Can you still play like this? Use Prompt Tuning for fine-grained image retrieval!
【Written in front】
Fine-grained object retrieval aims to learn discriminative representations to retrieve visually similar objects. However, existing best-performing works usually impose pairwise similarities on the semantic embedding space to continuously tune the entire model in a limited data regime, leading to easy convergence to suboptimal solutions. In this paper, we propose Fine-grained Retrieval Prompt Tuning Algorithm (FRPT), which utilizes frozen pre-trained models to perform fine-grained retrieval tasks from the perspective of sample prompting and feature adaptation. Specifically, FRPT only needs to learn fewer parameters in hinting and adaptation instead of tuning the whole model, thus solving the problem of converging to suboptimal solutions caused by fine-tuning the whole model. Technically, as sample hints, Structural Perturbation Tips (SPP) are introduced to scale and even exaggerate some pixels that are helpful for category prediction through content-aware non-uniform sampling operations. In this way, during the original pre-training process, the SPP algorithm can make the perturbation-cue-assisted fine-grained retrieval tasks closer to the solved tasks. Furthermore, the authors propose a category-based cognitive gimmick as feature adaptation , which eliminates the instance differences in the features extracted by the pre-trained model through instance normalization, so that the optimized features only contain the differences between subcategories. difference. Extensive experiments show that FRPT achieves state-of-the-art performance on three widely used fine-grained datasets with fewer learnable parameters.
1. Paper and code address

Fine-grained Retrieval Prompt Tuning
Paper address: https://arxiv.org/abs/2207.14465
Code address: not open source
2. Motivation
Fine-grained object retrieval (FGOR) is to retrieve images belonging to various subcategories of a certain metacategory (such as birds, cars, and airplanes) and return images with the same subcategories as the query image. However, retrieving visually similar objects is still challenging for practical applications, especially when there are large intra-class differences but small inter-class differences. Therefore, the crux of FGOR lies in learning discriminative and generalizing embeddings to recognize visually similar objects.
Recently, successful FGOR is performed for large intra-class but small inter-class differences by designing specialized metric constraints or localizing objects or even parts. While metric-based and localization-based works can learn discriminative embeddings to recognize granular objects, the FGOR model learned from the previous stage still requires endless fine-tuning in the next stage, forcing the model to adapt to granular retrieval tasks. However, continuously tuning the FGOR model may lead to easy convergence to suboptimal solutions, especially when faced with limited data regimes, inevitably limiting the retrieval performance. Therefore, a natural question arises: is it still possible to learn discriminative embeddings without fine-tuning the entire FGOR model?
Hint-based learning is task-related instructions for downstream input to adapt downstream tasks to a frozen pre-trained model. Its key idea is to reformulate the downstream task to be close to the task solved during the original pre-training through proper hint design, instead of adapting the pre-trained model to the downstream task. Following this idea, the visual-language pre-training task has been progressively developed, which derives visually guided concepts from natural language by putting visual category semantics as cues into text input. Despite achieving remarkable performance on many downstream vision tasks even without optimizing language models, their fast tuning strategies are tailored for multimodal models and not applicable to pre-trained vision models. Therefore, how to design a hinting scheme for pre-trained vision models to solve the convergence of suboptimal solutions due to the optimization of the whole FGOR model is worth investigating.
In this paper, the authors propose Fine-grained Retrieval Prompt Tuning ( FRPT) with Structural Perturbation Prompts (SPP), pre-trained backbone models and **Class-Specific Perceptual Heads (CAH)**, which only freezes the backbone model weights while learning fewer SPP and CAH parameters, which solves the problem of converging to a suboptimal solution. Specifically, as a sample hinting process, SPP is designed to scale and even exaggerate some elements that are helpful to category prediction through content-aware non-uniform sampling operations. In this way, SPP can adjust the object structure towards facilitating category prediction, which makes the FGOR task cued under this structure perturbation close to the solved task during the original pre-training. However, a problem that cannot be ignored is that the backbone model without adjustment will focus on extracting features to answer the question, "what are the different characteristics between species", rather than "how to distinguish granular objects in the same meta-category". Therefore, CAH is regarded as feature adaptation, which optimizes the features extracted by the backbone model by using instance normalization to remove species differences, so that the optimized features only contain differences between subcategories. Unlike fine-tuning, FRPT has fewer parameters to train, but still learns embeddings with greater discriminative and generalization due to SPP and CAH, thus solving the convergence of suboptimal solutions caused by fine-tuning the whole model.
