1. Introduction to Flink HA solution
Each Flink cluster has only a single JobManager, and there is a single point of failure. Flink has three modes: YARN, Standalone and Local. Among them, YARN and Standalone are cluster modes, and Local refers to stand-alone mode. However, Flink provides HA mechanism for YARN mode and Standalone mode, so that the cluster can recover from failure. Here we mainly introduce the HA solution in YARN mode.
Flink supports HA mode and exception recovery of Job. These two functions are highly dependent on ZooKeeper. Before using them, users need to configure ZooKeeper in the "flink-conf.yaml" configuration file. The parameters for configuring ZooKeeper are as follows:
high-availability: zookeeper
high-availability.zookeeper.quorum: ZooKeeperIP地址:24002
high-availability.storageDir: hdfs:///flink/recovery
YARN mode
Flink's JobManager and YARN's Application Master (AM for short) are under the same process. YARN's ResourceManager monitors AM. When AM is abnormal, YARN will restart AM. After startup, all JobManager metadata will be restored from HDFS. However, during the recovery period, old services cannot be run, and new services cannot be submitted. The metadata of the JobManager still exists on ZooKeeper, such as the information about running the Job, which will be provided to the new JobManager. For the failure of TaskManager, it is monitored and processed by Akka's DeathWatch mechanism on JobManager. When the TaskManager fails, re-apply for the container from YARN and create the TaskManager.
Standalone mode
For a cluster in Standalone mode, multiple JobManagers can be started, and then the leader is elected through ZooKeeper as the actual JobManager. In this mode, one primary JobManager (Leader JobManager) and multiple standby JobManagers (Standby JobManagers) can be configured, which can ensure that when the primary JobManager fails, one of the standby JobManagers can assume the primary responsibility. The recovery process of the active and standby JobManagers is shown in the figure below.
recovery process

TaskManager recovery
For the failure of TaskManager, it is monitored and processed by Akka's DeathWatch mechanism on JobManager. When the TaskManager fails, the JobManager is responsible for creating a new TaskManager and migrating the business to the new TaskManager.
JobManager recovery
Flink's JobManager and YARN's Application Master (AM for short) are under the same process. YARN's ResourceManager monitors AM. When AM is abnormal, YARN will restart AM. After startup, all JobManager metadata will be restored from HDFS. However, during the recovery period, old services cannot be run, and new services cannot be submitted.
Job recovery
The recovery of the job must configure the restart strategy in the Flink configuration file. There are currently three restart strategies: fixed-delay, failure-rate, and none. The job can be resumed only when fixed-delay and failure-rate are configured. In addition, if the restart strategy is configured as none, but the job is set to Checkpoint, the restart strategy will be changed to fixed-delay by default, and the number of retries is the configuration item "restart-strategy.fixed-delay.attempts" configured as "Integer. MAX_VALUE".
For specific information about the three strategies, please refer to the Flink official website: https://ci.apache.org/projects/flink/flink-docs-release-1.15/dev/task_failure_recovery.html . The configuration strategy reference is as follows:
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 10 s
Abnormalities in the following scenarios will cause the job to be resumed:
- When the JobManager fails, all jobs will stop until the new JobManager starts up, and all jobs will resume.
- When a TaskManager fails, all jobs on the TaskManager will be stopped and restarted after waiting for available resources.
- When a Job's Task fails, the entire Job will restart.
Note: Please refer to https://ci.apache.org/projects/flink/flink-docs-release-1.15/ops/jobmanager_high_availability.html for details about the job configuration restart strategy .
2. Relationship between components
Flink supports the cluster mode based on YARN management. In this mode, Flink, as an application on YARN, is submitted to YARN for execution. Flink's YARN-based cluster deployment is shown in the figure below.
Flink's YARN-based cluster deployment
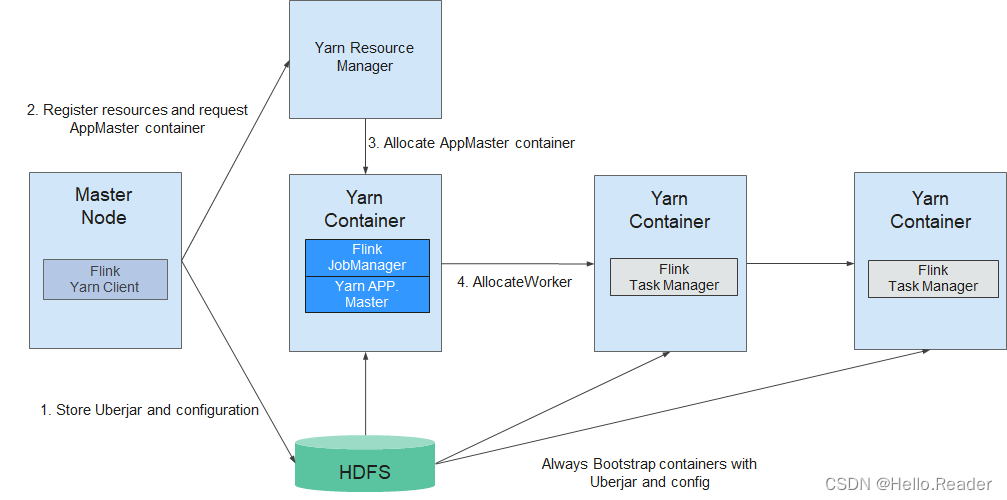
- The Flink YARN Client will first check whether there are enough resources to start the YARN cluster, and if the resources are sufficient, it will upload the jar package and configuration files to HDFS.
- The Flink YARN Client first communicates with the YARN Resource Manager, applies for starting the Container of the Application Master (hereinafter referred to as AM), and starts the AM. After all the Node Managers of YARN download the jar packages and configuration files on HDFS, it means that the AM starts successfully.
- During the startup process, AM will interact with YARN's RM, apply for the required Task Manager Container from RM, and start the TaskManager process after applying for the Task Manager Container.
- In the Flink YARN cluster, AM and Flink JobManager are in the same Container. The AM will notify each TaskManager of the RPC address of the JobManager through HDFS sharing. After the TaskManager starts successfully, it will register with the JobManager.
- After all TaskManagers have successfully registered with the JobManager, and the YARN-based cluster of Flink starts successfully, the Flink YARN Client can submit the Flink Job to the Flink JobManager for subsequent mapping, scheduling and calculation processing.