The following article comes from front-end power bank, author CUGGZ
In 2023, the Internet world is changing rapidly, and online applications have become an indispensable part of our lives. However, during this year, a series of staggering online accidents occurred frequently. "XXX collapsed" became a frequent hot search. These accidents not only bring inconvenience and trouble to users, but also expose problems in the stability, security and ability of online services to respond to emergencies.
This article will take stock of the top ten online accidents in 2023, with a view to providing reference and warning for future online services.
Bilibili
On the evening of March 5, a server failure occurred at Station B. Videos on both the web and mobile terminals could not be loaded, and the forwarded video link showed "resource invalid".
The main ones affected are the "Fanju" and "Movies" pages. Users reported that "Zhuifan keeps prompting that the acquisition of video content failed", "the display page failed to load", and "half of Kanfankan cannot be loaded." Some users reported that the home page could be loaded, but it was all in traditional Chinese characters.
On June 28, many users reported that "site B is down", and the entry subsequently became a hot search topic. Users reported that “Zhuifan kept prompting that the video content failed to be obtained” and “the display page failed to load, are you the same?” “Kanfankan failed to load halfway through, I thought there was something wrong with my network.”
The issue lasted for more than an hour before being resolved.
Tencent
In the early morning of March 29, a large number of netizens reported that WeChat, QQ and other social software owned by Tencent had malfunctions. Many functions of WeChat, including voice calling, account login, friend circle, and payment, cannot be used normally. Problems also occur with QQ file transfer, QQ space, QQ mailbox, etc.

Tencent customer service responded that due to a system failure, some users experienced abnormalities in WeChat payment-related functions and are currently undergoing emergency repairs. The security of user funds is not affected. After the fault is repaired, the use of related functions will return to normal.

The accident was caused by a failure of the cooling system in Guangzhou Telecom's computer room , and Tencent defined it as a company-level accident.
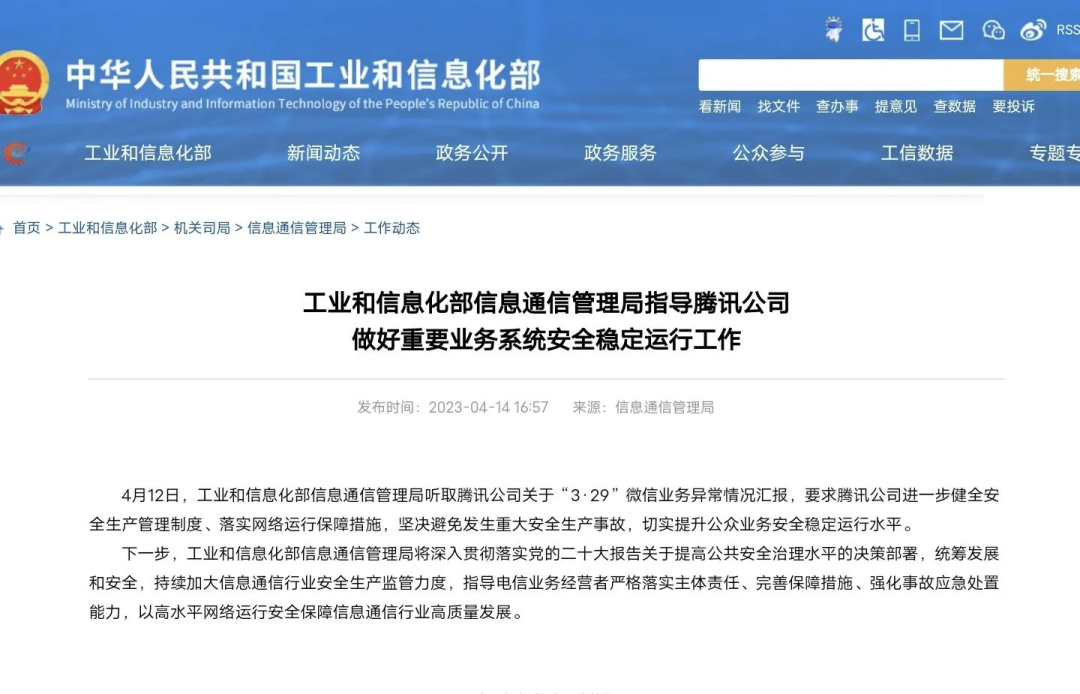
Afterwards, the Communications Administration Bureau of the Ministry of Industry and Information Technology interviewed relevant Tencent personnel regarding the WeChat "3.29 Incident", listened to the situation report, and required Tencent to further improve the safety production management system, implement network operation guarantee measures, resolutely avoid major safety production accidents, and effectively Improve the level of safe and stable operation of public services.
