guide
The development of diffusion models has aroused extensive discussions on generative models, and has promoted the progress of theoretical models of speech, audio, image and other modalities. On June 10th, the "Generative Model" Forum of Beijing Zhiyuan Conference invited Stefano Ermon, associate professor of Stanford University, Zhao Zhou, professor of Zhejiang University, Liu Guang, researcher of Zhiyuan Research Institute, Zhou Bolei, assistant professor of UCLA, and Wu Jiajun, assistant professor of Stanford University, The latest progress in the field of co-discourse generative models has launched a unique frontier discussion.
Using fractions instead of likelihoods is the key idea in modeling distributions. -- Stefano Ermon
Audio is more complex than text, and contains not only semantic information, but also attributes such as rhythm, duration, energy, and pitch. -- Zhao Zhou
The way of data hybrid expansion may be the right direction. -- Liu Guang
Combining generative models with machine decision-making can provide some new ideas. -- Zhou Bolei
Harnessing the rich structures, symbols, and programs that exist in nature is about better perception and understanding in the visual world. -- Wu Jiajun
List of Forum Experts
Li Chongxuan | Adjunct Assistant Professor, Renmin University of China
Stefano Ermon | Associate Professor, Stanford University
Zhao Zhou | Professor of Zhejiang University
Liu Guang | Researcher at Zhiyuan Research Institute
Zhou Bolei | Assistant Professor at UCLA
Jiajun Wu | Assistant Professor at Stanford University
Zhu Jun | Professor of Tsinghua University, Chief Scientist of Zhiyuan
Recent advances
in score-based diffusion models
Stefano Ermon | Associate Professor, Stanford University

The basis of image generation technology is to build a model that can understand the structure of natural images. The model needs to understand what kind of pixel sequence is reasonable/unreasonable. Such models can also be used to detect adversarial attacks, or to find out if there is a problem with the input to a machine learning system.
Building a complex generative model is challenging because the probability distribution needs to be built on a very high-dimensional space, and the model needs to be able to assign probabilities to a large number of possible objects.
The score function is the gradient of the logarithmic density function, and through the score function, any neural network can be directly used for modeling. This is a key innovation that allows us to use more powerful neural networks to develop probabilistic models of images.
Rewriting the objective function into an equivalent form actually tries to minimize the norm of the estimated scores at different data points while minimizing the Jacobian locus of the estimated scores at the data points in the training set. When dealing with high-dimensional data, their random projections can be compared rather than vector fields of gradients directly, can be extended to high-dimensional data sets like images, and still retain many advantages of score matching, consistency and asymptotic normality nature.
At the heart of all these good image-text-image generative models is this idea of scoring based on Langevin's kinetics for estimating data distributions. Diffusion models allow to control the generative process in a very natural way and can be applied to different numbers of projections and different types of measurements.

Using scores instead of probabilities is the key idea in modeling distributions, being able to model vector fields of gradients using arbitrary neural networks, and using diffusion models without using adversarial methods or in the case of minima Controlled generation, sampling from these models, not only generates samples, but also evaluates the likelihood under the model within the samples.
Multimodal Generative Speech Model
Zhao Zhou | Professor of Zhejiang University

This report introduces the application of generative models in acoustic models from three perspectives: NATSpeech model for speech generation; DiffSinger model for speech generation singing; Make-An-Audio model for audio generation. Audio generation is also a type of speech generation. Its framework generally consists of three parts: (1) Front end. Extract the pronunciation and prosody from the text through NLP technology; (2) Given a phoneme, synthesize the spectrum; (3) Vocoder, input the spectrogram, and output the voice.
