Article Directory
TransFG: A Transformer Architecture for Fine-grained Recognition
Abstract
Current work mainly accomplishes FGVC by focusing on how to locate the most discriminative regions and rely on them to improve the network's ability to capture subtle changes.
Most of these works propose bound boxes through RPN modules and reuse the backbone network to extract features of the selected boxes.
In recent years, ViT has made great achievements in traditional classification tasks, and its self-attention mechanism connects the token of each patch to the classification token. The strength of attention connections can be intuitively viewed as an indicator of representation importance.
In this paper, a new transformer-based structure TransFG is proposed.
In this paper, all original attention weights are aggregated into an attention map to guide the network to efficiently and accurately select discriminative image patches and calculate the relationship between them.
In addition, we use a contrastive loss to further enlarge the distance between feature representations of similar subclasses.
introduction
To avoid the labor-intensive local labeling problem, we currently focus on weakly supervised FGVC with only image labels.
Existing methods are mainly divided into two categories, namely localization methods and feature encoding methods. The advantage of the localization method is that it can clearly capture the subtle differences between different subclasses, which is more interpretable and leads to better results.
A typical strategy is to use local features for classification and use rank loss to keep the consistency between bbox and output probability.
However, such methods obviously ignore the relationship between the selected regions, and encourage RPN to generate some large bboxes to contain more parts to produce correct classification results. Even, a large bbox can cause background clutter.
The great success of the vision transformer demonstrates that a pure transformer with an intrinsic attention mechanism, when directly applied to a sequence of image patches, can capture important regions to facilitate classification.
This paper proposes TransFG, a simple and effective framework based on ViT, specifically:
- By leveraging the innate multi-head self-attention mechanism, this paper proposes a local selection module to compute discriminative regions and remove redundant information.
- This paper connects the selected local token with the global token as the input sequence of the last transformer layer of i;
- Introducing duplicate loss to estimate multi-head attention modules produces different results.
Such a strategy pushes the network to focus on different regions of the image. In order to further increase the distance between feature representations of samples of different categories and reduce the distance between feature representations of samples of the same kind, this paper introduces a contrastive loss to further improve performance.
Method
Vision transformer as feature extractor
Image Sequentialization
Following ViT , the input image is first preprocessed into a series of flattened patches xp x_pxp。
However, these original segmentation methods crop the image into some non-overlapping patches, which seriously damage the local neighboring structures . Especially the discriminative area is separated (because it is a simple segmentation, maybe half of the bird's head is in one piece, and the other half is in another piece).
To solve this problem, this paper proposes to generate overlapping patches with sliding windows .
Specifically, we set the resolution of the input image to be H ∗ WH*WH∗W , the size of the image patch isPPP , the step size of the sliding window isSSS , so we can get N patches.
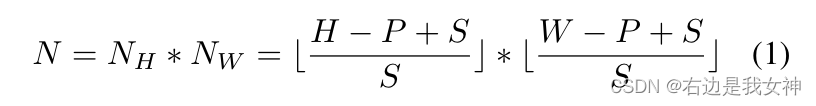
Thus, two connected patches have an overlapping area of size ( P − S ) ∗ P (PS)*P(P−S)∗P , helps preserve better local region information.
It stands to reason that the smaller the step size, the better the performance, but as S decreases, the computational cost will also increase.
Patch Embedding
This paper uses trainable linear projections to embed vectorized patches into a latent D-dimensional space.
A learnable position embedding is added to the patch embedding to maintain position information, and its operation is as follows:
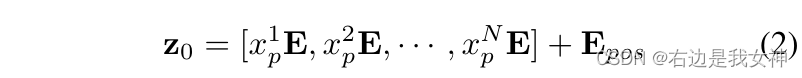
其中, E ∈ R ( P 2 ⋅ C ) ∗ D E\in R^{(P^2\cdot C)*D} E∈R(P2⋅C)∗D, E p o s ∈ R N ∗ D E_{pos}\in R^{N*D} Epos∈RN∗D。
The Transformer encoder contains L multi-head self-attention (MSA) and MLP modules.
