In the last issue, we shared the article "The Mystery of the ChatGPT Dataset". From the perspective of the model, according to six categories (Wikipedia, books, journals, Reddit links, Common Crawl, others), we analyzed and sorted out the data from 2018 to early 2022 . Details of all training data set domains, token numbers, etc. related to GPT-1 to Gopher's modern large language model.
Today, we continue to use these 6 major categories as the context, cut in from the perspective of public data sets, and sort out the data resources that have been put on the shelves of OpenDataLab and can be used for pre-training of large language models, instruction fine-tuning and other categories corresponding to different categories, hoping to save you Part data preparation time, and bring enlightenment.
Classification of large language model datasets:
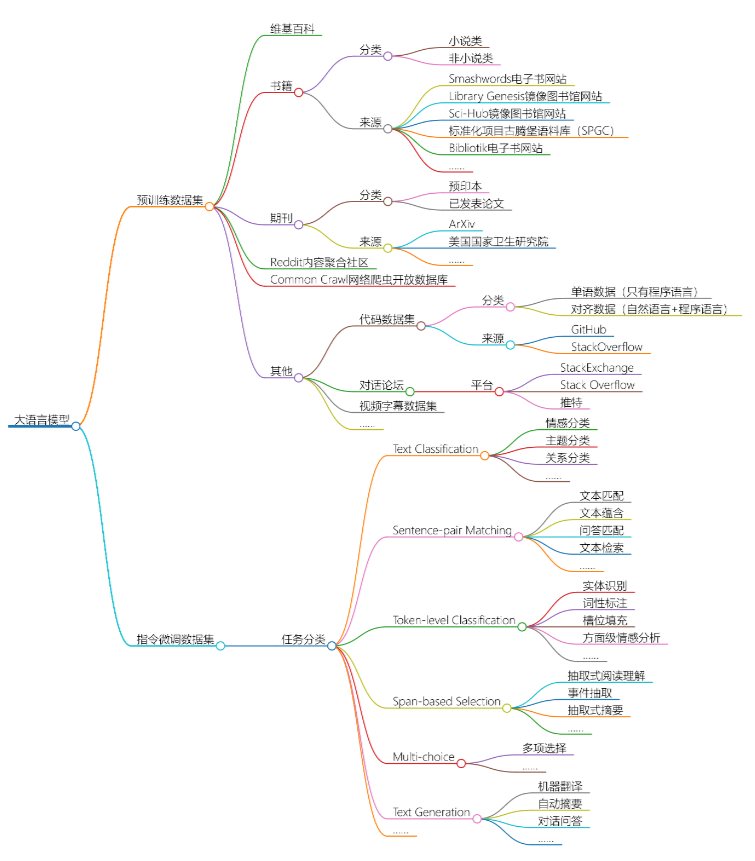
Classification reference: "ChatGPT Dataset Mystery" and network collation
1. Wikipedia class
No.1
Identifying Machine-Paraphrased Plagiarism
● Publisher : University of Wuppertal, Germany · Mendel University Brno
● Release date : 2021
● Brief :
This dataset is used to train and evaluate models for detecting machine-interpreted text. The training set contains 200,767 segments (98,282 original, 102,485 paraphrased) extracted from 8,024 Wikipedia (English) articles (4,012 original, 4,012 paraphrased using the SpinBot API). The test set is divided into 3 subsets: one from preprints of arXiv research papers, one from dissertations, and one from Wikipedia articles. In addition, different Marchine-paraphrasing methods are used.
● Download address :
https://opendatalab.org.cn/Identifying_Machine-Paraphrased_etc
No.2
Benchmark for Neural Paraphrase Detection
● Publisher : University of Wuppertal, Germany
● Release Date : 2021
● Introduction :
This is a benchmark for neural paraphrase detection to distinguish original content from machine-generated content. Training: 1,474,230 aligned paragraphs extracted from 4,012 (English) Wikipedia articles (98,282 original paragraphs, 1,375,948 paragraphs paraphrased with 3 models and 5 hyperparameter configurations, 98,282 each).
● Download address :
https://opendatalab.org.cn/Benchmark_for_Neural_Paraphrase_etc
No.3
NatCat
● Release date : 2021
● Introduction :
A general text classification dataset (NatCat) from three online sources: Wikipedia, Reddit, and Stack Exchange. These datasets consist of manually curated document-category pairs derived from natural occurrences in communities.
