Pre-training of large language models [2]: GPT, GPT2, GPT3, GPT3.5, GPT4 related theoretical knowledge and model implementation, model application and detailed explanation of the differences between versions
1. GPT model
1.1 Introduction to GPT model
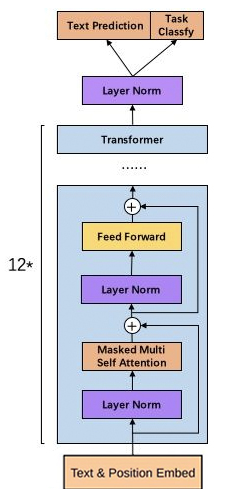
In natural language processing problems, a large amount of unlabeled data can be downloaded from the Internet, but there are very few labeled data for specific problems. GPT is a semi-supervised learning method, which is dedicated to using a large amount of unlabeled data to let the model learn " Common sense" to alleviate the problem of insufficient labeling information. The specific method is to pretrain the model Pretrain with unlabeled data before training Fine-tune for labeled data, and ensure that the two trainings have the same network structure. The bottom layer of GPT is also based on the Transformer model, which is different from the Transformer model for translation tasks: it only uses multiple Deocder layers.
The figure below shows the GPT model structure and how to use the model to adapt to the problems of multi-category, textual entailment, similarity, and multiple choice without modifying the main structure of the model.
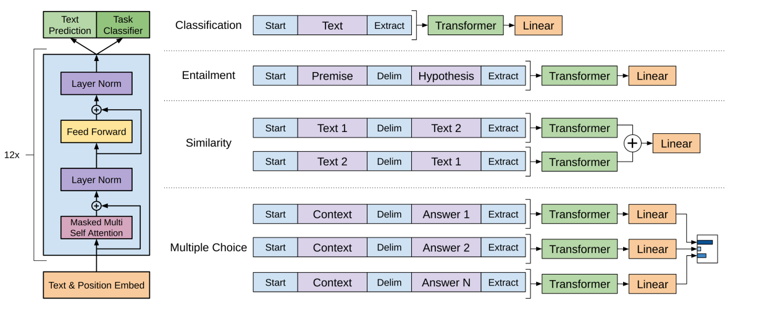
The left side shows the 12-layer Transformer Decoder model, which is consistent with the Transformer basic model. The right side shows that in Fine-Tune, different tasks are first combined into the Transformer model through data combination, and then a fully connected layer (Linear) is added after the output data of the basic model to adapt to the format of the labeled data.
For example, the simplest classification task, such as the emotional color recognition problem for sentences, only involves a single sentence, and the result is a binary classification. Therefore, only the sentence needs to be substituted, and a fully-connected layer can be added at the end; for judging the similarity problem, since there is no mutual relationship between the two sentences, the two sentences need to be connected in different order by adding delimiters, respectively Input the model, generate different hidden layer data and then substitute into the final fully connected layer.
1.2 Model Implementation
In the pre-training Pretrain part, use u to represent each token (word). When setting the window length to k and predicting the i-th word in the sentence, the k words before the i-th word are used. At the same time, according to the hyperparameter Θ, to predict what the i-th word is most likely to be. In short, previous words are used to predict subsequent words.
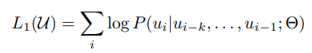
The specific method is to substitute into the Transformer model. The model in the following formula is composed of L groups of hidden layers. The initial data input to the hidden layer is the word code U multiplied by the word embedding parameter We plus the position parameter Wp; followed by L layers (as shown on the left side of the above figure) Transformer group) processing.
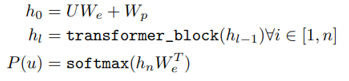
In the fine-tune part of supervised training, such as judging the emotional color of a sentence (two classification problems), the sentence contains m words x1...xm, and a fully connected layer is added to the model trained by pretain to learn the description Input the parameter Wy of the relationship between information x and target y, and finally predict the target y.
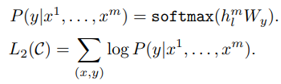
Taking into account L1 and L2 in the above formula, add the weight parameter λ to control its ratio to calculate L3, as the basis for optimization.
