Table of contents
1. What is a redis transaction?
2. How to use Redis transactions?
3. Why does Redis transaction not support atomicity
4. Does Redis transaction support persistence?
5. Realization of Redis transaction based on lua script
6. What is the master-slave replication model of Redis cluster?
7. In the Redis cluster, the steps of master-slave replication data synchronization
8. What is the process of Redis incremental replication?
9. Why does Redis use RDB instead of AOF for master-slave full replication?
10. Why does Redis have a diskless replication mode?
11. What is Redis Sentinel? What is the use?
12. How is the Redis Sentinel cluster formed?
13. How does Redis Sentinel monitor the Redis cluster?
15. What is the election mechanism for sentinels?
17. After the new main library is selected, how to transfer the failure?
18. Can Sentinel prevent split brain?
19. Why do you need Redis Cluster? What problem did it solve? What are the advantages?
20. How is Redis Cluster fragmented?
21. Why is there 16384 hash slots in Redis Cluster?
22. How to determine which hash slot should be distributed for a given key?
23. Does Redis Cluster support redistribution of hash slots?
24. Can Redis Cluster provide services during capacity expansion and contraction?
25. How do nodes in Redis Cluster communicate?
1. What is a redis transaction?
A Redis transaction refers to the operation of a set of commands in the Redis database that can be committed or rolled back as a single, atomic operation. A transaction can guarantee the atomicity of a set of commands, that is, all commands in a transaction are either executed successfully or not executed at all.
2. How to use Redis transactions?
Using transactions in Redis requires the use of commands such as MULTI, EXEC, WATCH, and DISCARD. Below is a simple example showing how to use Redis transactions.
Suppose we need to subtract a certain amount of money from the user's account balance in Redis and transfer the money to another account. We can use Redis transactions to guarantee the atomicity of these two operations.
First, use the MULTI command to start a transaction:
MULTI
Then, add the command to be executed to the transaction, for example:
DECRBY user:100:balance 50
INCRBY user:101:balance 50
Here we use the DECRBY command to decrease the balance of user 100 and the INCRBY command to increase the balance of user 101. Note that these commands are not executed directly, but added to the transaction.
Next, use the EXEC command to commit the transaction:
EXEC
If the transaction execution is successful, Redis will return an array containing the execution results of each command, and if the transaction execution fails, Redis will return an empty array.
If during the execution of a transaction, we need to watch one or more keys in order to cancel the transaction if other clients modify them, we can use the WATCH command. For example, we can use the following command to monitor the balance key of user 100:
WATCH user:100:balance
If during the execution of the transaction, other clients modify the monitored key, the transaction will be canceled and all commands added to the transaction will not be executed. At this point, we can use the DISCARD command to cancel the transaction and clear all commands that have been added to the transaction:
DISCARD
In this way, we can use Redis transactions to ensure the atomicity of a set of operations and avoid data inconsistencies caused by concurrent operations.
3. Why does Redis transaction not support atomicity
Although Redis transactions can be executed between multiple commands, Redis does not treat them as a single unit of operation during the execution of the transaction. Therefore, if multiple commands are executed within a transaction and one of them fails, the others will still execute, violating the atomicity requirement.
The main purpose of Redis transactions is to reduce the communication overhead between multiple commands and to ensure that during the execution of a transaction, other clients cannot interfere with the transaction being executed. Therefore, Redis transactions are just a way to logically group commands and do not guarantee atomicity.
The Redis official website also explained why it does not support rollback. Simply put, Redis developers feel that there is no need to support rollback, which is simpler, more convenient and has better performance. Redis developers feel that even command execution errors should be discovered during development rather than production.
4. Does Redis transaction support persistence?
The persistence methods of Redis are executed asynchronously, because synchronous persistence will have a great impact on the performance of Redis. Therefore, when using Redis transactions, although the transaction itself can guarantee the atomicity of a set of commands, Redis cannot guarantee whether the changes made by these commands to the data in Redis are persisted to disk.
5. Realization of Redis transaction based on lua script
Redis transactions can be implemented based on Lua scripts. In a Lua script, you can use Redis's MULTI command and EXEC command to open and commit a transaction, and execute multiple Redis commands in a transaction. Lua scripts can encapsulate multiple Redis commands as a whole, thus ensuring the atomic execution of these commands.