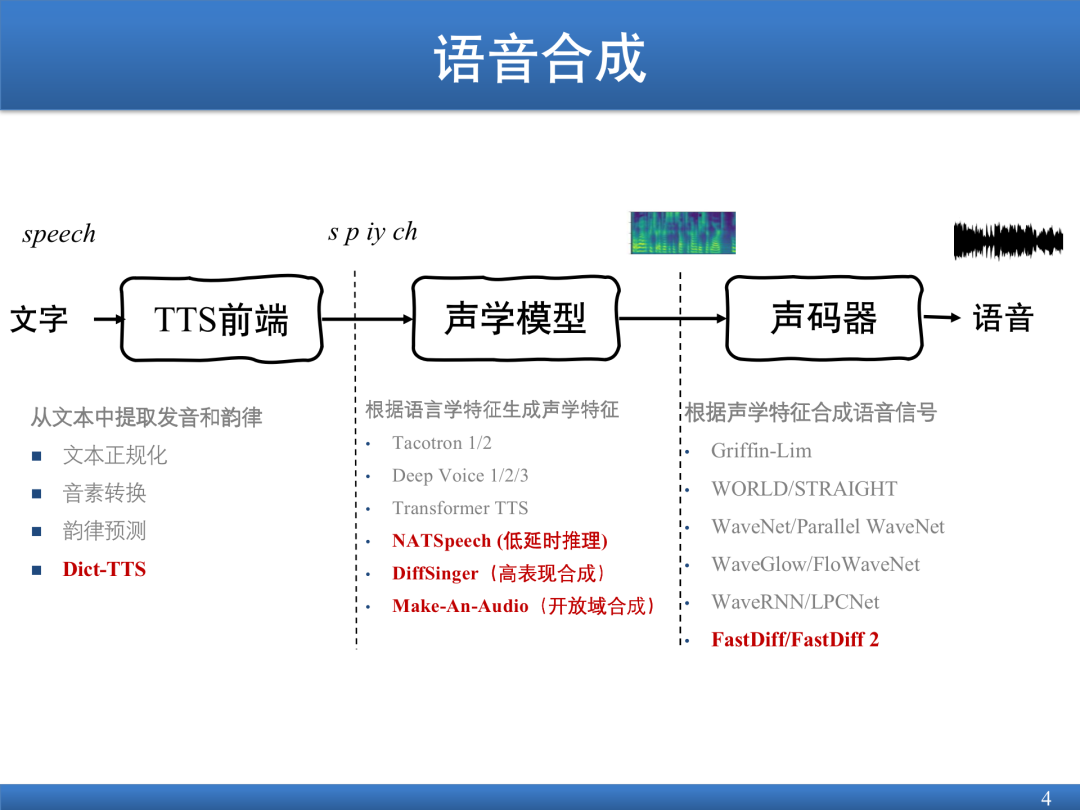
The NATSpeech model has made some improvements based on the Transformer framework. The reasoning speed of the Transformer framework is relatively slow; and there are some missing words. In order to improve the reasoning speed and solve the phenomenon of missing words at the same time, NATSpeech adopts the non-autoregressive prediction form and realizes the learning process of modal conversion.