The operation of a single layer is as follows:
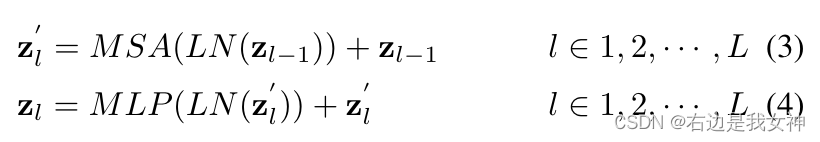
where LN ( ⋅ ) LN(\cdot)L N ( ⋅ ) is layer normalization. ViT converts the first token of the last layerto ZL 0 Z_L^0ZL0As a global feature and feed it into the head of a classifier to obtain the final classification result without considering the latent information in the remaining tokens .
TransFG Architecture
pure ViT can be directly used in FGVC, but it does not capture the local information needed by FGVC well. To this end, this paper proposes a partial selection module, PSM, and applies contrastive learning to enlarge the representation distance between similar subcategories.
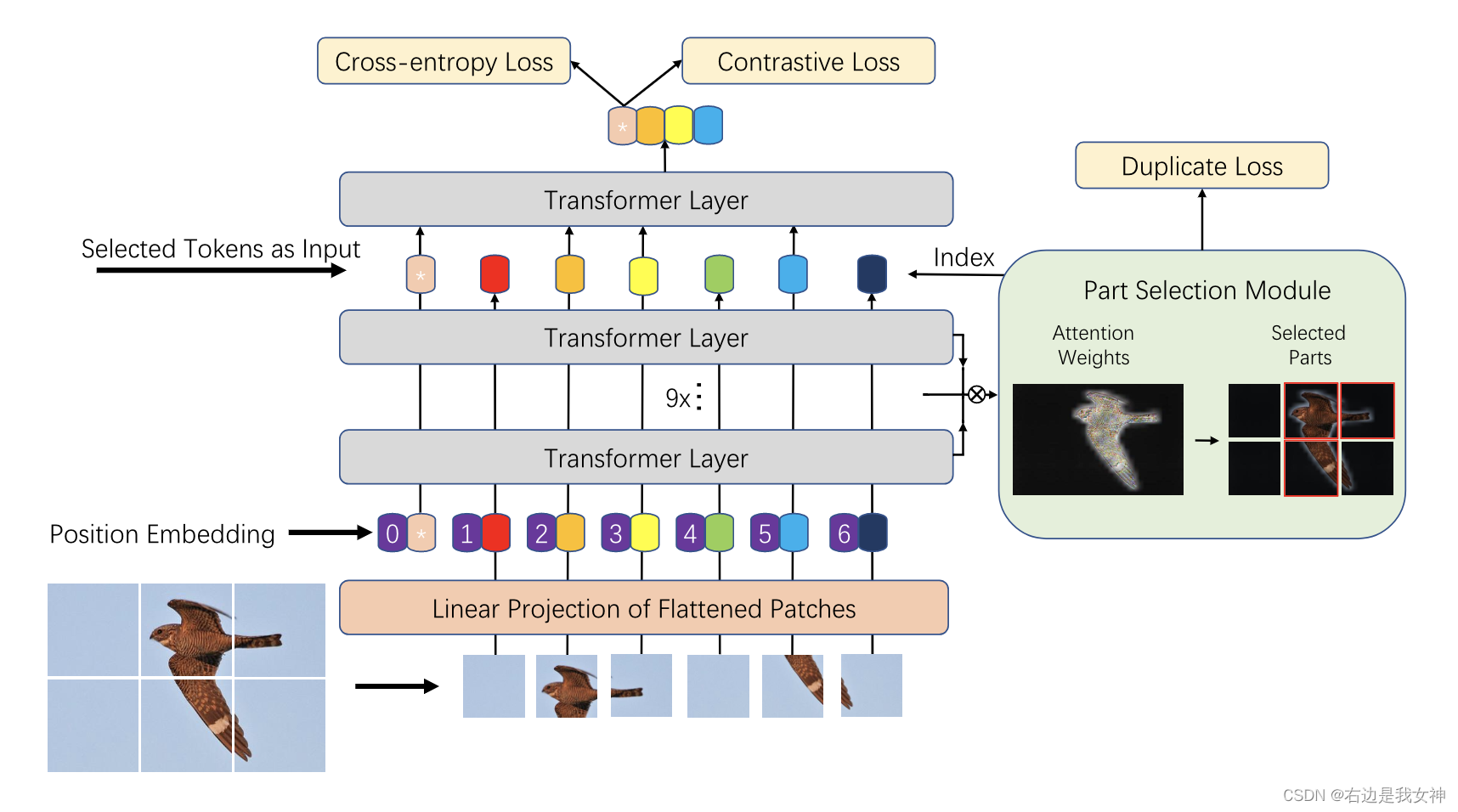
Part Selection Module
Suppose the model has K self-attention heads and let the hidden features sent to the last layer be z L − 1 = [ z L − 1 0 , z L − 1 1 , . . . , z L − 1 N ] z_ {L-1}=[z_{L-1}^0,z_{L-1}^1,...,z_{L-1}^N]zL−1=[zL−10,zL−11,...,zL−1N]。
Among them, the attention weights of the first few layers can be written as:
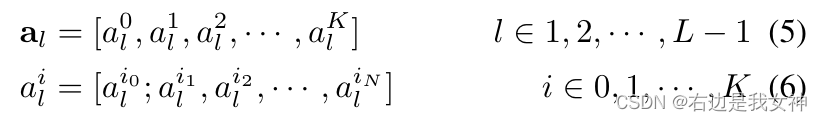
It can be seen that the attention of each head is a vector.
Previous work has shown that raw attention weights do not necessarily correspond to the relative importance of input tokens, especially for higher layers of the model due to the lack of discriminability of embedded tokens.
Therefore, we consider aggregating the attention weights of all previous layers. Specifically, we recursively apply matrix multiplication to all layers:
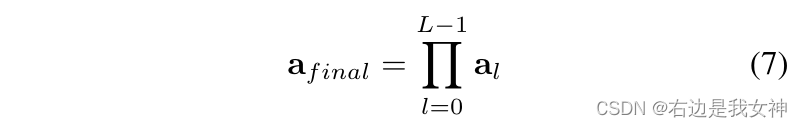
It captures how information is propagated from the input layer to higher embedding layers.
Compared to the original attention weight a L − 1 a_{L-1} of a single layeraL−1, this matrix acts as a better choice to select discriminative regions.