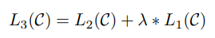
Compared with the basic Transformer, GPT has also made the following modifications:
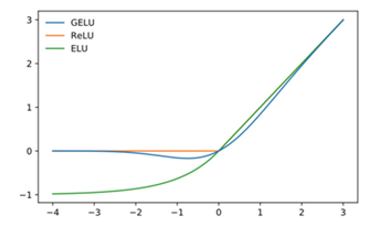
- Using GLUE (Gaussian Error Linear Unit) as the error function, GLUE can be regarded as an improved method of ReLU. ReLU converts data less than 1 into 0, and the part greater than 1 remains unchanged, while GELU slightly adjusts it, as shown in the figure below :
- Position encoding: The basic Transformer uses sine and cosine functions to construct position information, and the position information does not need to train corresponding parameters; while GPT uses absolute position information as encoding.
1.3 Model effect
GPT is modified based on Transformer, trained on a corpus of 800 million words, 12 Decoder layers, 12 attention heads, and a hidden layer dimension of 768.
GPT surpassed previous models in various evaluations of natural language reasoning, classification, question answering, and comparison of similarity. And it performs well from small data sets such as STS-B (about 5.7k training data instances) to large data sets (550k training data). Even through pre-training, some Zero-Shot tasks can be achieved. However, due to the low fit between unlabeled data and specific problems, it is slower to learn and requires more computing power.
1.4 Model application

GPT models can be used to generate natural language text. In practical applications, the GPT model can be applied to multiple scenarios, the following are some common application scenarios:
- Language generation: GPT models can be used to generate natural language texts, such as articles, dialogues, news, novels, etc. This application scenario can be applied to automatic writing, machine translation, intelligent customer service and other fields.
- Language understanding: GPT models can be used for natural language understanding, such as text classification, sentiment analysis, entity recognition, etc. This application scenario can be applied to search engines, advertising recommendations, public opinion monitoring and other fields.
- Dialogue system: GPT models can be used to build dialogue systems, such as intelligent customer service, chat robots, etc. This application scenario can be applied to customer service, entertainment and other fields.
- Language model: GPT model can be used to build language models, such as speech recognition, machine translation, etc. This application scenario can be applied to smart home, smart transportation and other fields.
In short, the GPT model can be applied in many fields, including natural language generation, natural language understanding, dialogue system, language model, etc. With the continuous development and application of artificial intelligence technology, the application scenarios of the GPT model will also continue to expand and deepen.
2. GPT2 model
GPT2 is a pre-trained language model released by Open AI. It has an amazing performance in text generation. The generated text exceeds people's expectations in terms of contextual coherence and emotional expression. As far as the model architecture is concerned, GPT-2 does not have a particularly novel architecture. GPT-2 continues to use the original one-way Transformer model used in GPT, and the purpose of GPT-2 is to take advantage of the one-way Transformer as much as possible. Make the function that the bidirectional Transformer used by BERT cannot achieve, that is, generate the contextual text through the above.
2.1 GPT2 model architecture
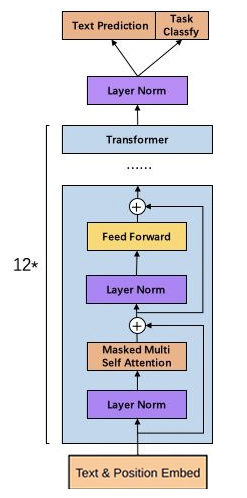
The structure of GPT-2 is similar to the GPT model, still using the one-way Transformer model, with only some local modifications: such as moving the normalization layer to the input position of the Block; adding a layer after the last self-attention block Normalization; increasing vocabulary, etc., GPT2 model structure diagram:

The Transformer decoder structure is as follows:

The GPT-2 model consists of the decoder part of the multi-layer unidirectional Transformer. It is essentially an autoregressive model, that is, after each new word is generated, the new word is added to the original input sentence as a new input sentence.
