning rate schedule (2000 steps of warm-up) was used, and the final learning rate was decayed to 10% of the peak learning rate. A weight decay of 0.1 and gradient clipping of 1.0 are used. The training loss is as follows:
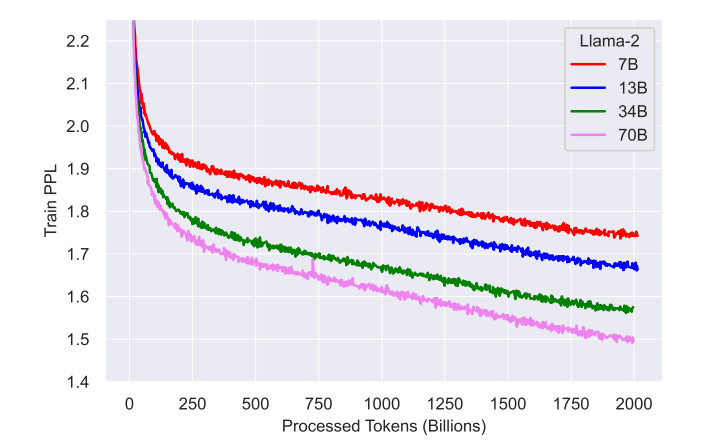
It can be seen that after pre-training 2T tokens, the model still does not appear saturated.
Word segmentation uses the same tokenizer as Llama 1, that is, byte pair encoding (BPE), using the implementation in SentencePiece, splitting all numbers into single numbers, and using bytes to decompose unknown UTF-8 characters, the total vocabulary size It is 32K tokens.
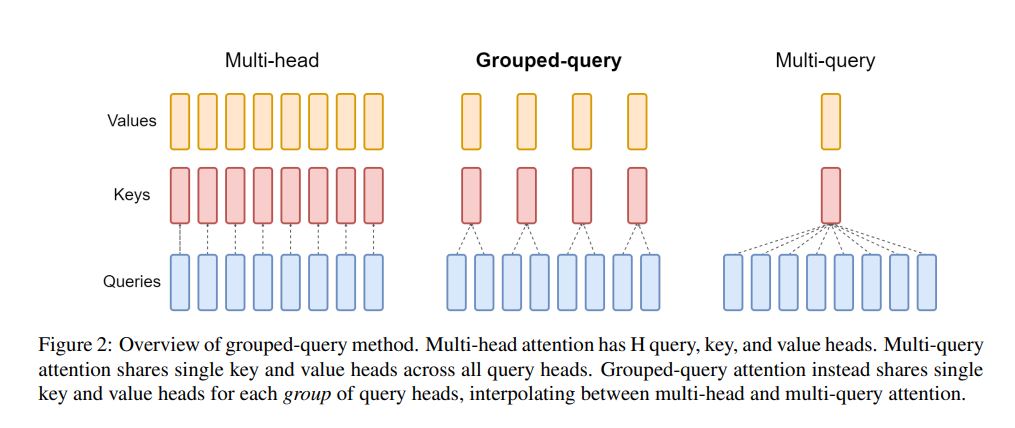
About GQA
论文:GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
GQA is an attention method proposed by Google in May 2023. Before understanding GQA, you must first know MHA and MQA.
MHA is the multi-head attention in Transformer. If the number of heads is 8, there will be 8 Q, 8 K, and 8 V (Q is the query vector, K is the key vector, and V is the value vector); MQA
is multi Query attention is an improvement to MHA. Only one K and V are reserved, which is equivalent to using 8 Q, 1 K, and 1 V for attention calculation. The advantage of this method is that it can speed up decoding. The reasoning speed of the device (because the amount of calculation of K and V is less), the disadvantage is that the performance drops; the proposal of
GQA is to set the number of K and V to a value greater than 1 and less than Q (for example, set to 4, between between 1 and 8), this method converts the multi-head attention model into a multi-query model with a small computational cost, thereby achieving fast multi-query and high-quality reasoning, and achieving a balance between performance and speed.