● Download link :
https://opendatalab.org.cn/NatCat
No.4
Quoref
● Publisher : Allen Institute for Artificial Intelligence · University of Washington
● Release time : 2019
● Introduction :
Quoref is a QA dataset for testing the coreference reasoning ability of reading comprehension systems. On this span selection benchmark containing 24K questions in 4.7K passages from Wikipedia, the system must resolve hard coreferences before it can select an appropriate span within a passage to answer the question.
● Download link :
https://opendatalab.com/Quoref
No.5
QuAC (Question Answering in Context)
● Published by : Allen Institute for Artificial Intelligence · University of Washington · Stanford University · University of Massachusetts Amherst
● Release time : 2018
● Introduction :
Contextual Question Answering is a large-scale dataset consisting of approximately 14K crowdsourced question answering conversations and a total of 98K question answering pairs. Data examples include an interactive conversation between two crowdworkers: (1) a student who asks a series of free-form questions to learn as much as possible about hidden Wikipedia text, and (2) a student who answers the questions by providing a short excerpt. The teacher (spanning) comes from the text.
● Download address :
https://opendatalab.org.cn/QuAC
No.6
TriviaQA
● Publisher : Allen Institute for Artificial Intelligence, University of Washington
● Release time : 2017
● Introduction :
TriviaQA is a realistic text-based question answering dataset consisting of 950K question-answer pairs in 662K documents from Wikipedia and the web. This dataset is more challenging than standard QA benchmark datasets such as Stanford Question Answering Dataset (SQuAD), because the answers to questions may not be directly obtained by span prediction, and the context is very long. The TriviaQA dataset consists of human-verified and machine-generated QA subsets.
● Download link :
https://opendatalab.com/TriviaQA
No.7
WikiQA (Wikipedia open-domain Question Answering)
● Publisher : Microsoft Research
● Release time : 2015
● Introduction :
The WikiQA corpus is a set of publicly available question and sentence pairs collected and annotated for the study of open-domain question answering. In order to reflect the real information needs of general users, the Bing query log is used as the source of the problem. Each question links to a Wikipedia page that may have an answer. Since the summary section of a Wikipedia page provides the basic and often most important information on the topic, the sentences in this section are used as candidate answers. The corpus includes 3,047 questions and 29,258 sentences, of which 1,473 sentences are labeled as answer sentences to the corresponding questions.
● Download address :
https://opendatalab.com/WikiQA
2. Books
No.8
The Pile
● Publisher : EleutherAI
● Release time : 2020
● Introduction :
The Pile is an 825 GiB diverse open-source language modeling dataset composed of 22 smaller high-quality datasets assembled together.
● Download link :
https://opendatalab.com/The_Pile
No.9
BookCorpus
● Publisher : University of Toronto MIT
● Release time : 2015
● Introduction :
BookCorpus is a massive collection of free fiction books by unpublished authors, containing 11,038 books (~74m sentences and 1g words) across 16 different sub-genres (eg, romance, history, adventure, etc.).
● Download address :
https://opendatalab.org.cn/BookCorpus
No.10
EXEQ-300k
● Publisher : Peking University · Pennsylvania State University · Sun Yat-Sen University
● Release time : 2020
● Introduction :
The EXEQ-300k dataset contains 290,479 detailed questions with corresponding math titles from Math Stack Exchange. This dataset can be used to generate concise math captions from detailed math problems.
● Download address :
https://opendatalab.org.cn/EXEQ-300k
3. Periodicals
No.11
Pubmed
● Published by : University of Maryland
● Release time : 2008
● Introduction :
The Pubmed dataset contains 19717 diabetes-related scientific publications from the PubMed database, classified into one of three categories. The citation network consists of 44338 links. Each publication in the dataset is described by a TF/IDF weighted word vector from a dictionary consisting of 500 unique words.
● Download link :
https://opendatalab.org.cn/Pubmed
No.12
PubMed Paper Reading Dataset
● Publisher : University of Illinois at Urbana-Champaign · Didi Lab · Rensselaer Polytechnic Institute · University of North Carolina at Chapel Hill · University of Washington
● Release time : 2019
● Introduction :
This dataset collects 14,857 entities, 133 relations, and entities corresponding to tokenized text from PubMed. It contains 875,698 training pairs, 109,462 development pairs and 109,462 test pairs.