The contributions of this paper are as follows:
1. The author proposes FRPT to guide the frozen pre-trained model to perform the FGOR task from the perspective of sample hints and feature adaptation. This paper is the first work to specifically develop a hint-based fine-tuning scheme to handle the convergence of suboptimal solutions caused by optimization strategies in FGOR.
2. A structural perturbation cue is proposed to emphasize elements contributing to decision boundaries that instruct frozen pretrained models to capture subtle but discriminative details.
3. A class-specific perceptual head aims to eliminate differences between species, which enables specific features to be used to identify specific granular objects within the same meta-class.
4. FRPT only needs to optimize about 10% of the parameters, rather than fully optimized, and even achieves new state-of-the-art results, which is a significant gain of +3.5% average retrieval accuracy on three widely used granular retrieval datasets .
3. Method

The authors propose Fine-grained Retrieval Prompt Tuning (FRPT) for guiding a frozen pre-trained model to perform the FGOR task. FRPT only optimizes fewer learnable parameters in example hints and feature adaptation, and keeps the backbone frozen during training. In this way, FRPT addresses the convergence of suboptimal solutions caused by tuning the entire FGOR model.
3.1 Network Architecture
The network architecture is given in the figure above. Given an input image I, it is first fed into a Structure Perturbation Prompt (SPP) module to generate a modified image IP I_{P}IP, the modified image IP I_{P}IPSelectively highlight certain elements that contribute to the decision boundary. After that, the modified image IP I_{P}IPAs input to a frozen pre-trained backbone, which outputs semantic features MP M_{P}MP. In order to make MP M_{P}MPTo identify granular objects in the same meta-category, instead of identifying different species, the MP M_{P}MPInput into the class-specific perception head (CAH) module to generate class-specific feature MR M_{R}MR. Finally, discriminative embeddings are obtained by a global average pooling operation, and then they are applied to search for other samples with the same subcategory.
3.2 Structure Perturbation Prompt
To address the problem of converging to a suboptimal solution caused by optimizing the entire model, the authors are inspired by hint-based learning to only modify pixels in the input, which enables granularity where hints are close to those resolved during pre-training. Retrieve tasks. Therefore, the authors propose the Structural Perturbation Prompt (SPP) module to scale and even exaggerate certain elements that contribute to category prediction in pixel space. In this way, SPP can manipulate the frozen pre-trained model with hints to perceive more discriminative details, leading to high-quality representations. Specifically, SPP consists of two steps. The first step, content parsing , is to learn a discriminative projection map that reflects the location and strength of discriminative information, and the second step, structural modification , is guided by the discriminative projection map by performing content-aware Non-uniform sampling operation, zooming in on discriminant elements. A detailed description of these two steps follows.
Content parsing
Perceptual details and semantics play a crucial role in perturbing object structure. Based on this consideration, the authors design a content parsing module to perceive the position and scale of distinguishing semantics and details from low-level features. Content parsing has an appealing property: a large-domain view that aggregates contextual information within a large receptive field, rather than exploiting pixel neighborhoods. Therefore, content parsing can capture discriminative semantics from low-level details while preserving discriminative details.
Given an input image I ∈ R 3 × H × WI \in \mathbb{R}^{3 \times H \times W}I∈R3 × H × W , the author feeds I to the frozen pre-trained representation modelF block 1 \mathcal{F}_{block 1}Fblock1In the convolution block 1 to generate low-level features MS ∈ RCS × HS × WS M_{S} \in \mathbb{R}^{C_{S} \times H_{S} \times W_{S}}MS∈RCS×HS×WS, among which HS , WS , CS H_{S}, W_{S},C_{S}HS,WS,CSare the height, width and number of channels. It should be clear that since shallow layers in pretrained representation models are sensitive to low-level details such as color and texture, their parameters do not need to be updated and still work well.
