say up front
In the community of thousands of readers of the 40-year-old architect Nien , he has been guiding everyone's resume and career upgrade. A few days ago, I guided the resume of an old Huawei partner . The advantage of the small partner is to live more in different places. However, in the process of resume guidance, Nien found that the concept of more live in different places and the structure of more live in different places are very important, but However, my friends are not too clear about the whole system of living in different places.
Moreover, the structure of multiple activities in different places is very important. In March, there were two major online accidents. Just after Bilibili collapsed, Vipshop collapsed again.
Here, Nien sorts out a top-level solution for his friends in the Future Super Architect Community (Future Super Architect Community).
The main goal: It is convenient to use it as a reference when guiding the architecture.
Of course, good knowledge cannot be enjoyed exclusively. This plan is announced to everyone through Nien’s self-media channels by the way, providing reference materials for everyone to build the structure.
Also take this solution as a reference answer for the system's high-availability architecture, and include it in our " Nin Java Interview Collection " V76 for reference by future partners to improve everyone's 3-high architecture, design, and development levels.
Note: This article is continuously updated in PDF. For PDF files of the latest Nien architecture notes and interview questions, please go to the [Technical Freedom Circle] at the end of the article.
Article directory
-
- say up front
- A series of P0 level accidents (high availability accidents)
- Architects, can you not bear the blame?
- What is a good architecture
- Root cause analysis of two P0 faults
- What is live in different places
- Common multi-active schemes
- Option 1: Live-active in the same city
- Option 2: Three Centers in Two Places
- Option 3: Unitization + multiple activities in different places
- 3 major challenges of living more in different places
- Successful case of multiple activities in different places: Dewu APP's transformation of multiple activities in different places
A series of P0 level accidents (high availability accidents)
-
Station B collapsed on March 5
-
Vipshop collapsed again on March 29
P0 level accident: Station B collapsed on March 5
On the evening of March 5th, in Nien’s Future Super Architect Community (Future Super Architect Community), some friends found that the server of station B was in a state from 20:22, and users could not watch videos and refresh recommended content. It didn't return to normal until around 20:40, which lasted for nearly 20 minutes.
Incident recovery
On the APP side of Station B, users can open the homepage with a cache,
If there is no cache, you will get an error message, and the page cannot be loaded normally when accessing video resources.

Users of the main website on the web cannot refresh normally after clicking "Change". After several attempts, they will get a prompt "There is no new content for the time being".
Cause of accident
At 2:00 a.m. the next day, Station B issued an announcement saying that last night, some server rooms at Station B failed, making it inaccessible.
The technical team immediately investigated and repaired the problem, and now the service has gradually returned to normal.
Sphere of influence
Judging from the 60 million daily active users of station B and the high activity period of traditional video users at 8 p.m., the number of users affected by this accident exceeds 10 million.
Judging from the conventional accident evaluation standards of Internet companies, it should be classified as a P0-level accident.
For such a serious accident, the main technical person in charge faces the risk of deduction of performance or even taking the blame and leaving.
P0 accident: Vipshop collapsed again on March 29
On 6.6, in Nien's Future Super Architect Community (Future Super Architect Community), a small partner posted a Vipshop punishment announcement.
The guy’s question is: tell me how to avoid this situation (P0-level accident, the person in charge will dismiss the get out of class).
Incident recovery
The sudden incident that happened on March 29, when the Vipshop app crashed, rushed to the hot search on the same day.
Symptoms of failure: Functions such as "additional purchase" may appear abnormal.
Duration of failure: 12 hours.
According to the news on June 6, Vipshop released a handling announcement, and the crash of the Vipshop app on March 29 was judged to be a P0-level failure.

What is a P0 level accident?