The following is an example of implementing a Redis transaction using a Lua script:
-- 定义 Lua 脚本,其中包含多个 Redis 命令
local script = [[
-- 开启 Redis 事务
redis.call('MULTI')
-- 执行多个 Redis 命令
redis.call('SET', 'name', 'Alice')
redis.call('INCR', 'count')
-- 提交 Redis 事务
return redis.call('EXEC')
]]
-- 加载 Lua 脚本
local sha = redis.call('SCRIPT', 'LOAD', script)
-- 执行 Lua 脚本,即执行 Redis 事务
redis.call('EVALSHA', sha)
The above Lua script uses the Redis MULTI command to start a transaction, then executes two Redis commands (SET and INCR), and finally uses the EXEC command to commit the transaction. By using the EVALSHA command to execute the Lua script, the Redis transaction function is realized.
In Lua scripts, you can also use Redis's WATCH command to monitor one or more keys and check whether the values of these keys have been modified by other clients before the transaction is executed. If the values of these keys are modified, the transaction execution fails and needs to be re-executed. By using the WATCH command, it can be guaranteed that the key value operated will not be modified by other clients during the execution of the transaction, thereby avoiding the interference of other clients.
6. What is the master-slave replication model of Redis cluster?
Redis Cluster uses a master-slave replication model to achieve high availability and scalability. In Redis Cluster, each node can be a master node or a slave node.
The master node is responsible for handling client requests and synchronizing write operations to all slave nodes. The slave node receives synchronously replicated data from the master node and replicates all write operations on the master node to keep its own data in sync with the master node.
When the master node fails, the Redis cluster will automatically upgrade one of the slave nodes to the master node to ensure service availability and data integrity. When the election of the new master node is completed, other slave nodes will start to synchronize the new master node so that they can quickly take over the work of the master node and continue to serve.
The master-slave replication model of Redis cluster improves the availability and reliability of the system by implementing multiple copies of data. At the same time, by adding more slave nodes, the Redis cluster can also be expanded horizontally to handle more concurrent requests.
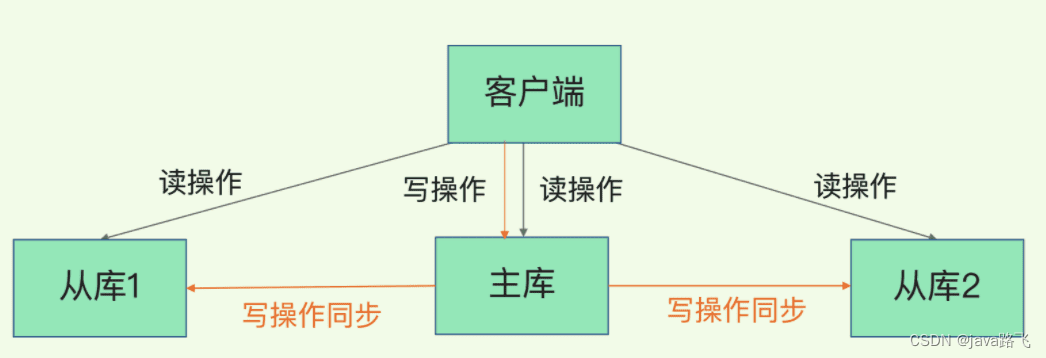
7. In the Redis cluster, the steps of master-slave replication data synchronization
1. Synchronization command: When the slave node goes online again, it will send the SYNC command to the master node, indicating that it needs to perform full synchronization.
2. Full synchronization: After receiving the SYNC command, the master node will send all its data to the slave node, and the slave node will write the data into its own memory.
3. Incremental synchronization: After the full synchronization is completed, the master node will send new write operations to the slave nodes, and the slave nodes will also perform these write operations in their own memory to maintain data synchronization.
It should be noted that when the master node receives the write operation, it will first write the data into its own memory, and then pass the command to the slave node. Therefore, if the master node crashes before delivering the command, it may result in incomplete data for the slave nodes. In this case, the slave node needs to resend the SYNC command to the master node for full synchronization.

