This column is the study notes of the artificial intelligence course "Neural Network and Deep Learning" of NetEase Cloud Classroom. The video is jointly produced by NetEase Cloud Classroom and deeplearning.ai. The speaker is Professor Andrew Ng. Interested netizens can watch the video of NetEase Cloud Classroom for in-depth study. The link of the video is as follows:
Neural Networks and Deep Learning - NetEase Cloud Classroom
Netizens who are interested in neural networks and deep learning are also welcome to communicate together~
When training a neural network, we need to make many decisions, such as how many layers the neural network has, how many hidden units each layer contains, what the learning rate is, and which activation functions to use for each layer.

When building a new deep learning application, it is impossible to accurately predict this information, as well as other hyperparameters, from the beginning.
In fact, applying deep learning is an empirical, highly iterative process. People usually start with an initial idea, then write code, and try to run the code, get the running results of the neural network through running and testing, and then adjust the strategy according to the running results, and continuously improve the neural network through multiple cycles. Create high-quality training sets, validation sets, and test sets to help improve iteration efficiency.

For the data set, people usually divide the data into several parts, one part as the training set (Training set), one part as the verification set (Development set), and the last part as the test set (Test set).
The training set is used to execute the training algorithm, and the validation set is used to test the algorithm and select the best model. Once the final model has been selected after sufficient validation, it is ready to be evaluated on the test set. The main purpose of the test set is to evaluate the performance of the model.
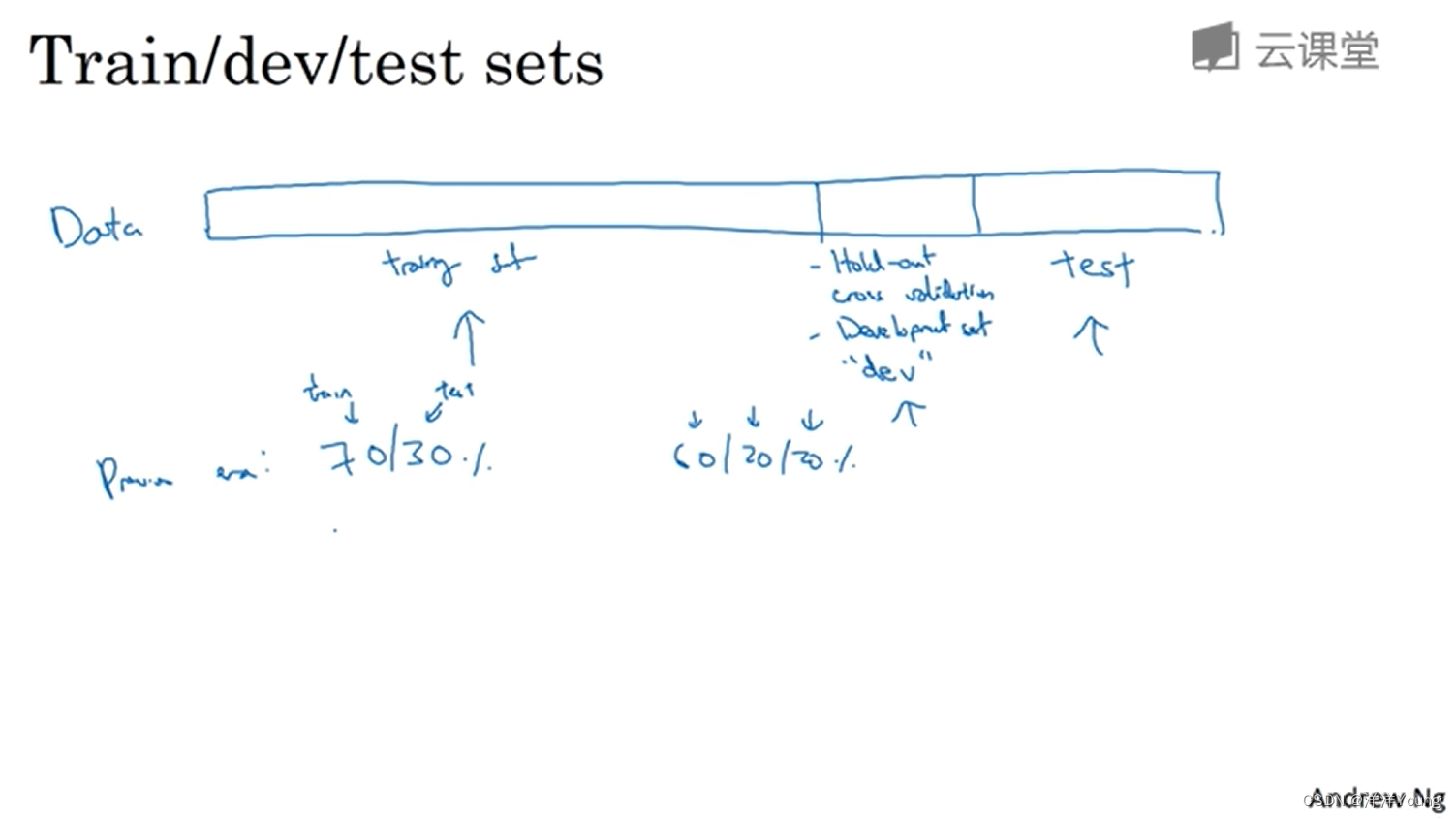
In the era of "small data", the common practice of data set division is to divide all the data into seven or three, that is, the data of training set and test set account for 70% and 30% respectively (no verification set); or training/validation/test set data Accounted for 60%, 20%, 20% respectively.
When the amount of data is less than 10000, the above division method is reasonable. But in the era of "big data", the amount of data may be in the millions, so the proportion of the verification set and the test set to the total data will tend to become smaller.
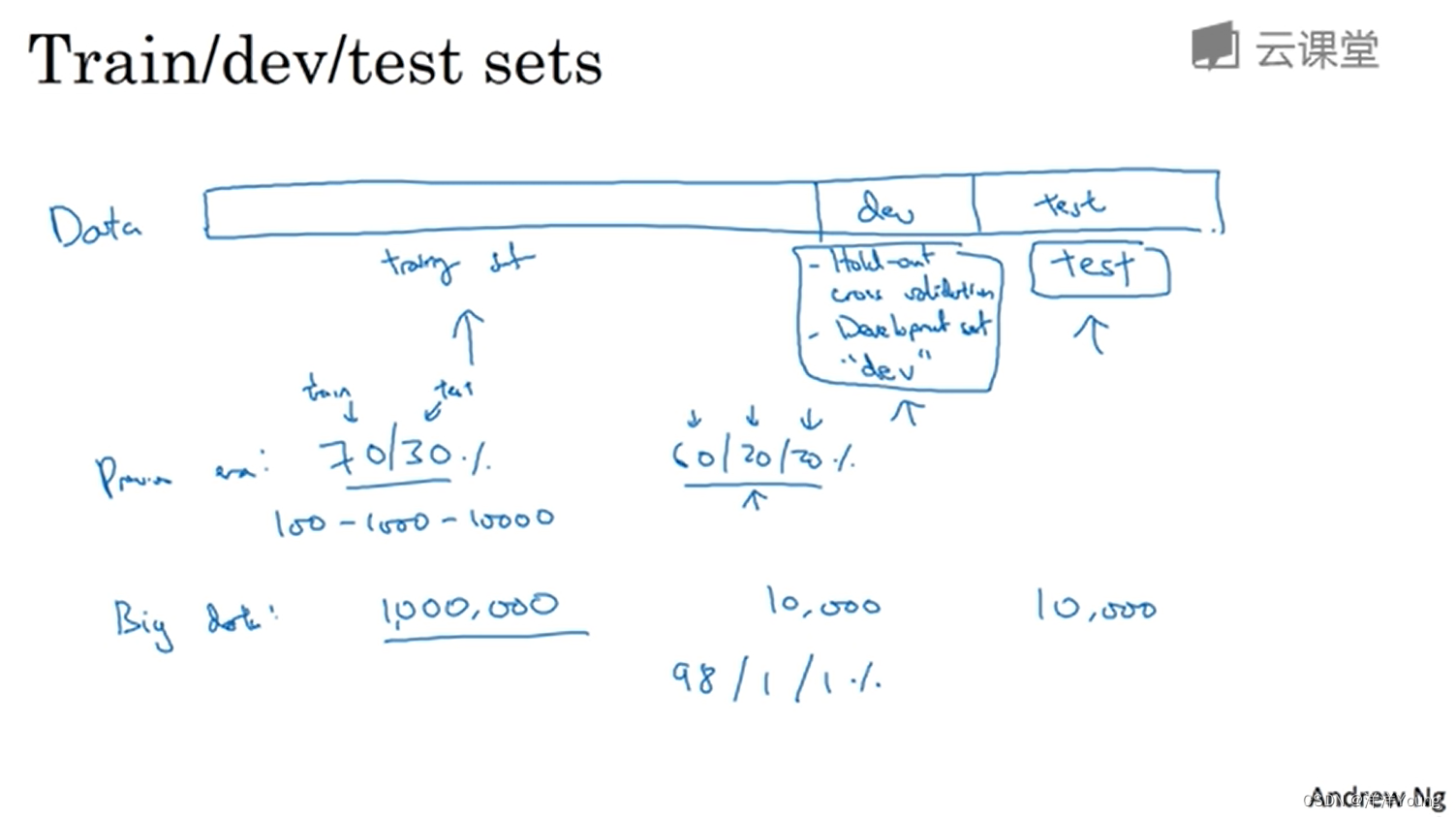
For example, in 1 million data, 10,000 verification sets and 10,000 test sets are required, so there are 980,000 training sets and 980,000 training sets, and training/validation/test set data account for 98%, 1%, and 1% respectively.

Finally, make sure that the validation and test sets come from the same distribution. Sometimes it is possible to have no test set. At this time, a part of the verification set is used as a test set, so it is also called a verification test set.