table of Contents
I have learned the batch processing WordCount of flink before, now let's learn about the flow processing WordCount of flink, which is actually similar to batch processing. The difference is that the method of obtaining the execution environment and the method of receiving data are different. The batch ExecutionEnvironment.getExecutionEnvironmentprocess obtains the batch execution environment by the readTextFile("inputParth")method , and then obtains the file by the method, and the stream processing StreamExecutionEnvironment.getExecutionEnvironmentobtains the stream processing execution environment by obtaining the stream processing execution environment, and then socketTextStream(host, port)obtains the socket stream data. The subsequent statistical processing logic is consistent.
First introduce the pom.xml file
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.fuyun</groupId>
<artifactId>flinkLearning</artifactId>
<version>1.0-SNAPSHOT</version>
<repositories>
<repository>
<id>aliyun</id>
<url>http://repository.apache.org/content/groups/snapshots/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>jboss</id>
<url>http://repository.jboss.com/nexus/content/groups/public</url>
</repository>
</repositories>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.12.0</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<!-- provided在这表示此依赖只在代码编译的时候使用,运行和打包的时候不使用 -->
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>${flink.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>${flink.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
</project>
flink stream processing code
package com.fuyun.flink
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala._
object StreamingWordCount {
def main(args: Array[String]): Unit = {
//从外部命令中提取参数,作为socket主机名和端口号
val paramTool = ParameterTool.fromArgs(args)