8. What is the process of Redis incremental replication?
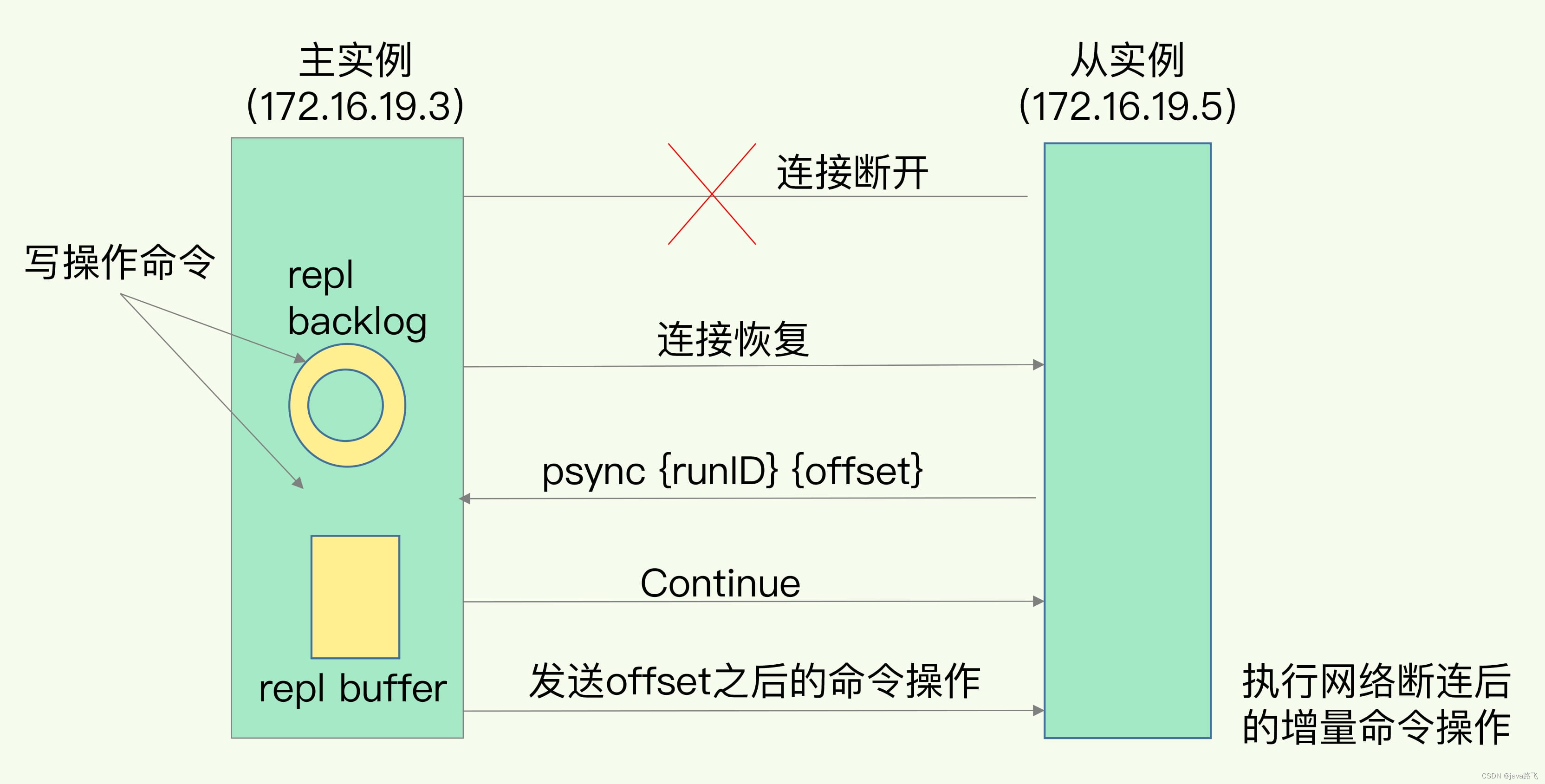
Redis incremental replication is a method of Redis master-slave replication, which is used to synchronize the data of the master node to the slave node. The process is as follows:
-
The slave node sends the SYNC command to the master node to request full replication. After receiving the request, the master node starts to generate the RDB snapshot file, and synchronizes the data of the file to the slave node, and the slave node saves the data locally after receiving the data.
-
During the process of generating RDB files, the primary node caches all write commands (including read and write commands) in memory, and appends the cached write commands to a memory buffer specially used for incremental replication. This buffer is called the replication buffer.
-
After the master node finishes transferring the RDB file, it starts to synchronize the commands in the replication buffer to the slave node. The master node will transmit the command in its own replication buffer to the slave node and wait for the slave node to confirm it. The master node will record at which position each slave node received the command, so that only the command starting from this position will be transmitted in the next transmission.
-
After the slave node receives the command from the master node, it saves it in the local database, and sends an ACK command to the master node, indicating that these commands have been received. After the master node receives the ACK command, it updates its own record to mark which position the slave node has synchronized to.
-
The slave node periodically sends the PSYNC command to the master node, requesting incremental replication. After receiving the request, the master node judges whether incremental replication can be performed. If the replication offset of the slave node is in the replication buffer of the master node, incremental replication can be performed; otherwise, full replication is required.
-
If incremental replication is possible, the master node will transmit the command corresponding to the current replication offset of the slave node and subsequent commands to the slave node. After receiving these commands from the node, save them in the local database.
-
If incremental replication is not possible, the master node regenerates the RDB file and transfers it to the slave node.
-
Repeat steps 5 to 7 until the slave node is synchronized with the master node.
