1. Select a big data platform
1. CDH big data platform
- The CDH big data platform is divided into a paid version and a free version. The paid version and the free version share system management, automated deployment, quick inspection, unified interface management, resource management, high availability (Zookeeper), management client configuration, node templates, and multiple Cluster management, monitoring of service host activity, extensive API, etc. Common components of hadoop, hive, spark and flink can be integrated.
- Features exclusive to the paid version
- Display of the current historical disk usage.
- Quota settings based on user and group.
- Record configuration history and rollback.
- Keep a trace file of all activity and configuration changes, including the ability to roll back to previous times.
- Automate backup and disaster recovery.
- Centrally configure and manage snapshots, and replicate HDFS, Hive, and Hbase workflows.
- Summary: The paid version provides 7X24 hours of technical support and provides version rollback. The free version of CDH supports common big data components and can be used.
2. HDP big data platform
- HDP is an enterprise-level Hadoop platform developed by American big data company Hortonworks. HDP is 100% open source. The platform mainly includes control integration, tools, data access (MapReduce, Pig, Hive/Tez, NoSQL), data management (HDFS, YARN) ), security and operations modules.
- Comparison of HDP and CDH
- 1. HDP is 100% completely open source, while CDH is not 100% completely open source.
- 2. Supported components, HDP and CDH basically support all open source big data components.
- 3. Code package dependencies. If it is the HDP platform, you can write the code directly depending on the version of Hadoop. If it is the CDH platform, you need to rely on the version of CDH to write the code.
3. CDP big data platform
- In 2019, the original cloudera company and hortonworks company merged, and CDP originated from the merger of their respective enterprise data cloud platforms CDH and HDP. CDP public cloud supports AWS, Azure, GCP and domestic aliCloud. CDP data center is similar to CDH and HDP, which is directly installed on the hardware server, and currently supports mainstream X86 servers on the market, including domestic Haiguang servers.
- CDP is a big data platform built on a cloud database by the cooperation of CDH and HDP. It has many integrated tools, high security, and relatively expensive. The government and large companies can choose it. It is not friendly to start-ups and the cost is too high.
4. Various cloud data middle platforms
- For example, Alibaba Cloud, Tencent Cloud, Kangaroo Cloud, Shumeng Workshop and other data platforms. Companies with a certain scale in the market will research and develop their own data platforms. The government generally adopts Alibaba Cloud data platforms. Maintenance, and the second is to reduce the cost of operation and maintenance and purchase of servers.
2. Select a scheduling platform
There are four common scheduling platforms in the market:
1. DolphinScheduler (Dolphin Scheduler)
- Docker-compose deployment dolphin scheduling
- DolphinScheduler official website
- Apache DolphinScheduler is a distributed and easily extensible open source system for visual DAG workflow task scheduling. Applicable to enterprise-level scenarios, it provides a solution for visualizing operational tasks, workflows, and data processing processes throughout the life cycle.
- Apache DolphinScheduler is designed to resolve complex big data task dependencies and provide applications with data and relationships in various OPS orchestrations. Solve the problem that the data R&D ETL depends on the complexity and cannot monitor the health status of the task. DolphinScheduler assembles tasks in a DAG (Directed Acyclic Graph, DAG) streaming manner, which can monitor the execution status of tasks in a timely manner, and supports operations such as retry, recovery failure of specified nodes, suspension, recovery, and termination of tasks.