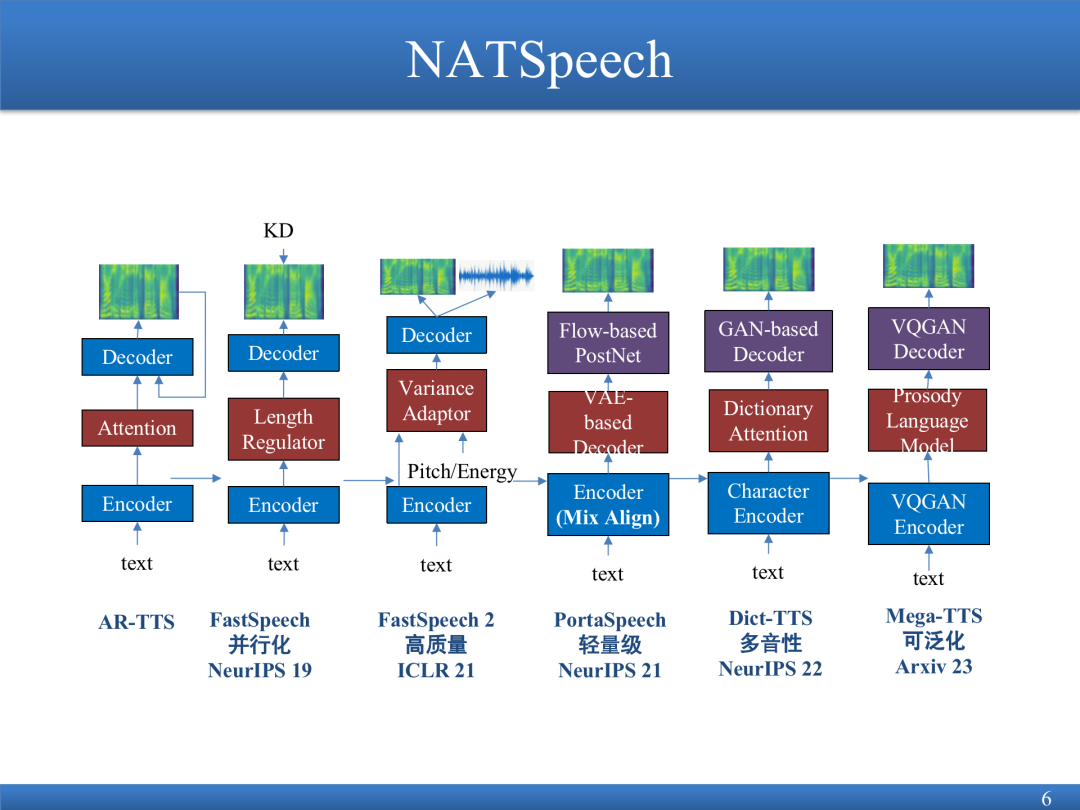
The DiffSinger model can complete some high-expressive synthesis work. Following the idea of PortaSpeech, it uses the spectrum code generated by the previous model to add noise to different spectrums, perform one-time noise addition and accelerated noise reduction, and generate songs.
Make-An-Audio can dub text, pictures, and videos, repair audio, and support general audio synthesis.
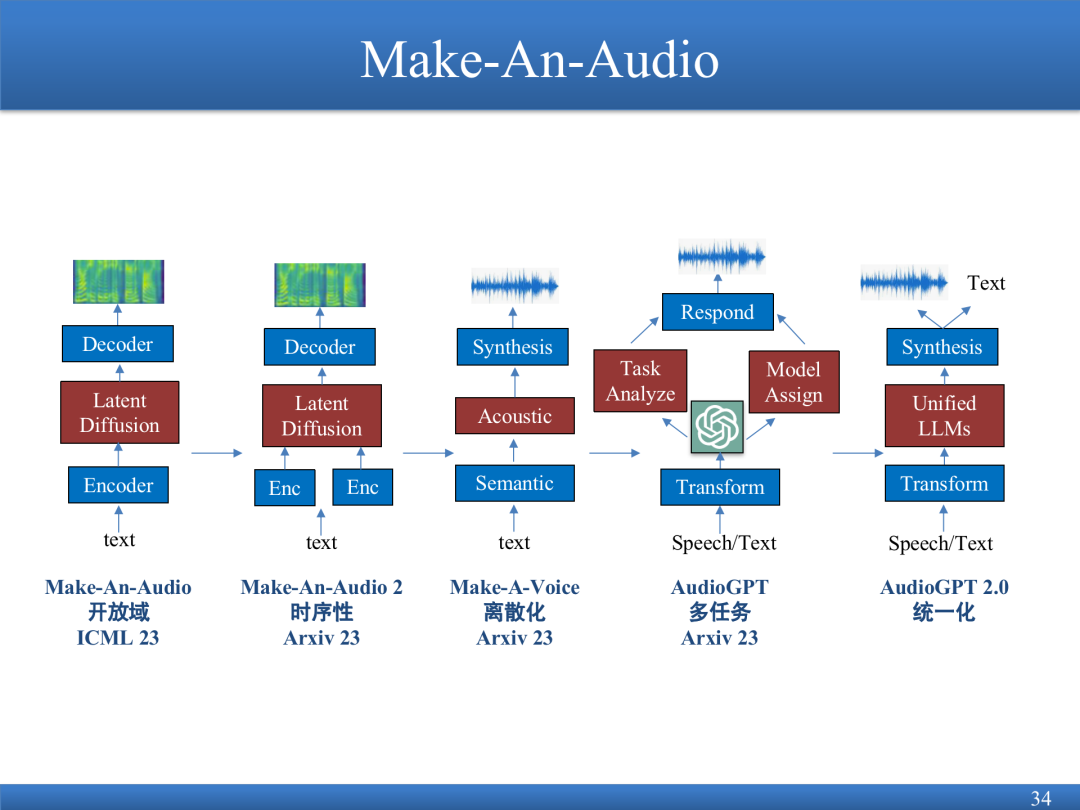
AudioGPT integrates previous work to support different tasks, from audio to text, audio to audio, text to audio, and picture to audio, to obtain the ability to integrate.
"Low-resource" multilingual Vincent graph model
AltDiffusion-M18
Liu Guang | Researcher at Zhiyuan Research Institute

There are three main problems in the existing research in the field of Vincent graphs:
(1) Lack of high-quality data sets. The quality of open source datasets is uneven, the language distribution is extremely uneven, and the channels for obtaining them are limited.
(2) Controlled generation. At the time of generation, the controllability is not high enough to realize complex editing.
(3) Evaluation of Vincent diagram. The consistency between automated evaluation indicators and human subjective evaluation indicators is low, the cost of manual evaluation is relatively high, and there is a lack of unified definition of evaluation standards.
