Article Directory
Preface
- In Data Parallel parallel operation, there is only one card in the operation when there are multiple cards in a single process due to various reasons
- When using the Distributed Data Parallel, attention must use the same random seed in each process, so that all the model weights are initialized to the same value.
1. Motivation
- The easiest way to accelerate neural network training is to use GPU. If one GPU is not enough, add a few more.
- In fact, large language models such as BERT and GPT-2 are even trained on hundreds of GPUs.
- In order to achieve multi-GPU training, we must find a way to distribute data and models on multiple GPUs and coordinate the training process.
二、Why Distributed Data Parallel?
- Pytorch takes into account the ease of use and controllability of the main neural network structure. And it provides two ways to split the multi-GPU data and model: that
nn.DataParallelwellnn.DistributedDataParallel.- nn.DataParallel is easier to use (usually just encapsulate the model and run the training code). But in each training batch (batch), because the weight of the model is calculated in a process and then distributed to each GPU, so the network communication becomes a bottleneck, and the GPU utilization rate is also Usually very low.
- In addition, nn.DataParallel requires all GPUs to be on one node (one machine) and does not support Apex's mixed precision training.
3. The big picture
- Using nn.DistributedDataParallel for Multiprocessing can copy the model between multiple GPUs, each of which is controlled by a process. (If you want, you can control multiple GPUs with one process, but this will be much slower than controlling one. There may also be multiple worker processes fetching data for each GPU, but for simplicity, this article will omit this.) These GPUs can be located on the same node or distributed on multiple nodes. Each process performs the same task, and each process communicates with all other processes.
- Only the gradient will propagate between processes/GPUs, so that network communication will not become a bottleneck.
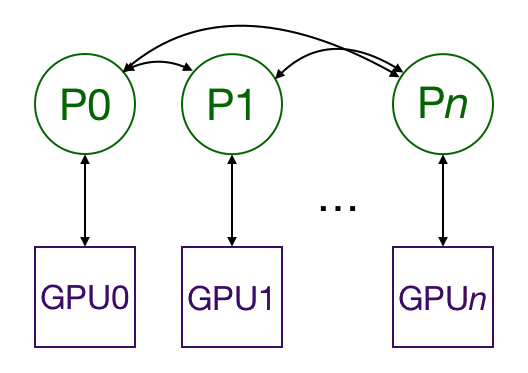
- During the training process, each process loads its own minibatch data from the disk and passes them to its GPU. Each GPU does its own forward calculation, and then the gradients are all reduced between GPUs. The gradient of each layer is not only dependent on the previous layer, so the full reduction of the gradient and the parallel calculation back propagation further alleviate the network bottleneck. At the end of backpropagation, each node has an average gradient to ensure that the model weights are synchronized.
- The above steps require multiple processes, and may even synchronize and communicate with multiple processes on different nodes. And Pytorch through its
distributed.init_process_grouprealization function. This function needs to know how to find process 0 (process 0) so that all processes can be synchronized, and also know how many processes need to be synchronized in total. Each independent process also needs to know the total number of processes, as well as its rank in all processes, and of course also know which GPU it uses. The total number of processes is called world size. Finally, each process needs to know which part of the data to be processed, so that batch processing does not overlap. The Pytorch throughnn.utils.data.DistributedSamplerto achieve this effect.
Fourth, the minimum routine and explanation
In order to show how to do this, here is an example of training on MNIST, and then modified it to run on multi-node multi-GPU, and the final modified version can also support mixed precision operations.