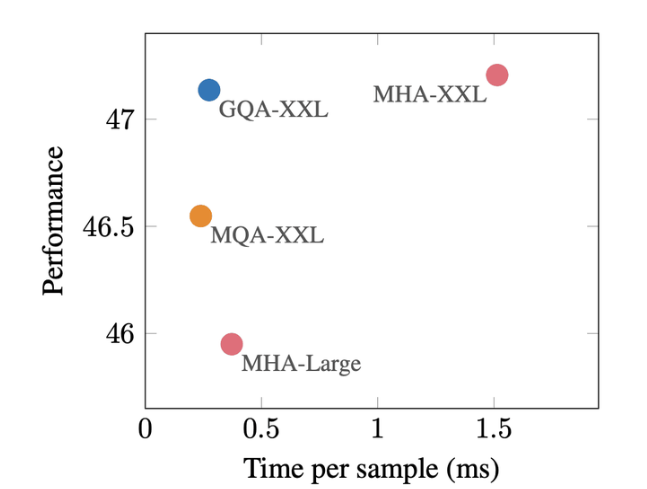
GQA is almost equal to MQA in reasoning speed, and almost equal to MHA in effect.
Introduction to the Llama-2-chat model
Llama-2-chat model performance on helpfulness and safety
The Llama-2-chat model is trained on over 1 million new human annotations, using reinforcement learning from human feedback (RLHF) for safety and helpfulness.
The Llama-2-chat model outperforms existing open source models in terms of helpfulness and safety, and is even comparable to some closed source models (evaluation method is manual evaluation )
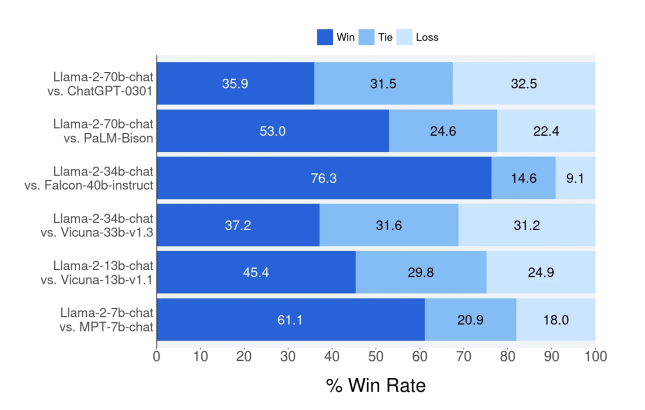
- The figure below shows the comparison of Llama 2-70b-chat and other open source and closed source models in about 4000 helpful prompts, where Win means win, Tie means tie, and Loss means failure.
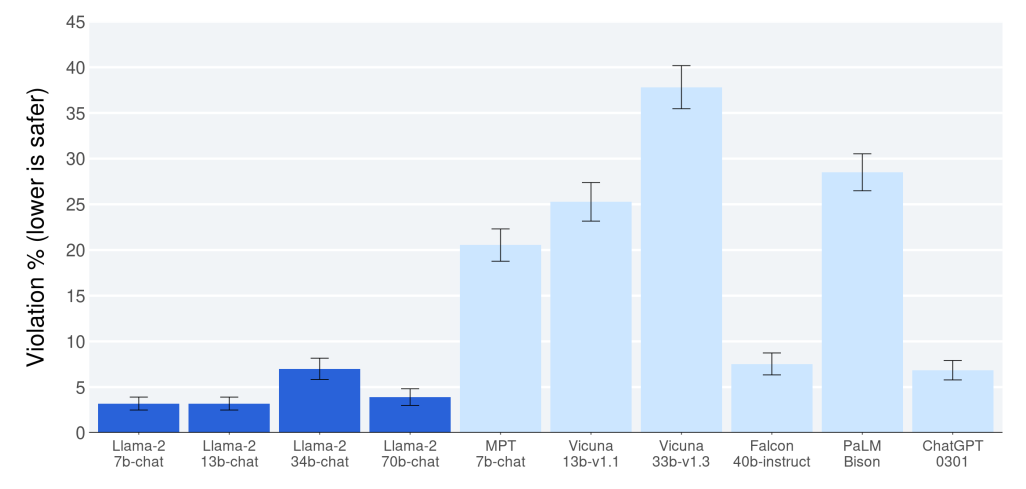
The figure below shows the comparison of Llama 2-70b-chat and other open source and closed source models in judging the security violations of the model in about 2000 adversarial prompts. The vertical axis represents the violation rate, and the smaller the value, the safer it is.