This report focuses on the problem of high-quality data sets.
The data set of Chinese open source graphics and texts is very uneven in multilingual distribution. In order to train the multilingual version of Diffusion, the multilingual version of CLIP is first trained, and the English and Chinese data are distilled respectively. This training mode will reduce English expression ability. Connect this CLIP model to the original Diffusion model and make an extension, which is equivalent to extending the original 2.1 into an 18-language text-image generation model, so that it can support 18 languages.
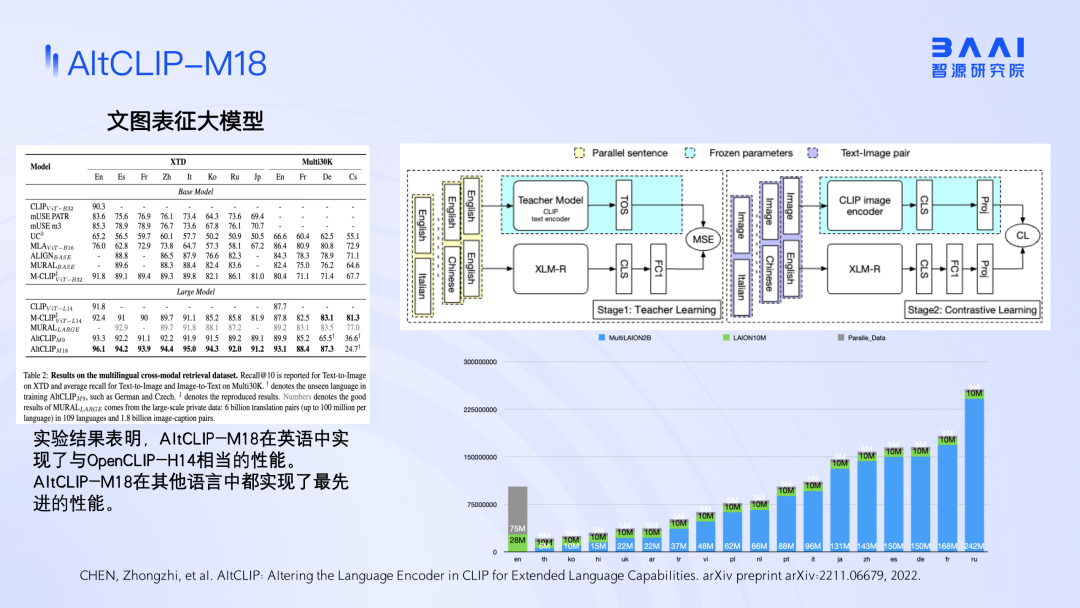
By connecting the Aquila model, the language model released by Zhiyuan and the Diffusion model, text input can be used to generate some pictures. At the same time, a multi-step controllable editing module is also connected to input complex multi-step instructions into the language model. The language model decomposes the instructions, and then makes a controllable image editing model based on the instructions, which can retain all the detailed information to a large extent, and at the same time realize high-precision modification of some areas.

