guide
In recent years, large-scale pre-trained models have achieved great success in natural language processing tasks. Fine-tuning pre-trained language models is a common paradigm in natural language processing tasks, showing excellent performance on many downstream tasks. Full-parameter fine-tuning, i.e. training on all parameters of a model, is currently the most general approach for applying pre-trained models to downstream tasks.
However, a major disadvantage of full fine-tuning is that for each task, the model needs to retain a large-scale parameter backup, which will be quite expensive when the downstream tasks are large. When the pre-training model is getting bigger and bigger, approaching hundreds of billions or even trillions of parameters, this kind of problem will be infinitely magnified.
Parameter-Efficient Fine-Tuning (Parameter-Efficient Fine-Tuning) came into being. Lightweight fine-tuning mainly focuses on fine-tuning a small number of parameters of the entire model, and tries to obtain performance close to full fine-tuning on downstream tasks by fine-tuning a small number of parameters, and solves the problem of upstream The problem of possible structural deviations between tasks and the input and output of downstream tasks. The author sorted out the classic papers on the direction of lightweight fine-tuning and the latest progress in the past two years. The paper mainly includes the mainstream lightweight fine-tuning methods in recent years , new lightweight fine-tuning methods , lightweight fine-tuning applications and a unified lightweight fine-tuning framework . Welcome to criticize and exchange.
Paper List
1、Parameter-Efficient Transfer Learning for NLP Adapter(ICML 2019)
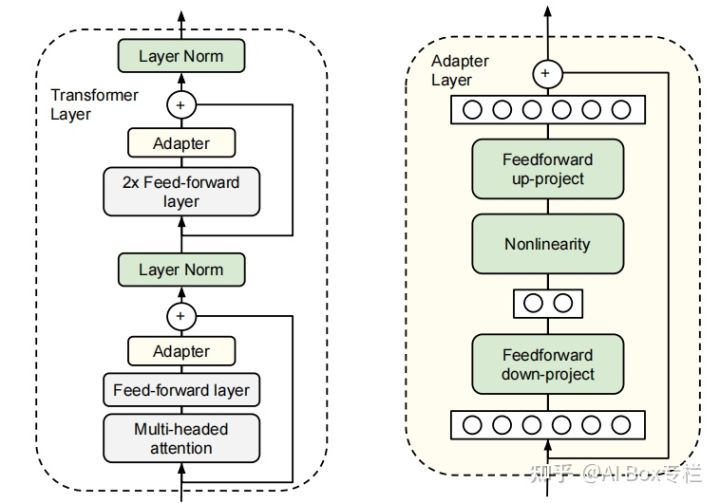
This work proposes the Adapter method for the first time. When fine-tuning the pre-trained model, we can freeze and add some additional parameters to the existing structure while retaining the original model parameters, and train this part of the parameters to achieve the effect of fine-tuning. The author uses Bert as the experimental model, and adds an Adapter structure after the Attention layer of each Transformer Block and two fully connected layers. The overall structure is as follows:
The Adapter structure has two characteristics: fewer parameters and an output similar to the original structure at initialization. In the actual fine-tuning, due to the adoption of the down-project and up-project architecture, when fine-tuning, the Adapter will first map the feature input to a lower dimension through the down-project, and then map it back to the high dimension through the up-project, so that Reduce the number of parameters. Adapter-Tuning only needs to train 0.5%-8% of the parameters of the original model. If fine-tuning for different downstream tasks, only a small number of parameters of the Adapter structure need to be reserved for different tasks. Due to the residual connection structure in the Adapter, initializing the Adapter with appropriate small parameters can make it almost maintain the original output, so that the model can still perform well in the initial stage of training when additional structures are added. On the GLUE test set, the Adapter uses a smaller number of parameters to achieve an effect close to that of the traditional transfer learning method.