We then choose about afinal a_{final}afinalThe maximum value of K different attention heads A 1 , A 2 , . . . , AK A_1,A_2,...,A_KA1,A2,...,AKindex of. These positions are used as indices into our model to extract z L − 1 z_{L-1}zL−1The relevant index in .
Finally, we concatenate these chosen tokens and label them as:
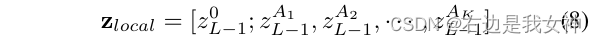
We not only keep global information, but also force the last Transformer Layer to pay attention to small differences.
In order to estimate that the multi-head attention focuses on different discriminative regions, we added a duplicate loss to restrict the selection of the same region :
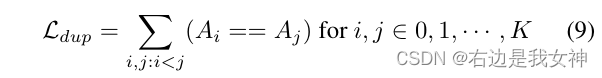
Constrastive feature learning
We still use the first token of PSM for classification. A simple cross-entropy loss is not enough to fully supervise the learning of this feature, since the differences between subclasses are relatively small.
Therefore, we adopt a contrastive loss to minimize the similarity between classification tokens corresponding to different labels and maximize the similarity between classification tokens corresponding to the same label.
To prevent the loss from being easily dominated by simple negative samples, we introduce a constant interval α \alphaα , which means that only the similarity ratio of negative sample pairs isα \alphaOnly when α is large will it contribute to the loss.
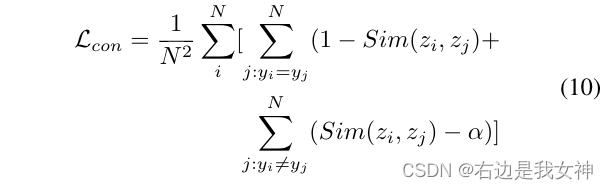
It means that the features corresponding to two samples with different sample labels should be extremely dissimilar, and such simple negative samples will greatly affect the model.
The final loss function consists of three parts:
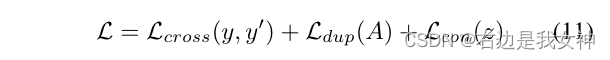
ViT-FOD:A Vision Transformer based Fine-grained Object Discriminator
Abstract
At present, some ViT-based methods have been proposed, which are significantly better than existing CNN-based methods.
