If you are interested in this article and want to learn more about practical skills in the field of AI, you can follow the "Technology Frenzy AI" public account . Here, you can see the latest and hottest articles and practical case tutorials in the AIGC field.
I. Introduction
In the field of large language models (LLMs), fine-tuning is a key process to improve performance and adjust behavior. However, fine-tuning for large models can be very expensive due to huge memory requirements. Recently, the University of Washington published an innovative solution to this problem-QLoRA (Quantized Low-Rank Adapter).
QLoRA is a new method for fine-tuning large language models (LLM) that saves memory while maintaining speed. The working principle is to first quantize the LLM by 4 bits, thereby significantly reducing the memory footprint of the model. Next, the quantized LLM is fine-tuned using the low-order adapter (LoRA) method. LoRA enables the improved model to retain most of the accuracy of the original LLM while being smaller and faster.
The above is a brief introduction to QLoRA, and its principles and applications will be further discussed below.
2. Introduction to QLoRA
QLoRA is an efficient fine-tuning method that significantly reduces memory usage by backpropagating gradients into a low-order adapter (LoRA). It can fine-tune a 65 billion-parameter model on a single 48GB GPU and maintain full 16-bit fine-tuning task performance.
A new model family called Guanaco was also launched, which performed well on the Vicuna benchmark, reaching 99.3% of the ChatGPT performance level. What is surprising is that such excellent results can be achieved with only 24 hours of fine-tuning on a single GPU. These innovations enable model fine-tuning in a more efficient manner with limited resources, and achieve very satisfactory results.
QLoRA is an innovative fine-tuned LLM method that has been verified on multiple tasks, including text classification, question answering, and natural language generation, proving its effectiveness in various fields. The emergence of this method provides a more convenient way to apply LLM to a wider range of users and applications, and is expected to further promote the application of LLM in different fields.
2.1. Key innovations
Traditional LoRA (low-rank adapter) and QLoRA (quantized LoRA) are both methods for fine-tuning large language models and reducing memory requirements. However, QLoRA introduces several innovations to further reduce memory usage while maintaining performance. Here's a comparison of the two methods:
LoRA:
-
- Use a small set of trainable parameters (adapters) while keeping the full model parameters fixed.
-
- The gradients during stochastic gradient descent are passed through fixed pre-trained model weights to the adapter, which is updated to optimize the loss function.
-
- More memory efficient than full fine-tuning, but still requires 16-bit precision for training.
QLoRA:
-
- Backpropagation of gradients into a low-order adapter (LoRA) via a frozen 4-bit quantized pre-trained language model.
-
- Introducing 4-bit NormalFloat (NF4), an information-theoretically optimal quantized data type for normally distributed data that produces better empirical results than 4-bit integers and 4-bit floating point.
-
- Applying double quantization, a method of quantizing quantization constants, saves an average of about 0.37 bits per parameter.
-
- Use the paging optimizer with NVIDIA unified memory to avoid memory spikes during gradient checkpoints when processing mini-batches with long sequence lengths.
-
- Significantly reduced memory requirements compared to the 16-bit fully fine-tuned baseline, allowing fine-tuning of a 65B parameter model on a single 48GB GPU without degrading runtime or prediction performance.
In summary, QLoRA builds on traditional LoRA and introduces 4-bit quantization, 4-bit NormalFloat data type, double quantization, and paging optimizer to further reduce memory usage while maintaining performance comparable to 16-bit fine-tuning methods.
2.2 Performance analysis
An in-depth study of model size and chatbot performance revealed some interesting results. Due to memory overhead limitations, conventional fine-tuning methods cannot be used. Therefore, a special instruction fine-tuning method was used to train on multiple data sets, different model architectures and parameter numbers, with a total of more than 1000 models trained.
The results show that even using smaller models than previous state-of-the-art models, fine-tuning with QLoRA on small high-quality datasets can achieve state-of-the-art results. This shows that data quality has a far greater impact on model performance than the size of the data set. This finding has important guiding significance for optimizing the performance of chatbots.
