Table of contents
3.2.1 Scaled version of dot product attention
3.2.3 Application of Attention in the model
3.3 Position-based feed-forward network
1. Article contribution
The article proposes a network structure transformer based entirely on the attention mechanism to deal with sequence-related problems. Unlike the past, the structure of CNN and RNN is not used, and the loop layer in the encoder-decoder is replaced by a multi-head attention mechanism, and Ability to implement parallel operations to improve model efficiency.
2. Introduction
Mainstream sequence transduction models are based on complex recurrent neural networks or convolutional neural networks that contain an encoder and a decoder. The best performing models also connect the encoder and decoder through an attention mechanism. This paper proposes a new simple network architecture Transformer, based only on the attention mechanism and completely avoiding loops and convolutions. Experiments have shown that the model can achieve better performance and the training time is shorter. At the same time, this model structure can avoid loops and completely rely on the attention mechanism to draw the global dependencies between input and output, which is easy to parallelize.
3. Model Architecture
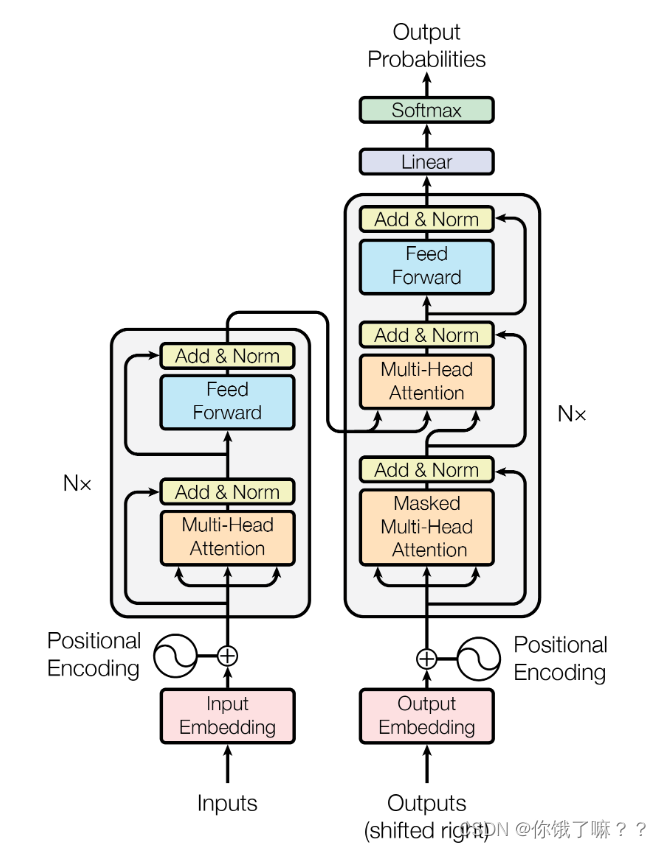
Most neural sequence transduction models have an encoder-decoder structure. Here, the encoder maps a symbolic input sequence (x1,...,xn) to a continuous representation z = (z1,...,zn). From z, the decoder generates an output sequence (y1,...,ym) of symbols, one element at a time. At each step, the model is autoregressive [10], using previously generated symbols as additional input when generating the next one.
Transformer follows this overall architecture, both encoder and decoder use self-attention stacking and point-wise, fully connected layers.
3.1 Encoder and decoder stack
3.1.1 Encoder
The encoder is stacked with N = 6 identical layers. Each layer has two sublayers. The first sublayer is a multi-head self-attention mechanism, and the second sublayer is a simple, positionally fully connected feed-forward network. We then employ a residual connection for each sublayer, followed by layer normalization. That is, the output of each sublayer is LayerNorm(x + Sublayer(x)), where Sublayer(x) is a function implemented by the sublayer itself. To facilitate these residual connections, all sublayers in the model, as well as embedding layers, produce output dimensions of dmodel = 512.
3.1.2 Decoder
The decoder is also stacked with N = 6 identical layers. In addition to the two sublayers in each encoder layer, the decoder inserts a third sublayer that performs multi-head attention on the output of the encoder stack. Similar to the encoder, a residual connection is employed at each sublayer followed by layer normalization. We also modify the self-attention sublayer in the decoder stack to prevent positions from paying attention to later positions. This combination of masks offsets the output embedding by one position, ensuring that a prediction for position i can only rely on known outputs smaller than i.
3.2 Attention
The Attention function maps a query and a set of key-value pairs to an output, where the query key value is a vector. The output is the weighted sum of the values, and the weight (attention weight) is obtained by calculating the key corresponding to the query and each value through the compatibility function.
3.2.1 Scaled version of dot product attention
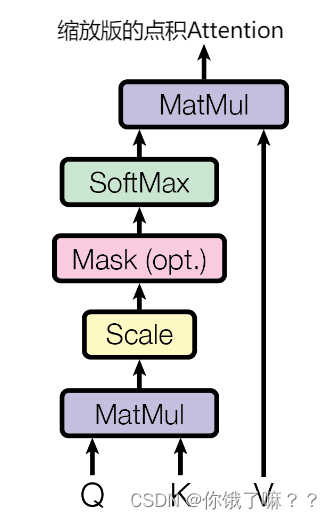
As shown in the figure, this article refers to this special attention as "zoomed version of dot product attention". The input consists of query, the key of the dk dimension and the value of the dv dimension. It then computes the dot product of the query and all keys, divides by , and applies a softmax function to get the value weights.