It should be noted that the cache space for incremental replication is limited. If the cache area of the primary node is full, new write commands cannot be cached. At this time, the primary node can only perform full replication.
9. Why does Redis use RDB instead of AOF for master-slave full replication?
-
RDB files have a simpler data format that allows for faster data loading and recovery. The RDB file only contains a snapshot of the data, while the AOF file records all write commands, so the data format of the AOF file is more complicated.
-
RDB files are smaller and transfer faster. The RDB file only contains a snapshot of the data, so its size is smaller than that of the AOF file, and the transmission speed is faster. Transfer speed is an important consideration when doing data synchronization.
-
RDB files can be backed up and restored without stopping the Redis service. Since the RDB file only contains a snapshot of the data, data backup and recovery can be performed without stopping the service of Redis. The AOF file needs to be backed up and restored when Redis stops serving.
10. Why does Redis have a diskless replication mode?
Redis diskless replication mode (Diskless replication) is a new master-slave replication method. Its main advantages are that it can reduce the network bandwidth occupation, improve the speed of master-slave synchronization, and also reduce the disk load of the master node. The principle is to transfer the data in the master node directly to the slave node without writing the data to the disk first. In the diskless replication mode, the master node does not need to generate RDB files or AOF files, so it does not need to perform disk read and write operations.
The advantage of the diskless replication mode is that it can improve the speed of master-slave synchronization, especially in large-scale clusters. Since the data transmission is carried out through the network, in the case of a large amount of data, it will occupy a large bandwidth. Using the diskless copy mode can reduce the occupation of network bandwidth and improve the speed of master-slave synchronization. At the same time, the diskless replication mode can also reduce the disk load of the master node and avoid performance problems caused by disk read and write.
However, the diskless copy mode also has some disadvantages. Since the data transmission is carried out through the network, it will increase the burden on the network, especially in the case of large data volume. In addition, since the data transmission is directly from the master node to the slave node, if the number of slave nodes is large, it may increase the load pressure on the master node.
Enabling the Redis diskless replication mode requires the following two conditions to be met:
-
Slave nodes must run Redis 6.0 and above.
-
The master node must be running Redis 6.2 and above, and the "repl-diskless-sync" option needs to be set to "yes" in the configuration file.
11. What is Redis Sentinel? What is the use?
The main function of Redis Sentinel is to monitor the health status of Redis master nodes and slave nodes, and automatically switch to standby nodes in case of failure to ensure the continuity and availability of Redis services. Specifically, Redis Sentinel provides the following features:
-
Fault detection: Redis Sentinel can periodically detect the health status of Redis master and slave nodes, including network connection status, CPU usage, memory usage, etc.
-
Failover: When the Redis master node is down or unreachable, Redis Sentinel will automatically switch one of the slave nodes to the new master node, so that the Redis service can continue to provide services.
-
Automatic failure recovery: When the Redis master node returns to normal operation, Redis Sentinel will re-add it to the master-slave replication architecture, so that the Redis service can resume normal operation.
-
Configuration management: Redis Sentinel can dynamically manage the configuration of Redis master-slave nodes, including adding, deleting, modifying nodes, setting node weights, etc.
The main function of Redis Sentinel is to improve the reliability and availability of Redis services, and ensure that Redis services can quickly and automatically switch to standby nodes in case of failure, so as to achieve seamless switching. In a production environment, Redis Sentinel is often used to build a highly available Redis cluster to ensure that Redis services can run continuously and stably.
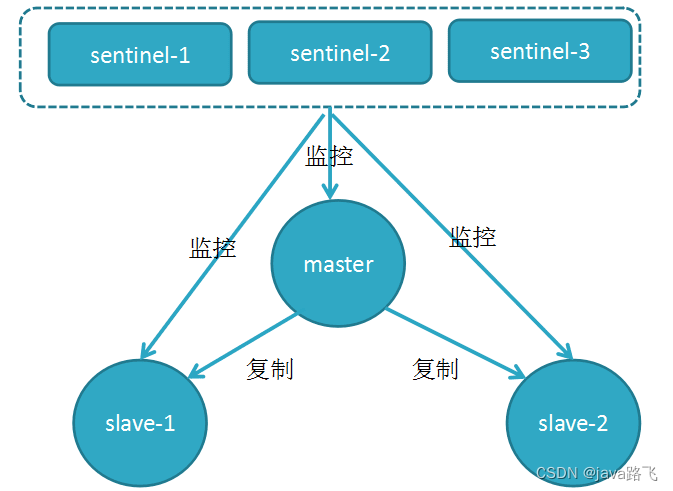
12. How is the Redis Sentinel cluster formed?
Redis Sentinel (sentinel) instances can discover each other through the pub/sub (publish/subscribe) mechanism provided by Redis. When a Sentinel instance starts up, it sends the SENTINEL is-master-down-by-addr command to the Redis master node to ask if the master node is down. If the master node does not respond, the Sentinel instance will send the same command to other Sentinel instances to try to confirm whether the master node is down. This process utilizes the pub/sub mechanism of Redis. The Sentinel instance can subscribe to a specific channel to receive status update messages sent by other Sentinel instances, so as to detect the failure of the master node in time.