# step1: 首先,我们 import 所有我们需要的库
import os
from datetime import datetime
import argparse
import torch.multiprocessing as mp
import torchvision
import torchvision.transforms as transforms
import torch
import torch.nn as nn
import torch.distributed as dist
from apex.parallel import DistributedDataParallel as DDP
from apex import amp
# step2: 之后,我们训练了一个 MNIST 分类的简单卷积网络
class ConvNet(nn.Module):
def __init__(self, num_classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7*7*32, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
def train(gpu, args):
torch.manual_seed(0)
model = ConvNet()
torch.cuda.set_device(gpu)
model.cuda(gpu)
batch_size = 100
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda(gpu)
optimizer = torch.optim.SGD(model.parameters(), 1e-4)
# Data loading code
train_dataset = torchvision.datasets.MNIST(root='./data', train=True,
transform=transforms.ToTensor(),
download=True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=0,
pin_memory=True)
start = datetime.now()
total_step = len(train_loader)
for epoch in range(args.epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
labels = labels.cuda(non_blocking=True)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0 and gpu == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(
epoch + 1,
args.epochs,
i + 1,
total_step,
loss.item())
)
if gpu == 0:
print("Training complete in: " + str(datetime.now() - start))
def main():
parser = argparse.ArgumentParser()
parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N')
parser.add_argument('-g', '--gpus', default=1, type=int,
help='number of gpus per node')
parser.add_argument('-nr', '--nr', default=0, type=int,
help='ranking within the nodes')
parser.add_argument('--epochs', default=2, type=int, metavar='N',
help='number of total epochs to run')
args = parser.parse_args()
train(0, args)
if __name__ == '__main__':
main()
Execute the following command, you can train on a single GPU on a node~
python src/mnist.py -n 1 -g 1 -nr 0
Five, plus MultiProcessing
- We need a script to start each GPU of a process. Each process needs to know which GPU to use and its rank in all running processes. Moreover, we need to run the script on each node.
- Now let us look at the changes of each function. These changes will be boxed separately for easy searching.
def main():
parser = argparse.ArgumentParser()
parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N')
parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node')
parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes')
parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run')
args = parser.parse_args()
#########################################################
args.world_size = args.gpus * args.nodes #
os.environ['MASTER_ADDR'] = '10.57.23.164' #
os.environ['MASTER_PORT'] = '8888' #
mp.spawn(train, nprocs=args.gpus, args=(args,)) #
#########################################################
- args.nodes is the number of nodes we use
- args.gpus is the number of GPUs per node.
- args.nr is the rank of the current node. The value range is 0 to args.nodes-1.
OK, now we have changed everything line by line
args.world_size = args.gpus * args.nodes
Based on the number of nodes and the number of GPUs per node, we can calculate the world_size or the total number of processes that need to be run, which is equal to the total number of GPUs.os.environ['MASTER_ADDR'] = '10.57.23.164'
Tell the Multiprocessing module which IP address to find process 0 to ensure that all processes are initially synchronized.os.environ['MASTER_PORT'] = '8888'
Similarly, this is the port where process 0 is locatedmp.spawn(train, nprocs=args.gpus, args=(args,))
Now, we need to generate args.gpus processes, and each process runs train(i, args), where i ranges from 0 to args.gpus-1.
Note that main() runs on every node, so there are a total of args.nodes * args.gpus = args.world_size processes.
In addition to the first and second settings, it can also be run in the terminal
export MASTER_ADDR=10.57.23.164
export MASTER_PORT=8888
Next, what needs to be modified is the training function, and the modified place is still framed.
def train(gpu, args):
############################################################
rank = args.nr * args.gpus + gpu #
dist.init_process_group( #
backend='nccl', #
init_method='env://', #
world_size=args.world_size, #
rank=rank #
) #
############################################################
torch.manual_seed(0)
model = ConvNet()
torch.cuda.set_device(gpu)
model.cuda(gpu)
batch_size = 100
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda(gpu)
optimizer = torch.optim.SGD(model.parameters(), 1e-4)
###############################################################
# Wrap the model #
model = nn.parallel.DistributedDataParallel(model, #
device_ids=[gpu]) #
###############################################################
# Data loading code
train_dataset = torchvision.datasets.MNIST(
root='./data',
train=True,
transform=transforms.ToTensor(),
download=True
)
################################################################
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset,
num_replicas=args.world_size,
rank=rank
)
################################################################
train_loader = torch.utils.data.DataLoader(
dataset=train_dataset,
batch_size=batch_size,
##############################
shuffle=False, #
##############################
num_workers=0,
pin_memory=True,
#############################
sampler=train_sampler) #
#############################
...