val host = paramTool.get("host")
val port = paramTool.getInt("port")
// 创建流处理执行环境
val senv = StreamExecutionEnvironment.getExecutionEnvironment
// 设置并行度
senv.setParallelism(8)
// 接收socket文本流
//val inputDataStream = senv.socketTextStream("bigdata-training.fuyun.com", 9000)
val inputDataStream = senv.socketTextStream(host, port)
// 进行转换处理统计
val resultDataStream = inputDataStream
.flatMap(_.split("\\s"))
.filter(_.nonEmpty)
.map((_, 1))
.keyBy(0)
.sum(1)
// 打印统计结果
resultDataStream.print()
// 必须调用execute方法执行,不然不会触发执行操作,参数为jobName
senv.execute("stream word count")
}
}
IDEA execution
Configure host and port in IDEA's Run-->>Edit Configurations-->>program arguments
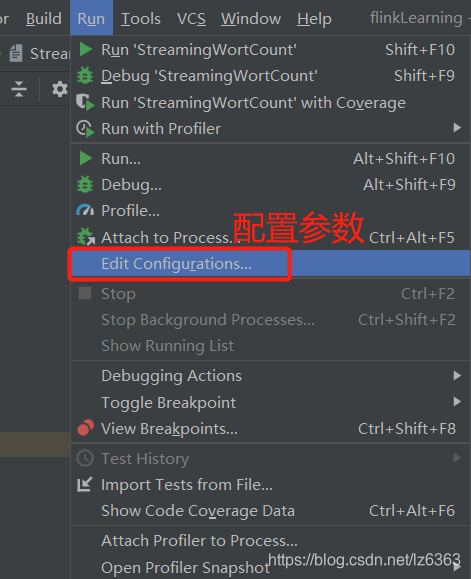
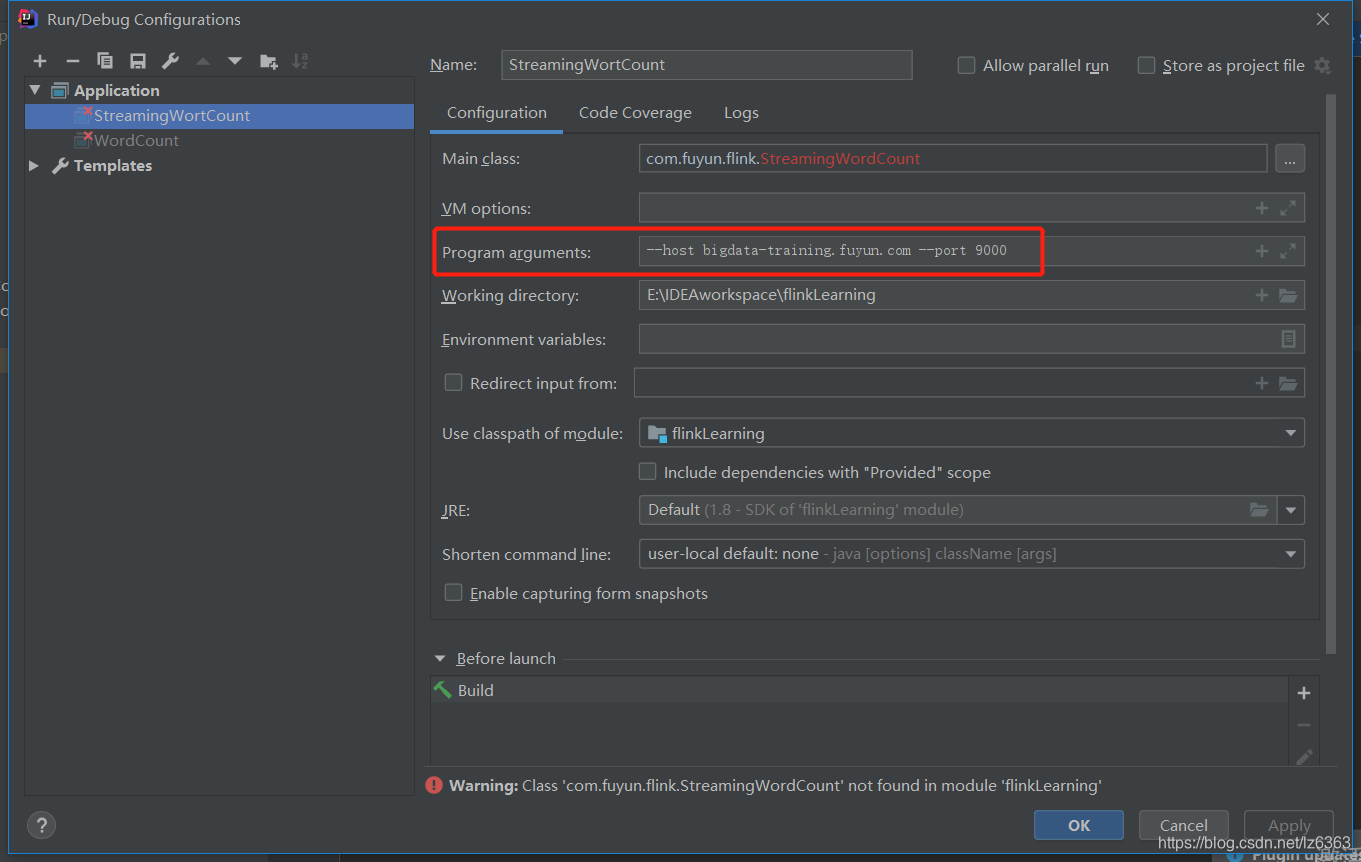
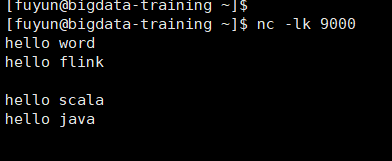
After configuring the parameters, execute the command on the virtual machine nc -lk 9000, then execute the program on IDEA, enter the word on the virtual machine, and IDEA will see the statistical results.
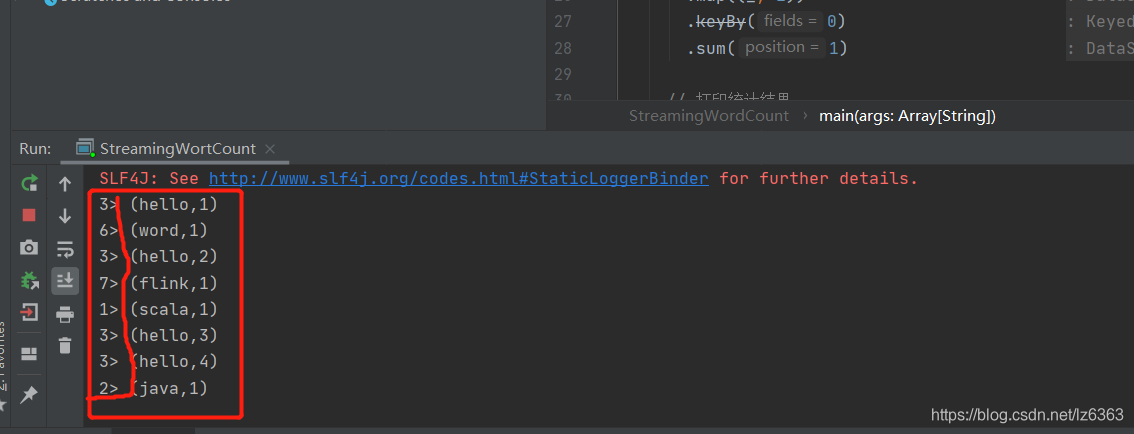
The result on IDEA shows that 3>the number in front of the screenshot appears. Because the parallelism is set to 8 in the code program, 3>and the id for the parallelism is 3, the id will not be greater than 8, and the parallelism can be set every time in the program. It can be set in each calculation. For example, in the above code, the parallelism is set to 8 after the stream processing environment is created. The parallelism defaults to the number of CPU cores of the computer itself (if the parallelism is not set in the program), if in the operator If the degree of parallelism is set, the set degree of parallelism is used. For example, in the above code: When resultDataStream.print()changed resultDataStream.print().setParallelism(1), the printed result will not have a similar 3>result, because the degree of parallelism is only 1.