Whether it is the AltDiffusion model or the AltCLIP model, when different languages are mixed together for comparative learning, or when the Diffusion model is trained, the problem of data imbalance will always be encountered. If you only train in one language environment, it will destroy the language alignment ability. If you put the abilities of multiple different parallel languages together for training, this problem may be alleviated.
Controllable based on bird's eye view
and interactive large-scale scene generation
Zhou Bolei | Assistant Professor at UCLA

The focus here is on conditional scene generation, and a more direct representation is the representation of a bird's-eye view. The first part is to use the bird's-eye view for scene generation, and the research hopes to generate this kind of driving picture from the first perspective; the second part is to simulate the scene based on the bird's-eye view, adding some physical representations, so that the whole scene can really move, or Connect with downstream tasks (such as autonomous driving).
The research hopes to generate a first-person picture from a different perspective from an input bird's-eye view. The solution is to model BVE-Gen, learn the bird's-eye view and picture generation separately, and then connect the two parts. The encoding is not text but BEV. After the bird's-eye view is turned into a feature, the picture is decoded.
Research attempts to combine generative models and neural field models. The neural field model can reconstruct the scene, but it does not have the ability to generate, but the neural field model itself contains a lot of 3D information, and the fusion of the two is equivalent to generating a 3D structure diagram with a 2D bird's eye view, and then performing neural processing from the 3D structure diagram. Rendering, to render the scene.
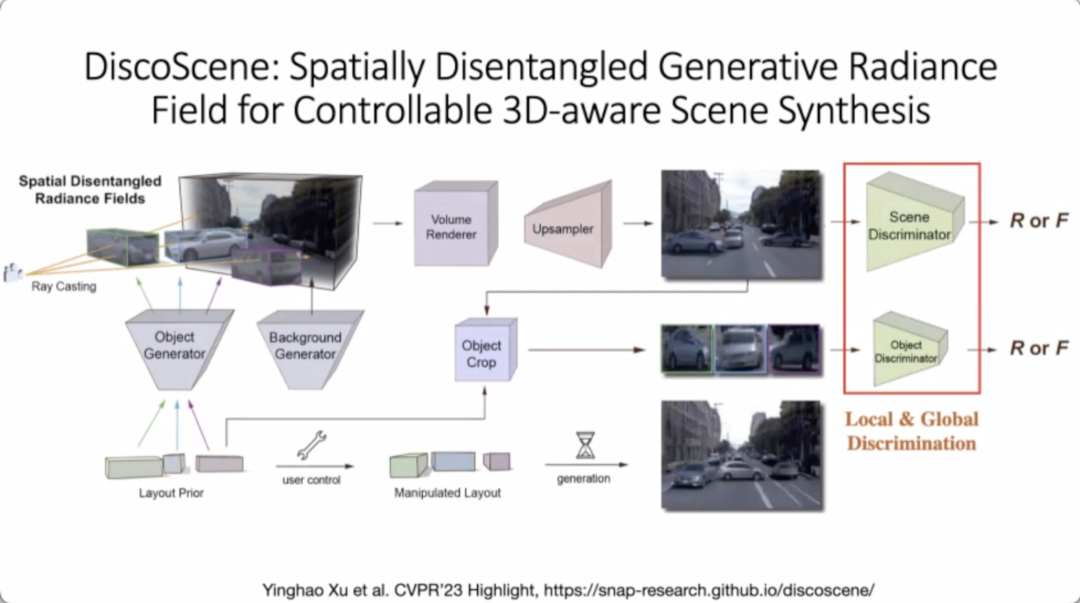