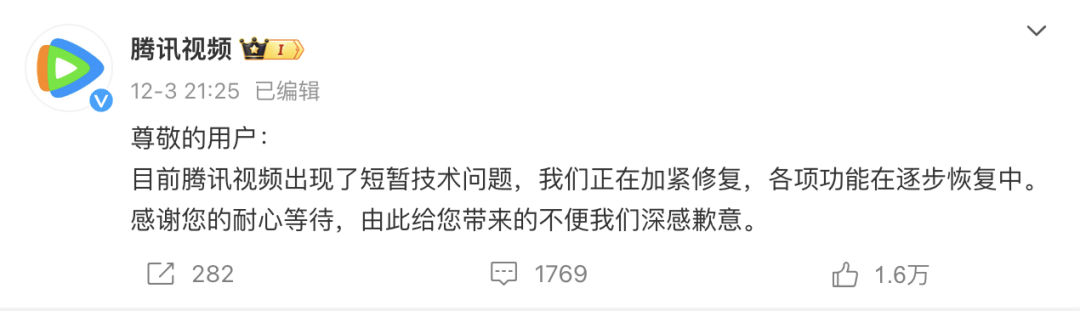
On December 3, Tencent Video suddenly had no members.
In response to this, Tencent Video’s official Weibo responded: Tencent Video is currently experiencing temporary technical problems. We are stepping up repairs and various functions are gradually being restored. Thank you for your patience and we apologize for any inconvenience this may cause you.
Vipshop
On March 29, “Vipshop collapsed” became a hot search topic on Weibo. Vipshop responded:
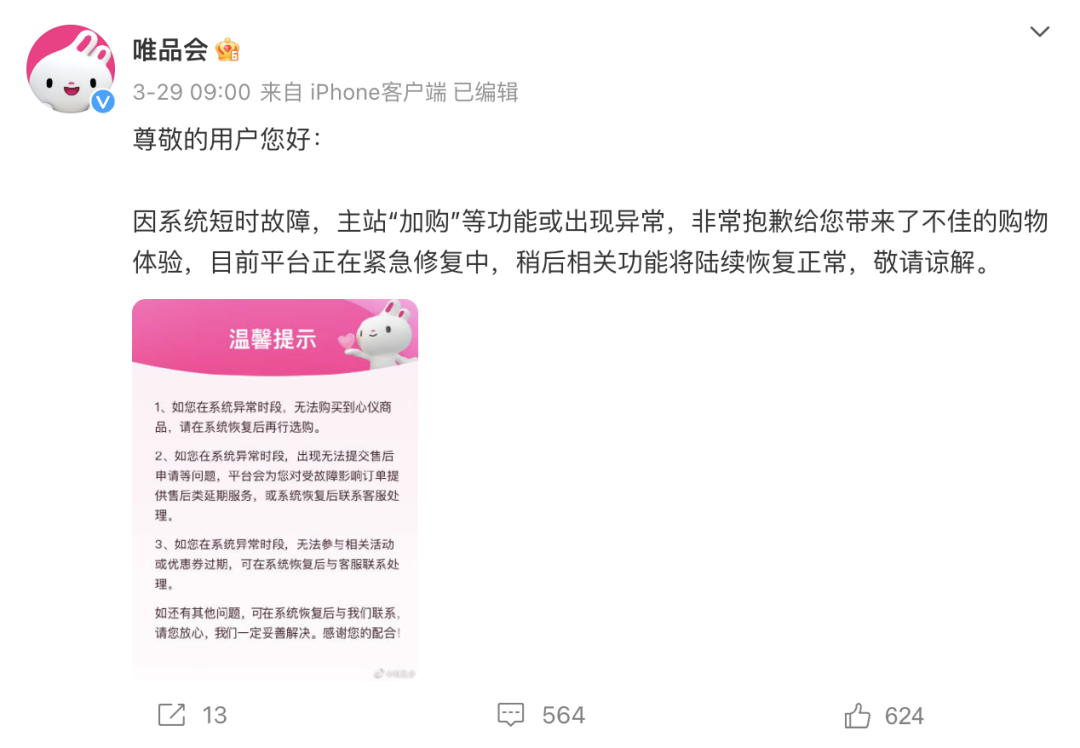
Afterwards, Vipshop issued a handling announcement, classifying the 329 computer room outage as a P0 level fault. Officials stated in the announcement that the major failure in the Nansha computer room lasted for 12 hours, causing the company's performance losses to exceed 100 million yuan and affecting more than 8 million customers. Vipshop stated that it has decided to deal with this incident seriously. The direct managers of the corresponding departments will bear the responsibility for the accident, and the person in charge of the basic platform department will be dismissed and handled accordingly.