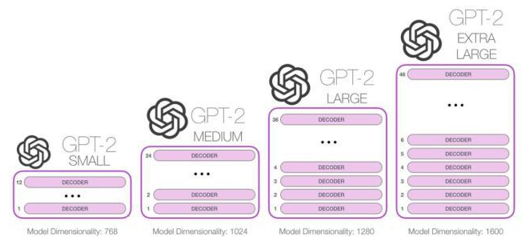
GPT-2 increases the number of Transformer stacked layers to 48 layers, the dimension of the hidden layer is 1600, and the number of parameters reaches 1.5 billion (Bert large is 340 million). "Small" has 12 floors, "Medium" has 24 floors, "Large" has 36 floors, and "King" has 48 floors. GPT-2 has trained 4 sets of models with different layers and word vector lengths, as shown in the figure:
GPT-2 removes the fine-tuning training: only the unsupervised pre-training stage, no longer fine-tuning modeling for different tasks, but does not define what tasks the model should do, the model will automatically identify what tasks need to be done . A more extensive and larger corpus composition data set is collected. The data set contains 8 million web pages with a size of 40G. What GPT2 needs is data with task information. A new NLP paradigm is proposed, emphasizing the training of high-capacity language models through more high-quality training data to complete downstream multi-tasks without supervision. Try to use a general language model to solve most of the existing NLP tasks.
2.2 Model application
The GPT-2 model is mainly used for natural language processing tasks such as:
-
Text generation: GPT-2 can learn large amounts of text data and generate articles, stories or poems similar to human writing.
-
Machine translation: GPT-2 can translate text in one language into text in another language, such as Chinese-English translation.
-
Sentiment Analysis: Using GPT-2 for sentiment analysis, you can judge whether the emotion expressed by a piece of text is positive, negative or neutral.
-
Text classification: GPT-2 can classify text into different categories, such as news classification, movie review classification, etc.
-
Question answering system: GPT-2 can answer questions posed by users and provide relevant information and solutions.
-
Dialogue system: GPT-2 can simulate human dialogue, interact with users, and answer questions from users.
2.3 Model Evaluation
-
advantage:
- Strong generation ability: GPT-2 has an excellent ability to generate text, and can generate coherent and smooth articles, stories and even code snippets.
- Contextual understanding: The model learns from large amounts of textual data to understand context and generate logically relevant responses.
- Multi-domain applications: GPT-2 has good applicability to tasks in multiple domains, including machine translation, summary generation, dialogue systems, etc.
- Availability of pre-trained models: Pre-trained models for GPT-2 have been released in the public domain and can be easily fine-tuned to suit specific task requirements.
- Diversity of language expression: GPT-2 can generate diverse language expressions, from formal to colloquial, humorous to serious, making the generated text more vivid and interesting.
-
shortcoming:
- Lack of common sense and factual knowledge: Although GPT-2 can generate coherent text, it has no common sense and factual knowledge of its own and is susceptible to false or misleading information.
- Vulnerabilities of adversarial examples: GPT-2 is vulnerable to adversarial examples, i.e. tricking a model with deliberately crafted inputs resulting in inaccurate or misleading outputs.
- Lack of creativity and initiative: GPT-2 is a statistical model based on a large amount of data, without real creativity and initiative, it can only generate text within the scope of existing knowledge.
- There are long-term dependency problems: GPT-2 may encounter long-term dependency problems when processing long texts, resulting in logically inconsistent or incoherent generated text.
- Poor interpretability: GPT-2 is a black-box model, and its decision-making process is difficult to explain, and cannot provide detailed reasoning or evidence support.
3. GPT3 model
GPT3 (Generative Pre-trained Transformer 3) is a natural language processing model developed by OpenAI, and is currently recognized as the originator of large language models. In the GPT family, the first generation of GPT was released in 2018 and contained 117 million parameters. GPT2, released in 2019, contains 1.5 billion parameters. And GPT3 has 175 billion parameters, which is more than 100 times that of its predecessor and more than 10 times that of similar programs. GPT3 uses the Transformer neural network structure in deep learning, and utilizes unsupervised pre-training technology, which can automatically process various natural language tasks, such as text generation, question answering, translation, etc.
GPT3 continues its own one-way language model training method, not only greatly increasing the model parameters, but also GPT3 mainly focuses on more general NLP models, GPT3 models in a series of benchmark tests and domain-specific natural language processing tasks (from language translation to news generation) ) to achieve state-of-the-art SOTA results. For all tasks, GPT3 does not perform any fine-tuning and only interacts with the model through text. Same as the GPT2 model architecture, as shown in the figure below:
However, compared with GPT-2, GPT-3's image generation function is more mature, and it can complete complete images based on incomplete image samples without fine-tuning. GPT-3 means that the leap from one generation to three generations has achieved two shifts:
- the turn from language to images;
- Solve problems with less domain data, even without fine-tuning steps.