In practice, we simultaneously compute attention functions for a set of queries and combine them into a matrix Q. The keys and values are also packed together into matrices K and V . The calculated output matrix is:
![]()
The two most commonly used attention functions are additive attention and dot product (multiplicative) attention. In addition to scaling factor 1/
In addition, the dot product attention is the same as the algorithm in this paper. Additive attention computes a compatibility function using a feed-forward network with a single hidden layer. While both are similar in theoretical complexity, dot-product attention is faster and more space-efficient in practice because it can be implemented using highly optimized matrix multiplication code.
When the value of dk is relatively small, the performance of the two mechanisms is similar. When dk is relatively large, the performance of additive attention is better than that of dot product attention without scaling. It can be seen that for very large values of dk, the dot product grows substantially, pushing the softmax function into regions with very small gradients. To counteract this effect, we shrink the dot product to 1/ of the original value .
3.2.2 Multi-Head Attention

The author found that it is better to use different, learned linear mapping h times for query, key and value to dk, dk and dv dimensions, instead of performing a single attention function with query, key and value of dmodel dimension. Based on the query, key, and value of each mapped version, we execute the attention function in parallel to produce dv-dimensional output values. Concatenating them and mapping them again yields the final value as shown.
Multi-head attention allows different representation subspaces of the model to jointly focus on information at different locations. If there is only one attention head, its averaging suppresses this information.
Among them, the mapping is the parameter matrix WiQ ∈ ℝdmodel×dk ,
WiK ∈ ℝdmodel×dk ,
WiV ∈ ℝdmodel×dv
W O ∈ ℝhdv×dmodel。
In this work, h = 8 parallel attention layers or heads are employed. For each head, use dk=dv=dmodel / h=64. Due to the reduced size of each head, the overall computational cost is similar to a single head attention with full dimensionality.
3.2.3 Application of Attention in the model
Transformer uses multi-head attention in 3 ways:
1. In the "encoder-decoder attention" layer, the query comes from the decoder layer above, and the key and value come from the output of the encoder. This allows each position in the decoder to attend to all positions in the input sequence. This mimics the typical encoder-decoder attention mechanism in sequence-to-sequence models.
2. The encoder contains a self-attention layer. In the self-attention layer, all keys, values and queries come from the same place, in this case the output of the previous layer in the encoder. Each position in the encoder can attend to all positions in the previous layer of the encoder.
3. Similarly, a self-attention layer in the decoder allows each position in the decoder to pay attention to all positions in the decoder up to and including that position. We need to prevent leftward information flow in the decoder to preserve the autoregressive properties. We do this in a scaled version of dot-product attention by masking all illegally connected values (set to -∞) in the softmax input.
3.3 Position-Based Feedforward Networks
Except for the attention sublayer, each layer in our encoder and decoder contains a fully connected feed-forward network that is applied to each position individually and identically. It consists of two linear transformations with a ReLU activation in between.
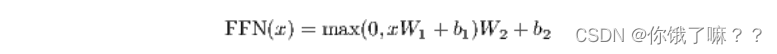
Although the linear transformations are the same across locations, they use different parameters from layer to layer. Another way to describe it is as a convolution of two kernels of size 1. The dimensions of the input and output are dmodel = 512, and the dimension of the inner layer is dff = 2048.
3.4 Embedding and Softmax
Similar to other sequence transduction models, we use learned embeddings to convert input tokens and output tokens into vectors of dimension dmodel. We also use ordinary linear transformation and softmax function to transform the decoder output into the predicted probability of the next token. In our model, the same weight matrix is shared between the two embedding layers and the pre-softmax linear transformation. In the embedding layer, we multiply these weights by .
4. Training model
4.1 Training parameters
This paper is trained on the standard WMT 2014 English-German dataset, which contains about 4.5 million sentence pairs. The sentences are encoded using byte pairs, and the source and target sentences share a vocabulary of approximately 37,000 tokens. For English-French translation, we use the much larger WMT 2014 English-French dataset, which contains 36 million sentences and divides tokens into a vocabulary of 32,000 word-pieces. Sentences of similar sequence length are batched together. Each training batch of sentence pairs contains approximately 25,000 source tokens and 25,000 target tokens.
4.2 Hardware information
This paper trains our model on a machine with 8 NVIDIA P100 GPUs. Using the base model with the hyperparameters described in this paper, each training step takes about 0.4 seconds. Our base model was trained for a total of 100,000 steps or 12 hours. For our big models, (described on the bottom line of table 3 ), step time was 1.0 seconds. The big models were trained for 300,000 steps (3.5 days).
4.3 Optimizer
This article uses the Adam optimizer, where β1 = 0.9, β2 = 0.98 and ϵ = 10-9.