Boss direct recruitment
On May 24, netizens reported that Boss direct employment collapsed. Later, Boss Direct Pin responded: When some users used the Boss Direct Pin PC version this morning, some functions experienced abnormalities. After emergency repairs, they have been restored.
On July 6, many users opened BOSS Direct Recruitment and found that "system service error" was displayed on the page and they could not switch identities correctly. Some netizens said that they were chatting with job seekers and were about to schedule an interview, but the result was that they collapsed. BOSS Zhipin also released a message on the same day, saying, "On the morning of July 6, the BOSS Zhipin APP experienced a short-term service abnormality. After repairs by the team, it has returned to normal. We deeply apologize for the inconvenience caused to users during this period. We will continue to optimize Service guarantee. Thank you all for your continued attention and support."
On September 15, "BOSS Direct Recruitment" suddenly crashed. Many users were unable to refresh the page, view new recruitment information, or even chat.
On social media, a self-proclaimed BOSS direct employee said that the Golden Nine and Silver Ten are the peak recruitment season. At 10:15:26 on September 15, 2023, online statistics showed that more than 47 million people were browsing the BOSS page. The server is currently overloaded. It is being maintained, and people looking for jobs are more anxious than those buying tickets for the National Day.
BOSS Zhipin responded that he noticed a screenshot posted online. The server crashed, it's true. It is true that technology needs to improve. The data transmitted online is false. Please don’t believe or spread rumors. According to the latest data, 43.6 million users use BOSS direct recruitment every month. "

Yuque
On October 23, an unprecedented P0-level incident occurred in Yuque , an online document editing and collaboration tool owned by Ant Financial , which caused the platform to be unable to be accessed and used normally, which lasted for nearly 8 hours (14:10 to 21:45)
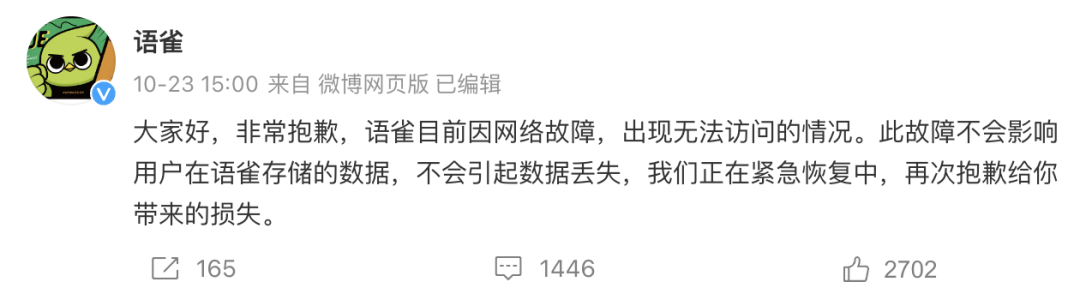
Afterwards, Yuque gave the cause and treatment process of the failure:
On the afternoon of October 23, when Service Yuque's data storage operation and maintenance team was performing an upgrade operation, due to a bug in the new operation and maintenance upgrade tool, the production environment storage server in East China was accidentally offline. Affected by this, Yuque's data service suffered a serious failure, causing widespread service interruption. In order to restore services as soon as possible, we and the data storage operation and maintenance team worked hard to restore the data. However, due to factors such as the recovery plan and data magnitude, the overall time took a long time. The specific process is as follows:
14:07 The data storage operation and maintenance team received an alarm from the monitoring system and determined that the reason was that the node machine was offline due to a new operation and maintenance tool bug during the storage upgrade;
14:15 Contact the hardware team to try to bring the offline machine back online;
15:00 It was confirmed that the storage system used an older machine type and could not be brought online directly. The recovery plan was immediately adjusted to restore storage data from the backup system.
