foreword
This article will address the problem of difficulty in reading and searching due to information overload, and show how to use the OpenAI API to efficiently and automatically summarize PDFs, thereby improving reading efficiency and saving time. Contains detailed tutorials, practical cases, and best practices to ensure accurate and efficient document summarization. In addition, this article will also deeply discuss the advantages of using AI technology for PDF summarization, such as improving productivity and saving time, etc., and at the same time analyzing the limitations and challenges that may be encountered in practical applications.

Through this article, it can help you simplify the reading process, improve your ability to process a large amount of information, thereby improving work efficiency and academic performance, better respond to information challenges in a fast-paced world, and make full use of AI technology to bring more benefits to your reading and learning. How convenient.
Environmental preparation
Before we start, we need to prepare the development environment. First, you need to Openaiprepare the access key and provide the ability to summarize the text. \ Secondly, you need to prepare pythonthe language development environment, and install Fitzthe library, which will provide the ability to read, write and manipulate PDF files.
pip pip install PyMuPDF openai
Then import the necessary libraries into the Python file.
python import fitz import openai
read pdf content
```python import fitz import openai
context = ""
with fitz.open(‘filename.pdf’) as pdffile: numpages = pdffile.pagecount
for page num in range(num pages): page = pdf file[page num] page text = page.get text() context += page_text ```
- Create a variable called Context, set it to an empty string. This variable will be used to store the text content of the entire PDF document.
- Open the PDF file using the fitz.open() function of the Fitz library. This function takes a PDF filename as an argument.
- Use the page_count property of the pdf_file object to get the total number of pages in the PDF file. This will be used to loop through each page in the PDF file.
- Use a for loop to iterate through each page in the PDF file. The loop starts at 0 and ends at num_pages - 1 because Python's array indexing starts at 0.
- Inside the loop, use the pdf_file object to get the current page. The page_num variable is used to index the pages in the PDF file.
- Use the get_text() method of the page object to extract the text content of the current page. This method returns a string containing the text of the page.
- Use the += operator to append the text of the current page to the Context variable. This adds the text to the end of the Context string.
- After the loop is complete, the Context variable will contain the text content of the entire PDF document.
Break down pdf into paragraphs
The next step is to feed the content of the pdf into split_textthe function which is responsible for dividing the text into paragraphs of 5000 characters each.
```python
def splittext(text, chunksize=5000): “”” Splits the given text into chunks of approximately the specified chunk size.
Args: text (str): The text to split.
chunk_size (int): The desired size of each chunk (in characters).
Returns: List[str]: A list of chunks, each of approximately the specified chunk size. “””
chunks = [] currentchunk = StringIO() currentsize = 0 sentences = senttokenize(text) for sentence in sentences: sentencesize = len(sentence) if sentencesize > chunksize: while sentencesize > chunksize: chunk = sentence[:chunksize] chunks.append(chunk) sentence = sentence[chunksize:] sentencesize -= chunksize currentchunk = StringIO() currentsize = 0 if currentsize + sentencesize < chunksize: currentchunk.write(sentence) currentsize += sentencesize else: chunks.append(currentchunk.getvalue()) currentchunk = StringIO() currentchunk.write(sentence) currentsize = sentencesize if currentchunk: chunks.append(current_chunk.getvalue()) return chunks ```
- 该代码定义了一个名为
split_text的 Python 函数,用于将较长的文本分割成大小相近的较小块。 - 函数使用
sent_tokenize函数将文本分割成句子,然后遍历每个句子以创建块。 - 每个块的大小可以在函数参数中指定,默认大小为5000个字符。
- 该函数返回一个块列表,每个块的大小约为指定的大小。 这个函数可以用于对较长的 PDF 文本进行摘要处理,将它们分解成容易处理的较小块。
总的来说,split_text函数将冗长的PDF文本分解成可管理的段落,以便进行归纳总结,使其更容易处理和提取关键信息。
用OpenAI模型归纳总结文本段落
```python def gpt3completion(prompt, engine=’text-davinci-003', temp=0.5, topp=0.3, tokens=1000):
prompt = prompt.encode(encoding=’ASCII’,errors=’ignore’).decode() try: response = openai.Completion.create( engine=engine, prompt=prompt, temperature=temp, topp=topp, max_tokens=tokens ) return response.choices[0].text.strip() except Exception as oops: return “GPT-3 error: %s” % oops ```
def gpt3_completion(prompt, engine='text-davinci-003', temp=0.5, top_p=0.3, tokens=1000)这个函数接受一个提示字符串和四个可选参数:engine,temp,top_p 和 tokens。promptprompt.encode(encoding='ASCII',errors='ignore').decode()将提示字符串编码为 ASCII 格式,并在编码过程中忽略可能出现的任何错误,然后将其解码回字符串。 3.try:和except Exception as oops:用于处理在执行 try 块内的代码时可能出现的任何错误。response = openai.Completion.create(...)向 OpenAIGPT-3 API发送请求,根据提供的prompt、engine、temp、top_p 和 tokens 参数生成文本补全。响应结果存储在 response 变量中。return response.choices[0].text.strip()从响应对象中提取生成的文本,并删除任何前导或尾随的空白字符。- 如果在执行 try 块期间发生错误,函数将返回一个包含错误信息的错误消息。
总结
总的来说,本文实现的能力极大地简化阅读过程。通过使用 Fitz 库和 OpenAI 的 GPT-3 语言模型我们可以轻松地从 PDF 文件中提取并总结关键信息。另外,本文使用的是GPT-3模型,如果使用GPT-4模型那效果更佳,特别是2023年6.13以后的模型版本更出彩。
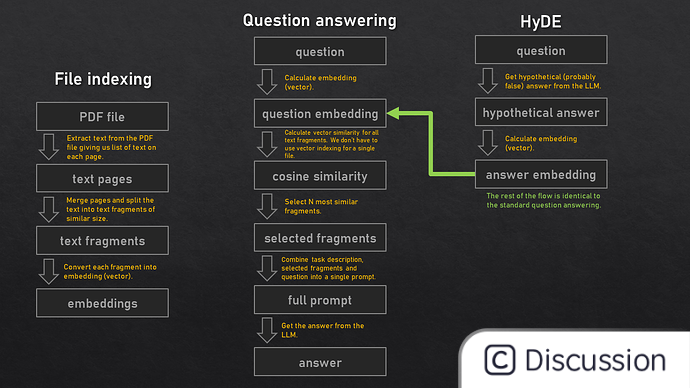
Of course, this article only provides an idea for the summary and refinement of pdf. If it is an engineering level, it also needs to consider what to do if the number of pages of the file is sufficient, how to index the directory and content, how to avoid model nonsense, how to provide privacy encryption, etc. wait. Embedding, prompt engineering, encryption and other technologies may be used. You can refer to the general process in the above figure, which we will discuss in the following article.