However, applying ViT directly to FGVC has some limitations:
- ViT needs to divide the image into small pieces and calculate the attention of each pair, which may lead to a large number of redundant calculations, and the performance is not satisfactory when dealing with fine-grained images with complex backgrounds and small objects;
- Standard ViT only utilizes the last layer of class tokens for classification, which is not enough to extract comprehensive fine-grained information.
To address the above two issues, this paper proposes a new ViT based on a fine-grained object discriminator, which is called ViT-FOD for short.
Specifically, in addition to the main body of ViT, it also introduces three new components, namely Attention Patch Combination (APC), Critical Regions Filter (CRF) and Complementary Tokens Integration (CTI).
Among them, APC divides information blocks from two images to generate a new image, reducing redundant calculations. CRF emphasizes tokens with discriminative regions to generate new category tokens for subtle feature learning. To extract comprehensive information, CTI integrates supplementary information captured by category tokens in different ViT layers.
Introduction
CNN-based methods lack proper means to establish the relationship between these regions and integrate them into a unified concept , and the self-attention mechanism is a way to solve this problem.
There are currently several papers that have done research and achieved initial success:
- Ju He, Jie-Neng Chen, Shuai Liu, Adam Kotylewski, Cheng Yang, Yutong Bai,Changhu Wang, and Alan Yuille. 2022. TransFG: A Transformer Architecture for Fine-grained Recognition. InProceedings of the AAAI Conference on Artificial Intelligence
- Yunqing Hu, Xuan Jin, Yin Zhang, Haiwen Hong, Jingfeng Zhang, Yuan He, and Hui Xue. 2021. RAMS-Trans: Recurrent Attention Multi-scale Transformer for Fine-grained Image Recognition. InProceedings of the ACM InternationalConference on Multimedia. 4239– 4248.
- Xinda Liu, Lili Wang, and Xiaoguang Han. 2021. Transformer with Peak Sup-pression and Knowledge Guidance for Fine-grained Image Recognition.arXivpreprint arXiv:2107.06538(2021).
- Jun Wang, Xiaohan Yu, and Yongsheng Gao. 2021. Feature Fusion Vision Trans-former for Fine-grained Visual Categorization.arXiv preprint arXiv:2107.02341(2021).
There are still some issues to consider:
1) Standard ViT needs to divide the image into small patches as input, and then a multi-head self-attention module (MSA) in each layer obtains the relationship between any two small patches. However, for fine images, many samples contain complex backgrounds and some objects may be relatively small, so using ViT to process things will inevitably generate a lot of useless calculations and even introduce noise .

The large number of grass patches does not help the classification done by ViT.
2) ViT uses pre-defined class tokens for prediction. In the standard ViT model, class tokens are processed in MSA like each image patch, and only the last layer is taken out for classification. From a certain point of view, the class token is obtained based on all image blocks in a self-attention manner, which may not be conducive to further focusing on some key and subtle areas. From another perspective, according to the experiments in this paper, class labels from different layers can extract features targeting different information, and they are complementary. Therefore, only using the final class labels is not enough to fully utilize the feature extraction ability of ViT.
This paper presents three improved modules:
- APC decomposes two images into small pieces and stitches the informative ones together to generate a new image. In this way, it reduces the influence of the background in the input image by partially replacing the corresponding region with the informative part of another image;
- With a lower computational cost, CRF emphasizes the token corresponding to the differentiated area to generate a new class token;
- CTI classifies token-like objects based on multi-layers to capture complementary information between different layers.