事故等级主要针对生产环境,划分依据类似于bug等级。
P0级 属于最高级别事故。 比如崩溃,页面无法访问,主流程不通,主功能未实现,或者在影响面上影响很大(即使bug本身不严重)。
P1级 属于高级别事故。 一般属于主功能上的分支,支线流程,核心次功能等
P2级 属于中级别事故。主要根据企业实际情况划分。
P3级 属于低级别事故。 主要根据企业实际情况划分。
PN级 ...级别越高。
P0 belongs to the highest level of accidents, such as crashes, page inaccessibility, main process failure, main function not implemented, or great impact on the impact surface (even if the bug itself is not serious).
The official stated in the announcement that the major failure of the Nansha computer room lasted for 12 hours, resulting in a loss of more than 100 million yuan in the company's performance and affecting more than 8 million customers.
Vipshop stated that it has decided to deal with the incident seriously, and the direct managers of the corresponding departments shall bear the responsibility for the accident.
The key point is that the main technical person in charge will face deduction of performance or even take the blame and leave : the person in charge of the basic platform department will be dismissed and dealt with accordingly.
Architects, can you not bear the blame?
In Nien's Future Super Architect Community (Future Super Architect) community, there are a large number of architects, many of whom are senior 40-year-old architects.
Therefore, Nien's perspective is not to pay attention to how many billions will be lost by Station B and Vipshop.
Instead, we focus on the career of our architects. Simply put, it is a sentence:
Architects, can you not bear the blame?
Here, let's clarify the responsibilities first.
Although the person in charge of the basic platform department is a management post, he also has certain architectural responsibilities. Therefore, in a certain sense, he is also an architect.
Of course, some friends will say that an architect is a technical strategist and technical master, who is responsible for coming up with plans and ideas. The head of the basic platform department is not an architect.
If you must say so, fine.
Now that the old commander is gone, will the military adviser feel better? Also have to take the blame and leave .
So, it's still the same question: architects, how do you get rid of the fate of taking the blame and leaving?
What is a good architecture
How not to take the blame? Let's go back to the problem itself.
Nien sorted out a three-level architecture knowledge universe for our Future Super Architect Community (Future Super Architect) community, including an architect knowledge map worth 100,000.
In Nien's three-high architecture knowledge universe knowledge graph, there is a super large graph that reveals to everyone that a good software architecture should follow the following three principles:
- high performance
- High concurrency
- high availability
The url link address of the map is at the top of the PDF of many Bible e-books in Nien, so I won’t post it here
For details, please refer to the front of the PDF of Nin's "Java High Concurrency Core Programming Volume 1", "Java High Concurrency Core Programming Volume 2" and "Java High Concurrency Core Programming Volume 3".
The three principles of the three-high architecture
Principle 1: High performance means that the system has the ability to process more traffic and lower response delay.
For example, 10W concurrent requests can be processed in 1 second, the interface response time is 5 ms, and so on.
Principle 2: High concurrency means that the system can be expanded with minimal cost when iterating new functions. When the system encounters traffic pressure, the system can be expanded without changing the code.
Principle 3: High availability is usually measured by two indicators:
- MTBF (Mean Time Between Failure): Indicates the interval between two failures, that is, the average time for the system to "normally operate". The longer the time, the higher the stability of the system
- MTTR (Mean Time To Repair): Indicates the "recovery time" after a system failure. The smaller the value, the less impact the failure will have on users
Usability is related to both:
Availability = MTBF / (MTBF + MTTR) * 100%
The result of this formula is a ratio, and usually we use "N nines" to describe the availability of a system.
| system availability | Annual downtime | Daily failure time |
|---|---|---|
| 90% (1 of 9) | 36.5 days | 2.4 hours |
| 99% (2 nines) | 3.65 days | 14 minutes |
| 99.9% (3 nines) | 8 hours | 86 seconds |
| 99.99% (4 nines) | 52 minutes | 8.6 seconds |
| 99.999% (5 nines) | 5 minutes | 0.86 seconds |
| 99.9999% (6 nines) | 32 seconds | 86 milliseconds |
From this picture, it is best for everyone to be familiar with it.