Get low-level features MS M_{S}MSFinally, the authors transform it into a discriminative projection map in a content-aware manner. Specifically, each target position A ∈ RHS × WS \mathcal{A} \in \mathbb{R}^{H_{S} \times W_{S}} on the discriminant projection mapA∈RHS×WSCorresponds to MS M_{S}MSσ 2 \sigma^{2} onp2 source locations. Therefore, each target location shares a content-aware kernelW k ∈ R σ × σ × CS W_{k} \in \mathbb{R}^{\sigma \times \sigma \times C_{S}}Wk∈Rσ×σ×CS, where σ is the content-aware kernel size and is not smaller than MS M_{S}MS1 2 \frac{1}{2} of width21. Using a shared content-aware kernel W k W_{k}Wk, the content parsing module will specify the position, scale and intensity of distinguishing semantics and minutiae. For target position ( m , n ) (m, n)(m,n ) , the calculation formula is as follows, wherer = ⌊ σ / 2 ⌋ r=\lfloor\sigma / 2\rfloorr=⌊σ/2⌋:
A ( m , n ) = ∑ w = − r r ∑ h = − r r ∑ c = 1 C S W k ( w , h , c ) ⋅ M S ( m + w , n + h , c ) \mathcal{A}_{(m, n)}=\sum_{w=-r}^{r} \sum_{h=-r}^{r} \sum_{c=1}^{C_{S}} W_{k}^{(w, h, c)} \cdot M_{S}^{(m+w, n+h, c)} A(m,n)=w=−r∑rh=−r∑rc=1∑CSWk(w,h,c)⋅MS(m+w,n+h,c)
The discriminative projection map A is spatially normalized using a softmax function before being applied to the structure modification operation. The normalization step forces the sum of the weight values in A to be 1:
A i j = e A i j ∑ i = 1 W S ∑ j = 1 H S e A i j \mathcal{A}_{i j}=\frac{e^{\mathcal{A}_{i j}}}{\sum_{i=1}^{W_{S}} \sum_{j=1}^{H_{S}} e^{\mathcal{A}_{i j}}} Aij=∑i=1WS∑j=1HSeAijeAij
Structure modification
The structure modification module utilizes the spatial information of sample points in the discriminative projection map and the corresponding sample weights to rearrange the object structure, which further highlights some elements in the input that contribute to category prediction. Therefore, the modified image IP ∈ R 3 × W × H I_{P} \in \mathbb{R}^{3 \times W \times H}IP∈R3 × W × H can be expressed as follows:
I P = S ( I , A ) I_{P}=\mathcal{S}(I, \mathcal{A}) IP=S(I,A)
S ( . ) S(.) S ( . ) represents the content-aware non-uniform sampling function.
The author's basic idea of non-uniform sampling is to treat the discriminative projection map A as a probability mass function, where regions with larger sample weights in A are more likely to be sampled. Therefore, the authors compute the mapping function between the modified and original images, and then use the grid sampler introduced in STN to rearrange the objects. The mapping function can be decomposed into two dimensions, the horizontal axis dimension and the vertical axis dimension, thereby reducing the mapping complexity. Taking the coordinates (x, y) in the modified image as an example, the mapped coordinates ( M x ( x ) , M y ( y ) ) in the original input can be calculated \left(\mathcal{M}_{x}(x) , \mathcal{M}_{y}(y)\right)(Mx(x),My( y ) ) as follows:
M x ( x ) = ∑ w = 1 W S ∑ h = 1 H S A ( w , h ) ⋅ D < ( x W S , y H S ) , ( w W S , h H S ) > ⋅ w W S ∑ w = 1 W S ∑ h = 1 H S A ( w , h ) ⋅ D < ( x W S , y H S ) , ( w W S , h H S ) > , M y ( y ) = ∑ w = 1 W S ∑ h = 1 H S A ( w , h ) ⋅ D < ( x W S , y H S ) , ( w W S , h H S ) > ⋅ h H S ∑ w = 1 W S ∑ h = 1 H S A ( w , h ) ⋅ D < ( x W S , y H S ) , ( w W s , h H S ) > , \mathcal{M}_{x}(x)=\frac{\sum_{w=1}^{W_{S}} \sum_{h=1}^{H_{S}} \mathcal{A}(w, h) \cdot \mathcal{D}<\left(\frac{x}{W_{S}}, \frac{y}{H_{S}}\right),\left(\frac{w}{W_{S}}, \frac{h}{H_{S}}\right)>\cdot \frac{w}{W_{S}}}{\sum_{w=1}^{W_{S}} \sum_{h=1}^{H_{S}} \mathcal{A}(w, h) \cdot \mathcal{D}<\left(\frac{x}{W_{S}}, \frac{y}{H_{S}}\right),\left(\frac{w}{W_{S}}, \frac{h}{H_{S}}\right)>},\\\mathcal{M}_{y}(y)=\frac{\sum_{w=1}^{W_{S}} \sum_{h=1}^{H_{S}} \mathcal{A}(w, h) \cdot \mathcal{D}<\left(\frac{x}{W_{S}}, \frac{y}{H_{S}}\right),\left(\frac{w}{W_{S}}, \frac{h}{H_{S}}\right)>\cdot \frac{h}{H_{S}}}{\sum_{w=1}^{W_{S}} \sum_{h=1}^{H_{S}} \mathcal{A}(w, h) \cdot \mathcal{D}<\left(\frac{x}{W_{S}}, \frac{y}{H_{S}}\right),\left(\frac{w}{W_{s}}, \frac{h}{H_{S}}\right)>}, Mx(x)=∑w=1WS∑h=1HSA(w,h)⋅D<(WSx,HSy),(WSw,HSh)>∑w=1WS∑h=1HSA(w,h)⋅D<(WSx,HSy),(WSw,HSh)>⋅WSw,My(y)=∑w=1WS∑h=1HSA(w,h)⋅D<(WSx,HSy),(Wsw,HSh)>∑w=1WS∑h=1HSA(w,h)⋅D<(WSx,HSy),(WSw,HSh)>⋅HSh,
where D < , > \mathcal{D}<,>D<,> is the Gaussian distance kernel used as a regularizer to avoid some corner cases such as all pixels converging to the same location.