Method
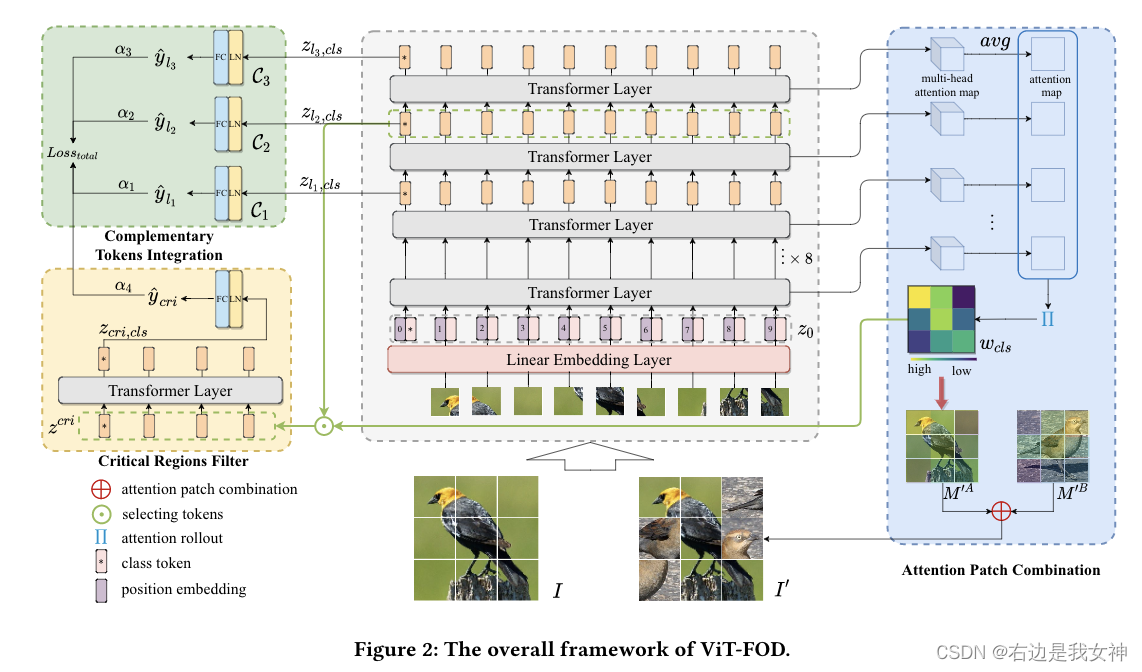
Complementary Tokens Integration
Image III is divided intoH × WH\times WH×W个patches x i ∈ R P × P × C , i ∈ { 1 , . . . , N } x^i\in R^{P\times P\times C},i\in\{1,...,N\} xi∈RP×P×C,i∈{ 1,...,N } , P is the size of each patch, C is the number of channels of the image,N = H × WN=H\times WN=H×W is the number of patches.
A linear embedding layer is used to map each patch to a token. Additionally, a learnable class token xcls x_{cls}xclswas introduced for classification.
Then, positional encodings are introduced to maintain spatial information. So, the data input to the first Transformer Layer looks like this:
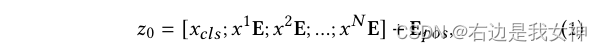
After that is the normal ViT operation:
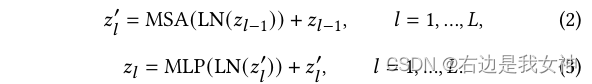
The class token of the last layer is sent to the classifier for classification to generate labels: y ^ = CL ( z L , cls ) \hat{y}=C_L(z_{L,cls})y^=CL(zL,cls)。
In order to complement information, CTI sends the class token of each layer to the classifier to obtain the category:
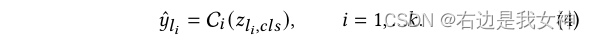
The final decision is obtained by weighting all predictions, and the corresponding loss is:
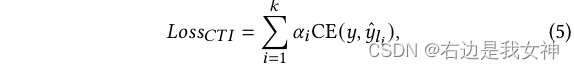
Attention Patch Combination
First introduce the basic operating mechanism of Self-Attention:

We remember the attention map as A l ∈ R ( N + 1 ) × ( N + 1 ) A_l\in R^{(N+1)\times(N+1)}Al∈R( N + 1 ) × ( N + 1 ) , for multi-head attention, its size isRH head ( N + 1 ) × ( N + 1 ) R^{H_{head}(N+1)\times(N+ 1)}RHhead(N+1)×(N+1)。
We add a recognition matrix E to this attention and average them to get the attention weights for each layer:
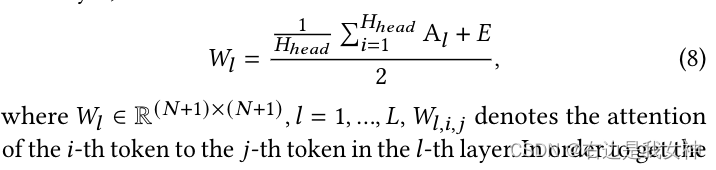
In order to obtain the final attention map, this paper adopts the attention rollout algorithm, which applies a matrix multiplication iteratively to the attention weights of all layers:
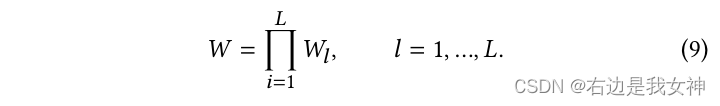
The goal of APC is to merge important patches of two images according to the weight map to eliminate redundant calculations. In addition, APC can also be used as a data augmentation method to improve the generalization ability of the model.
