Table of contents
After studying the previous notes, I basically know the basic code framework of federated learning. There are also two implementation methods for federated learning, one is C/S architecture, server integration model, and the other is P2P architecture, which does not require a third party. Now implement the horizontal federated learning model under the C/S architecture.
The general processing process is as follows:
1. Data preprocessing, get data_loader
2. Create a virtual machine, allocate data sets
3. Initialize the model
4. Send the model to the virtual machine
5. Guide the virtual machine training
6. Recycle the model
Familiar with the basic processing flow In the future, I plan to write a federated learning model for handwritten digit recognition using the MINIST dataset.
Handwritten digit recognition model (non-parallel training)
Overview

The server first sends the model to Alice. After Alice uses local data for training, she then sends the model to Server. After Server receives the model, it sends the model to Bob. Bob uses local data for training. After the training is completed, it is handed over to Server. Server The model is evaluated on local test data, and the model is then distributed to Alice and Bob.
But the disadvantage of such training is very obvious: Bob can reason about the parameters of the accepted model, and may be able to obtain some features of Alice's local data, thus destroying the privacy of the data. Non-parallel training takes a long time, and Bob’s data is post-training, which may account for a large part of the total model, and cannot make good use of the data of both parties.
At present, I still encounter some confusion when writing the training code, which is written at the end of this article. Welcome everyone to leave a message, thank you very much.
import base package
import torch
#用于构建NN
import torch.nn as nn
#需要用到这个库里面的激活函数
import torch.nn.functional as F
#用于构建优化器
import torch.optim as optim
#用于初始化数据
from torchvision import datasets, transforms
#用于分布式训练
import syft as sy
hook = sy.TorchHook(torch)
create client
Bob = sy.VirtualWorker(hook,id='Bob')
Alice = sy.VirtualWorker(hook,id='Alice')
Set training parameters
class Arguments():
def __init__(self):
self.batch_size = 1
self.test_batch_size = 100
self.epochs = 3
self.lr = 0.01
self.momentum = 0.5
self.no_cuda = False
self.seed = 1
self.log_interval = 30
self.save_model = False
#实例化参数类
args = Arguments()
#判断是否使用GPu
use_cuda = not args.no_cuda and torch.cuda.is_available()
#固定化随机数种子,使得每次训练的随机数都是固定的
torch.manual_seed(args.seed)
device = torch.device('cuda' if use_cuda else 'cpu')
Initialize the dataset
#定义联邦训练数据集,定义转换器为 x=(x-mean)/标准差
fed_dataset = datasets.MNIST('data',download=True,train=True,
transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))]))
#定义数据加载器,shuffle是采用随机的方式抽取数据,顺便也把数据集定义在了客户端上
fed_loader = sy.FederatedDataLoader(federated_dataset=fed_dataset.federate((Alice,Bob)),batch_size=args.batch_size,shuffle=True)
#定义测试集
test_dataset = datasets.MNIST('data',download=True,train=False,
transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))]))
#定义测试集加载器
test_loader = torch.utils.data.DataLoader(test_dataset,batch_size=args.test_batch_size,shuffle=True)
Build a neural network model
#构建神经网络模型
class Net(nn.Module):
def __init__(self) -> None:
super(Net,self).__init__()
#输入维度为1,输出维度为20,卷积核大小为:5*5,步幅为1
self.conv1 = nn.Conv2d(1,20,5,1)
self.conv2 = nn.Conv2d(20,50,5,1)
self.fc1 = nn.Linear(4*4*50,500)
#最后映射到10维上
self.fc2 = nn.Linear(500,10)
def forward(self,x):
#print(x.shape)
x = F.relu(self.conv1(x))#28*28*1 -> 24*24*20
#print(x.shape)
#卷机核:2*2 步幅:2
x = F.max_pool2d(x,2,2)#24*24*20 -> 12*12*20
#print(x.shape)
x = F.relu(self.conv2(x))#12*12*20 -> 8*8*30
#print(x.shape)
x = F.max_pool2d(x,2,2)#8*8*30 -> 4*4*50
#print(x.shape)
x = x.view(-1,4*4*50)
x = F.relu(self.fc1(x))
x = self.fc2(x)
#使用logistic函数作为softmax进行激活吗就
return F.log_softmax(x, dim = 1)
Define training and testing functions
def train(model:Net,fed_loader:sy.FederatedDataLoader,opt:optim.SGD,epoch):
model.train()
for batch_idx,(data,target) in enumerate(fed_loader):
#传递模型
model.send(data.location)
opt.zero_grad()
pred = model(data)
loss = F.nll_loss(pred,target)
loss.backward()
opt.step()
model.get()
if batch_idx % args.log_interval==0:
#获得loss
loss = loss.get()
print('Train Epoch : {} [ {} / {} ({:.0f}%)] \tLoss: {:.6f}'.format(
epoch, batch_idx * args.batch_size, len(fed_loader) *
args.batch_size,
100.* batch_idx / len(fed_loader), loss.item()))
#定义测试函数
def test(model, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
output=model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.argmax(1, keepdim=True)
correct+= pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set : Average loss : {:.4f}, Accuracy: {}/{} ( {:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100.* correct / len(test_loader.dataset)))
Define the main function
if __name__ == '__main__':
model = Net().to(device)
optimizer = optim.SGD(model.parameters(), lr = args.lr)
for epoch in range(1, args.epochs +1):
train(model, fed_loader, optimizer, epoch)
test(model, test_loader)
training effect
 I feel that the error is quite small, but the training time is too long.