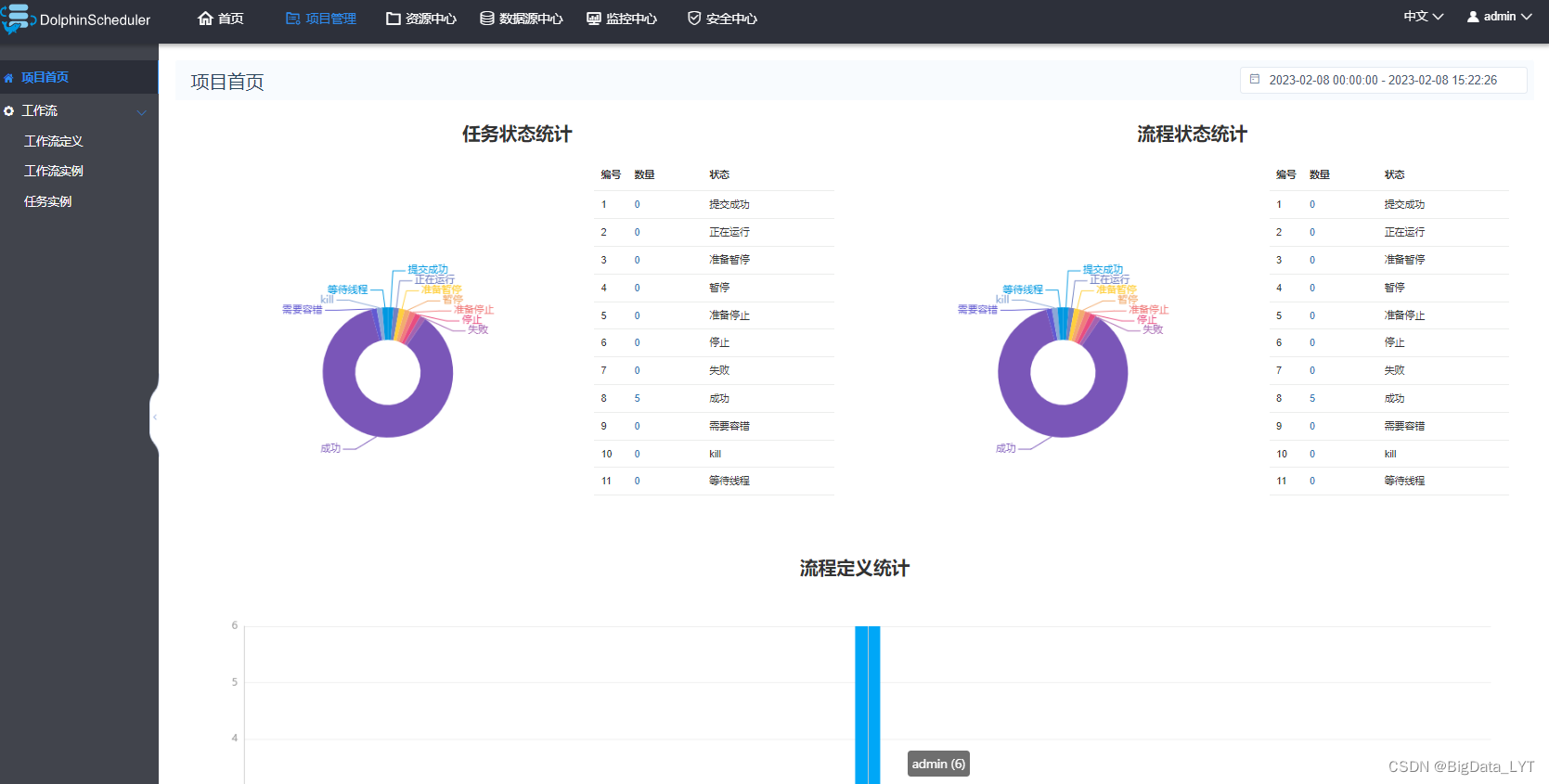
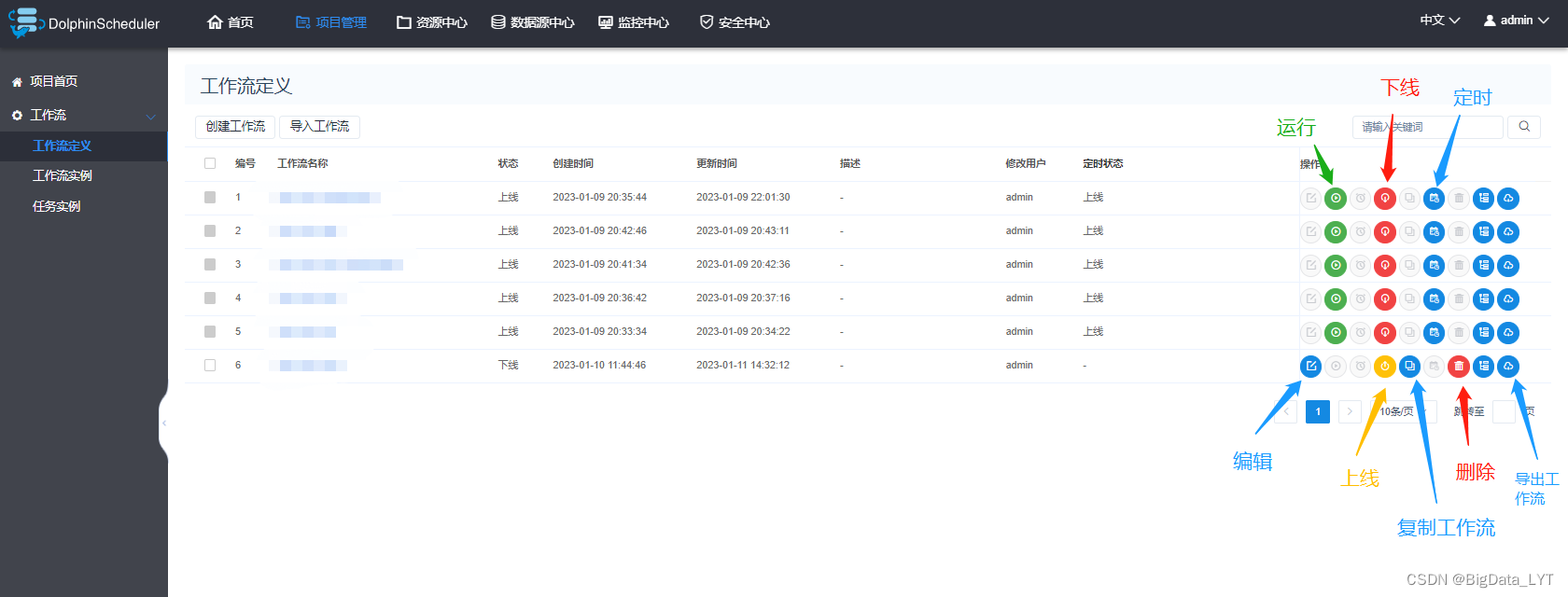
- Dolphin Scheduling is a scheduling tool developed in China. The Chinese version of the page integrates the scheduling of tools such as shell scripts, database SQL, Spark, Flink, MapReduce, Python, HTTP, DataX, and Sqoop in the workflow. It is more friendly to beginners.
2、AzKaban
- AzKaban official website
- Azkaban is a set of simple task scheduling services, including three parts: webserver, dbserver, and executorserver.
Azkaban is a Java project open sourced by Linkedin, a batch workflow task scheduler. Used to run a set of jobs and processes in a specific order within a workflow.
Azkaban defines a KV file format to establish dependencies between tasks and provides an easy-to-use web user interface to maintain and track your workflow. - Azkaban's features:
1), Web user interface
2), easy to upload workflow
3), easy to set the relationship between tasks
4), workflow scheduling
5), authentication/authorization
6), able Kill and restart workflows
7), modular and pluggable plugin mechanism
8), project workspaces
9), logging and auditing of workflows and tasks
3、Then
- Oozie official website
- Features of Oozie
-
- Oozie is a scheduling system that manages hadoop jobs.
-
- Oozie's workflow job is a directed acyclic graph (DAG) of actions.
-
- The Oozie coordination job is to trigger the current Oozie workflow by time (frequency) and valid data.
-
- Oozie supports various hadoop jobs, such as: java, map-reduce, Streaming map-reduce, pig, hive, sqoop, and distcp, etc., and also supports system-specific jobs, such as java programs and shell scripts.
-
- Oozie is a scalable, reliable and extensible system.
-
- The Oozie scheduler is integrated in the CDH big data platform. You can open the Oozie page on the CDH platform and set up the workflow on the Oozie platform. The Oozie scheduler is difficult to learn.
