1. Le type de données
1 Données structurées
Les données structurées font référence aux données qui peuvent être exprimées et stockées à l'aide d'une base de données relationnelle et sont représentées sous une forme bidimensionnelle.Les caractéristiques générales sont: Les données sont exprimées en unités de lignes, une ligne de données représente les informations d'une entité et les attributs de chaque ligne de données sont les mêmes.
2 Données semi-structurées
Modèle non relationnel, données avec un schéma structurel fixe de base,Par exempleFichiers journaux, documents XML, documents jsonW, etc.
3 Données non structurées
Comme son nom l'indique, cela signifie des données sans structure fixe. Divers documents, images et vidéo/audio sont tous des données non structurées. Pour ce type de données, nous les stockons généralement directement dans leur ensemble, et les stockons généralement sous formebinaireformat de données.
2. Introduction au HTML
1 HTML
Ⅰ HTML est un langage de balisage hypertexte (Hyper Text Markup Language) est un langage utilisé pour décrire les pages Web.
① Interprétation de l'hypertexte
Il peut ajouter des images, des sons, des animations, du multimédia et d'autres contenus, c'est-à-dire : au-delà de la limitation du texte ; non seulement cela, il peut également passer d'un fichier à un autre et se connecter avec des fichiers d'hôtes du monde entier, c'est-à-dire : texte du lien hypertexte
Ⅱ HTML n'est pas un langage de programmation, mais un langage de balisage (langage de balisage)
Ⅲ Un langage de balisage est un ensemble de balises de balisage
Ⅹ Pour faire simple, une page Web est composée d'éléments de page Web, qui sont décrits par des balises HTML, puis analysés par un navigateur avant d'être affichés aux utilisateurs.
2 Résumé des balises squelette HTML
① Le cadre de base est illustré dans la figure ci-dessous :
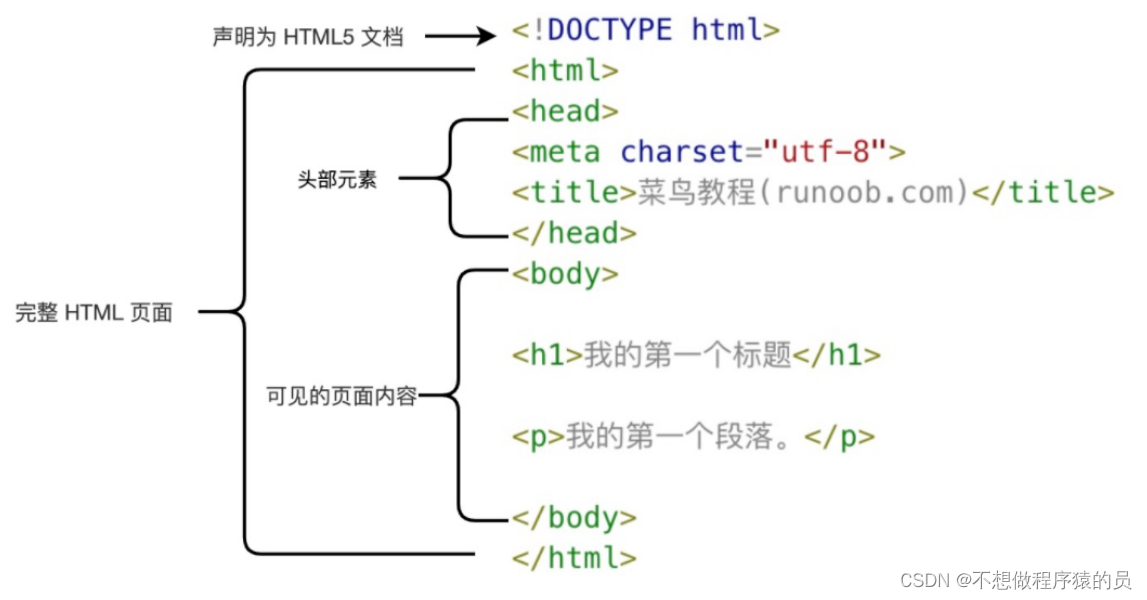
② L'explication de chaque étiquette est comme indiqué sur la figure

3 Relation entre les balises HTML
étiquette parent-enfant
<head>
<title> </title>
</head>
étiquette de frère
<head></head>
<body></body>
1 Les balises doubles HTML peuvent être divisées en : l'une estparent et enfantL'étiquette de la relation de confinement estfrère et sœurÉtiquettes parallèles
3. Explication détaillée des sélecteurs CSS
En css, un sélecteur est un mode de sélection des éléments qui doivent être stylisés, nous pouvons ensuite utiliser des sélecteurs css pour trouver les balises correspondantes en html.