Research proposes a model of DiscoScene. The input of the model is a 3D abstract representation of a bird's-eye view, which symbolizes the corresponding position of the object. It can combine the foreground and background, which is equivalent to combining the GAN model with the neural field model to improve the authenticity of the picture. By changing the structure of the input Layout, edit the generated pictures accordingly, and use the neural network for rendering. Compared with some previous methods, in the field of 3D-aware subdivision, the effect of DiscoScene model in these scenes is currently the best.
MetaDrive's driving simulator can better combine machine decision-making with machine perception, and its efficiency is greatly improved compared with previous simulators. On a single PC, it can achieve a training efficiency of 500 frames, ensuring that its scenes can be obtained from the actual database. Import some new scenes into it. At the same time, the team developed a TrafficGen model. The generation process is divided into two steps: put the car into the bird's-eye view; generate the future trajectory for each car, so as to simulate the scene.
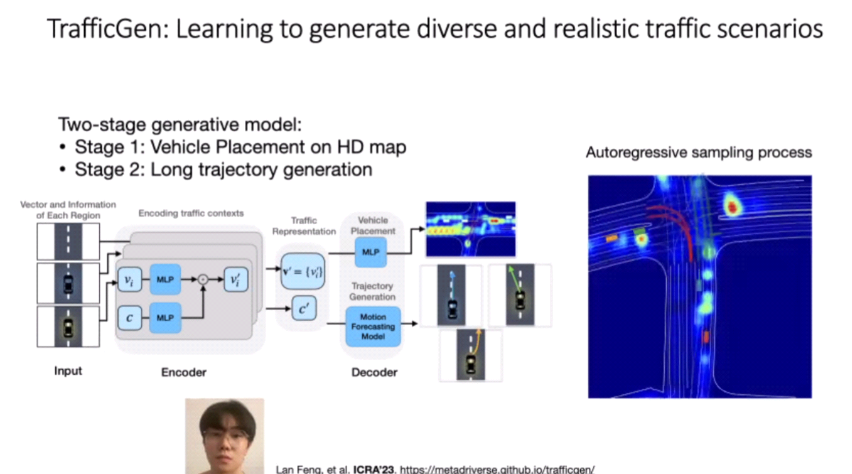
The TrafficGen model has been open-sourced, and the scenes generated by TrafficGen can be imported into other simulators to help the simulator expand the scene.
Understanding the Visual World
Through Naturally Supervised Code
Jiajun Wu | Assistant Professor at Stanford University

This report has a broader explanation of what is encoding and what is natural supervision. Harnessing the rich structures, symbols, and programs that exist in nature is for better perception and understanding in the visual world. Fundamentally speaking, there are only two processes in the formation of encoding rules: the first encoding rules come from humans; the second encoding comes from nature. A class of natural objects has the same intrinsic distribution, including geometry, including texture, including the materials of construction, how to reflect light, and including their physical properties. Even if the intrinsic generative distribution of objects is truly learned, there is still an intrinsic regularity, structure, or encoding of things that nature provides to us. Enforcing this more general constraint or encoding through generative neural networks can help us better understand the visual world.