2、Prefix-Tuning: Optimizing Continuous Prompts for Generation(ACL 2021)
This article is a work of Stanford University in ACL2021. The author proposes a prefix fine-tuning method, which is different from the Prompting method in which GPT-3 prompts the model to generate output through natural language instructions. The author uses continuous task-related vectors as input prefixes, and does not train model parameters during fine-tuning, only training These prefix vectors, and utilize these continuously trainable Prefix Embedding hints to the model to generate the correct output. The following figure is the representation of the method in the autoregressive model and the encoder-decoder model respectively:


During training, the optimization objective of Prefix-Tuning is the same as normal fine-tuning, but only the parameters of the prefix vector need to be updated. The author found that directly updating the parameters of the prefix vector will lead to training instability and a slight drop in results, so a re-parameterization method is used to generate a normal-scale prefix vector through a single-layer MLP through a number of smaller prefix vectors. The form Expressed as follows:

After training, the smaller prefix vectors used for reparameterization are discarded, and only the parameters of the target prefix vector are kept.
The author uses Table-To-Text and Summarization as experimental tasks. On the Table-To-Text task, Prefix-Tuning is much better than Adapter when optimizing the same parameters, and it is almost the same as full parameter fine-tuning. On the Summarization task, the Prefix-Tuning method is slightly worse than the full parameter fine-tuning when using 2% parameters and 0.1% parameters, but still better than Adapter fine-tuning.
3、GPT Understands, Too(Arxiv 2021.3.18)
This paper proposes the P-tuning method, which searches for suitable prompt vectors in continuous space through automatic search methods, and bridges the gap between the GPT model and natural language understanding tasks. Similar to Prefix-Tuning, P-tuning also uses continuous trainable vectors as the input of the pre-training model, and optimizes the prompt vector through the gradient descent method.
Different from Prefix-Tuning, P-tuning does not only place Prompt in the prefix part of the input, but uses an appropriate Template to prompt the model, and trains continuous Prompt representations through gradient descent to get the best Prompting Effect. Its structure is as follows:
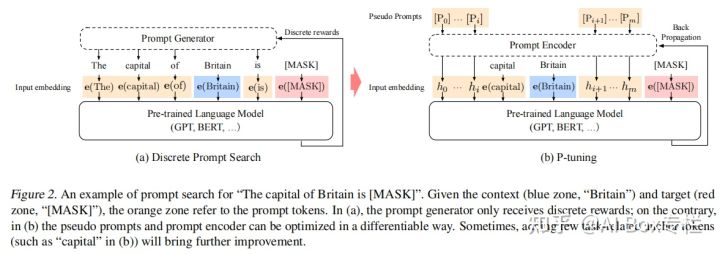
If random initialization is used for each prompt vector, since the ideal target vector (that is, the discrete prompt in the left figure) has become highly discretized after pre-training, it is easy to fall into a local optimum when optimizing with gradient descent. At the same time, the author believes that intuitively prompt embeddings (that is, the continuous prompts in the right figure) should be interdependent, and some methods need to be used to increase the correlation between prompts. Therefore, the author used a Prompt Encoder consisting of a bidirectional LSTM and a two-layer MLP for mapping. The formal representation is as follows:

The author tested on two natural language understanding datasets: LAMA knowledge probing and SuperGlue, and achieved results close to or even better than BERT. At the same time, the author shows through experiments that the P-tuning method can also help BERT to improve on related tasks.
4、The Power of Scale for Parameter-Efficient Prompt Tuning(EMNLP 2021)
This article is a work of Google on EMNLP 2021. This work continues the idea of Prompt-Tuning, using continuous Soft Prompt for training, and freezing all other parameters of the model. Unlike Prefix-Tuning and P-Tuning, the author did not use any Prompt mapping layer (that is, the reparameterization layer in Prefix-Tuning and the Prompt Encoder in P-Tuning), but directly to the Embedding corresponding to the Prompt Token Trained.
The author uses the T5 model as the experimental backbone, and remodels all tasks as text-to-text generation tasks. T5 uses Span Corruption to restore scrambled or masked sentences, which will cause the input and output of the model to be unnatural language texts, making the Prompt-Tuning method with a small number of parameters unable to bridge the gap between pre-training tasks and downstream tasks. difference. Therefore, the author made the following changes for T5.
