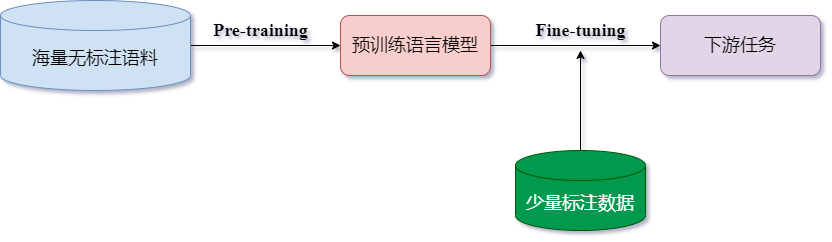
The success of the pre-trained language model proves that we can learn latent semantic information from massive unlabeled texts without having to individually label a large amount of training data for each downstream NLP task. In addition, the success of the pre-trained language model has also created a new paradigm of NLP research, that is, firstly use a large amount of unsupervised corpus for language model pre-training ( Pre-training),