In a Sentinel cluster, each Sentinel instance will send status update information to a specific channel, including the status of the master node, the status of the slave node, and the status of the Sentinel instance. Other Sentinel instances can receive and process status updates by subscribing to these channels, thereby ensuring the stability and availability of the Redis Sentinel cluster.
In the master-slave cluster, there is a __sentinel__:hellochannel named on the master library, through which different sentinels discover each other and communicate with each other. In the figure below, Sentinel 1 publishes its own IP (172.16.19.3) and port (26579) to the __sentinel__:hellochannel, and Sentinel 2 and 3 subscribe to the channel. Then at this time, Sentinel 2 and 3 can directly obtain the IP address and port number of Sentinel 1 from this channel. Then, Sentinel 2, 3 can establish a network connection with Sentinel 1.
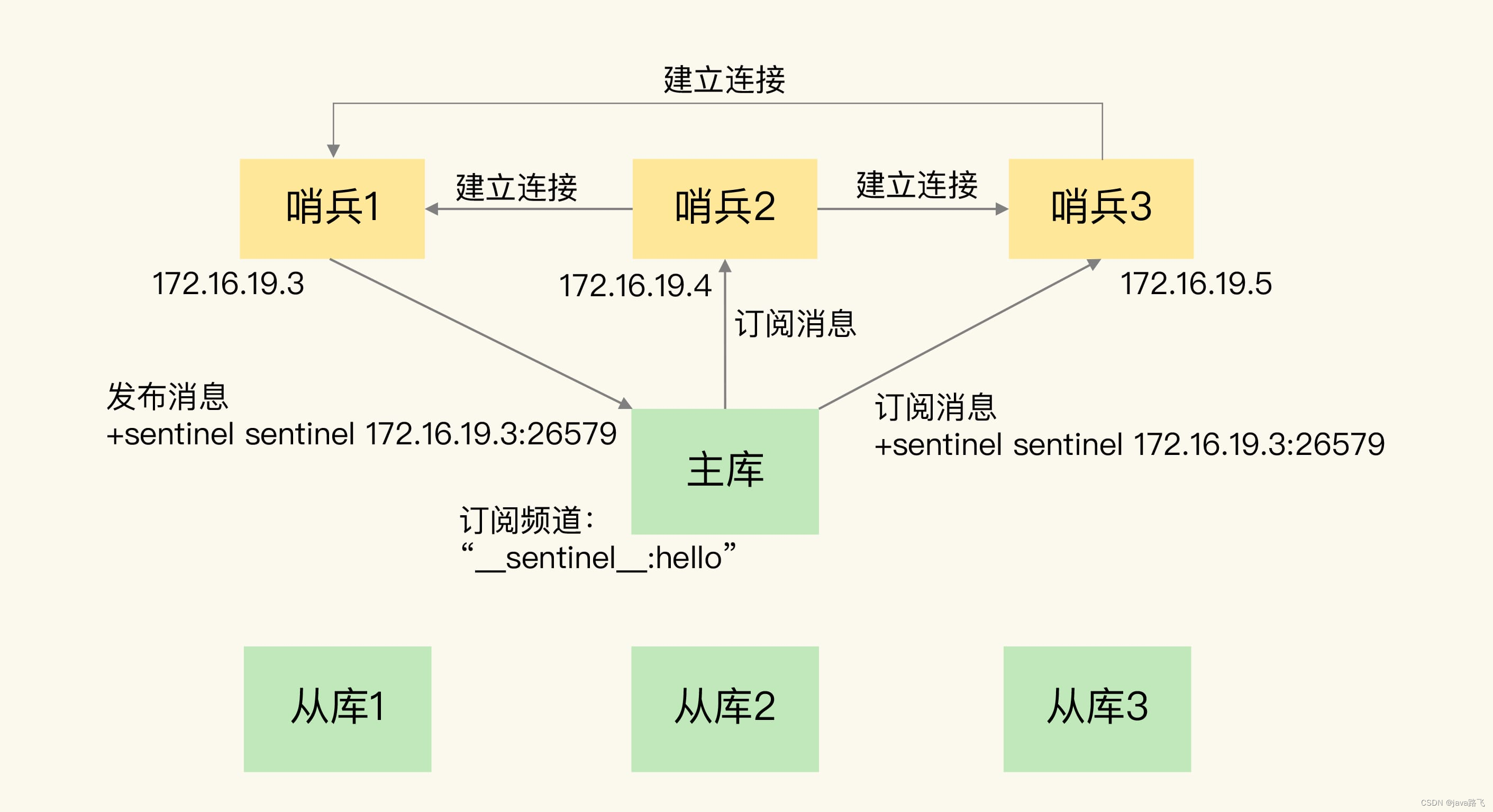
In this way, Sentinel 2 and 3 can also establish a network connection, so that a Sentinel cluster is formed. They can communicate with each other through network connections, such as judging and negotiating whether the main library is offline or not.