From the figure, we can see that in order to achieve the availability of more than 4 nines, the unavailable time in a year is 52 minutes, and the average daily failure time must be controlled within 10 seconds.
What is a good architecture?
Principle 1 tells everyone: Use the least amount of resources to get the most benefit.
Principle 2 tells everyone: It must be highly scalable and self-scaling, be able to undertake high throughput, high concurrency, and be able to automatically expand and shrink
Principle 3 tells everyone: The availability of a year must reach at least 4 nines, and the unavailable time should not exceed 52 minutes.
From this point of view, the accidents at station B and Vipshop all illustrate a problem:
Station B and Vipshop have not achieved the high availability of principle 3: High availability has not reached 4 9s, let alone 5 9s.
From this dimension: Station B and Vipshop have so many people and such a large technical team, but they have not achieved an excellent structure.
It's time for their architecture team to reflect on it.
It's time for some serious reflection.
Root cause analysis of two P0 faults
When Nien is a member of our Future Super Architect Community (Future Super Architect) community, when he guides the transformation and upgrade of the architecture, he first emphasizes: root cause analysis
Generally speaking, regardless of Bilibili or Vipshop, the links inside the stand-alone room must be highly available.
why? With so many architects, if the high-availability architecture inside the single computer room cannot be realized, it will be useless.
If some readers really don't know: how to do a high-availability architecture inside a single computer room.
This is simple, look at the 40-year-old Nien's value 10W architect knowledge map, and browse Nien's blog, you will get a general idea.
The internal high availability of the single computer room is guaranteed by the architect.
The high availability of the computer room is guaranteed by the computer room manufacturer: the requirements for building a computer room are actually very high, such as geographical location, temperature and humidity control, backup power supply, etc., the computer room manufacturer will do a good job in all aspects of protection.
The key is, how to ensure that there are no infrastructure problems in the geographical dimension?
for example:
- On May 27, 2015, an optical fiber was cut in a certain place in Hangzhou, and nearly 300 million users could not access Alipay for 5 hours
- On July 13, 2021, part of the server room of station B failed, causing the entire station to be inaccessible for 3 hours
- On October 9, 2021, a power failure occurred in the server room of Futu Securities, causing users to be unable to log in and trade for 2 hours
- On March 29, 2023, Vipshop encountered a catastrophic failure in the computer room. The failure of the Nansha IDC refrigeration system caused the temperature of the equipment in the computer room to rise rapidly and shut down, causing the online mall to stop serving. The impact of the accident lasted for 12 hours, resulting in a loss of more than 100 million yuan in Vipshop's performance and affecting more than 8 million customers
- ...all P0 accidents
It can be seen that even if the protection at the computer room level has been done well enough , as long as there are infrastructure problems in the regional dimension (network problems, power problems, earthquake problems, flood problems), our system will not be available.
How to solve the infrastructure problem in the geographical dimension?
In contrast, this god can't handle it.
As application architects, we can only evade, only evade, and only evade.
How to avoid it? The core measure is: live more in different places.
What is live in different places
There are many concepts of multiple living in different places, such as double living in the same city, three centers in two places, five centers in three places and so on.
If you want to understand how to live in different places, you need to start with the three high principles of architecture design.
Common multi-active schemes
4 9 high-availability core solutions are multi-active in different places
Multi-active in different places refers to the business scenario in which multiple sites distributed in different places provide services to the outside world at the same time.
Remote multi-active is a kind of high-availability architecture design. The main difference from traditional disaster recovery design is "multi-active", that is, all sites provide services to the outside world at the same time.
Common multi-active solutions include multiple technical solutions such as dual-active in the same city, three centers in two places, and five centers in three places.
Option 1: Live-active in the same city
Intra-city dual-active is to establish two computer rooms in the same city or in a similar area.
The distance between the two computer rooms in the same city is relatively short, and the quality of the communication line is relatively good. It is relatively easy to realize synchronous data replication, ensuring a high degree of data integrity and zero data loss.