3.1 GPT3 training strategy
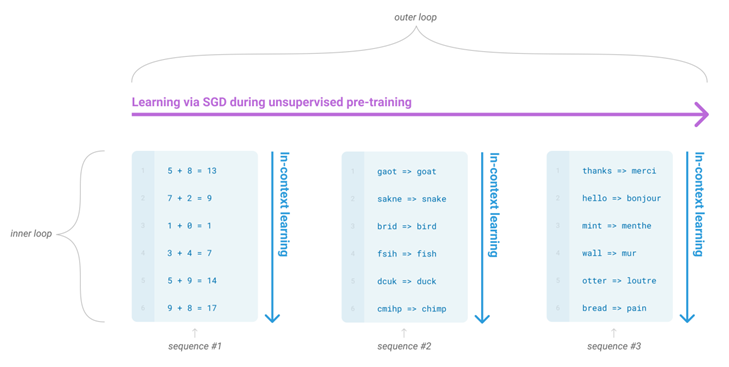
GPT3 uses in-context learning for training in downstream tasks. In-context learning: Given a few task examples or a task specification, the model should be able to complete other instances of the task by making simple predictions. Here are three contextual learning methods:
-
few-shot learning (no gradient propagation, some examples are also used as input and output models during prediction)
Definition: Allows input of several examples and a task description.
The following figure is an example:
-
One-shot learning (no gradient propagation, an example is also used as an input and output model when predicting)
definition: only one example and one task description are allowed to be input.
The following figure is an example:
-
Zero-shot learning (no gradient propagation)
definition: no examples are allowed to be input, only one task description is allowed. The
following figure is an example:
3.2 Model performance
GPT-3 performs better than language modeling datasets like LAMBADA and Penn Tree Bank in the few-shot / zero-shot setting. For other datasets, it cannot beat the state-of-the-art, but improves the zero-shot state-of-the-art performance.
GPT-3 also performs reasonably well on NLP tasks such as answering closed-book questions, pattern parsing, translation, etc., often outperforming the state-of-the-art, or on par with fine-tuned models. For most tasks, the model outperforms one-shot and zero-shot in the few-shot setting.
In addition to being evaluated on traditional NLP tasks, GPT-3 is also evaluated on comprehensive tasks such as arithmetic addition, word unscrambling, news generation, and learning and using new words. For these tasks, performance also increases with the number of parameters, and the model performs better in the few-shot setting than in the one-shot and zero-shot settings.
The figure below explains how to understand GPT-3 as meta learning. The model has learned many different tasks, which can be compared to the process of meta learning, so it has better generalization.
3.3 Limitations
While GPT-3 is capable of generating high-quality text, sometimes it starts to lose coherence when forming long sentences and repeating text sequences over and over.
Limitations of GPT-3 include complex and expensive model inference due to its heavy architecture, language and low interpretability of results produced by the model, and uncertainties about helping the model achieve its small amount of learned behavior.
3.4 Model application
GPT-3 is a very powerful language model that can be used in many different applications and domains:
-
Natural language generation: GPT-3 can be used to automatically generate various types of text such as articles, emails, product descriptions, etc.
-
Smart customer service: GPT-3 can be used to build chatbots that solve customer problems and provide assistance.
-
Writing Assistant: GPT-3 can suggest topics, paragraphs, and sentences, while automatically generating appropriate text based on user-entered data.
-
Language translation: GPT-3 can be used to translate text between different languages, thereby facilitating cross-cultural communication.
-
Automatic summarization: GPT-3 can be used to automatically extract the main information and focus of an article or document, helping users understand its content faster.
-
Virtual Assistants: GPT-3 can be used to build virtual assistants such as Siri or Alexa. It can understand the user's instructions and perform corresponding operations.
-
Personalized recommendations: GPT-3 can analyze users' historical behavior and preferences to provide them with personalized product and service recommendations.
-
Smart Search: GPT-3 can be used to improve search engine results, providing more accurate answers and suggestions.