The training process of the Llama-2-chat model
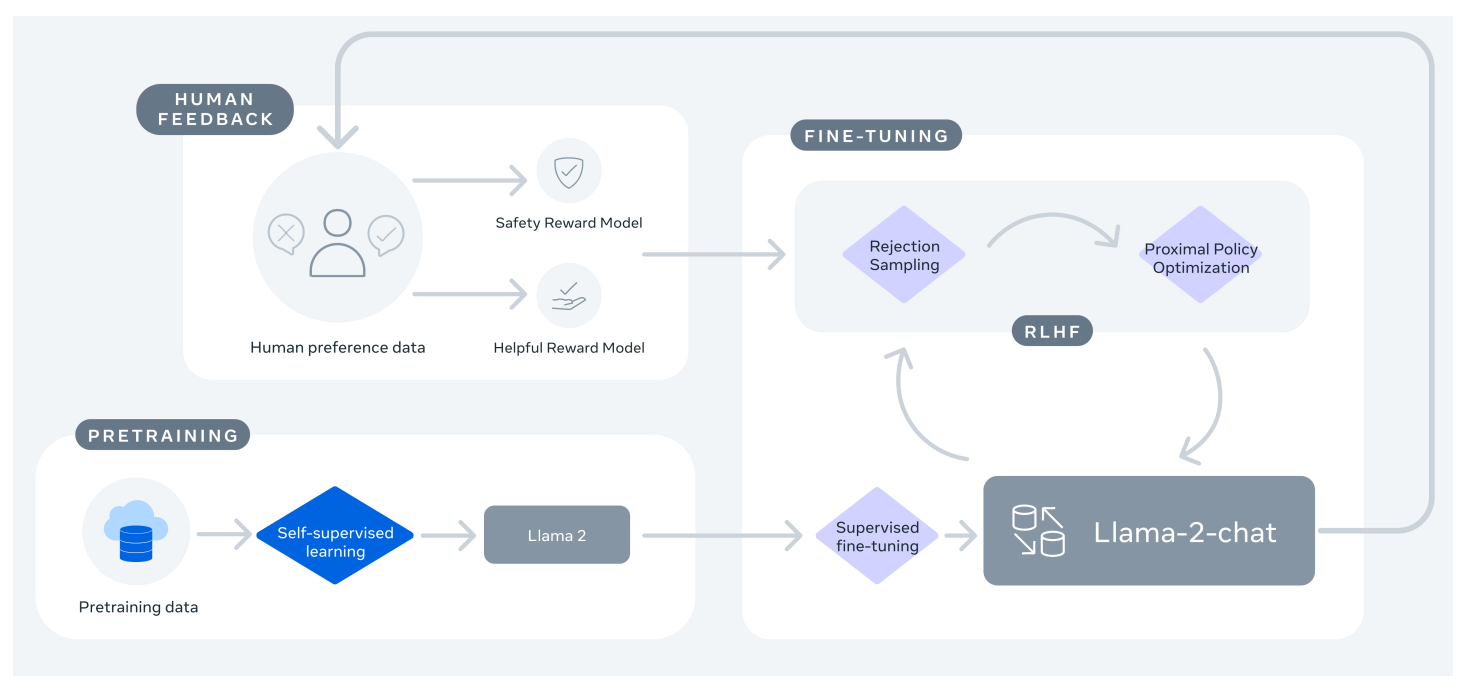
Training of Llama 2-Chat: First, Llama 2 is pre-trained using publicly available online resources, then an initial version of Llama 2-Chat is created by means of supervised fine-tuning, and finally a reinforcement learning with human feedback (RLHF) method is used, specifically The model is iteratively optimized through rejection sampling and approximate policy optimization (PPO). Throughout the RLHF phase, the accumulation of iterative reward modeling data in parallel with model augmentation is crucial to ensure that the reward model remains within the distribution.
As can be seen from the figure above, reward models are set for safety and helpfulness, that is, Safety Reward Model and Helpful Reward Model.
Reference: https://mp.weixin.qq.com/s/PJyFoLP7IBxjbswq-NBEkA