● Download link :
https://opendatalab.org.cn/PubMed_Paper_Reading_Dataset
No.13
PubMed RCT (PubMed 200k RCT)
● Published by : Adobe Research MIT
● Release time : 2017
● Introduction :
PubMed 200k RCT is a new dataset based on PubMed for sequential sentence classification. The dataset consists of approximately 200,000 abstracts of randomized controlled trials totaling 2.3 million sentences. Each sentence of each abstract is labeled with one of the following categories for its role in the abstract: background, objectives, methods, results, or conclusion. The purpose of publishing this dataset is twofold. First, most datasets for sequential short text classification (i.e. classifying short texts that appear in sequences) are small: the authors hope that the release of a new large dataset will help develop more accurate algorithm. Second, from an applied perspective, researchers need better tools to efficiently browse the literature. Automatically categorizing each sentence in an abstract will help researchers read abstracts more efficiently, especially in fields where abstracts can be long, such as medicine.
● Download address :
https://opendatalab.org.cn/PubMed_RCT
No.14
MedHop
● Published by : University College London Bloomsbury AI
● Release time : 2018
● Introduction :
In the same format as WikiHop, the MedHop dataset is based on abstracts of research papers in PubMed, and queries are about interactions between drug pairs. The correct answer must be deduced by combining information from the sequence of reactions of the drug and the protein.
● Download address :
https://opendatalab.org.cn/MedHop
No.15
ArxivPapers
● Published by : Facebook · University College London · DeepMind
● Release time : 2020
● Introduction :
The ArxivPapers dataset is a collection of over 104K unlabeled papers related to machine learning published on arXiv.org between 2007 and 2020. The dataset includes approximately 94K papers (LaTeX source code is available) in a structured form where papers are divided into title, abstract, sections, paragraphs and references. Additionally, the dataset contains over 277K tables extracted from LaTeX papers. Due to the dissertation license, the dataset is released as metadata and an open-source pipeline can be used to obtain and transform the dissertation.
● Download link :
https://opendatalab.org.cn/ArxivPapers
No.16
unarXive
● Publisher : Karlsruhe Institute of Technology
● Release time : 2020
● Profile :
A collection of scholarly datasets containing the full text of publications, annotated in-text citations, and links to metadata. The unarXive dataset contains 1 million plain-text papers 63 million citation contexts 39 million reference strings 16 million connected citation web data from all LaTeX sources on arXiv between 1991 and 2020/07, so higher quality than generated data from PDF files. Additionally, since all citing papers are available in full text, citation contexts of any size can be extracted. Typical uses of the dataset are methods in citation recommendation citation context analysis reference string parsing the code to generate the dataset is publicly available.
● Download address :
https://opendatalab.org.cn/unarXive
No.17
arXiv Summarization Dataset
● Published by : Georgetown University · Adobe Research
● Release time : 2018
● Introduction :
This is a dataset for evaluating abstraction methods on research papers.
● Download address :
https://opendatalab.org.cn/arXiv_Summarization_Dataset
No.18
SCICAP
● Published by : Pennsylvania State University
● Release date : 2021
● Introduction :
SciCap is a large-scale graphics subtitle dataset based on computer science arXiv papers, published in 2010 and published in 2020. SCICAP contains over 416k graphs focused on one dominant graph type - graph graphs, extracted from over 290,000 papers.
● Download link :
https://opendatalab.org.cn/SCICAP
No.19
MathMLben (Formula semantics benchmark)
● Publisher : University of Konstanz National Institute of Standards and Technology
● Release time : 2017
● Introduction :
MathMLben is a benchmark of evaluation tools for mathematical format conversion (LaTeX ↔ MathML ↔ CAS). It contains tasks/datasets from NTCIR 11/12 arXiv and Wikipedia, the NIST Digital Library of Mathematical Functions (DLMF) and a system for formula and identifier name recommendation using AnnoMathTeX (https://annomathtex.wmflabs.org).
● Download address :
https://opendatalab.org.cn/MathMLben
4. Reddit content aggregation community class
No.20
OpenWebText
● Publisher : University of Washington · Facebook AI Research
● Release time : 2019
● Introduction :
OpenWebText is an open source re-engineering of the WebText corpus. This text is web content extracted from a URL shared on Reddit with at least 3 upvotes (38GB).
● Download address :
https://opendatalab.org.cn/OpenWebText
5. Common Crawl web crawler open database
No.21
C4 (Colossal Clean Crawled Corpus)
● Publisher : Google Research
● Release time : 2020
● Introduction :
C4 is a huge, clean version of Common Crawl's corpus of web crawlers. It is based on the Common Crawl dataset: https://commoncrawl.org. It is used to train the T5 text-to-text Transformer model. The dataset can be downloaded in preprocessed form from allennlp.
● Download link :
https://opendatalab.com/C4
No.22
Common Crawl
● Publisher : French National Institute of Informatics and Automation · Sorbonne University
● Release time : 2019
● Introduction :
The Common Crawl Corpus contains petabytes of data collected during 12 years of web crawling. The corpus contains raw web page data, metadata extraction, and text extraction. Common Crawl data is stored on Amazon Web Services' public datasets and on multiple academic clouds around the world.