- Directly use Span Corruption to test downstream tasks
- Takes Span Corruption, but prefixes the input text with task-related Sentinel
- Continue to supervise T5 for a short period of time, but adopt the training goal of LM, that is, given a text prefix, and generate follow-up text that conforms to natural language according to the prefix text. This is to enable T5 to have a certain ability to output natural language.
The author conducted experiments on the SuperGlue test set, and the experimental results are as follows:
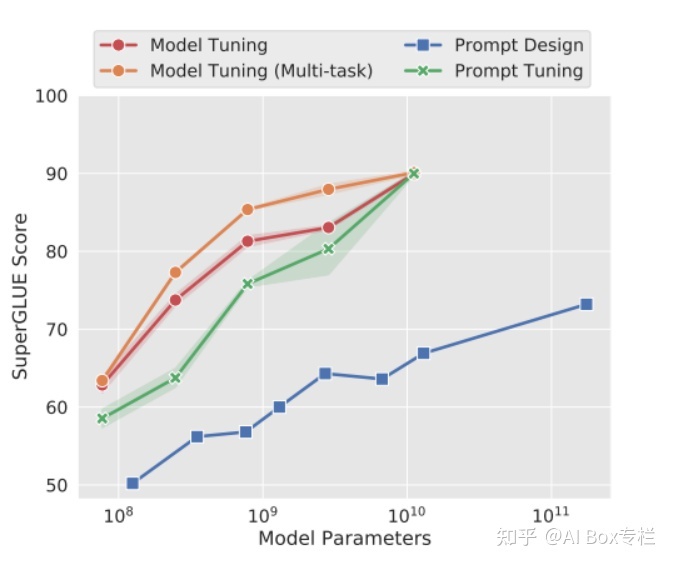
It can be seen that as the size of the model increases, the effect of Prompt-Tuning is getting closer, and it is almost the same as the effect of Model-Tuning when the amount of parameters is large enough, and it is significantly better than artificially designed discrete Prompting at any model size. method.
5、LoRA Low-Rank Adaptation of Large Language Models(ICLR 2022)
This article is a work submitted by Microsoft on ICLR2022. The author proposes a new fine-tuning method based on low-rank matrix optimization LoRA, which can reduce the amount of training parameters to nearly one ten-thousandth of the original when fine-tuning downstream tasks, and will hardly hurt the pre-training model. performance on downstream tasks.
The article first pointed out the shortcomings of previous lightweight fine-tuning methods. For the Adapter-Tuning method, due to the addition of an additional structure to the model, although the Adapter uses the Down-Project and Up-Project methods to reduce the amount of parameters, the redundant structure will still slow down the speed of the model during inference. For the Prompt-Tuning method, the training of Prompt is often unstable. At the same time, adding Prompt Token to the input sequence will also reduce the effective sequence length of the input to a certain extent, thus affecting the performance of the model.
LoRA overcomes the above problems by optimizing the "low rank parameters" of the matrix. Neural networks typically contain a large number of fully connected layers, and forward propagation is done by performing matrix multiplication. The parameter matrices in these fully connected layers are often of full rank. [1] proves that there is often a lower "essential dimension" in the parameters of the pre-trained language model, even if the parameter matrix to be optimized is mapped to a smaller Excellent learning ability can also be maintained in the subspace. Under such a premise, the author hopes to optimize only the low-rank part of the parameter matrix, and express the optimization process of the original matrix as an optimization process of a low-rank matrix:
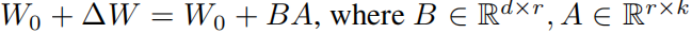
In this way, we can express the forward propagation process as follows:

Among them, A and B are low-dimensional matrices. After adopting such a transformation, the parameter scale to be optimized is changed from the original parameter scale to the parameter scale of the low-dimensional matrix, which greatly reduces the number of parameters. During the experiment, the author initializes B with a zero matrix and initializes A with a random Gaussian distribution. The whole process is as follows:
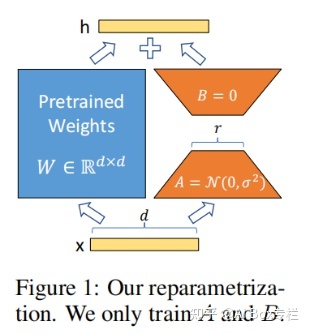
The author used LoRA to conduct experiments on RoBERTa, DeBERTa, GPT-2 and GPT-3 respectively. LoRA achieves near-full-parameter fine-tuning results using only a very small number of parameters. On GPT-3 with 175 billion parameters, LoRA only optimized 37.7 million parameters, that is, achieved more than full parameter fine-tuning effects on WikiSQL, MNLI-m and SAMSum data sets, proving the correctness of the method.