Modifying each spatial location of an image requires a global perspective to select filled pixels in the original input, thereby preserving structural knowledge. Moreover, regions with large sample weight values are allocated more sampling opportunities, thus amplifying or even exaggerating discriminative elements in the input. More importantly, each pixel in the modified image is related to each other, and the object structure is slightly perturbed instead of completely destroyed.
After obtaining the mapping coordinates, the differentiable bilinear sampling mechanism proposed in STN is then used, which interpolates linearly to approximate the final output, with I p I_pIpexpress
I P ( x , y ) = ∑ ( i , j ) ∈ N ( M x ( x ) , M y ( y ) ) w p ⋅ I ( i , j ) , I_{P}(x, y)=\sum_{(i, j) \in \mathcal{N}\left(\mathcal{M}_{x}(x), \mathcal{M}_{y}(y)\right)} w_{p} \cdot I(i, j), IP(x,y)=(i,j)∈N(Mx(x),My(y))∑wp⋅I(i,j),
其中 N ( M x ( x ) , M y ( y ) ) \mathcal{N}\left(\mathcal{M}_{x}(x), \mathcal{M}_{y}(y)\right) N(Mx(x),My( y ) ) represents the neighbors of the mapped point in I,wp w_pwpis the bilinear kernel weight estimated by the distance between a mapped point and its neighbors.
3.3 Category-specific Awareness Head
The core of CAH is Instance Normalization (IN), which can eliminate the differences between species. However, using IN directly may destroy the discriminative information, inevitably affecting the performance of target retrieval. To address this limitation, the authors design a channel-attention-guided IN, which selects features containing species differences based on channel attention, uses IN to remove these features, and integrates the original discriminative and optimized features into category-specific The characteristic MR M_{R}MR:
M R = W C ⋅ M P + ( 1 − W C ) ⋅ I N ( M P ) M_{R}=W_{C} \cdot M_{P}+\left(1-W_{C}\right) \cdot I N\left(M_{P}\right) MR=WC⋅MP+(1−WC)⋅IN(MP)
where, WC ∈ RCP W_{C} \in \mathbb{R}^{C_{P}}WC∈RCPThe weight coefficient representing the importance of different channel features, IN ( MR ) IN\left(M_{R}\right)IN(MR) is the inputMR M_{R}MRThe instance normalized features of . Inspired by SENet, channel attention can be expressed as follows:
W C = σ ( W L δ ( W F g ( M P ) ) ) W_{C}=\sigma\left(W_{L} \delta\left(W_{F} g\left(M_{P}\right)\right)\right) WC=p(WLd(WFg(MP)))
where g( ) represents the global average pooling operation, WF ∈ RCP r × CP W_{F} \in \mathbb{R}^{\frac{C_{P}}{r} \times C_{P}}WF∈RrCP×CP和 W L ∈ R C P × C P r W_{L} \in \mathbb{R}^{C_{P} \times \frac{C_{P}}{r}} WL∈RCP×rCPare the learnable parameters in the two unbiased fully connected layers, followed by the ReLU activation function δ and the Sigmoid activation function σ. For the size reduction ratio r, it aims to balance performance and complexity, so it is set to 8. The parameterless definition of IN is:
IN ( M P i ) = M P i − E [ M P i ] Var [ M P i ] + ϵ \operatorname{IN}\left(M_{P}^{i}\right)=\frac{M_{P}^{i}-E\left[M_{P}^{i}\right]}{\sqrt{\operatorname{Var}\left[M_{P}^{i}\right]+\epsilon}} IN(MPi)=Was[MPi]+ϵMPi−E[MPi]
其中 M P i ∈ R H P × W P M_{P}^{i} \in \mathbb{R}^{H_{P} \times W_{P}} MPi∈RHP×WPis the feature map MP M_{P}MPThe i-th channel of , used to avoid dividing by zero, calculates the average E [ ⋅ ] E[\cdot] of each channelE [ ⋅ ] and standard deviationVar [ ⋅ ] \operatorname{Var}[\cdot]Was [ ⋅ ]。
3.4 Optimization
After obtaining class-specific features, the model is only trained with cross-entropy loss. Apply the following cross-entropy loss to the classifier C( ) to predict subclasses:
L = − log P ( y ∣ C ( g ( M R ) ∣ θ ) ) \mathcal{L}=-\log P\left(y \mid C\left(g\left(M_{R}\right) \mid \theta\right)\right) L=−logP(y∣C(g(MR)∣i ) )
Where y represents the label, C ( g ( MR i ) ∣ θ ) C\left(g\left(M_{R}^{i}\right) \mid \theta\right)C(g(MRi)∣θ ) is the prediction of a classifier with parameters θ. The optimization process only affects the parameters within the SPP and CAH modules, but has no effect on the backbone network during backpropagation, thereby solving the problems related to converging to suboptimal solutions due to the optimization of the entire representation model.
4. Experiment

The above table shows the results of the ablation experiments of the method in this paper. It can be seen that each module contributes to the performance of the overall model.

The above table shows the experimental results of different methods on the CUB-200-2011, Stanford Cars-196 and FGVC Aircraft datasets. It can be seen that under the same Backbone, the method in this paper can achieve better performance.

Different fine-tuning strategies As shown in the table above, tuning pre-trained vision models can reduce retrieval performance compared to freezing them. This phenomenon is plausible because tuning a pre-trained model on a limited granular dataset may compromise its ability for general vision modeling by converging to a suboptimal solution.
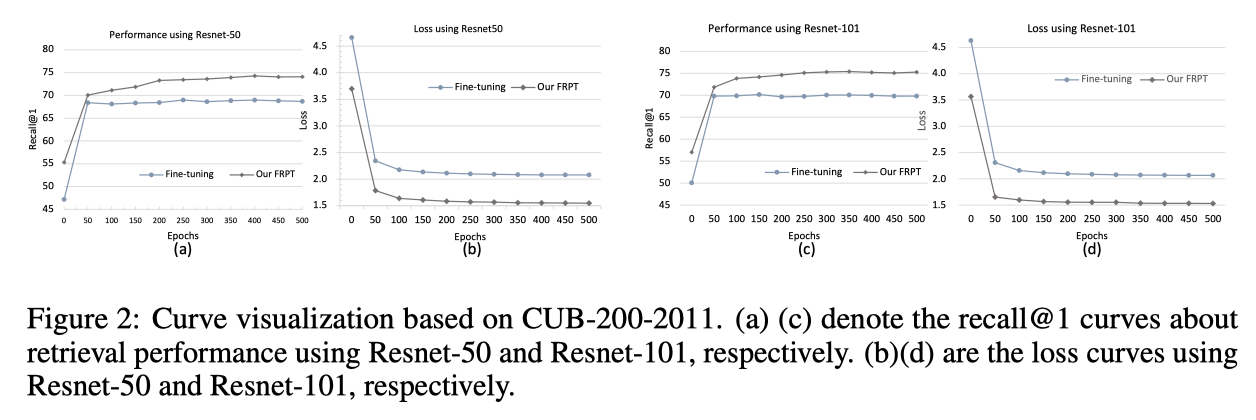
In order to better show the positive impact of FRPT in this paper, the author visualizes the retrieval accuracy and training loss curves in the above figure. It can be observed from the FRPT curves that more and more training epochs usually bring slow performance improvement and significantly increase the convergence speed.

To explore the effectiveness of FRPT more deeply, the authors conduct extensive experiments based on the few-shot setting with two different numbers of samples for each subclass: 10 and 5 on CUB-200-2011. In the 5-shot and 10-shot experimental settings in the table above. FRPT consistently outperforms fine-tuning strategies under different pre-trained vision models. Compared with the pre-trained model tuned using all images in CUB-200-2011, our FRPT uses only 10 samples per subclass, but achieves close performance.