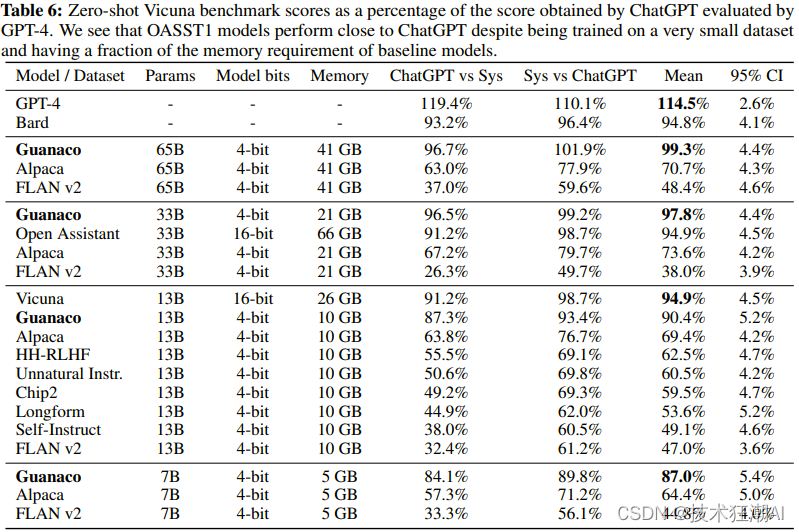
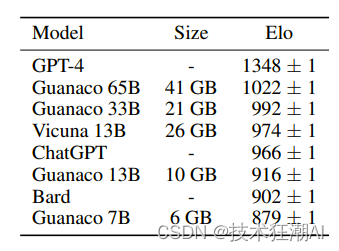
Evaluation was conducted on the Guanaco 65B model, which was fine-tuned for variants of OASST1 using QLORA. The results show that it is the best performing open source chatbot model and its performance is comparable to ChatGPT. Compared to GPT-4, Guanaco 65B and 33B have an expected winning probability of 30%.
-
In the Vicuna benchmark, Guanaco 65B performs best after GPT-4, achieving 99.3% performance relative to ChatGPT. Despite having more parameters, the Guanaco 33B model is more memory efficient than the Vicuna 13B model because the weights only use 4 digits of precision. Furthermore, the Guanaco 7B can be installed on modern phones while outscoring the Alpaca 13B by nearly 20 percentage points.
-
Although the results are impressive, many models have overlapping performances with wide confidence intervals. The authors attribute this uncertainty to the lack of clear scaling specifications. To solve this problem, they propose to use the Elo ranking method, which is based on the pairwise judgments of human annotators and GPT-4.
-
Elo rankings show that the Guanaco 33B and 65B models outperform all models except GPT-4 on the Vicuna and OA benchmarks, and perform on par with ChatGPT. However, the choice of fine-tuning dataset greatly affects the performance, indicating the importance of dataset suitability.
3. Use QLoRA to fine-tune the GPT model
3.1. Hardware requirements for QLoRA:
-
GPU: For models with less than 20 billion parameters, such as GPT-J, it is recommended to use a GPU with at least 12 GB VRAM. For example, an RTX 3060 12 GB GPU is available. If you have a larger GPU and 24 GB VRAM, you can use a model with 20 billion parameters, such as GPT-NeoX-20b.
-
RAM: It is recommended that you have at least 6 GB RAM. Most computers today meet this criterion.
-
Hard Drive: Since GPT-J and GPT-NeoX-20b are large models, you need at least 80 GB of free space on your hard drive.
If your system does not meet these criteria, you can use a free instance of Google Colab.
3.2. QLoRA software requirements:
-
CUDA : Make sure CUDA is installed on your computer.
-
Dependencies : dependencies:
-
bitsandbytes : This library contains all the tools needed to quantify large language models (LLMs).
-
Hugging Face Transformers and Accelerate : These standard libraries are used for efficient model training of Hugging Face Hub.