13. How does Redis Sentinel monitor the Redis cluster?
Redis Sentinel (sentinel) checks the health status of Redis master and slave nodes by periodically sending commands, and monitors the status of Redis cluster in real time through the pub/sub mechanism provided by Redis, so as to ensure the availability and stability of Redis cluster. Specifically, Redis Sentinel monitors Redis clusters mainly through the following aspects:
1. Regularly send commands to check the health status of Redis master and slave nodes
Redis Sentinel will periodically send commands to Redis master and slave nodes, such as PING command or INFO command, to check whether the nodes are running normally. If a node fails to respond to commands normally, Redis Sentinel marks it in a DOWN state and begins automatic failover operations.
2. Real-time monitoring of Redis cluster status through pub/sub mechanism
Redis Sentinel uses the pub/sub mechanism provided by Redis to subscribe to specific channels to receive updates on the state of the Redis cluster. For example, when a Redis master node fails, Sentinel will publish failure information to subscribed channels to notify other Sentinel instances to perform failover operations. Other sentinel instances will also receive update information by subscribing to these channels, thereby ensuring the consistency and correctness of the cluster state.
3. Define the failover strategy and election algorithm
Redis Sentinel can define failover strategies and election algorithms through configuration files or command line parameters to meet the needs of different scenarios. For example, you can define the timeout period and the number of retries for failover operations, or specify the priority and weight of the election algorithm, etc.
14. How does Sentinel detect whether a node is offline? What is the difference between subjective offline and objective offline?
Redis Sentinel is a high availability solution that monitors the state of Redis instances for automatic failover. In order to detect whether the Redis node is offline, Redis Sentinel will use the following two methods:
1. Subjective Down
In Redis Sentinel, each Sentinel process periodically sends PING commands to other Sentinel processes to check whether the Redis instance is running normally. If a Sentinel process does not receive a PONG response from a Redis instance within a specified time, it will mark the Redis instance as subjectively offline. This judgment is based on the subjective determination of the Sentinel process itself.
2. Objective Down
In addition to subjective offline, Redis Sentinel also supports objective offline detection. When multiple Sentinel processes believe that a Redis instance has gone offline, the Redis instance will be marked as objectively offline. Specifically, when more than half of the Sentinel processes believe that a Redis instance has gone offline within a specified time, the Redis instance will be marked as objectively offline.
15. What is the election mechanism for sentinels?
The sentinel election mechanism uses the Raft election algorithm.
The Raft election algorithm is a distributed consensus algorithm that divides nodes into three roles: leader (leader), follower (follower), and candidate (candidate). In the initial state, all nodes are followers. If a follower node cannot maintain communication with the leader node, it will become a candidate and start a new round of elections.
The election process is divided into the following steps:
-
Election Timeout: A candidate node will become a candidate at random intervals. At this point it will send a message requesting votes to other nodes and start timing.
-
Collect votes (Request Vote): The node that receives the voting request will check whether the candidate's term (term) is greater than its own. If so, it will switch to the follower state and set its own vote for as the candidate's ID. If you have already voted or find that the candidate's term is smaller than yourself, you will refuse to vote.
-
Winning the Election: If a candidate receives more than half of the votes, it becomes the new leader and sends a heartbeat message to other nodes to let them know that a new leader has been created.
-
Preventing Split Votes: If the term of the candidate is greater than the term of the follower node, the follower node will switch to the candidate state and start a new round of elections.
In Sentinel, each sentinel node can become a candidate, and a new leader node is elected through mutual voting. In order to ensure the stability and reliability of the election, some additional mechanisms have been added to the election process in Sentinel, such as the quorum mechanism, which means that the election must be voted by a majority of nodes. These mechanisms are to ensure that the sentinel cluster can quickly select a new leader node in the event of a failure or network split, ensuring system availability.
16. The Redis main library is determined to be offline objectively, so how to choose a new main library from the remaining slave libraries?