As shown in the table above, switching the processing method from structure perturbation hinting (SPP) to a fixed hinting strategy, i.e. scaling objects directly, leads to a significant performance drop. Specifically, the authors localize objects using class activation maps (CAMs) or bounding boxes provided by annotation information, and then crop them from the original image.

The author shows the visualization results of the original image and the modified image in the figure above. These visualizations can explain why and how our method can correctly identify different subcategories.
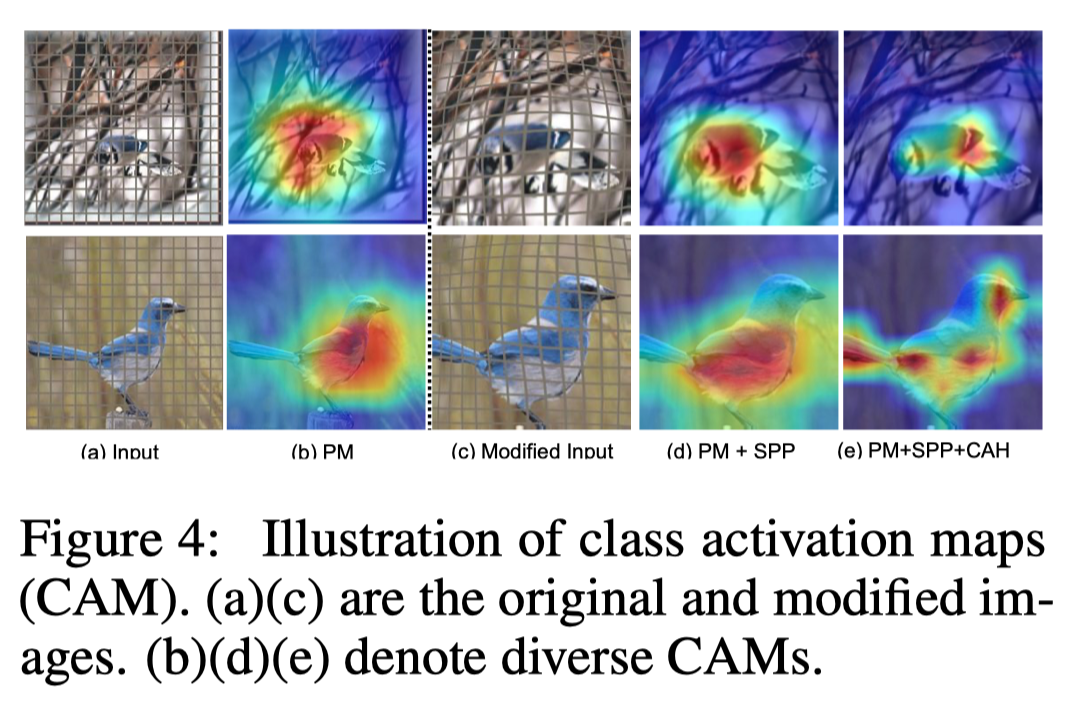
In the figure above, in addition to showing the original and modified images, the authors also provide discriminative activation maps for the three representation models.
5. Summary
In this paper, the authors propose Fine-grained Retrieval Prompt Tuning (FRPT), which aims to address the convergence of suboptimal solutions caused by the optimization of the entire FGOR model. FRPT designs structural perturbation cues (SPP) and class-specific perceptual heads (CAH) to guide a frozen pre-trained vision model to perform non-ad hoc retrieval tasks. Technically, SPP scales and exaggerates some pixels that contribute to class prediction, which helps this structural perturbation force the frozen pre-trained model to focus on discriminative details. CAH optimizes the semantic features extracted by the pre-trained model by eliminating species differences using instance normalization, which makes the optimized features sensitive to granular objects within the same meta-category. Compared with fine-tuning schemes, FRPT has fewer parameters to train, but still learns embeddings with greater discriminative and generalization due to SPP and CAH, thus solving the suboptimality caused by fine-tuning the whole FGOR model solution convergence. Extensive experiments show that our FRPT achieves state-of-the-art performance on three widely used fine-grained datasets with fewer learnable parameters.
【Project recommendation】
The core code library of top conference papers for Xiaobai: https://github.com/xmu-xiaoma666/External-Attention-pytorch
YOLO target detection library for Xiaobai: https://github.com/iscyy/yoloair
Analysis of papers for Xiaobai's top journal and conference: https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading

"Look at each one, the monthly salary is 100,000!"
"Learn to like, worth tens of millions!"