-
Automated programming: GPT-3 can be used to automatically generate code and scripts, saving developers time and reducing errors.
-
Art creation: GPT-3's text generation capabilities can be used to create art forms such as poetry, novels, and screenplays, thereby providing novel literary experiences.
These are just a few of the application areas of GPT-3. With the development of technology, GPT-3 will be applied in more and more fields.
4. GPT3.5 large language model
GPT3.5 is a chat robot model developed by OpenAI, which can simulate human language behavior and interact naturally with users. Its name comes from the technology it uses - the GPT-3 architecture, which is the third generation of the generative language model. At the same time, the ChatGPT intelligent chat robot model was developed based on GPT3.5. GPT3.5 simulates human language behavior by using a large amount of training data, and generates text that humans can understand through grammatical and semantic analysis. It can provide accurate and appropriate responses based on context and context, and simulate a variety of emotions and tones. In this way, users can feel a more realistic and natural dialogue experience when interacting with the machine.
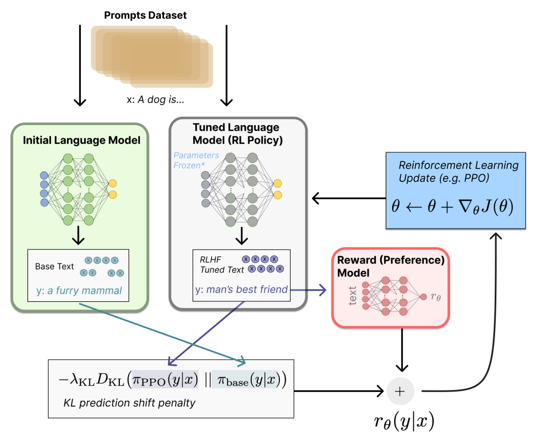
The GPT3.5 model has not changed much from the previous GPT-3. The main change is that the training strategy has changed and reinforcement learning has been used. The following figure is the GPT3.5 model structure diagram:
4.1 GPT3.5 training strategy
The GPT3.5 training strategy uses a reward model for training, and the goal of a reward model (RM) is to characterize whether the output of the model is good for humans. That is, input [prompt, text generated by the model] outputs a scalar number characterizing the quality of the text.

The reward model can be regarded as a discriminative language model, so it can be hot-started with a pre-trained language model, and then fine-tuned on the labeled corpus composed of [x=[prompt, model answer], y = human satisfaction], or Direct random initialization and direct training on the corpus.
4.2 Language Model Optimization Based on Reinforcement Learning (RL)
GPT3.5 models the fine-tuning task of the initial language model as a reinforcement learning (RL) problem, so basic elements such as policy, action space, and reward function need to be defined.
The strategy is based on the language model, receiving the prompt as input, and then outputting a series of texts (or the probability distribution of the text); and the action space is the arrangement and combination of all tokens in the vocabulary at all output positions (a single position usually has about 50k token candidates ); the observation space is the possible input token sequence (prompt), which is the permutation and combination of all tokens in the vocabulary at all input positions; and the reward function is the RM model trained based on the reward model, with some strategic constraints. reward calculation.
Calculate the reward (reward):
- Based on the previous pre-enriched data, the prompt input is sampled from it, and input to the initial language model and the language model (policy) currently being trained at the same time, and the output text y1 and y2 of the two models are obtained. Use the reward model RM to score y1 and y2 to judge who is better. The difference in scores can be used as a signal for training policy model parameters, and this signal is generally used to calculate the size of "reward/punishment" through KL divergence. If the score of y2 text is higher than that of y1, the reward will be greater, otherwise the penalty will be greater. This reward signal reflects the overall generation quality of the text.
- Through this reward, the model parameters can be updated according to the Proximal Policy Optimization (PPO) algorithm.
The flow of this stage is shown in the figure below:
4.3 Advantages and disadvantages of the model
As one of the important technologies in the field of natural language processing, GPT3.5 has very broad application prospects and development potential. Through dialogue generation technology, various application scenarios such as intelligent customer service, knowledge question answering system, and natural language generation can be realized, which greatly improves the efficiency and convenience of human-computer interaction. With the continuous development of computer technology and the continuous improvement of deep learning algorithms, the application field of GPT3.5 will also continue to expand and deepen, providing people with more advanced, efficient and intelligent natural language processing services. The image below shows the GPT3.5 output for two hints.