- Line3: Here is the global rank of the process in all processes (one process corresponds to one GPU). This rank will be used in Line6
- Line4~6: Initialize the process and join other processes. This is called
blocking, which means that a single process will only run when all processes are added. The nccl backend is used here because the Pytorch documentation says it is the fastest.init_methodLet the process group know where to find the settings it needs. Here, it is looking for the nameMASTER_ADDRas well asMASTER_PORTenvironment variables, these environment variables are set off in the main function. Of course, world_size could have been set to a global variable, but this script chose to use it as a keyword parameter (same as the global rank of the current process)- Line23: Encapsulate the model as a DistributedDataParallel model. This will copy the model to the GPU for processing.
- Line 35~39:
nn.utils.data.DistributedSamplerEnsure that each process gets a different training data slice.- Line46/Line51: Because nn.utils.data.DistributedSampler is used, the normal method cannot be used for shuffle.
To run it on 4 nodes (8 gpus on each node), we need 4 terminals (one on each node). On node 0 (set by line 13 in main):
python src/mnist-distributed.py -n 4 -g 8 -nr 0
And on other nodes:
python src/mnist-distributed.py -n 4 -g 8 -nr i
- Among them, i∈1,2,3. In other words, we need to run this script on each node and let the script run args.gpus processes to synchronize each process before the training starts.
- Note that the batchsize in the script sets the batchsize of each GPU, so the actual batchsize must be multiplied by the total number of GPUs (worldsize).
Six, use Apex for mixed mixed precision training
- Mixed-precision training, which combines floating-point numbers (FP32) and half-precision floating-point numbers (FP16) for training, allows us to use a larger batchsize and use NVIDIA tensor cores for faster calculations. The AWS p3 instance uses 8 NVIDIA Tesla V100 GPUs with tensor cores.
- We only need to modify the train function. For the sake of simplicity, the following has removed the data loading code and the code after backpropagation from the example, and replaced them with..., but you can see the complete script here.
rank = args.nr * args.gpus + gpu
dist.init_process_group(
backend='nccl',
init_method='env://',
world_size=args.world_size,
rank=rank)
torch.manual_seed(0)
model = ConvNet()
torch.cuda.set_device(gpu)
model.cuda(gpu)
batch_size = 100
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda(gpu)
optimizer = torch.optim.SGD(model.parameters(), 1e-4)
# Wrap the model
##############################################################
model, optimizer = amp.initialize(model, optimizer, opt_level='O2')
model = DDP(model)
##############################################################
# Data loading code
...
start = datetime.now()
total_step = len(train_loader)
for epoch in range(args.epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
labels = labels.cuda(non_blocking=True)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
##############################################################
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
##############################################################
optimizer.step()
...
- Line18: Encapsulate
amp.initializethe model and optimizer for subsequent mixed precision training.
Note that the model model must have been deployed on the GPU before calling amp.initialize. opt_level ranges from O0 (all use floating point numbers) to O3 (all use half-precision floating point numbers). O1 and O2 have different degrees of mixed precision. For details, please refer to APEX's official documents. Note the capital letter O before the number.- Line20:
apex.parallel.DistributedDataParallelis ann.DistributedDataParallelreplacement version. We don't need to specify a GPU, because Apex only allows one GPU in a process. And it also assumes that the program has calledtorch.cuda.set_device(local_rank)(line 10) before moving the model to the GPU .- Line37-38: Mixed precision training needs to scale the loss function to prevent underflow of the gradient. But Apex will automatically do these tasks.