4、Airflow
- Airflow official website
- Airflow is an open source project of Airbnb's Workflow, a task management, scheduling, and monitoring workflow platform written and implemented in Python. Airflow is a task management system based on DAG (Directed Acyclic Graph), which can be simply understood as an advanced version of crontab, but it solves the task dependency problem that crontab cannot solve. Compared with crontab, Airflow can easily check the execution status of tasks (whether the execution is successful, execution time, execution dependencies, etc.), track the historical execution status of tasks, receive email notifications when task execution fails, and view error logs.
5. corntab command
- corntab rookie tutorial
- The service process of crontab is called crond, which means periodic tasks in English. As the name suggests, crontab is mainly used for periodical timing task management in Linux. Usually after the operating system is installed, the crond service is started by default. crontab can be understood as cron_table, which means cron's task list. Tools similar to crontab include at and anacrontab, but the specific usage scenarios are different.
- The purpose of crontab:
- Timing system testing;
- Timing data collection;
- Regular log backup;
- Regularly update the data cache;
- Generate reports at regular intervals;
…
3. Select the data warehouse design scheme
Data warehouses are mainly divided into 3 categories, offline data warehouse, real-time data warehouse and offline real-time integrated data warehouse (lambda architecture)
1. Offline data warehouse
- In the context of big data, there will be a large amount of data and the real-time requirements are not high. An offline data warehouse can be established to extract historical data into the offline data warehouse. After data warehouse design, data development, data mining, and report and Data visualization presentation.