1. First, use Sentinel or other monitoring tools to detect all currently available slave libraries, and filter out healthy slave nodes that respond to sentinel ping responses.
2. Next, select one of the healthy slave nodes as the new master library, which can be based on the following priorities:
-
Priority selects the slave node with the highest
slave-prioritypriority . -
If there are multiple slave nodes with the same
slave-prioritypriority , then select one of the slave nodes with the largest replication offset as the new master library. Because the data of the slave node with the largest replication offset is the latest, after becoming the new master database, the data loss is the smallest. -
If multiple slave nodes have the same replication offset, one of them can be randomly selected as the new master.
3. After selecting a new master library, you need to update the configuration files of all other healthy slave nodes to make them new slave nodes and start replicating the new master library. This ensures data consistency.
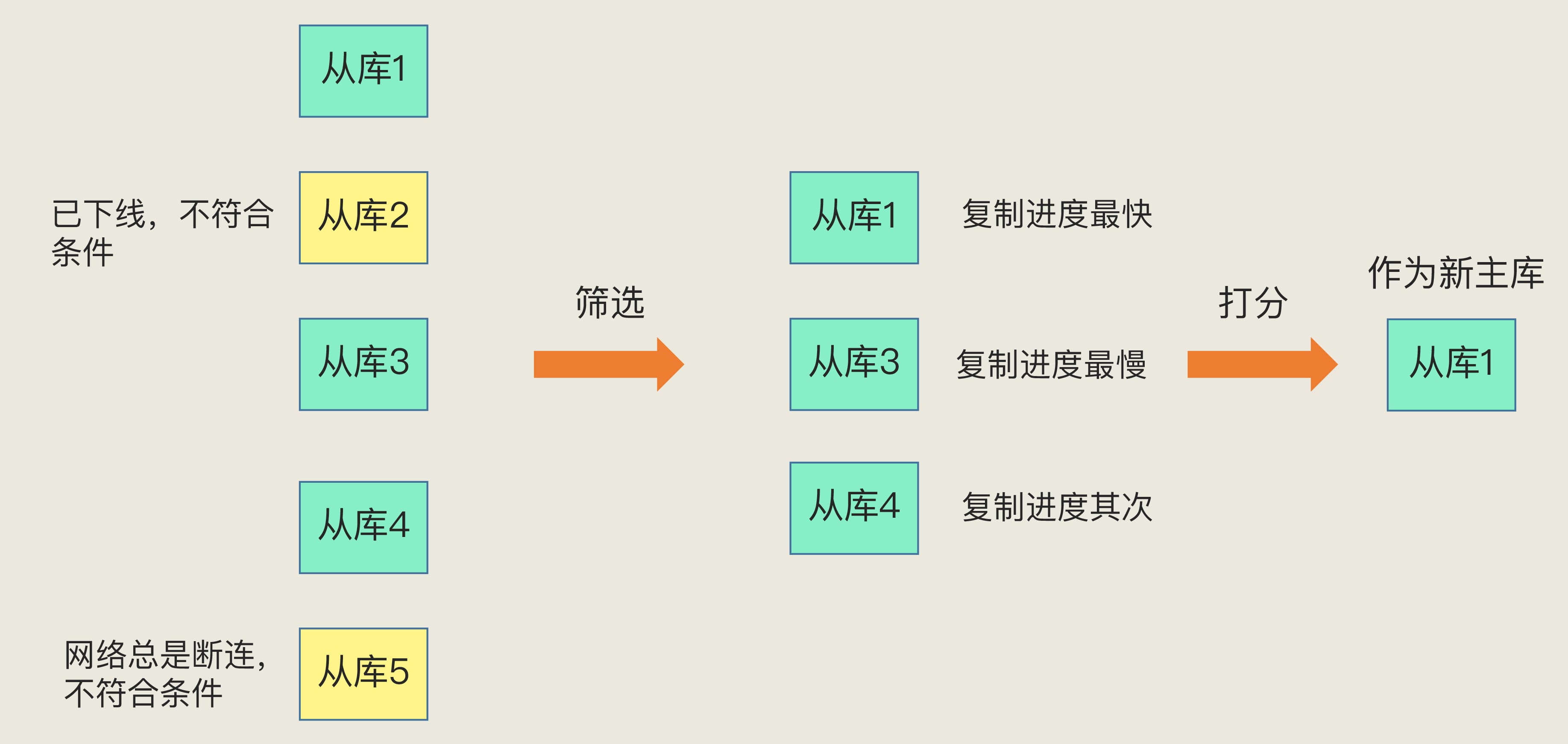
In short, by screening healthy slave nodes that respond to sentinel ping responses, and slave-priorityprioritizing the node with the highest priority and the node with the largest replication offset, the slave node that is most suitable to become the new master library can be selected to achieve a high performance of Redis. availability.