-
GPT3.5 advantages:
-
Versatility: GPT3.5 can answer various questions, provide creative inspiration, support various functions such as speech recognition, and can be applied in many fields, such as technical support, intelligent customer service, text generation, etc.
-
Natural language processing ability: GPT3.5 has strong natural language processing ability, which can simulate human dialogue, express thoughts and feelings, and provide more natural and smooth answers.
-
Multilingual support: GPT3.5 supports multiple languages to meet the language needs of different countries and regions.
-
Intelligent learning: GPT3.5 can continuously improve its expression ability and answer accuracy by learning a large amount of data, and has a certain intelligent learning ability.
-
Convenience: GPT3.5 can be used through third-party applications or websites, APIs provided by OpenAI, or on the official website of OpenAI. It is very convenient to use.
-
-
GPT3.5 Disadvantages:
-
There may be bias: Since GPT3.5 is obtained by learning from a large amount of data, there may be a problem of data bias. This may lead to bias in GPT3.5's responses to certain groups or viewpoints.
-
Lack of human touch: Although GPT3.5 can simulate human dialogue, it still lacks real emotion and humanity, and cannot perform complex thinking and emotional expression like real humans.
-
A large amount of data is required: In order for GPT3.5 to have a high answer accuracy and expressive ability, a large amount of data needs to be trained, which consumes a lot of time and resources.
-
There may be security risks: when using the GPT3.5 model, certain text or voice data needs to be input, which may lead to the risk of personal privacy disclosure.
-
5. GPT4 large language model
GPT-4 (Generative Pre-trained Transformer 4) is a large multimodal model that accepts image and text inputs and outputs text. GPT4 still adopts the Transformer model structure, which has the ability to process pictures. The model structure is no longer Decoder-only, but has Encoder to complete image encoding. As shown in the image below, GPT4 pointed out that the image of a large, outdated VGA port plugged into a small, modern smartphone charging port is absurd.

The GPT4 model has several times more parameters than the GPT3 model, and the number of model parameters may be close to trillions. In order to train GPT4, OpenAI uses Microsoft's Azure cloud computing service, which includes thousands of Nvidia A100 graphics processing units connected together or GPU. GPT4 proposes RBRMS (Rule-Based Reward Model) in the training strategy to deal with security issues.
5.1 GPT4 Model Security