1 Un exemple simple est le suivant :
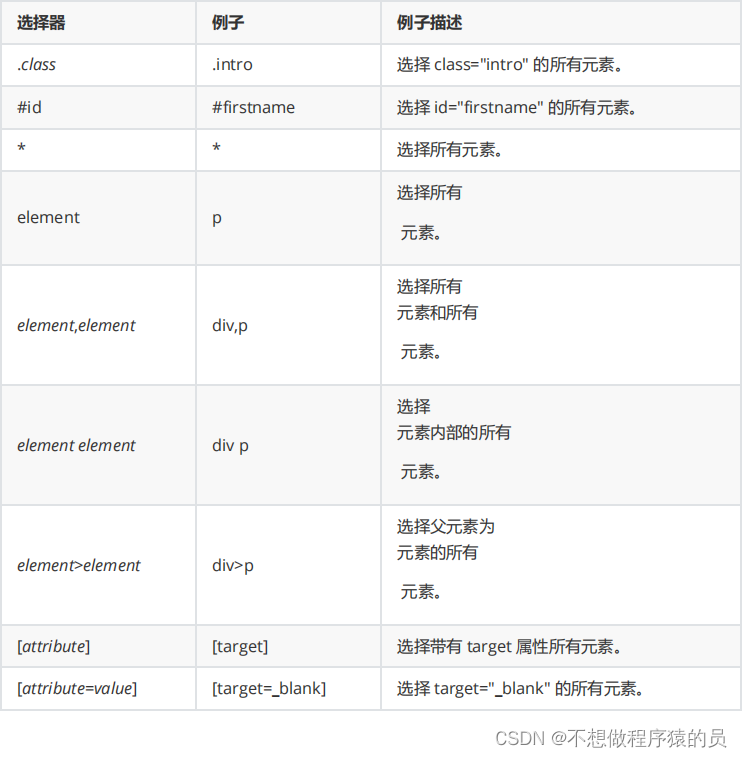
Sélecteur à 2 onglets
Le sélecteur d'étiquette est en fait l'étiquette dans le code html que nous disons souvent. Par exemple : html, span, p, div, a, img, etc. ; par exemple, nous voulons définir la police et la couleur d'un morceau de texte dans l'étiquette p dans la page Web. Ensuite, le code css est le suivant :
# 简化的html标签
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p>css标签选择器的介绍</p>
<p>标签选择器、类选择器、ID选择器</p>
<a href="https://www.baidu.com">百度一下</a>
<span> 我是一个span标签</span>
</body>
</html>
"""
import parsel
selector = parsel.Selector(html)
span = selector.css('span').getall()
print(span)
Résultat courant :
['Je suis une balise span']
3 types de sélecteurs
Le sélecteur de classe est le plus courant dans notre futur codage de style css. Il donne à l'élément un effet de style en définissant une classe distincte pour l'élément.utiliser la syntaxe:(Nous avons défini un attribut class class séparément pour la balise p ici, le code est le suivant)
# 简化的html标签
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p class="top">css标签选择器的介绍</p>
<p class="top">标签选择器、类选择器、ID选择器</p>
<a href="https://www.baidu.com">百度一下</a>
<span> 我是一个span标签</span>
</body>
</html>
"""
import parsel
selector = parsel.Selector(html)
p = selector.css('.top').getall()
print(p)
Résultat courant :
['
Introduction aux sélecteurs de balises CSS
', 'Sélecteur de balise, sélecteur de classe, sélecteur d'ID
']Explication détaillée:
- Les sélecteurs de classe sont tous des points anglais (.)début.