15:10 Start building a new storage system and restoring data from backup. Due to the large amount of Yuque data, this process takes a long time
Data recovery was completed at 19:00; at the same time, in order to ensure data integrity, it took 2 hours to perform data verification after the recovery was completed;
The storage system passed the integrity check at 21 o'clock and started joint debugging with the Yuque team. Finally, all Yuque services were restored at 22 o'clock. All user data is not lost.
And improvement measures:
Through this failure, we deeply realized that as a document product that serves tens of millions of customers, Yuque should achieve more complete technical risk protection and high-availability architecture design, especially the "monitorable and reliable" for technical change operations. Systematized construction and process auditing of “grayscale, rollback”, upgrading from multi-copy disaster recovery in the same region to high availability capabilities in three centers in two places, designing sufficient data and system redundancy to achieve rapid recovery, and conducting regular disaster recovery Disaster emergency drills. Only in this way can the recovery speed in case of serious infrastructure failures be improved and the recurrence of such failures can be fundamentally avoided. To this end we have developed the following improvement measures:
Upgrade the hardware version and model to quickly go online after being offline. This measure has been completed in this fault repair;
The operation and maintenance team strengthens the quality assurance and testing of operation and maintenance tools to prevent such operation and maintenance bugs from happening again;
Reduce the grayscale range of operation and maintenance actions, increase the grayscale time, and detect bugs in advance;
Improve services from the architecture and high availability levels, and add remote disaster recovery of storage systems for Yuque.