I feel that the error is quite small, but the training time is too long.
Handwritten digit recognition model (parallel training)
Overview
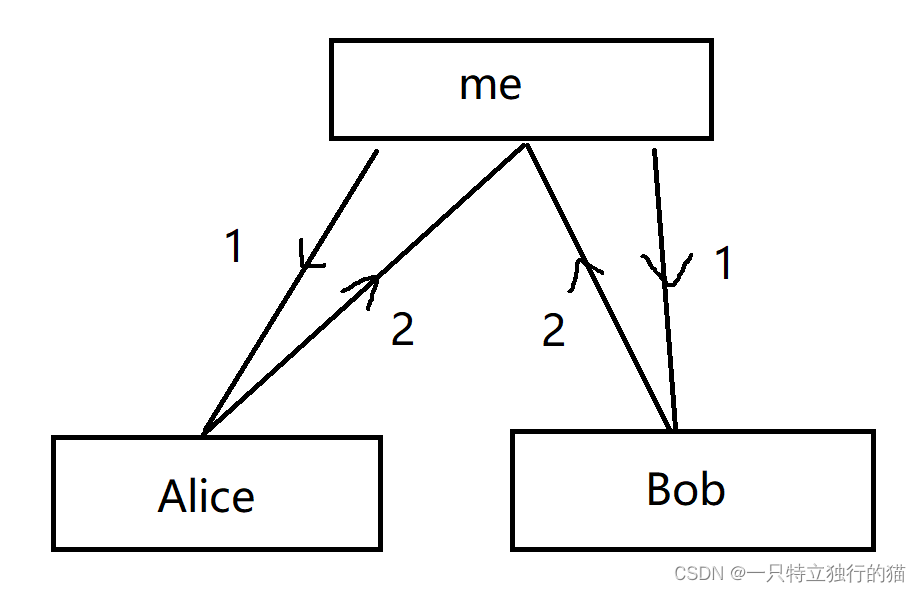
import the necessary packages
from imaplib import Time2Internaldate
import torch
import time
#用于构建NN
import torch.nn as nn
#需要用到这个库里面的激活函数
import torch.nn.functional as F
#用于构建优化器
import torch.optim as optim
#用于初始化数据
from torchvision import datasets, transforms
#用于分布式训练
import syft as sy
hook = sy.TorchHook(torch)
build client
Bob = sy.VirtualWorker(hook,id='Bob')
Alice = sy.VirtualWorker(hook,id='Alice')
Initialize training parameters
class Arguments():
def __init__(self):
self.batch_size = 1
self.test_batch_size = 100
self.epochs = 1
self.lr = 0.01
self.momentum = 0.5
self.seed = 1
self.log_interval = 1
self.save_model = True
#实例化参数类
args = Arguments()
#固定化随机数种子,使得每次训练的随机数都是固定的
torch.manual_seed(args.seed)
Define training set and test set
#定义联邦训练数据集,定义转换器为 x=(x-mean)/标准差
fed_dataset_Bob = datasets.MNIST('data',download=False,train=True,
transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))]))
#定义数据加载器,shuffle是采用随机的方式抽取数据
fed_loader_Bob = torch.utils.data.DataLoader(fed_dataset_Bob,batch_size=args.batch_size,shuffle=True)
#定义联邦训练数据集,定义转换器为 x=(x-mean)/标准差
fed_dataset_Alice = datasets.MNIST('data',download=False,train=True,
transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))]))
#定义数据加载器,shuffle是采用随机的方式抽取数据
fed_loader_Alice = torch.utils.data.DataLoader(fed_dataset_Alice,batch_size=args.batch_size,shuffle=True)
#定义测试集
test_dataset = datasets.MNIST('data',download=True,train=False,
transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))]))
#定义测试集加载器
test_loader = torch.utils.data.DataLoader(test_dataset,batch_size=args.test_batch_size,shuffle=True)
Define a neural network
#构建神经网络模型
class Net(nn.Module):
def __init__(self) -> None:
super(Net,self).__init__()
#输入维度为1,输出维度为20,卷积核大小为:5*5,步幅为1
self.conv1 = nn.Conv2d(1,20,5,1)
self.conv2 = nn.Conv2d(20,50,3,1)
self.fc1 = nn.Linear(800,500)
#最后映射到10维上
self.fc2 = nn.Linear(500,10)
def forward(self,x):
#print(x.shape)
x = F.relu(self.conv1(x))#28*28*1 -> 12*12*20
#卷机核:2*2 步幅:2
x = F.max_pool2d(x,2,2)
#print(x.shape)
x = F.relu(self.conv2(x))
#print(x.shape)
x = F.max_pool2d(x,2,2)
#print(x.shape)
x = x.view(-1,4*4*50)
x = F.relu(self.fc1(x))
x = self.fc2(x)
#使用logistic函数作为softmax进行激活吗就
return F.log_softmax(x, dim = 1)
Consolidate models using the Fed_avg algorithm
def fedavg_updata_weight(model:Net, Alice_model:Net, Bob_model:Net, num:int):
"""
训练中需要修改的参数如下,对以下参数进行avg
conv1.weight
conv1.bias
conv2.weight
conv2.bias
fc1.weight
fc1.bias
fc2.weight
fc2.bias
"""
model.conv1.weight.set_((Bob_model.conv1.weight.data+Alice_model.conv1.weight.data)/num)
model.conv1.bias.set_((Bob_model.conv1.bias.data+Alice_model.conv1.bias.data)/num)
model.conv2.weight.set_((Bob_model.conv2.weight.data+Alice_model.conv2.weight.data)/num)
model.conv2.bias.set_((Bob_model.conv2.bias.data+Alice_model.conv2.bias.data)/num)
model.fc1.weight.set_((Bob_model.fc1.weight.data+Alice_model.fc1.weight.data)/num)