6、Enabling Lightweight Fine-tuning for Pre-trained Language Model Compression based on Matrix Product Operators(ACL 2021)
This work proposes a novel model compression and lightweight fine-tuning scheme - MPOP. The idea of MPOP comes from the MPO decomposition method in the physical quantum many-body problem. Given a matrix, MPO decomposition can represent the matrix as a product of several tensors as follows:
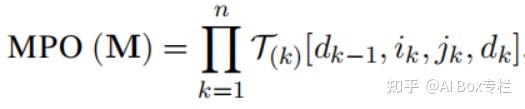
Based on this method, we can decompose the parameter matrix, and define the tensor in the middle as the central tensor, and the tensors in the remaining positions as auxiliary tensors. Due to the characteristics of MPO decomposition, the parameter amount of the intermediate tensor is much larger than that of the auxiliary tensor, so the author guesses that the intermediate tensor stores the core linguistic information of the pre-training model, and the adaptation of the downstream task only needs to train the auxiliary tensor with low parameter amount amount, as shown in the figure below:

In addition, the author uses the connection key truncation method to achieve a low-rank approximation to the original matrix, and calculates the upper bound of the error of reconstructing the original parameter matrix, as shown in the following figure:
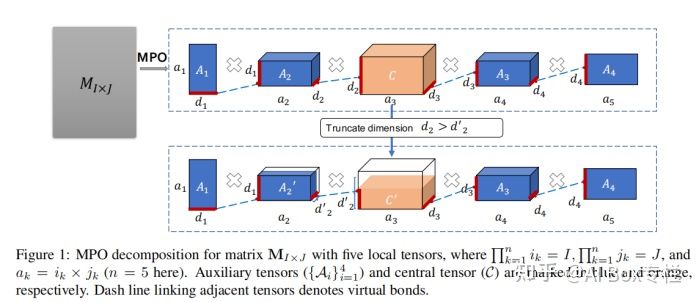

In the end, the author used the GLUE data set to conduct experiments on ALBERT. When the amount of fine-tuning parameters was reduced by 91%, it achieved results exceeding the full parameter fine-tuning except for the MNLI task.
7、Y-Tuning: An Efficient Tuning Paradigm for Large-Scale Pre-Trained Models via Label Representation Learning ACL2021(ACL 2022 ARR)
This work proposes a label-based mapping method. Unlike the mainstream lightweight fine-tuning method, Y-Tuning completely freezes the entire pre-training model, and learns different downstream tasks through label mapping in downstream tasks. corresponding label features. In other words, Y-Tuning no longer learns feature-representation at all, but instead learns label-representation that is more complicated than one-hot. The advantages of Y-Tuning can be summarized as follows:
- Lightweight parameters: Y-Tuning only needs to train the last label mapping layer without any update to the pre-training model, and the number of training parameters is greatly reduced.
- Lightweight training: The pre-trained model does not need to record any gradient-related information, which greatly reduces time and storage consumption.
- Lightweight reasoning: During the reasoning process, the data of all different tasks can be encoded and represented through a forward pass.
- Robust: The pre-trained model itself does not undergo any adjustments, so it is difficult to attack the model through the adversarial data of downstream tasks.
- Safe: By encoding the label, the information of the label itself is hidden, thereby reducing the possibility of data leakage.