And for individual users of Yuque, 6 months of membership service is provided as a gift.
Ali Cloud
At around 17:00 on November 12, Alibaba Cloud suddenly experienced an accident, causing problems in almost all Alibaba applications such as Alibaba Cloud, Taobao, Xianyu, and DingTalk. At around 19:20, after emergency processing by engineers, Alibaba's Taobao, DingTalk, Alibaba Cloud and other applications have been fully restored.

According to statistics, the impact of this anomaly involves more than 100 products including API gateways, video on demand, and operation and maintenance event centers, and 25 regions including Beijing, Silicon Valley, and London are affected.
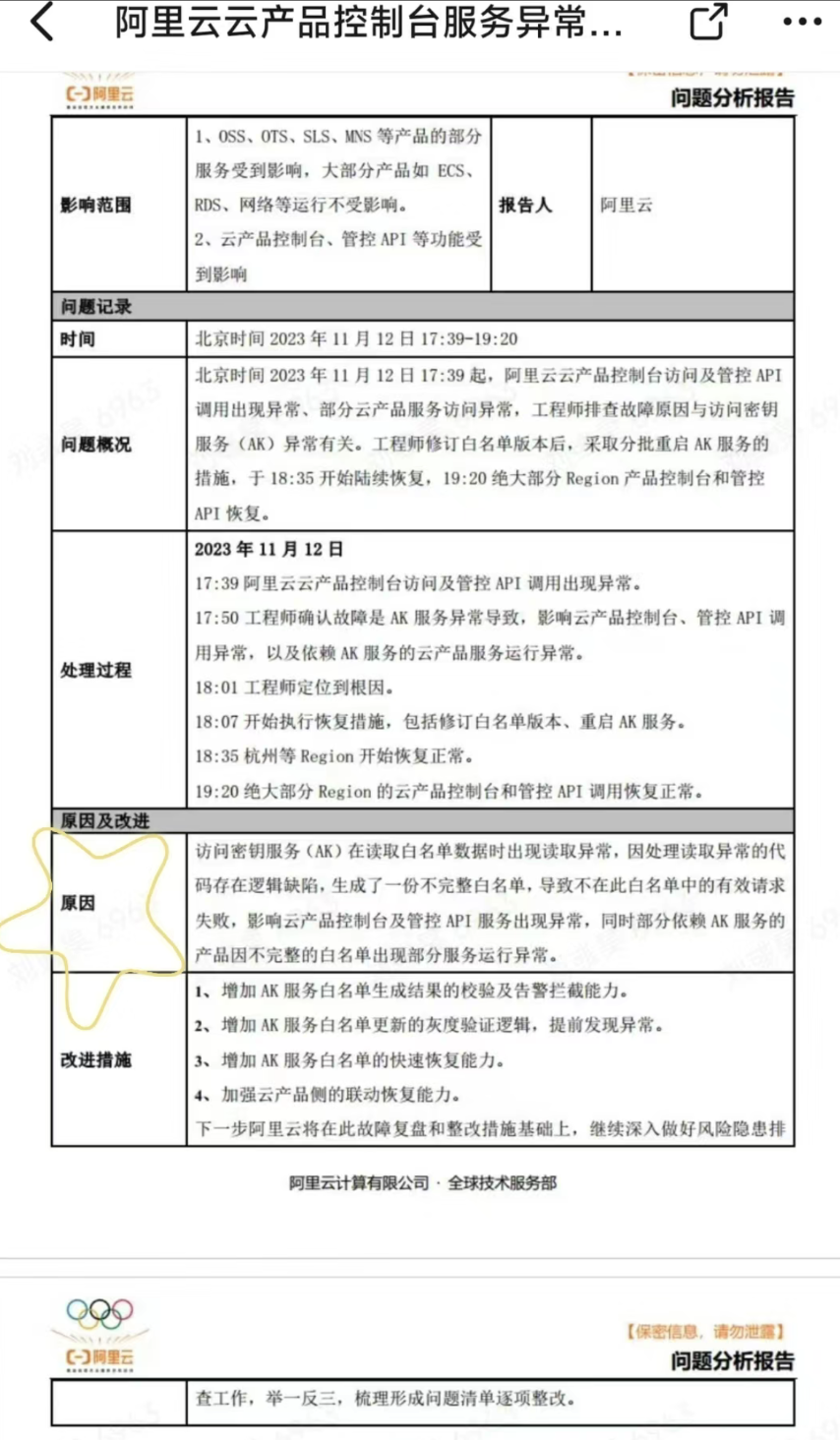
Afterwards, Alibaba Cloud did not announce the cause of the accident. However, there is an accident report circulating on the Internet for reference only:
Didi
On the evening of November 27, Didi Chuxing experienced a system crash. It was repaired on the 28th and the crash lasted for 12 hours. On November 29, Didi released an apology statement for this extremely long system failure. Preliminary investigation results show that the cause of the accident was a failure of the underlying system software and was not an "attack" transmitted over the Internet.
When the accident occurred, Didi users in Shanghai, Beijing, Guangzhou and other places reported that the Didi Chuxing APP could not be used and the map could not be loaded. Some netizens said that after using Didi to call a ride-hailing app, the app suddenly became unavailable and the driver could not find the passenger. An online ride-hailing driver said on social platforms that while on the way to deliver passengers, the navigation was unavailable and the map could not be loaded.
Himalayas
On December 19, many netizens reported that the Ximalaya App crashed and could not be used or listened to programs normally. Subsequently, Ximalaya's official blog issued an apology, saying that it has been urgently repaired and will not affect users' membership and other rights.