Specifically, we are getting wcls ∈ RN w_{cls}\in R^Nwcls∈RAfter N (the attention weight of the class token relative to other tokens, obtained from W), we reshape it into a two-dimensional, and then pool it into pxp to get wcls ′ ∈ R p × p w_{cls}' \in R^{p\times p}wcls′∈Rp×p:
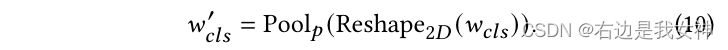
According to the weight map, we can get the corresponding sequence numbers idxcls idx_{cls} in descending orderidxcls。
For two graphs IA I_AIAJapanese IB I_BIBFor example, the generated mask MAM^AMA andMBM^BMB as follows:
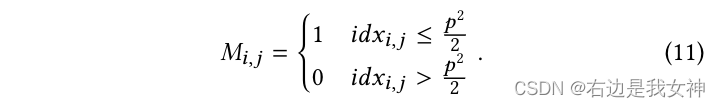
Then we get a new image with the following operations:
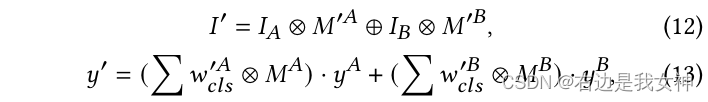
Circle multiplication means element-by-element multiplication, and circle addition means filling the front 0 part with the back part of 1.
Let me translate:
- Get a class token part of the attention matrix from the original image to the final, which reflects the degree of attraction of each token to the class token. The greater the attraction, the more important this part is;
- Two-dimensional + pooling of this local attention vector is equivalent to dividing the original image first, and labeling the image blocks according to their importance. The more important the number, the higher the number, half of which is marked as 1, and the other half is marked as 0;
- Finally, the 1 image block of A picture and the 1 image block of B picture are put together.
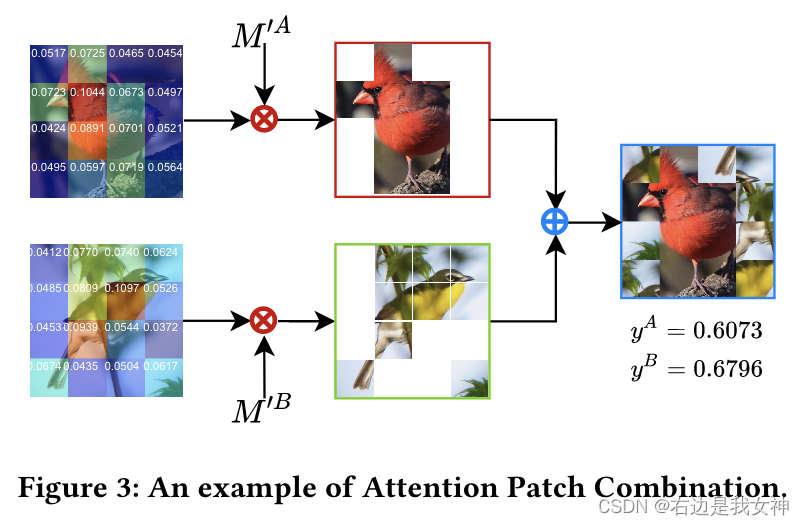
Regarding the label of the synthetic graph, this paper gives the corresponding calculation method.
This amounts to a complex data augmentation.
I think the reason for this is that the original model will learn the attention relationship between the background and the background, which is useless, so I hope the model can learn more about the relationship between key parts.