The structure of Y-Tuning is as follows:
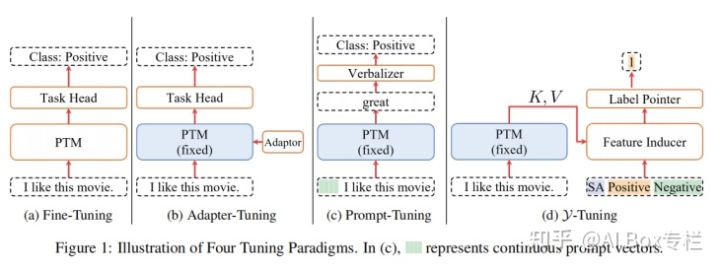
The authors conducted experiments on the GLUE dataset using the BART and RoBERTA models. Experiments show that the effect of Y-Tuning is significantly improved compared with the traditional method of completely freezing the pre-training model, and the speed is more than 6 times faster than the method of full parameter fine-tuning. However, there is still a certain gap between the final effect and the full parameter fine-tuning.
8、Composable Sparse Fine-Tuning for Cross-Lingual Transfer(ACL 2022 ARR)
This article is a work submitted by the University of Cambridge on 2022ACL ARR. It mainly proposes a Sparse Fine-Tuning method based on the lottery ticket hypothesis, which reduces the amount of fine-tuning parameters and achieves better cross-language task transfer than previous methods. Effect.
Lottery-ticket assumes that in a parameter matrix, only a small number of parameter updates are helpful for learning, and these parameters are called lottery tickets. The pruning method Lottery-ticket Sparse Fine-Tuning (LT-SFT) used in this paper refers to: After a round of training, the updated smaller parameters are pruned through a mask according to a certain ratio, and they are restored to the original Pre-train weights while keeping other parameters with larger updates. Finally, after many rounds of training, only a small part of the parameters of the model are actually updated.
The migration of cross-language tasks is also completed through LT-SFT. For a certain target language corpus, first use the pre-trained MLM objective function to train through the LT-SFT method to obtain the corresponding sparse difference matrix (that is, the update amount of parameters), Called Language SFT. For a certain task, the corresponding difference matrix is obtained again by using LT-SFT on the corresponding downstream task in the source language (usually English), which is called Task SFT. In the end, we directly added these SFTs to obtain a cross-language transfer model, and the model also obtained the ability to perform downstream tasks on the source language in the target language. The framework of the whole model is as follows:
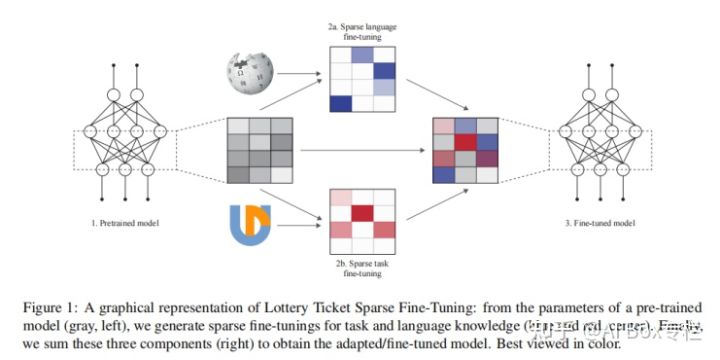
The authors conduct experiments on four downstream tasks: part-of-speech tagging (POS), syntactic analysis (DP), named entity recognition (NER) and natural language inference (NLI). The author trained on 35 different languages (usually uncommon languages with fewer data sets), and compared to the original Baseline-Adapter-based MAD-X method for this task, it has been greatly improved.
9、Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning(EMNLP 2021)
This article is a work on EMNLP2021. From the perspective of parameter update, the author proposes a sub-network-based Child-Tuning method, which alleviates the over-fitting problem of large-scale pre-training models when training on relatively small-scale downstream task data by only updating some parameters of the original network. , and has a significant performance improvement compared to traditional fine-tuning methods.