Procedural papers focusing on relevant visual data, starting from sketches to natural images, to single-image learning, then from one plane to multiple planes, up to the study of 3D directions. Object shapes in 3D, often with abstract and procedural structures. In a sense, using a learning method to simulate the actual forming process enables the inference of a procedural representation of the shape. Similarly, in computer graphics, about how to use the procedural model of computer graphics to process shapes, it is to use neural networks to reason. Because the distribution of shape programs is very limited, using neural networks as program executors allows mostly self-supervised training.
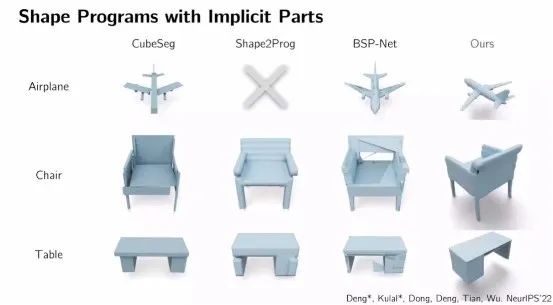
In geometry these shapes have definite laws, for example it is rotationally symmetric. Once you have the shape, tile the object so you can get the normals and texture of the surface. Doing a standard intrinsic image decomposition, you can put it back during a re-render, rebuild the texture, then drop it to the poles and shapes, rebuild the original image.
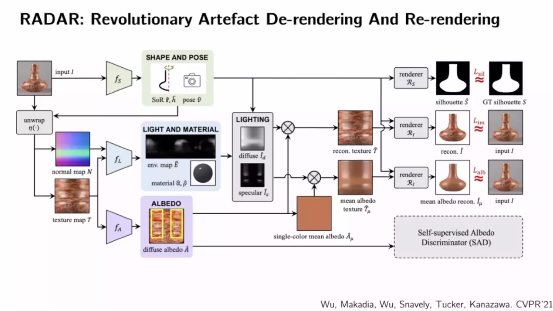
By setting different intrinsic image components, surface normals and reflectivity to obtain 3D effects, objects can be virtualized and observed from different views.

A class of instances or objects in the visual world that naturally share essentially similar intrinsic properties, geometry, and reflectivity. These are the basic natural supervised encodings that would be considered for inclusion, a generality that really applies everywhere. Future considerations could be given to how this can be extended to more complex scenes with complex backgrounds, i.e. complex interactions between lighting, objects and backgrounds, some more procedural and some less so.
As for how to go from passive perception to interaction to interaction with the scene, many of them are inspired by cognition. How to link human cognition to natural language, then, since language and the way of talking about things is another important source of natural supervision, will be another more enlightening research effort.
round table discussion
y


Q1. The development of generative AI may have a lot of abuse problems, leading to social security or some other problems. How to solve these hidden dangers technically?
Zhu Jun: After the development of AIGC, technology may be used for malicious purposes. Around 2019, fake videos synthesized with generative model-GAN technology were spread on the Internet to bring some malicious effects. After that, everyone is thinking about using programs and artificial intelligence to automatically detect such videos, pictures, voices, texts, etc.
In terms of related technologies, after the further development of AIGC, the generation quality is higher. In fact, there are still many differences between computer-generated content and natural, real pictures or videos. For example, some of its feature distribution will be different. There are differences, including some pictures or videos synthesized by changing faces, etc., in terms of naturalness and smoothness, there will be differences in characteristics. Using this information, computer algorithms can be used for more accurate recognition. There are also many progress and related applications.
But this is evolving with each other. Will the AIGC in the future be able to develop to completely surpass it? Now it is acceptable to many people, and it can achieve better results visually, but in the future, it will also be on the algorithm. The detection algorithm has more impact, and I'm sure it will.
But the detection itself, I think the content of the detection has a relatively negative impact, not whether the detection is generated by an algorithm. This may not be so urgent. Relatively speaking, I think it has some purposes like some cases just mentioned. content, which may be further detected from the content itself to be expressed, not just from the visual characteristics of the display.