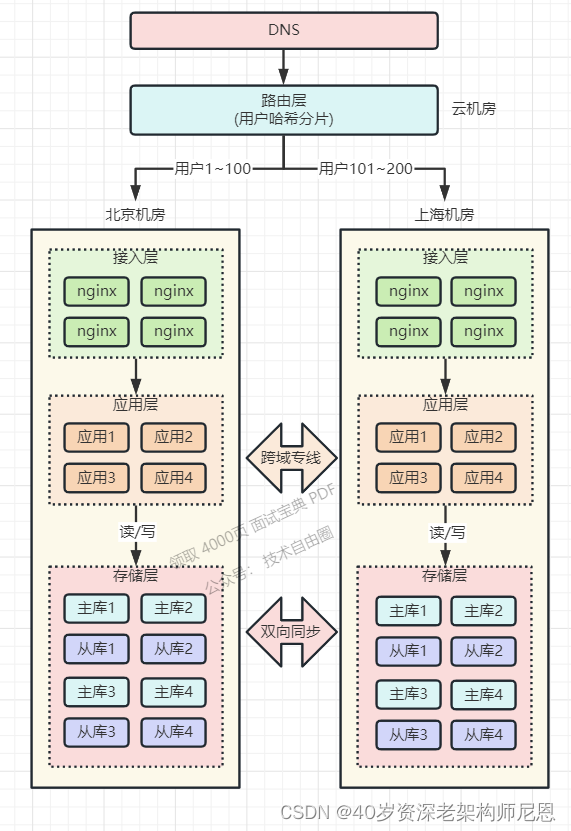
Each of the two computer rooms in the same city bears a part of the traffic. Generally, the entrance traffic is completely random. Internal RPC calls should be closed-loop in the same computer room through the nearest route as much as possible. This is equivalent to deploying two independent clusters in the mirror image of the two computer rooms, and the data is still written to the database of the computer room at a single point. , and then synchronize to another computer room in real time.
The following figure shows a simple deployment architecture for intra-city active-active. Of course, the actual deployment and considerations are far more complicated than the following figure.

The service call basically completes the closed loop in the same computer room, and the data is still written to the data storage in the main computer room at a single point, and then copied to the backup computer room in the same city synchronously in real time.
When there is a problem in computer room A, the operation and maintenance personnel only need to manually change the routing method through GSLB or other solutions to route the traffic to B computer room.
Active-active in the same city can be effectively used to prevent computer room disasters caused by fire, building damage, power supply failure, computer system and man-made sabotage.
For the principle of GSLB, the core component of the dual-active in the same city, you can refer to the PDF of Nien's High Concurrency Trilogy Part 3 "Java High Concurrency Core Programming Volume 3 Enhanced Edition".
The key to live-active in the same city:
(1) How to switch between two computer rooms
(2) How to ensure data consistency
How to switch between two computer rooms
Then how to let the B computer room also access the traffic?
The simplest measure is to perform DNS flow switching. Add the IP address of the access layer of computer room B to the DNS, so that the traffic of computer room B can come in from the upper layer.

How to ensure data consistency
Business applications need to distinguish " read-write separation " when operating the database. Assuming that A is the master and B is the slave,
- "Read" traffic, you can read the storage of any computer room,
- "Write" traffic is only allowed to write to computer room A, because the main library is in computer room A.
- Then perform data synchronization in the A-B computer room

This architecture involves all storage used, for example, MySQL, Redis, MongoDB, etc. are used in the project.
To operate these databases, it is necessary to distinguish read and write requests, so this requires a certain amount of business "transformation" costs.
The best way: to complete the unified reading and writing transformation through the proxy intermediate component.
Why not immediately achieve more living in different cities?
The above plan is only to live more in the same city, not to live more in different cities.
Multiple activities in the same city can solve irresistible disasters at the computer room level , but there is no way to solve irresistible disasters at the regional level.
If the computer room with more jobs in the same city is placed in two cities, wouldn’t it become more jobs in different cities?