-
PEFT : This library provides implementations of various methods to fine-tune a small number of additional model parameters. LoRA requires it.
-
Dataset : Although not mandatory, a dataset library can be used to obtain a dataset for fine-tuning. Alternatively, you can provide your own dataset.
Make sure to install all required software dependencies before proceeding with QLoRA-based fine-tuning of the GPT model.
4. QLoRA Demonstration
Guanaco is a system designed for research purposes and can be experienced through the following demo address.
-
Visit the Guanaco Playground demo [4], this is a demo for the 33B model, the 65B model will be demoed later.
-
If you want to host your own Guanaco grdio demo, you can use this[5]. For 7B and 13B models, it works with a free GPU.
-
Regarding the difference between ChatGPT and guanaco, their model responses can be compared in [6]. On the Vicuna tip you can see the comparison between ChatGPT and guanaco 65B.
5. QLoRA installation
To use Transformer and BitsandBytes to load 4-bit models, you must install the accelerator and Transformer from source and install the current version of the BitsandBytes library (0.39.0). You can use the following command to achieve the above purpose:
pip install -q -U bitsandbytes
pip install -q -U git+https://github.com/huggingface/transformers.git
pip install -q -U git+https://github.com/huggingface/peft.git
pip install -q -U git+https://github.com/huggingface/accelerate.git
6. Getting Started with QLoRA
qlora.pyFunctions can be used to fine-tune and infer on a variety of data sets. Here are the basic commands for fine-tuning a baseline model on the Alpaca dataset:
python qlora.py --model_name_or_path <path_or_name>
For models larger than 13B, we recommend adjusting the learning rate:
python qlora.py –learning_rate 0.0001 --model_name_or_path <path_or_name>
6.1. Quantification
The quantization parameters are BitsandbytesConfigcontrolled by as follows:
-
Enable 4-bit loading via
load_in_4bit. -
bnb_4bit_compute_dtypeData type used for linear layer calculations. -
Nested quantization is
bnb_4bit_use_double_quantenabled via . -
bnb_4bit_quant_typeSpecifies the data type used for quantification. Two quantized data types are supported:fp4(four-bit floating point) andnf4(regular four-bit floating point). We advocate its usenf4because it is theoretically optimal for normally distributed weights.
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path='/name/or/path/to/your/model',
load_in_4bit=True,
device_map='auto',
max_memory=max_memory,
torch_dtype=torch.bfloat16,
quantization_config=BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type='nf4'
),
)
6.2. Paging optimizer
To handle the occasional situation where the GPU runs out of memory, QLoRA uses a paging optimizer that leverages NVIDIA's Unified Memory feature, which performs automatic page-to-page transfers between the CPU and GPU and functions similarly to regular memory between CPU RAM and GPU Pagination is very similar. disk. This feature is used to allocate paged memory for the optimizer state, then move it to CPU RAM when GPU memory is low, and move it back to GPU memory when needed.
We can access the paging optimizer using the following parameters.
--optim paged_adamw_32bit
7. Use QLoRA to fine-tune LLaMA 2
Next we describe how to fine-tune the latest Llama-2-7b model on a single Google Colab and turn it into a chatbot. We will use the PEFT library in the Hugging Face ecosystem as well as QLoRA to achieve more efficient memory fine-tuning.
7.1. PEFT or parameter efficient fine-tuning
PEFT (Parameter Efficient Fine-Tuning) is a new open source library from Hugging Face that efficiently adapts pre-trained language models (PLM) to a variety of downstream applications without the need to fine-tune all model parameters. PEFT currently includes the following technologies:
-
LoRA: low-order adaptation for large language models [8]
-
Prefix Tuning: P-Tuning v2: Fast tuning comparable to universal fine-tuning across scales and tasks
-
P-Tuning: GPT can also understand [9]
-
On-the-fly tuning: The power of scale enables efficient on-the-fly tuning of parameters [10]
7.2. Set up the development environment
First you need to install the necessary dependencies, we will need to install the accelerate, peft, transformers, datasetsand TRL libraries to take advantage of the latest SFTTrainer. bitsandbytesQuantize the base model to 4 bits by using . It will also be installed einopsas it is a required library to load the Falcon model.