5. Experimental results
5.1 Machine translation
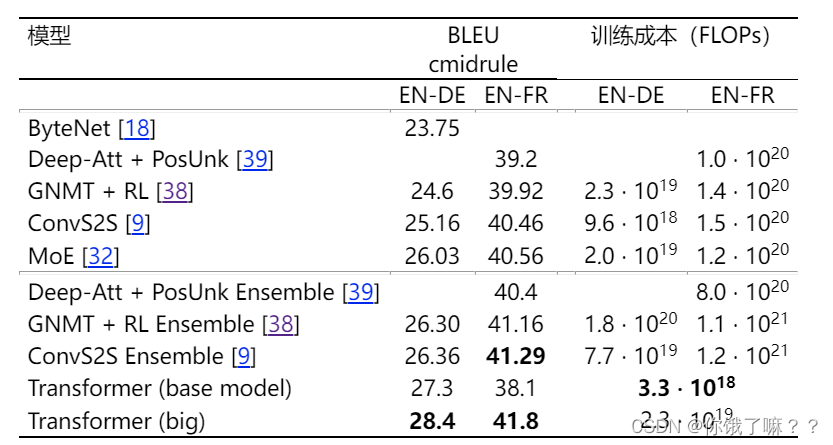
As can be seen from the above table, in the WMT 2014 English-German translation task, the large transformer model outperforms the best previously reported models (including the ensemble model) by more than 2.0 BLEU, establishing a new highest BLEU score of 28.4. The configuration for this model is listed at the bottom of the table below. Training takes 3.5 days on 8 P100 GPUs. Our base model also outperforms all previously published models and ensembles at a fraction of the training cost of these models.
5.2 Variations of the model
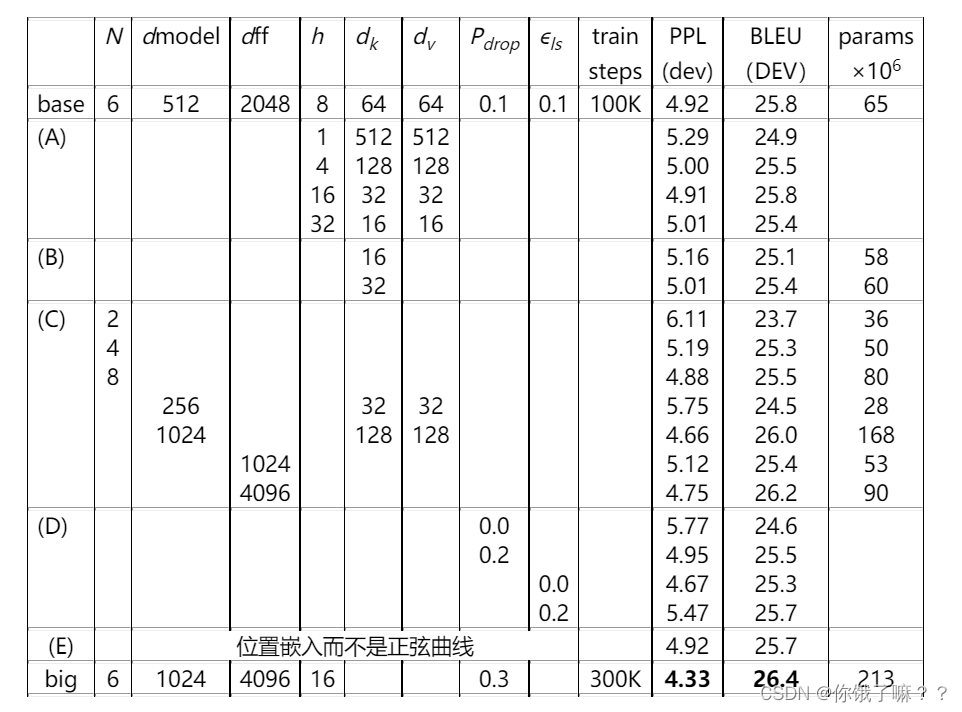
In order to evaluate the importance of different components of the Transformer, we vary our base model in different ways, measuring the performance change for English-German translation on the development set newstest2013. We use beam search as described in the previous section, but without averaging checkpoints.
In row (A) of the above table, we change the number of attention heads and the dimensions of attention key and value, keeping the calculation amount unchanged. Although only one head attention is 0.9 BLEU worse than the optimal setting, the quality also drops with too many heads.
In the upper row (B) of the table, we observe that reducing the key size dk hurts the model quality. This suggests that determining compatibility is not easy, and that a more complex compatibility function than the dot product may be more useful. We further observe in rows (C) and (D), that larger models are better, as expected, and dropout is very helpful in avoiding overfitting. In row (E), we replace our sinusoidal position encoding with the learned position embedding [ ] and observe almost the same results as the base model.
6. Conclusion
In this work we propose Transformer, the first sequence transduction model based entirely on attention mechanisms, replacing the most commonly used recurrent layers in encoder-decoder architectures with multi-headed self-attention.
For translation tasks, Transformers can be trained faster than architectures based on recurrent or convolutional layers. This paper achieves the best results on the WMT 2014 English-German and WMT 2014 English-French translation tasks. On the preceding task, our best model even outperforms all previously reported ensemble models.