Chatgpt
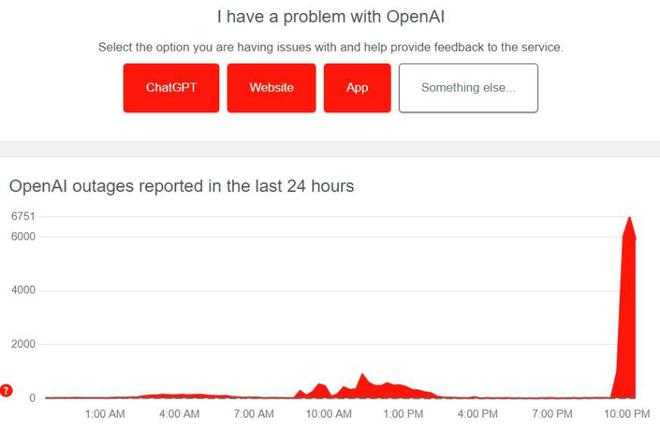
Starting at 22:00 on November 8, many netizens reported that OpenAI’s ChatGPT, including the API, could not be used normally. The OpenAI outage lasted approximately 100 minutes.
Afterwards, OpenAI also characterized this failure as a "Major Outage." OpenAI said it had discovered an issue that caused a high error rate in ChatGPT and API and was working to resolve it. Until 23:33, OpenAI stated that it had determined and implemented the repair plan, and the service gradually returned to normal.
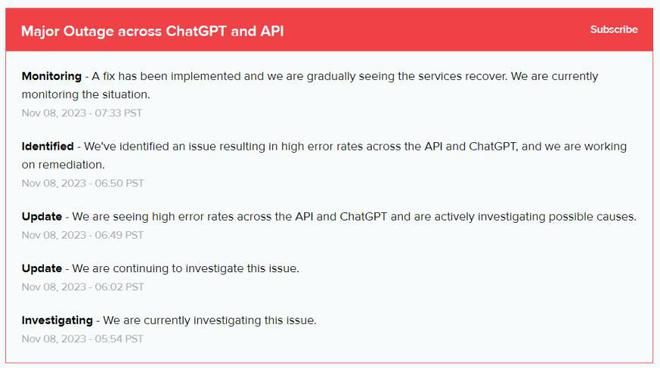
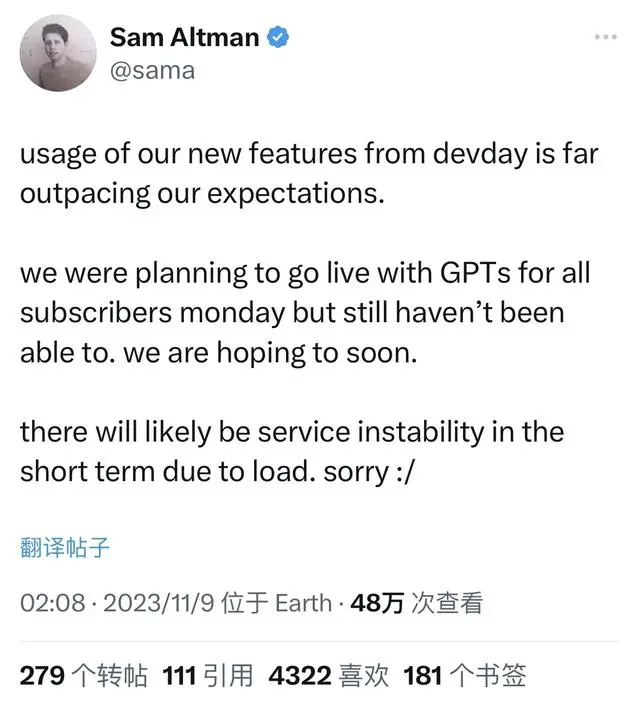
OpenAI CEO Altman said that the use of new features at devday (developer conference) far exceeded expectations. The company originally planned to enable GPT for all subscribers on Monday, but it still failed to materialize. Due to load reasons, service instability may occur in the short term.
X
On December 21, the well-known foreign social platform X (formerly Twitter) suffered a sudden crash. Many users reported that they could not load pages, browse profiles, view fan lists and other operations normally, and the social platform was almost paralyzed.
This is the second large-scale outage of the X platform this year. Back in March this year, the platform experienced a global outage. Since the $44 billion acquisition, Musk has laid off nearly 80% of its workforce, including many engineers responsible for repairing and preventing service interruptions.