● Download address :
https://opendatalab.org.cn/Common_Crawl
6. Other categories
code dataset
No.23
CodeSearchNet
● Publisher : Microsoft Research GitHub
● Release time : 2020
● Introduction :
The CodeSearchNet Corpus is a large function dataset containing relevant documentation written in Go, Java, JavaScript, PHP, Python, and Ruby from open source projects on GitHub. The CodeSearchNet corpus includes: * 6 million methods in total * 2 million of which have associated documentation (docstrings, JavaDoc, etc.) * Metadata indicating where the data was originally found (such as repository or line number).
● Download address :
https://opendatalab.org.cn/CodeSearchNet
No.24
StaQC
● Published by : Ohio State University · University of Washington · Fujitsu Research Institute
● Release time : 2018
● Introduction :
StaQC (Stack Overflow Question Code Pairs) is by far the largest dataset with approximately 148K Python and 120K SQL domain question code pairs, automatically mined from Stack Overflow using the Bi-View Hierarchical Neural Network.
● Download address :
https://opendatalab.org.cn/StaQC
No.25
CodeExp
● Publisher : Beihang University·Microsoft Research·University of Toronto
● Release date : 2022
● Introduction :
We provide a python code-docstring corpus, CodeExp, which contains (1) a large partition of 2.3 million raw code-docstring pairs, (2) a partition of medium 158,000 pairs from the raw corpus using learned filters, and (3) partition annotations with strictly human 13,000 pairs. Our data collection process leverages annotation models learned from humans to automatically filter high-quality annotated code-docstring pairs from the original GitHub dataset.
● Download address :
https://opendatalab.org.cn/CodeExp
No.26
ETH Py150 Open
● Publisher : Indian Institute of Science · Google AI Research
● Release time : 2020
● Introduction :
A large-scale deduplicated corpus of 7.4 million Python files from GitHub.
● Download address :
https://opendatalab.org.cn/ETH_Py150_Open
Forum Dataset
No.27
Federated Stack Overflow
● Publisher : Google Research
● Release date : 2022
● Brief :
The data consists of the text of all questions and answers. The body is parsed into sentences, and any users with less than 100 sentences are dropped from the data. Minimal preprocessing is done as follows: lowercase text, escape HTML symbols, remove non-ASCII symbols, separate punctuation marks as separate tokens (except apostrophes and hyphens), remove redundant whitespace, and replace URLS with special tokens. Additionally, the following metadata is provided: Date Created Question Title Question Label Question Score Type ("Question" or "Answer").
● Download address :
https://opendatalab.org.cn/Federated_Stack_Overflow
No.28
QUASAR (QUestion Answering by Search And Reading)
● Published by : Carnegie Mellon University
● Release time : 2017
● Introduction :
Question Answering on Search and Reading (QUASAR) is a large-scale dataset consisting of QUASAR-S and QUASAR-T. Each of these datasets is designed to focus on evaluating systems designed to understand natural language queries, large corpora of text, and extract answers to questions from the corpus. Specifically, QUASAR-S consists of 37,012 fill-in-the-blank questions collected from the popular website Stack Overflow using entity labels. The QUASAR-T dataset contains 43,012 open-domain questions collected from various Internet resources. Candidate documents for each question in this dataset are retrieved from an Apache Lucene-based search engine built on top of the ClueWeb09 dataset.
● Download link :
https://opendatalab.org.cn/QUASAR
No.29
GIF Reply Dataset
● Published by : Carnegie Mellon University
● Release time : 2017
● Introduction :
The published GIF replies dataset contains 1,562,701 real text-GIF conversations on Twitter. In these conversations, 115,586 unique GIFs were used. Metadata, including OCR-extracted text, annotated labels, and object names, is also available for some of the GIFs in this dataset.
● Download address :
https://opendatalab.org.cn/GIF_Reply_Dataset
Video Caption Dataset
No.30
TVC (TV show Captions)
● Published by : University of North Carolina at Chapel Hill
● Release time : 2020
● Introduction :
TV Show Caption is a large-scale multimodal captioning dataset, containing 261,490 caption descriptions and 108,965 short video clips. TVC is unique because its subtitles can also describe dialogue/subtitles, while subtitles in other datasets only describe visual content.
● Download link :
https://opendatalab.org.cn/TVC
The above is this sharing, because the space is limited, for more data sets, please visit the official website of OpenDataLab: https://opendatalab.org.cn/