Critical Regions Filter
It is an interesting idea to crop out discriminative regions and then train the model, which is adopted in RAMS-Trans, but this method will significantly increase the computational cost. In addition, there is a big limitation of rectangle clipping.
To solve the above problems, this paper proposes a simple and effective key region filtering module to select tokens of discriminative regions and generate an additional class token to collect the information of the selected tokens.
First, a threshold η \eta is definedη to control the number of tokens selected.
Suppose the token is based on wcls w_{cls}wclsSort the size in descending order, record η N \eta Nη The weight of N tokens is wcls ˉ \bar{w_{cls}}wclsˉ, so we can choose the token method as follows:
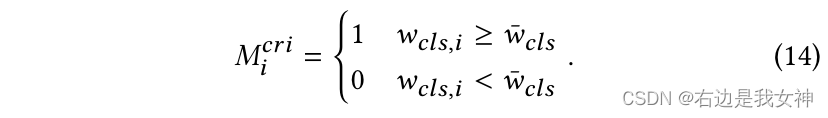
Finally, the selected token and class token are concatenated as input to the Transformer Layer in the CRF:

Feature Fusion Vision Transformer for Fine-Grained Visual Categorization
Abstract
ViT achieves state-of-the-art performance on general image recognition tasks. The self-attention mechanism aggregates and weights information from all tokens to classify tokens. However, deep classification tokens pay more attention to global information and lack local and low-level features important to FGVC.
In this paper, we propose a new pure transformation-based framework for fusion of visual transformations, where we pool important tokens from each transformation layer to compensate local, low-level and mid-level information.
In this paper, we design a new token selection model called Mutual Attention Weight Selection (MAWS) to effectively guide the network to select discriminative tokens without introducing additional parameters.
Introduction
Common methods are divided into localization-based and attention-based.
localization-based: In the early days, it was realized by directly annotating the discriminative part of the image; later, due to the high cost of labeling, RPN was used to obtain potential and discriminative bboxes;
However, the current method ignores the relationship between regions; and this type of method often prompts RPN to propose a large bbox, which is inaccurate and prone to confusion; in addition, some regions cannot be simply marked with rectangles .
attention-based: Contacted the reliance on manual labeling to distinguish regions, and achieved good results.
The FFVT proposed in this paper aggregates local information from low-level, mid-level and high-level tokens to facilitate classification. This paper proposes a new and important token selection method for selecting representative tokens at each layer. These tokens are added as input to the last Transformer layer.
Methods
ViT For Image Recognition
Given a picture of size HxW, vit first processes it as N = ⌊ HP ⌋ × ⌊ WP ⌋ N=\lfloor\frac{H}{P}\rfloor\times\lfloor\frac{W}{P}\ rfloorN=⌊PH⌋×⌊PW⌋ patchxp x_pxp。
These patches are then linearly mapped and position encoded. Then add an additional class token, and the input is complete:
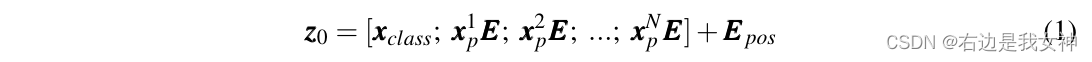
After that, it enters the stacked MSA layer and MLP layer:
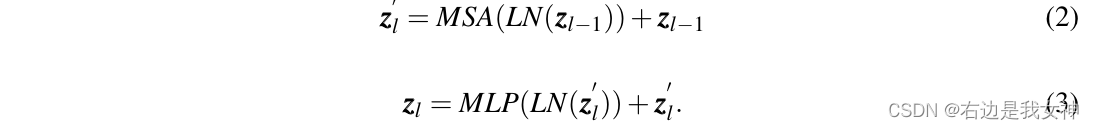
FFVT Architecture
TransFG implies that this ViT does not capture enough information. In order to solve this problem, this paper proposes to fuse these low-level features and mid-level features to enrich these local information.
This paper proposes a new token selection method called mutual attention weight selection (MAWS) to determine token pooling.
The overall framework is as follows:

Feature Fusion Module
Given important tokens, we replace the input of the last layer with these tokens (except the class token). In this way, the class token and the last layer can fully interact with low, middle, and high-level features, enriching local information and feature representation capabilities.
