After installing yolov5 and testing successfully, you can try to train the data set. It can be completely your own data set, which can be standardized through labeling tools (such as labelme), or it can be a public data set. Here, the public data set is temporarily used (later, we will take a step to train our own data set).
1. Download the dataset
A public fruit data set is used here, and other data sets can also be used, and the data set can be placed in the data folder under the yolov5 directory.
Link: https://pan.baidu.com/s/1TMp5ZiPhFoHFDf2lVqgm0w?pwd=yolo
Extraction code: yolo
The data set has a total of 200 fruit images in four categories: banana, red snake fruit, dragon fruit, and pineapple.
2. Prepare the yolo annotation file
2.1 Split Dataset
The above dataset has only two folders, as shown in the figure below

in:
(1) Annotations: label file, xml format
(2) Images: image files, the dataset is in png format (other image formats are also possible)
The general data set is divided into test set, verification set and training set, so this data set needs to be divided, use the following python script to split the data set, you can write the script yourself to split a certain proportion, or refer to the code on the Internet , here directly use the online python script split_train_val.py, as shown below.
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
# xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='Annotations', type=str, help='input xml label path')
# 数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='dataset', type=str, help='output txt label path')
opt = parser.parse_args()
# trainval_percent = 1.0
# train_percent = 0.9
trainval_percent = 0.8 # 训练集和验证集所占比例。
train_percent = 0.8 # 训练集所占比例,可自己进行调整
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()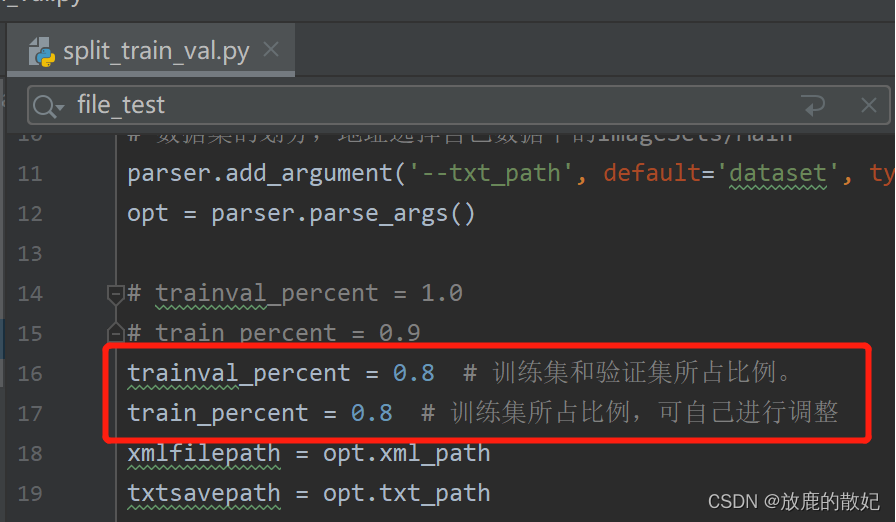
According to the parameters in the code (the red box in the above figure), it can be seen that the training verification set accounts for 80% (the training set accounts for 80% of the training verification set, and the verification set is 20%), and the test set accounts for 20%. After splitting, the result is shown in the figure below.

Open each txt separately, and you can get the data volume as follows, which conforms to the ratio setting when splitting
Test: 40
Train: 128
trainVal: 160
Val: 32
2.2 Prepare yolo calibration file
2.1 Just split the file names of all datasets (excluding paths and image formats), run the following script (voc_label.py) file, and form the following content according to the results of the previous step
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
'''
准备labels,把数据集格式转换成yolo_txt格式,即将每个xml标注提取bbox信息为txt格式,
每个图像对应一个txt文件,文件每一行为一个目标的信息,包括class, x_center, y_center, width, height格式
'''
sets = ['train', 'val', 'test']
classes = ["banana", "snake fruit", "dragon fruit", "pineapple"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
# difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
#wd = getcwd()
for image_set in sets:
if not os.path.exists('labels/'):
os.makedirs('labels/')
image_ids = open('dataset/%s.txt' % (image_set)).read().strip().split()
list_file = open('./%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/images/%s.png\n' % (image_id))
convert_annotation(image_id)
list_file.close() 
in
* test.txt: full path (absolute path) of images for all test sets
* train.txt: The full path (absolute path) of images for all training sets
* val.txt: full path (absolute path) of images for all validation sets
(4) labels: label files of all images, the format is written in the format of yolo, as shown in the following figure fruit0.txt, each row is a fruit, each row has 5 data, the first is the category, the second -5 is position information, which are x, y, w, h respectively.

Notice:
(1) If other data sets are used, corresponding category modifications must be made, as shown in the figure below

(2) Pay attention to the path of each file, which needs to be modified to your own path.

3. Prepare the configuration file
3.1 Write a dataset configuration file
Write the fruit.yaml file under the data folder, as shown in the figure below:

Note that the number and name of the categories need to correspond to voc_label.py, and you need to pay attention to the file path (since fruit.yaml is in the data directory, the train and val paths did not add data at the beginning, but it will report an error and cannot find the train when training later. and val path, so be sure to add data).
3.2 Modify the model configuration file
Yolov5 has four different model versions: s, m, l, and x. Here, select the s version, and modify the categories in yolov5s.yaml accordingly, and the others remain unchanged for the time being.

4. Training
Use the following command to train
python train.py --img 640 --epochs 100 --data data/fruit.yaml --cfg models/yolov5s.yaml
The training is complete, as shown in the figure below


5. Problem solving

Find the cmd.py path according to the error content and open it, add the following content, as shown in the figure.
os.environ['GIT_PYTHON_REFRESH'] = 'quiet'