GPT-4 has done a lot of work to ensure the safety of the model. First, more than 50 domain experts in different directions were hired to conduct confrontation tests and red team tests. Second, a rule-based reward model (Rule-Based Reward Models) was trained. , RBRMs)+RLHF to assist the training of the model.
RBRMS (Rule-Based Reward Models): The purpose is to refuse to generate harmful requests and not to reject harmless requests through the training of the correct reward-guided model.
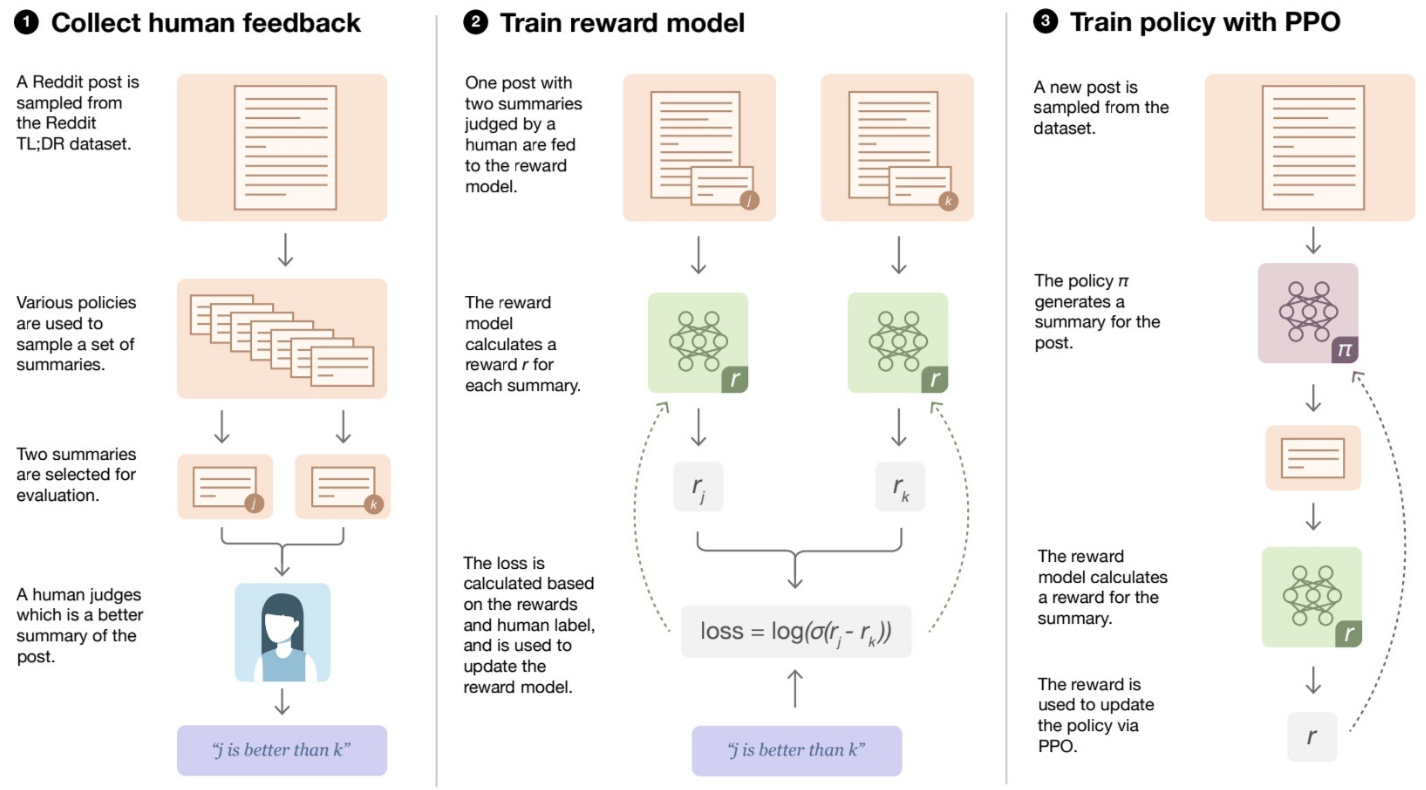
RLHF (Reinforcement Learning from Human Feedback): It uses the method of reinforcement learning to directly optimize the language model by using human feedback signals. The training process is shown in the figure below, which can be broken down into three core steps:
- Multiple strategies to generate samples and gather human feedback
- Train the Reward Model
- Train the reinforcement learning strategy and fine-tune the LM
5.2 Model comparison
-
Model scale: The scale of GPT-4 is larger than that of GPT-3, including more parameters and deeper network structure. As the scale increases, GPT-4 is able to capture more complex language patterns and semantic relationships, thereby improving the ability to understand and generate natural language.
-
Performance improvement: Due to the increased scale, GPT-4 shows higher performance than GPT-3 in most natural language processing tasks. This includes tasks such as reading comprehension, machine translation, summarization, question answering, and more. This means GPT-4 is better able to understand user input and generate more accurate and natural responses.
-
Training Data and Data Cleaning: GPT-4 uses a newer, richer training dataset. Compared with GPT-3, GPT-4 adopts stricter standards in data screening and cleaning to reduce misinformation, outdated content and bias in training data.
-
Fine-tuning ability: GPT-4 outperforms GPT-3 in terms of fine-tuning, which means that GPT-4 can adapt to specific tasks and domains using less labeled data. This makes the application of GPT-4 more flexible and efficient in personalized customization and specific scenarios.
-
Robustness and Interpretability: GPT-4 has made some progress in model robustness and interpretability. By introducing new techniques and methods, GPT-4 is able to better handle anomalous inputs, resist adversarial attacks, and provide interpretability about its predictions.
-
Optimize resource consumption: Although GPT-4 is larger in scale, OpenAI has adopted a series of optimization measures to reduce the resource consumption of the model in the training and inference stages. This allows GPT-4 to reduce computational cost and environmental impact while maintaining high performance.