pip install -q -U trl transformers accelerate git+https://github.com/huggingface/peft.git
pip install -q datasets bitsandbytes einops wandb
7.3. Prepare data set
We loaded the train dataset split from the AlexanderDoria/novel17_test dataset. This data set contains text data of some French novels and is used for training and evaluation of natural language processing tasks. The text in this dataset will be used to train the model to perform natural language processing on French novels.
from datasets import load_dataset
#dataset_name = "timdettmers/openassistant-guanaco" ###Human ,.,,,,,, ###Assistant
dataset_name = 'AlexanderDoria/novel17_test' #french novels
dataset = load_dataset(dataset_name, split="train")
7.4. Load model
Loaded the pretrained model and set the quantization configuration using the BitsAndBytesConfig function, loading the model as 4 bits and using the torch.float16 calculation data type. Load the pretrained model into the model variable through the from_pretrained function, and pass the quantization configuration to the model.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, AutoTokenizer
model_name = "TinyPixel/Llama-2-7B-bf16-sharded"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
trust_remote_code=True
)
model.config.use_cache = False
Load the pretrained model's tokenizer and configure it to add padding markers at the end of the sequence for batch processing when using the model for inference.
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
Create a PEFT configuration object for use when training and evaluating the model.
from peft import LoraConfig, get_peft_model
lora_alpha = 16
lora_dropout = 0.1
lora_r = 64
peft_config = LoraConfig(
lora_alpha=lora_alpha,
lora_dropout=lora_dropout,
r=lora_r,
bias="none",
task_type="CAUSAL_LM"
)
7.5. Load the trainer
We will use the TRL library SFTTrainer, which provides Trainerwrappers around transformers to easily fine-tune models on instruction-based datasets using PEFT adapters. Let's first load the training parameters below.
from transformers import TrainingArguments
output_dir = "./results"
per_device_train_batch_size = 4
gradient_accumulation_steps = 4
optim = "paged_adamw_32bit"
save_steps = 100
logging_steps = 10
learning_rate = 2e-4
max_grad_norm = 0.3
max_steps = 100
warmup_ratio = 0.03
lr_scheduler_type = "constant"
training_arguments = TrainingArguments(
output_dir=output_dir,
per_device_train_batch_size=per_device_train_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
optim=optim,
save_steps=save_steps,
logging_steps=logging_steps,
learning_rate=learning_rate,
fp16=True,
max_grad_norm=max_grad_norm,
max_steps=max_steps,
warmup_ratio=warmup_ratio,
group_by_length=True,
lr_scheduler_type=lr_scheduler_type,
)
Then finally pass everything to the trainer, creating a trainer object to train the specified language model.
from trl import SFTTrainer
max_seq_length = 512
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=max_seq_length,
tokenizer=tokenizer,
args=training_arguments,
)
We will also preprocess the model by upgrading the layer specification in float 32 for more stable training
for name, module in trainer.model.named_modules():
if "norm" in name:
module = module.to(torch.float32)
7.6. Training model
Next, the training process of the model is started to update the model parameters through the backpropagation algorithm to improve the performance of the model.
trainer.train()
During training, the model should converge nicely as shown below:
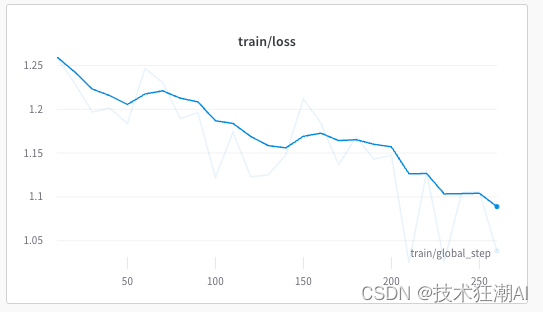
Save the trained model to the local file system for subsequent use. SFTTrainerOnly the adapter is saved correctly, not the entire model.