model.fc1.bias.set_((Bob_model.fc1.bias.data+Alice_model.fc1.bias.data)/num)
model.fc2.weight.set_((Bob_model.fc2.weight.data+Alice_model.fc2.weight.data)/num)
model.fc2.bias.set_((Bob_model.fc2.bias.data+Alice_model.fc2.bias.data)/num)
define training
def train(model:Net,fed_loader:torch.utils.data.DataLoader):
Bob_model = Net()
Alice_model = Net()
#定义Bob的优化器
Bob_opt = optim.SGD(Bob_model.parameters(), lr = args.lr)
#定义Alice的优化器
Alice_opt = optim.SGD(Alice_model.parameters(), lr = args.lr)
model.train()
Bob_model.train()
Alice_model.train()
Bob_model.send(Bob)
Alice_model.send(Alice)
for epoch in range(1, args.epochs +1):
#传递模型
Alice_loss = 0
Bob_loss = 0
#模拟Bob训练数据
for epoch_ind, (data, target) in enumerate(fed_loader):
data = data.send(Bob)
target = target.send(Bob)
Bob_opt.zero_grad()
pred = Bob_model(data)
Bob_loss = F.nll_loss(pred,target)
Bob_loss.backward()
Bob_opt.step()
if(epoch_ind%50==0):
print("There is epoch:{} epoch_ind:{} in Bob loss:{:.6f}".format(epoch,epoch_ind,Bob_loss.get().data.item()))
#模拟Alice训练模型
for epoch_ind, (data, target) in enumerate(fed_loader):
data = data.send(Alice)
target = target.send(Alice)
Alice_opt.zero_grad()
pred = Alice_model(data)
Alice_loss = F.nll_loss(pred,target)
Alice_loss.backward()
Alice_opt.step()
if(epoch_ind%50==0):
print("There is epoch:{} epoch_ind:{} in Alice loss:{:.6f}".format(epoch,epoch_ind,Alice_loss.get().data.item()))
with torch.no_grad():
Bob_model.get()
Alice_model.get()
#更新权重
fedavg_updata_weight(model,Alice_model,Bob_model,2)
if epoch % args.log_interval==0:
#获得loss
#模型的loss
# pred = model(fed_loader)
# Loss = F.nll_loss(pred,target)
print("Bob in train:")
test(Bob_model,test_loader)
print("Alice in train:")
test(Alice_model,test_loader)
print("model in train:")
test(model,test_loader)
define test
#定义测试函数
def test(model, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
output=model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.argmax(1, keepdim=True)
correct+= pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set : Average loss : {:.4f}, Accuracy: {}/{} ( {:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100.* correct / len(test_loader.dataset)))
start entry
if __name__ == '__main__':
model = Net()
start=time.clock()
train(model, fed_loader_Bob)
mid=time.clock()
print("model in test:")
test(model, test_loader)
end=time.clock()
time1 = mid - start
time2 = end - mid
print("训练时间:{}h{}m{}s 测试时间为:{}h{}m{}s".format(time1//60//60,time1//60,time1%60,time2//60//60,time2//60,time2%60))
if(args.save_model):
torch.save(model.state_dict(),"Net.weight")
training effect
epoch:10000

epoch:60000
 epoch:500
epoch:500
 epoch:3000
epoch:3000

At present, it is not clear why the fed_avg algorithm is used to integrate the model. On the basis of the very good training effect of the local model, the effect of the integrated model is actually worse. On the contrary, when the training effect of the local model is not so good, the effect of the integrated model is not bad. Welcome to leave a message in the comment area, thank you very much.