It's not that simple, let's see the problem.
Generally speaking, the network of the multi-active computer room is connected through a " cross-city dedicated line ".
If the distance between the two computer rooms is far away, limited by the physical distance, the network delay between the two places has now become a factor that cannot be ignored .
For example, the distance from Beijing to Shanghai is about 1,300 kilometers. Even if a high-speed "network leased line" is set up, the optical fiber transmits at the speed of light, and a round trip requires a delay of nearly 10ms.
Moreover, various routers, switches and other network devices will pass through the network lines, the actual delay may reach 30ms ~ 100ms, if the network jitter occurs, the delay may even reach 1 second.
At this time, both computer rooms are connected to traffic, so the request from the Shanghai computer room may have to read and write the storage in the Beijing computer room. There is a big problem here: network delay, poor user experience, and risk of data loss .
That is to say, if it is more live in different cities, the distance is too far, and the network delay is too large.
At this time, if computer room A hangs up and the data has not been synchronized, there will be 1 second of data loss.
Here is another case of poor user experience: A client requests to call to the Shanghai computer room, and the Shanghai computer room needs to read and write the storage in the Beijing computer room. The delay of a cross-computer room access reaches 30ms, which is roughly the intranet network (0.5 ms) of the computer room. 60 times the speed (30ms / 0.5ms), a request is 60 times slower, and a round trip is more than 100 times slower.
When we open a page in the app, we may access dozens of back-end APIs, and each time we access across computer rooms, the response delay of the entire page may reach the second level. This performance is simply horrible and unacceptable .
so:
If the computer room with more jobs in the same city is placed in two cities, wouldn’t it become more jobs in different cities? This kind of thinking is too superficial.
Option 2: Three Centers in Two Places
The so-called three centers in two places refers to two centers in the same city + remote disaster recovery center.
The remote disaster recovery center refers to the establishment of a backup disaster recovery center in a remote city, which is used for dual-center data backup. The data and services are usually cold.
When the city or region where the dual center is located is abnormal and cannot provide external services, the remote disaster recovery center can use the backup data to restore the business.

Features of the two-site three-center plan
Advantage
- Active-active service in the same city, data disaster recovery in the same city, and cross-computer room level disaster recovery without data loss in the same city.
- The architecture solution is relatively simple, and the core is to solve the problem of active-active underlying data. Due to the short distance between the two computer rooms and the good communication quality, the underlying storage such as mysql can use synchronous replication to effectively ensure the data consistency of the two computer rooms.
- The disaster recovery center can prevent the two centers in the same city from failing at the same time, and use the backup data to restore the business.
disadvantage
- There are cross-computer room calls to write data in the database. Frequent cross-computer room calls under complex services and links increase the response time and affect system performance and user experience.
- If the service scale is large enough (for example, a single application exceeds 10,000 machines), all machines linking to one primary database instance will cause insufficient connections.
- If there is a problem, dare not easily switch the traffic to the off-site data backup center. The off-site backup data center is cold, and there is no traffic entering at ordinary times. Therefore, it takes a long time to verify the off-site disaster recovery computer room if there is a problem.
The construction complexity of the dual-active in the same city and the three-center construction in two places is not high. Compared with the active-active in the same city, the three-center in two places effectively solves the problem of data disaster recovery in different places, but it still cannot solve the many shortcomings of the active in the same city. Solving the disadvantages of these two architectures requires introducing more complex solutions to solve these problems.
Option 3: Unitization + multiple activities in different places
When Ali implemented this kind of solution, he named it " unitization ".
The strategy of unitization + multi-activity in different places is a real strategy of multi-activity in different places. There are two core points:
- user modularization
- data globalization
What is User Unitization
The same user will only fall in the same computer room. All subsequent business operations are completed in this computer room, avoiding "cross-computer rooms" from the root cause.
Under normal circumstances, the user's request processing will not "drift" in the two computer rooms.