model_to_save = trainer.model.module if hasattr(trainer.model, 'module') else trainer.model # Take care of distributed/parallel training
model_to_save.save_pretrained("outputs")
Use the LoraConfig class to load the configuration information of a pretrained model and combine it with an existing model to obtain a new model.
lora_config = LoraConfig.from_pretrained('outputs')
model = get_peft_model(model, lora_config)
Use the pre-trained model to generate a new piece of text to test the model's generation capabilities.
text = "Écrire un texte dans un style baroque sur la glace et le feu ### Assistant: Si j'en luis éton"
device = "cuda:0"
inputs = tokenizer(text, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Push the model to Hugging Face Hub where it can be shared and accessed with others.
from huggingface_hub import login
login()
model.push_to_hub("llama2-qlora-finetunined-french")
8. Limitations of QLoRA
QLoRA is a reasoning model based on LoRA (Logical Reasoning Architecture), which has some limitations in some aspects. The following are some known limitations:
-
Slow inference speed: QLoRA's inference speed is relatively slow when using four-digit inference. Currently, QLoRA's four-bit inference system is not yet connected to four-bit matrix multiplication, which may affect its performance and speed.
-
Trainer recovery training failure: When using Trainer to resume LoRA training runs, you may encounter failures. This may be due to some internal issue or incorrect configuration and will require further investigation and resolution.
-
Instability with bnb 4bit compute type='fp16' : Currently, using bnb 4bit compute type='fp16' may cause instability. Especially for the 7B LLaMA task, only 80% of the fine-tuning runs without problems. While there are solutions, they are not yet implemented in bits and bytes.
-
Set tokenizer.bos token id to 1: To avoid difficulties, it is recommended to set tokenizer.bos token id to 1. This is probably to ensure that when using QLoRA, the ID of the start tag (BOS) is correctly set to 1 to avoid potential issues.
9. Summary
QLoRA is a quantization-based language model fine-tuning method that quantizes pre-trained language models into a low-precision format, thereby increasing inference speed and reducing model storage space while maintaining model performance.
In this article, we explore how to use the QLoRA method to fine-tune the LLaMA 2 model, including loading the pre-trained model, setting the quantization configuration, using the SFTTrainer class to create a trainer object, and training the model. We also discussed how to use the BitsAndBytesConfig function to quantize the model to 4 bits and use the torch.float16 calculation data type for calculations. These operations can help us increase inference speed and reduce model storage space while maintaining model performance, thereby enabling the deployment and application of language models in resource-constrained environments.
10. References
[1]. QLoRA GitHub:
https://github.com/artidoro/qlora
[2]. QLoRA Pager:
https://arxiv.org/abs/2305.14314
[3]. Bits and Bytes (for 4-bit training):
https://github.com/TimDettmers/bitsandbytes
[4]. Guanaco HF Playground:
https://huggingface.co/spaces/uwnlp/guanaco-playground-tgi
[5]. Guanaco Gradio Colab:
https://colab.research.google.com/drive/17XEqL1JcmVWjHkT-WczdYkJlNINacwG7?usp=sharing
[6]. Guanaco vs ChatGPT Colab:
https://colab.research.google.com/drive/1kK6xasHiav9nhiRUJjPMZb4fAED4qRHb?usp=sharing
[7]. PEFT GitHub:
https://github.com/huggingface/peft
[8]. LoRA Pager:
https://arxiv.org/pdf/2106.09685.pdf
[9]. P-Tuning Pager:
https://arxiv.org/pdf/2103.10385.pdf
[10]. Prompt Tuning Pager:
https://arxiv.org/pdf/2104.08691.pdf
[11]. SFTTrainer HF:
https://huggingface.co/docs/trl/main/en/sft_trainer
If you are interested in this article and want to learn more about practical skills in the field of AI, you can follow the "Technology Frenzy AI" public account . Here, you can see the latest and hottest articles and practical case tutorials in the AIGC field.