- The offline data warehouse mainly uses HDFS in Hadoop for data storage and YARN for resource scheduling.
- Hive divides data warehouse permissions and designs data warehouse layers.
- Mapreduce, Spark rdd or Hive on Spark as the computing engine.
- SparkML as a tool for data mining.
- Datax, Sqoop, and Kettle are used as data collection tools.
- FineBI and Superset for visualization.
- Zabbix does cluster monitoring.
- Atlas does metadata management.
2. Real-time data warehouse
- With the increase of social requirements for real-time data, the real-time data such as water flow and orders are extracted into the real-time data warehouse. After real-time data warehouse design, Source table, Chanel, Sink table, data development, data mining, and Presentation of reports and data visualizations.
- The real-time data warehouse mainly uses HDFS in Hadoop for data storage and YARN for resource scheduling.
- Hive divides data warehouse permissions and designs data warehouse layers.
- Sparkstreaming or Flink as the computing engine.
- SparkML as a tool for data mining.
- Canal and Flume are used as data collection tools.
- FineBI and Superset for visualization.
- Prometheus does cluster monitoring.
- Atlas does metadata management.
3. Offline real-time integrated data warehouse (lambda architecture)
- The main application of offline real-time integrated data warehouse includes the development of offline data and real-time data; the main related projects include user portrait project, recommendation algorithm and data warehouse development of e-commerce platform, etc. There are almost many data warehouses in the market The development projects are all lambda architectures, and there are few developments of pure offline data warehouses and pure real-time data warehouses. According to the development requirements of business data, select the appropriate data warehouse development plan.
4. Choose a data collection plan
1. Offline collection
- Tools for offline collection include DataX, Kettle and Sqoop and other tools
1)DataX
- DataX official website
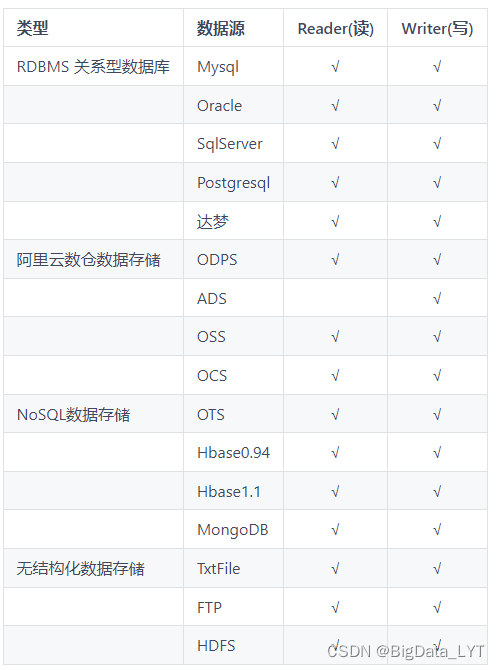
- DataX is an offline synchronization tool for heterogeneous data sources open sourced by Ali. It is dedicated to realizing stable and efficient data between various heterogeneous data sources including relational databases (MySQL, Oracle, etc.), HDFS, Hive, ODPS, HBase, FTP, etc. Synchronization function.
- design concept
- In order to solve the synchronization problem of heterogeneous data sources, DataX has changed the complex mesh synchronization link into a star data link, and DataX is responsible for connecting various data sources as an intermediate transmission carrier. When you need to access a new data source, you only need to connect this data source to DataX to achieve seamless data synchronization with the existing data source.
- framework design
- Reader: Data collection module, responsible for collecting data from data sources and sending the data to FrameWork.
- Writer: The data writing module is responsible for continuously fetching data from FrameWork and writing the data to the destination.
- FrameWork: Used to connect Reader and Writer as a data transmission channel between the two, and handle core issues such as caching, flow control, concurrency, and data conversion.
- Supported Data Sources
2)Scoop
- Sqoop installation and use
- Sqoop is a tool for efficiently transferring large amounts of data between Hadoop and structured data storage (such as relational databases). It includes the following two aspects:
- Sqoop can be used to import data from a relational database management system (such as MySQL) to a Hadoop system (such as HDFS, Hive, HBase)
- Extract data from Hadoop system and export to relational database (such as MySQL)
3)Kettle
- Kettle official website
- Kettle is a pure java development, open source ETL tool for data migration between databases. Can run in Linux, windows, unix. There is a graphical interface, as well as command scripts and secondary development.