Standard full-parameter fine-tuning often has problems of instability and poor generalization performance. Previous work has proved that fine-tuning often does not need to fine-tune the entire network, but only needs to fine-tune some parameters. Child-Tuning achieves this by updating sub-networks in the network. Child-Tuning will first find the sub-network in the parameter matrix according to a certain strategy, and generate the corresponding mask matrix. After calculating the gradient, only the parameters corresponding to the self-network are updated according to the mask, while other parameters remain unchanged. The Child-Tuning method is different from the pruning method in that it does not invalidate a non-self-network parameter, but just stops updating it. Therefore, Child-Tuning only works when the gradient is backpropagated, and does not make any changes during forward propagation. Its method can be expressed as the following figure:
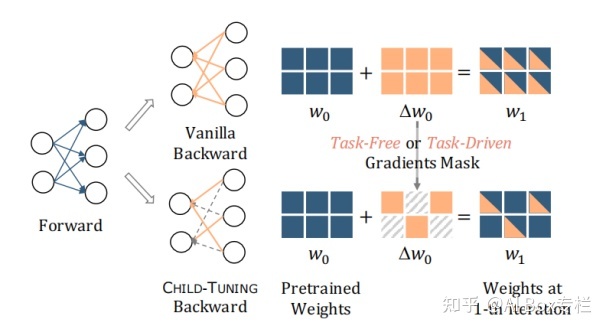
The author proposes two variants of Child-Tuning: task-independent Child-Tuning-F and task-related Child-Tuning-D. For task-independent Child-Tuning-F, since it has nothing to do with downstream tasks, it only needs to obtain a random mask matrix by sampling Bernoulli distribution. For task-related Child-Tuning-D, the author uses the Fisher Information Matrix (FIM) to calculate the importance of each parameter to the downstream task, and adjusts the mask matrix for each iteration according to this strategy.
The author used BERT-large, XLNet-large, RoBERTa-large and ELECTRA-large models to conduct experiments on four benchmark tasks of GLUE. Compared with the full parameter fine-tuning method, Child-Tuning has improved, and it has also improved the generality of the model. ability, which demonstrates the effectiveness of the method.
10、Towards a Unified View of Parameter-Efficient Transfer Learning(ICLR 2022)
This article is a work of CMU on ICLR2022. The author mainly explores the Prefix-Tuning, Adapter and LoRA methods, analyzes the connections and differences between these current mainstream lightweight fine-tuning methods, and regards them as lightweight fine-tuning methods to learn the specific hidden layer state in the model, And a unified lightweight fine-tuning framework is proposed to integrate these methods.
The author uses the calculation process of the input to represent the difference of each lightweight fine-tuning method. For the Adapter, its calculation process is as follows:

where h denotes the hidden representation to be modified, and x denotes the direct input of the submodule. For the Prefix-Tuning method, after a series of transformations, the Prefix-Tuning method can be expressed as follows:

LoRA achieves the effect of lightweight fine-tuning by fine-tuning a low-rank matrix, which can also be expressed in a similar form:
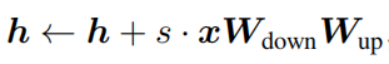
After the above analysis, the author found that the essential calculation forms of the three methods are similar, and all three methods can be expressed as modifications to the hidden state of the model, and these methods are unified in the same framework, as shown in the figure below Shown:

The author uses BART-Large's multilingual model variants mBART-Large and RoBERTa-Base to test on document summarization, cross-language translation, natural language reasoning and sentiment classification data sets respectively. The optimal ensemble outperforms all previous lightweight fine-tuning methods and is very close to full-parameter fine-tuning.
references
[1] Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning.
[2] The Power of Scale for Parameter-Efficient Prompt Tuning
[3] Parameter-Efficient Transfer Learning for NLP Adapter
[4] The Power of Scale for Parameter-Efficient Prompt Tuning
[5] LoRA Low-Rank Adaptation of Large Language Models
[6] Enabling Lightweight Fine-tuning for Pre-trained Language Model Compression based on Matrix Product Operators
[7] Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning
[8] Towards a Unified View of Parameter-Efficient Transfer Learning
[9] Composable Sparse Fine-Tuning for Cross-Lingual Transfer