- Chaque élément peut avoir plusieurs noms de classe, et le nom peut être nommé arbitrairement (mais ne prenez pas le nom chinois, c'est généralement une abréviation anglaise liée au contenu)
4 sélecteur d'identification
Les sélecteurs d'ID sont similaires aux sélecteurs de classe et agissent de la même manière que les sélecteurs du même type, mais il existe quelques différences.
# 简化的html标签
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p class="top">css标签选择器的介绍</p>
<p class="top">标签选择器、类选择器、ID选择器</p>
<a href="https://www.baidu.com">百度一下</a>
<span> 我是一个span标签</span>
</body>
</html>
"""
import parsel
selector = parsel.Selector(html)
p = selector.css('#content').getall()
print(p)
Le résultat est le suivant :
['
Introduction aux sélecteurs de balises CSS
', 'Sélecteur de balise, sélecteur de classe, sélecteur d'ID
']Explication détaillée :
1. Le sélecteur d'ID définit id="ID name" pour l'étiquette au lieu de class="class name"
2. Le symbole devant le sélecteur d'ID est le signe dièse (#), au lieu de points anglais (.3.
Le nom du sélecteur d'ID est unique, c'est-à-dire que le sélecteur d'ID portant le même nom ne peut apparaître qu'une seule fois dans une page ;
5 sélecteurs combinés
Plusieurs sélecteurs peuvent être utilisés ensemble, ce qui est un sélecteur combiné.
# 简化的html标签
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p class="top">css标签选择器的介绍</p>
<p class="top">标签选择器、类选择器、ID选择器</p>
<a href="https://www.baidu.com">百度一下</a>
<span> 我是一个span标签</span>
</body>
</html>
"""
import parsel
selector = parsel.Selector(html)
result = selector.css('p#contend.top').getall()
print(result)
Le résultat est le suivant :
['
Introduction aux sélecteurs de balises CSS
', 'Sélecteur de balise, sélecteur de classe, sélecteur d'ID
']6 sélecteurs de pseudo-classe
Vous pouvez utiliser ==:== pour spécifier les balises que vous souhaitez extraire.
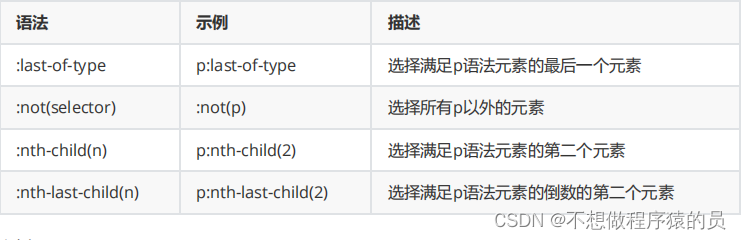
# 简化的html标签
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p class="top">css标签选择器的介绍</p>
<p class="top">标签选择器、类选择器、ID选择器</p>
<a href="https://www.baidu.com">百度一下</a>
<span> 我是一个span标签</span>
</body>
</html>
"""
import parsel
selector = parsel.Selector(html)
result = selector.css('p:nth-child(2)::text').getall()
print(result
Le résultat est le suivant :
['sélecteur d'étiquette, sélecteur de classe, sélecteur d'ID']
7 Extracteur d'attributs
Vous pouvez utiliser ==::== pour extraire les attributs contenus dans la balise.
# 简化的html标签
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p class="top">css标签选择器的介绍</p>
<p class="top">标签选择器、类选择器、ID选择器</p>
<a href="https://www.baidu.com">百度一下</a>
<span> 我是一个span标签</span>
</body>
</html>
"""
import parsel
selector = parsel.Selector(html)
result = selector.css('p#contend.top::text').getall()
print(result)
result = selector.css('a::attr(href)').getall()
print(result)
Les résultats sont les suivants :
['Introduction to css tag selector', 'Tag selector, class selector, ID selector']
['https://www.baidu.com']
4. Les avantages d'apprendre le CSS
CSS est l'une des trois fonctions majeures du front-end. Après l'avoir appris, il sera d'une grande aide pour notre front-end. Il existe deux autres méthodes d'analyse de données dans le crawler (expression régulière, xpath), l'éditeur mettra à jour dès que possible. Merci pour votre compagnie.