We mark the tokens selected in layer l as:
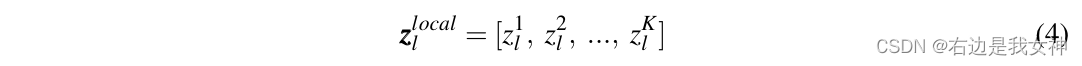
Then, the input to the last layer is:
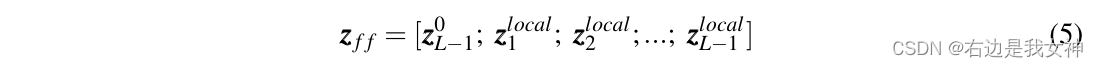
Finally, the class token of the final layer is ready to be distributed to the classification head to perform classification. Thus, the question becomes how to choose important and discriminative tokens.
Mutual Attention Weight Selection Module
This paper directly uses the attention scores generated by MSA to implement the token selection strategy. More specifically, the attention matrix A ∈ R ( N + 1 ) × ( N + 1 ) A\in R^{(N+1)\times(N+1)} of an attention headA∈R( N + 1 ) × ( N + 1 ) is expressed as follows:
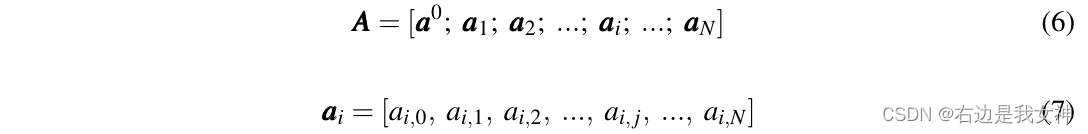
a i , j a_{i,j} ai,jIndicates the dot-product between the query of token I and the key of token j.
One of the simplest strategies is to choose a token with a higher attention score than the classification token, because the classification token contains rich classification information.
In this way, just pass to a 0 a_0a0Sort and select the index corresponding to K larger values.
This paper calls this method single attention weight selection (SAWS).
But this method introduces some noise, because the selected tokens can gather more information from noisy patches.
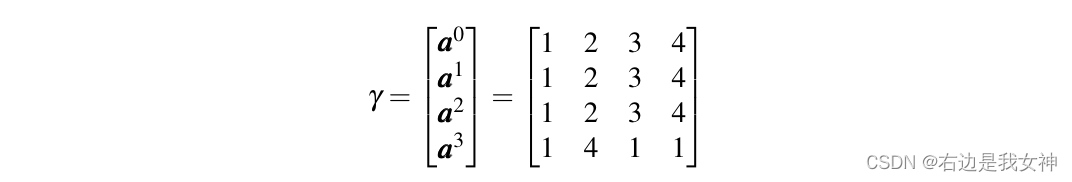
In the figure above, the classification token selects the third token, but the third token contains too much information about the first token. If the first token is a noisy token, then token3 contains a lot of noise.
To address this issue, this paper proposes a mutual attention weight selection module that requires the selected tokens to be similar to the categorical token both in the context of the categorical token and in the token itself.
Represent the first column of the attention map as b 0 b_0b0, denote the attention scores of the classification token and other tokens in the context of other tokens.
Then with a 0 a_0a0For comparison, the interactive attention weights mai ma_imaiExpressed as:
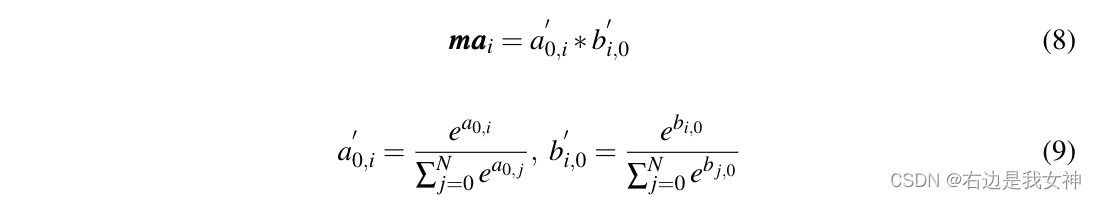
For multi-head self-attention, we average the attention scores of all heads.
This indicator means that the attention of the classification token to token I and the attention of token I to the classification token are both high.