2. Real-time collection
- Real-time collection tools include Canal, Flume and other tools
1)Canal
Installation and use of Canal
- Canal is an open source project under Alibaba, developed in pure Java. Based on database incremental log analysis, it provides incremental data subscription & consumption. Currently, it mainly supports MySQL (also supports mariaDB).
2)Flume
- Flume is a distributed log collection system produced by cloudera software company, and was donated to the apache software foundation in 2009 as one of hadoop related components.
- Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large volumes of log data. It has a simple yet flexible architecture based on streaming dataflows. It has a reliable reliability mechanism and many failover and recovery mechanisms, and has strong fault tolerance and fault tolerance. It uses a simple scalable data model that allows online analytics applications.
Writing a Flume custom interceptor
Flume custom interceptor - filter out content beginning with a certain text
3. Offline and real-time collection
1)Flinkx
- Flinkx official website
- FlinkX is a distributed offline/real-time data synchronization plug-in based on Flink, which can realize efficient data synchronization of multiple heterogeneous data sources. It was initially developed by Kangaroo Cloud in 2016. Currently, it has a stable R&D team for continuous maintenance. Open source on Github/Gitee and maintain the open source community. At present, the unification of batch and stream has been completed, and the data synchronization tasks of offline computing and stream computing can be realized based on FlinkX.
- FlinkX abstracts different data source libraries into different Reader plugins, and the target library into different Writer plugins, with the following characteristics:
- Based on Flink development, it supports distributed operation;
- Two-way reading and writing, a database can be used as both the source library and the target library;
- It supports a variety of heterogeneous data sources, and can realize bidirectional collection of more than 20 data sources such as MySQL, Oracle, SQLServer, Hive, and Hbase.
- High scalability, strong flexibility, newly expanded data sources can communicate with existing data sources in real time.
- Data sources supported by Flinkx

5. Choose a data visualization solution
Data visualization tools mainly include Visualization tools such as FineBI, FineRepoart, Superset, Echarts, Sugar, QuickBI and DataV.
1, FineBI
-
FineBI is a business intelligence (Business Intelligence) product launched by Fanruan Software Co., Ltd. It can independently analyze the existing information data of enterprises through end business users, help enterprises discover and solve existing problems, and assist enterprises to adjust strategies in time Make better decisions and enhance the sustainable competitiveness of enterprises.
-
Data processing: data processing services, used to extract, convert, and load raw data. Generate data warehouse FineCube for analysis services.
-
Instant analysis: You can select data to quickly create tables or charts to visualize data, add filter conditions to filter data, and sort in real time to make data analysis faster.
-
Multi-dimensional analysis: OLAP analysis implementation, providing various analysis and mining functions and early warning functions, such as arbitrary dimension switching, adding, multi-layer drilling, sorting, custom grouping, intelligent association, etc.
-
Dashboard: Provide various styles of tables and various chart services to display data in line with various business needs.
-
big data engine
- Use the Spider high-performance computing engine to implement data analysis with a lightweight architecture.
- The Spider engine supports two modes of real-time data and extracted data, which can realize seamless switching.
- The high performance of the Spider engine can realize the second-level presentation of data within a billion level.
- The Spider engine supports flexible data update strategies to improve data preparation efficiency.
-
authority management
-
data modeling
-
data preparation
-
Data visualization intelligent analysis
2、Superset
- Docker install Superset
- Docker installation link: Docker installation
- Docker deploys Superset link: Docker deploys Superset
- Introduction to Superset
- Superset is Airbnb's open source BI data analysis and visualization platform (formerly known as Caravel, Panoramix). The main features of this tool are self-service analysis, custom dashboards, analysis results visualization (export), user/role permission control, and also integrates a SQL editor, which can edit and query SQL, was originally used to support the visual analysis of Druid, and later developed to support many relational databases and big data computing frameworks, such as: mysql, oracle, Postgres, Presto, sqlite, Redshift, Impala , SparkSQL, Greenplum, MSSQL. The whole project is based on the Python framework, which integrates Flask, D3, Pandas, SqlAlchemy, etc.
- Github address: https://github.com/airbnb/superset
- Official website address: http://airbnb.io/projects/superset/
- Other visualization tools are for reference only, and there are not many open source visualization software on the market.