The core measure of unitization of users: "differentiate" users at the top level, some users request to call the Beijing computer room, other users request to call the Shanghai computer room, and users who enter a certain computer room request, and all subsequent business operations , are all completed in this one computer room, avoiding "cross-computer rooms" from the root cause.
For safety reasons, each computer room needs to have a mechanism that can detect "data ownership" when writing storage. When the application layer operates storage, it needs to use middleware to do "coverage" to avoid situations that should not be written to the computer room.
After user unitization, user sharding can be performed.
The core idea of sharding is to allow related requests from the same user to complete all business "closed loops" in only one computer room, and "cross-computer room" access will no longer occur.
What is data globalization
The data in multiple computer rooms is full data.
Of course, part of the full amount can also be stored in different regions.
The nature of architecture is not one size fits all.
If one size fits all, it goes against the architectural spirit of Nien's Future Super Architect Community (Future Super Architect) community.
How to achieve data globalization?
Multiple computer rooms are receiving "reading and writing" traffic (request for fragmentation), the underlying storage maintains "two-way" synchronization, and both computer rooms have full data
When any computer room fails, another computer room can "take over" all the traffic to achieve fast switching
Traffic Routing in User Unitization Scenarios
In the unitized + remote multi-active strategy, a "routing layer" (usually deployed on cloud servers) is deployed on top of the access layer
The responsibility of the traffic routing layer is to "distribute" users to different computer rooms.

Rules for multi-computer room traffic routing
But how to determine this routing rule?
The general routing rules are:
- Fragmentation by business type
- Direct hash sharding
- Shard by geographic location
1. Fragmentation by business type
Assume that there are 4 applications, and these applications are deployed in both Beijing and Shanghai computer rooms.
However, applications 1 and 2 only access traffic in the Beijing computer room, and are only hot standby in the Shanghai computer room.
Applications 3 and 4 only access traffic in the Shanghai computer room, and are hot standby in the Beijing computer room.
In this way, all business requests of application 1 and 2 can only read and write the storage in the Beijing computer room, and all requests of application 3 and 4 can only read and write the storage in the Shanghai computer room.

Here, traffic is accessed in different computer rooms according to business types. It is also necessary to consider the dependencies between multiple applications. It is necessary to deploy applications that complete "related" services in the same computer room as much as possible to avoid cross-computer room calls.
2. Direct hash sharding
For example, the routing layer will calculate the "hash" modulo based on the user ID, then find the corresponding computer room from the routing table, and then forward the request to the designated computer room.
Example: There are 200 users in total, calculate the hash value according to the user ID, and then according to the routing rules,
User 1 - 100 is routed to the Beijing computer room,
Users 101 - 200 are routed to the Shanghai computer room,
In this way, it is avoided that the same user modifies the same piece of data.
3. Segmentation by geographic location
The sharding scheme based on geographical location is very suitable for businesses closely related to geographical location, such as taxi-hailing and food delivery services.
Takeaway must be ordered "nearby". The entire business scope is related to merchants, users, and riders, and they are all in the same geographical location.
In view of this feature, the top layer can be segmented according to the user's "geographical location" and distributed to different computer rooms.
For example: when users in Beijing and Hebei regions order food, their requests will only be sent to the computer room in Beijing, while for users in Shanghai and Zhejiang regions, their requests will only be sent to the computer room in Shanghai. Such fragmentation rules can also avoid data conflicts.

In short,
So far, we have realized the real " dual live in different places "!
So far you can see that the cost required to complete such a set of architecture is huge.
Routing rules, routing and forwarding, data synchronization middleware, and data verification strategies require not only the development of powerful middleware, but also a series of work such as business coordination and transformation (business boundary division, dependency splitting), and insufficient manpower and material resources. , this structure is difficult to implement.
3 major challenges of living more in different places

1. Data synchronization delay challenge
(1) If the application wants to go to a different place, the first thing to face is the delay caused by the physical distance.