Wu Jiajun: As Mr. Zhu said at the end, AIGC will definitely become more and more accurate, so that there is no way to distinguish it. In the end, society needs to solve problems systematically, just like dynamite, we have to formulate rules. If this technology becomes more and more convenient, especially now that the model can be transformed, you can convert Token, and then you can imitate human behavior, and you can get the results of this person doing other things in various scenarios, I think it's definitely going to be very real. Maybe the effect of the video is not very good now, but it will get better and better in the future. There are a lot of data on the Internet for the video, at least from the perspective of the appearance, it seems to be a real angle, and the effect is very real. In the end, this problem is not a purely technical problem, but a problem that requires comprehensive social consideration.
Zhao Zhou: The current generative model may have some generated unnatural places, which can be used for detection. As the model gets bigger and more realistic, it's hard to tell the difference afterwards. One of my views is that there is no need to deny the generation technology itself, and take measures mainly against the possible occurrence of malicious content.
If the model becomes more and more realistic and detailed, I personally think that there may be another way to distinguish it, which is to add a digital watermark to the model when the model is generated. While loading the digital watermark, mark which model or institution the generated content was generated through, so that the source of the content can be quickly found.
Q2. From the perspective of algorithm or basic model development, after Diffusion, do you think we will have the next major breakthrough?
Zhu Jun: There will definitely be a big breakthrough in the next step, just like before the Diffusion model came out, everyone said that GAN was very good, but suddenly one day after Diffusion came out, many people turned to embrace the Diffusion model. Now in fact, the Diffusion model does not mean that it has no limitations in essence, and there are many open problems.
Q3. Professor Wu Jiajun's report starts from knowledge, or some laws of nature. It has good restraint, control ability, and good generalization. But recently there is also a new method, which is similar to a large-scale pre-training model. The two methods have their own advantages and disadvantages. How do you view their future development prospects?
Wu Jiajun: I don't think there is any difference in principle between them. I think they have the same goal, but they have different starting points. They are largely equally abstract concepts. Perhaps abstract concepts actually appear in a very subtle way, not that they are contradictory, but in fact may be just a range.
Q4. How will the multimodal model develop in the future? How many modals do we need to do? Or how to improve each other between different modalities and so on.
Zhao Zhou: We now solve the two problems of understanding and generation separately. In the era of large models, we hope to put understanding and generation together in a unified model. For example, we input Talking-face, output voice and other different modalities.
Q5. If there is another breakthrough in the generation model in the next step, or what is the most exciting point of future development?
Zhao Zhou: The combination of generative models and large language models can achieve very good intelligent interaction between humans and machines. There will be many new scenarios that can be conceived, such as the mapping of physical space to virtual space intelligent interaction, which is very interesting.
Wu Jiajun: I have two expectations, one is short-term, the direction of video that can continue to be researched; the other is how to better do 3D direction, what kind of data should I choose, whether to process existing data or real-time data. Starting with ProlificDreamer, being able to do better, to be more generalizable, to be more adaptable, I find it very exciting.
Second, I think this is a basic research question. Regarding the future direction, after AI has completed the task well, how can we control the development direction of AI so that it can have continuous productivity. Whether it is audio, song, video, or text to be generated by the model, AI needs to control the best measurement standards to achieve better interconnection and interaction between humans and devices. There is still a lot of work to be done, and of course it also involves many social issues.
Zhu Jun: Robots and entities are combined. In the future, what we see is not only a model, an algorithm, but also a physical object that can interact and evolve with the environment, people, and various aspects.
- Click "View Original Text" to watch the video replay of the complete conference -
playback -

Frontier Progress in Embodied Intelligence and Reinforcement Learning丨Wonderful Review of 2023 Zhiyuan Conference

Large Models and the Future of Humanity丨Wonderful Review of Large Models Forum Based on Cognitive Neuroscience