-
Improvements in generation strategies: GPT-4 has been optimized in terms of generation strategies, improving the quality, variety, and controllability of output text. This means that GPT-4 is better able to meet users' needs and preferences when generating responses, while reducing the risk of generating irrelevant, repetitive, or inappropriate content.
-
Wider application fields: Thanks to performance improvements and optimization measures, GPT-4 has wider applicability in various application fields. In addition to traditional natural language processing tasks, GPT-4 can also handle more complex scenarios, such as multimodal tasks, knowledge map generation, etc.
-
Community support and development tools: With the launch of GPT-4, OpenAI also provides developers with richer support resources and tools, including APIs, SDKs, and pre-trained models. This makes it easier for developers to integrate and utilize GPT-4 in their own projects.
GPT-4 exhibits more common sense than previous models, as shown in the example below:

5.3 Application
Multimodal and interdisciplinary composition: GPT-4 not only demonstrates high proficiency in diverse domains such as literature, medicine, law, mathematics, physical science, and programming, but also fluently combines skills and concepts from multiple domains, showing Impressive ability to understand complex ideas. The following figure shows a comparison case of GPT-4 and ChatGPT on interdisciplinary tasks:

Code generation: GPT-4 is capable of coding at a very high level, whether writing code from instructions or understanding existing code, and can handle a wide range of coding tasks, from coding challenges to real-world applications, from low-level assembly to high-level frameworks , from simple data structures to complex programs, can also reason about the execution of code, simulate the effects of instructions, and interpret the results in natural language, and even execute pseudocode, which requires explaining non- Formal and vague expressions. The following figure shows a case of GPT-4 executing Python code:

The application scenarios of GPT4 in various fields have brought innovation to human beings. In addition to the above application fields, there are the following application fields:
-
Content creation and editing:
GPT-4's excellent performance in text generation provides strong support for creators. From writing soft articles, blog posts to book creation, GPT-4 is able to generate high-quality content according to user needs. At the same time, GPT-4 also has intelligent error correction and editing functions, which can help users quickly optimize text and improve work efficiency. -
Language translation:
With the deep learning technology of GPT-4, the field of language translation can realize real-time and accurate translation services. GPT-4 supports translation between multiple languages, providing a convenient language communication bridge for international exchanges and cooperation. -
Customer service and support:
More and more companies have begun to apply GPT-4 to online customer service systems to achieve intelligent and efficient user services. GPT-4 can quickly generate accurate and professional answers based on user questions, greatly improving customer satisfaction and customer service efficiency. -
Smart education:
GPT-4 has broad application prospects in the field of education. The AI tutoring system can provide students with personalized learning suggestions and Q&A services. In addition, GPT-4 can also be used to write educational resources such as teaching materials and lesson plans, and share the workload for teachers. -
Game development:
GPT-4 also plays an important role in the field of games. Developers can use GPT-4 to generate various game scenes, character dialogues and plot designs to create rich and unique game experiences for players. -
Voice assistants:
Voice assistants have become an integral part of people's daily lives. GPT-4 uses natural language processing technology to enable voice assistants to better understand the needs of users and provide more precise responses to meet people's needs in life and work. -
Data analysis and visualization:
GPT-4 can be applied in the field of data analysis to help companies and individuals discover potential value through deep mining of large amounts of data. At the same time, GPT-4 can also generate clear and easy-to-understand visual charts, making the data analysis results more intuitive and easier to understand. -
Legal consultation:
With the knowledge reserve and intelligent reasoning ability of GPT-4, users can obtain professional answers and suggestions on legal issues. This will greatly reduce the cost and time investment of people in legal advice. -
Medical field:
The application of GPT-4 in the medical field is also receiving increasing attention. AI models can assist doctors in case analysis, diagnostic recommendations, etc., improving the accuracy and efficiency of medical services. In addition, GPT-4 can also provide patients with health consultation and popular science knowledge, and improve public health awareness. -
Artificial intelligence ethics and regulation:
With the popularization of AI technologies such as GPT-4, issues of artificial intelligence ethics and regulation have become increasingly prominent. GPT-4 can help relevant institutions research and formulate corresponding policies and norms to ensure the development of AI technology in a compliant and safe environment.