If an application request needs to modify the same row of records in multiple units in different places, it will take a high time cost to meet the consistency and integrity of database data between units in different places.
(2) To solve the high latency in different places, it is necessary to close the reading and writing of data in the unit, so that different units cannot modify the same row of data, so we need to find a dimension to divide the unit.
(3) The access to other unit data in a certain unit needs to be correctly routed to the corresponding unit. For example, if user A transfers money to user B, the data of user A and user B are not in the same unit, and the operation on user B can be routed to the corresponding unit .
(4) The challenge of data synchronization is that all the data that is closed by the unit needs to be synchronized to the corresponding unit. For the read-write separation type, we need to synchronize the data in the center to the unit.
2. The challenge of unitized decoupling
The so-called unit (we will replace it with RZone below) refers to a self-contained collection that can complete all business operations. This collection contains all the services required by all businesses and the data assigned to this unit.
The unitized architecture is to use the unit as the basic unit of system deployment, and deploy several units in all computer rooms of the whole station. The number of units in each computer room is variable, and any unit has deployed all the applications required by the system.
Under the unitized architecture, the service is still layered. The difference is that any node in each layer belongs to and only belongs to a certain unit. When the upper layer calls the lower layer, only the nodes in this unit will be selected.
Which dimension to choose for traffic segmentation needs to be analyzed from the business itself.
For example, for e-commerce business and financial business, the most important processes are order placement, payment, and transaction process. It is the best choice to split the data by user ID, and the relevant operations of the buyer will be in the buyer's homepage. Completed within the unit.
For merchant-related operations, unitization cannot be performed, and it needs to be deployed according to the non-unitization mode described below.
Of course, the user operation business cannot completely avoid cross-unit or even cross-computer room calls. For example, two buyers A and B transfer business. When the data units of A and B are inconsistent, the operation on B needs to be completed across units. Later we Cross-unit call service routing issues will be introduced.
3. Traffic routing challenges
- Traffic scheduling : After the system is deployed, how the traffic will follow.
- Traffic self-closed loop : Due to the distance, cross-regional physical delay is unavoidable. How to ensure that all operations are completed locally after the traffic passes, and if not, how to minimize the impact of this delay.
- Disaster recovery and flow switching : When a computer room fails, how to quickly switch the traffic to other computer rooms without loss. This is not to say that simply cutting the traffic is over. Since the data is synchronized in multiple regions, can the consistency of the data be guaranteed after the traffic is cut?
Successful case of multiple activities in different places: Dewu APP's transformation of multiple activities in different places
Seeing so many P0-level off-site multiple live cases, let’s take a look at the successful cases:
High availability, 100Wqps, multiple live in different places, how is Dewu structured?
In addition, the remote multi-active structure of this article, together with Nien's other structure articles,
Form an architecture knowledge system to help everyone realize your architecture freedom :
" Have a thorough understanding of the 8-figure-1 template, everyone can do the architecture "
" 10Wqps review platform, how to structure it? This is what station B does! ! ! "
" Peak 21WQps, 100 million DAU, how is the small game "Sheep a Sheep" structured? "
" How to Scheduling 10 Billion-Level Orders, Come to a Big Factory's Superb Solution "
" Two Big Factory 10 Billion-Level Red Envelope Architecture Scheme "
Architecture is different from advanced development: Architecture issues are open, development-oriented, and there is no standard answer.
The road to architecture is destined to be full of ups and downs.
In the process of architecture or transformation, if you encounter a complex scenario, you really don’t know how to make an architecture solution, and you really can’t find a solid solution, what should you do? You can come to the 40-year-old structure Nien for help.
Just a few days ago, a small partner came across the golden link structure of an e- website , and couldn’t find his way of thinking at first, but after 10 minutes of voice guidance from Nien, he suddenly became enlightened.
So, if you encounter architecture problems, or even architecture problems, you can talk to Nien for help.
The PDF files of Nien’s architecture notes and interview questions are updated, ▼Please go to the following [Technical Freedom Circle] official account to get▼