1. Pre-training pre-training
-
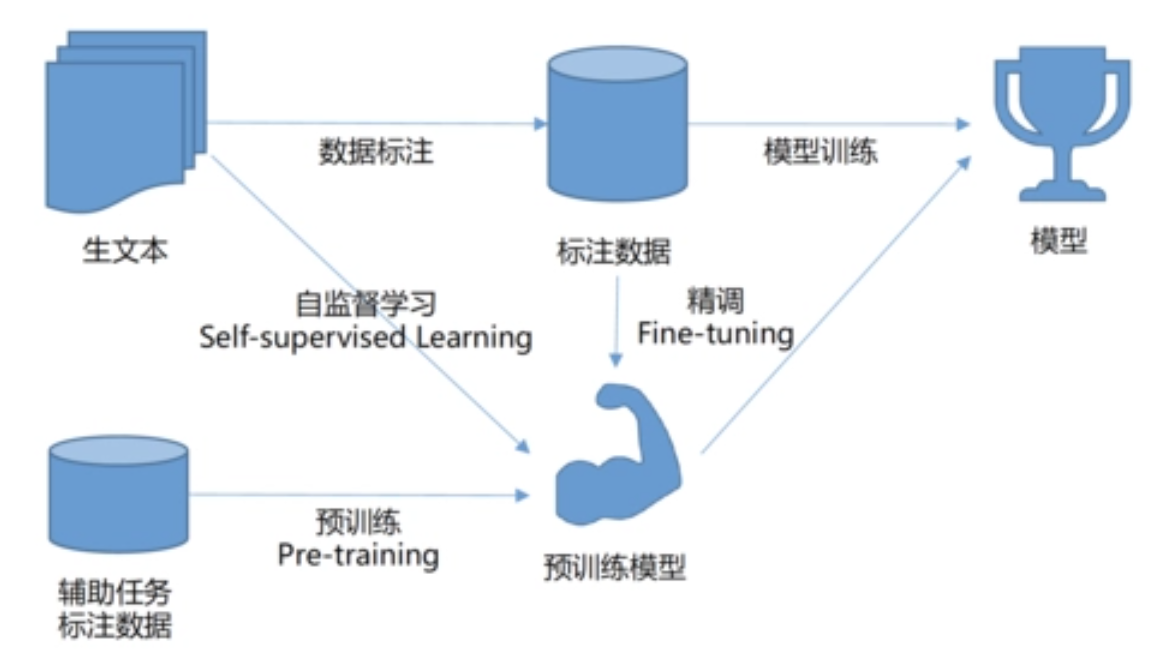
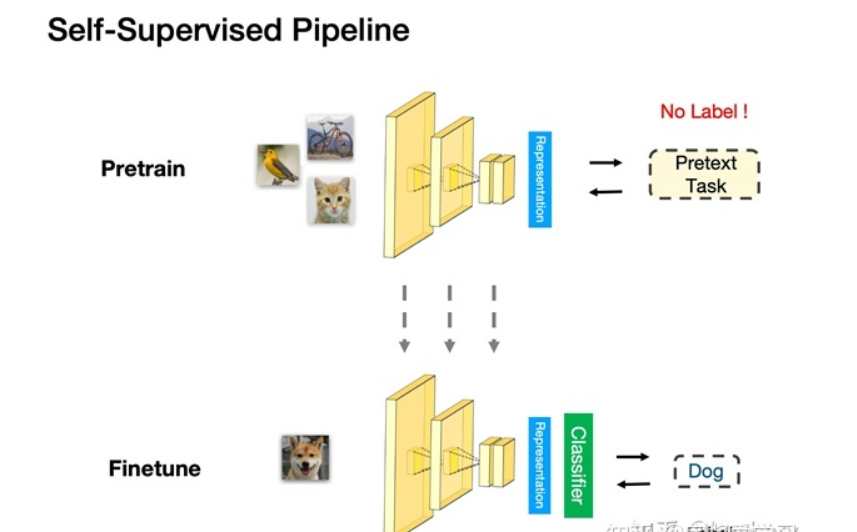
Pre-trained model (Pre-trained Model) refers to a neural network model trained on a large-scale data set, the purpose of which is to extract and learn the characteristics of the data. These pretrained models are commonly used in fields such as computer vision and natural language processing.
-
When training pre-trained models, unlabeled datasets are usually used for self-supervised learning or unsupervised learning. These models can be fine-tuned on other tasks using transfer learning by learning general features of the data.
-
The main advantage of using a pre-trained model is that you can use general features learned on large-scale datasets to solve tasks on smaller datasets. The training of the pre-trained model requires a lot of computing resources and time. However, the accuracy and generalization ability of the model can be improved through the pre-trained model, and the training time and data volume requirements of the model can be reduced. In addition, pre-trained models can avoid challenges such as model overfitting and optimization problems.
-
Currently, many publicly available pre-trained models are available on the Internet, such as BERT, GPT-2, ResNet, etc. These pre-trained models have become an important technology in the field of deep learning and are widely used in many fields, such as natural language processing, computer vision, speech recognition, etc.
2. Fine-tune
Fine-tune (fine-tune) is a commonly used deep learning technique, which can improve the performance of the model by fine-tuning on a specific task through the pre-trained model.
2.1 Commonly used fine-tuning methods:
-
Standard Fine-tuning: Based on the pre-trained model, only the top classification layer is fine-tuned. This approach is often used to solve tasks with similar semantics, such as text classification, sentiment analysis, etc.
-
Feature Extraction Fine-tuning: Freeze all layers of the pre-trained model and only fine-tune the top classification layer of the model. In this case, the model can only use the general features extracted by the pre-trained model to solve specific tasks, which is suitable for scenarios with relatively small datasets or few categories.
-
End-to-end Fine-tuning: On the basis of the pre-trained model, fine-tune the entire model, all layers from input to output. This approach is often used to solve specific, complex tasks such as image segmentation, natural language generation, etc.
-
Headless Fine-tuning: Based on the pre-trained model, the classification layer of the model is removed, a new classification layer is added, and the entire model is fine-tuned. This method is suitable for situations that require reconstruction on the basis of the original model, such as transfer learning of the model.
Fine-tuning can quickly build an efficient model without a large amount of labeled data, but you need to pay attention to the over-fitting problem of the model, and you need to use some common techniques in the fine-tuning process, such as data enhancement, regularization, etc. to alleviate the over-fitting problem .
2.2 steps
The fine-tuning process typically involves the following steps:
-
Select an appropriate pre-training model: Select an appropriate pre-training model according to the characteristics of the task. For example, for natural language processing tasks, pre-training models such as BERT and GPT can be used.
-
Freezing the pre-training model: The first few layers of the pre-training model (usually all convolutional layers or embedding layers) are fixed, and do not participate in fine-tuning, so as to retain its general feature extraction ability for data.
-
Add new fully-connected layers: Add some fully-connected layers on top of the pre-trained model to solve specific tasks.
-
Fine-tuning the model with annotated data: Use the annotated dataset to fine-tune the model to a specific task, updating the weights of the fully-connected layers in the process. The process of fine-tuning usually requires repeated iterations of training, validation, and tuning.
Combination of the two : pre-trained models and fine-tuning (fine-tune) can be combined with each other to solve specific tasks. The pre-trained model can be trained through large-scale unlabeled datasets, extract general features of the data, and then fine-tune using transfer learning on other tasks to solve specific tasks.