17. After the new main library is selected, how to transfer the failure?
The process of Redis Sentinel to achieve failover is as follows:
1. Primary node failure detection
Sentinel periodically sends PING commands to the master node to check whether the master node is still in a normal state. If Sentinel fails to receive the PONG response from the master node within the specified time, or receives a notification from Sentinel that the master node has gone offline, Sentinel will determine that the master node has failed.
2. Select a new master node
When Sentinel finds that the master node has failed, it will choose one of the Redis slave nodes as the new master node. When selecting a new master node, Sentinel will consider several factors, such as replication offset, priority, etc. of the slave node.
3. Perform a failover operation
Once Sentinel determines the new master node, it sends a SENTINEL is-master-down-by-addr command to other Sentinel processes, asking other Sentinel processes to perform failover operations. When performing a failover operation, Sentinel:
- Switch the slave node to the new master node to ensure data consistency.
- Update the Redis configuration to make the slave node the new master node, and notify clients to connect to the new master node.
4. Restore the original master node
Once Sentinel detects that the original master node has recovered, it will rejoin the original master node into the Redis cluster and replicate it as a new slave node.
18. Can Sentinel prevent split brain?
Sentinel can prevent the split-brain problem of Redis nodes to a certain extent.
Split-brain refers to the fact that due to network partition or hardware failure, the nodes in the Redis cluster lose connection with each other and cannot perform normal communication and data synchronization. In this case, the Redis cluster splits into multiple parts, each of which thinks it is correct, causing data consistency and availability issues.
Sentinel can prevent split brain by:
-
Electing the master node: When Sentinel detects that the master node is not working properly, it will elect a new master node through the election mechanism in the Sentinel cluster. Only one node is elected as the master node, and the other nodes become slave nodes.
-
Failover: When Sentinel finds that the master node is not working properly, it will broadcast the address of the new master node to the slave nodes, allowing them to switch to the new master node. This method can avoid the split-brain problem, because there is only one new master node, and data synchronization between slave nodes is also performed under this new master node.
-
Quorum: Sentinel uses the quorum mechanism to ensure the correctness of failover. Quorum refers to how many Sentinels are required in the cluster to perform failover operations. Typically, the Quorum is set to (Number of Sentinels/2 +1). This setting ensures that failover will only occur when a majority of Sentinels agree, thereby avoiding split-brain issues.
Although Sentinel can prevent split-brain problems to a certain extent, in extreme cases, split-brain problems may still occur, such as excessive network partitions or too few Sentinels. Therefore, in order to further improve the high availability of the Redis cluster, it is recommended to adopt a distributed Redis solution such as Redis Cluster to avoid the split-brain problem.
19. Why do you need Redis Cluster? What problem did it solve? What are the advantages?
Redis Cluster is a distributed cluster solution of Redis, which can solve the capacity and performance bottleneck problems of single-machine Redis, and provide higher availability and scalability.
Specifically, Redis Cluster is needed mainly to solve the following problems:
-
Capacity limitation: The capacity of a stand-alone Redis is limited by the memory size. If you need to store more data, you need to use more Redis instances, which will cause data to be scattered among multiple instances, making management and maintenance more difficult.
-
Performance bottleneck: The performance of stand-alone Redis will be limited when processing large-scale data. For example, a large number of read and write requests will slow down the response speed of stand-alone Redis.
-
Availability: Stand-alone Redis faces the problem of single point of failure. If the Redis instance fails, the entire Redis service will be unavailable.
Redis Cluster realizes distributed storage and access of data by sharding data into multiple Redis nodes. Each Redis Cluster node can handle multiple requests at the same time, which improves the performance and throughput of Redis. In addition, Redis Cluster can also automatically perform data backup and failover, thereby ensuring the high availability of Redis Cluster.
The advantages of Redis Cluster mainly include:
-
Horizontal expansion: Redis Cluster can easily achieve horizontal expansion of data. By increasing the number of Redis nodes, the capacity and performance of the cluster can be increased without changing the application.
-
High availability: Redis Cluster uses a master-slave replication mechanism to ensure high availability of data. When the master node fails, it can automatically switch to the slave node, thus avoiding the single point of failure problem.
-
Distributed management: Redis Cluster can easily perform operations such as adding, deleting, and resharding nodes without stopping the service.
-
Automatic load balancing: Redis Cluster can automatically distribute requests to the most suitable nodes according to the load conditions of each node, thereby achieving load balancing.
In short, Redis Cluster provides higher scalability, high availability, performance and flexibility, and is suitable for scenarios that need to store large amounts of data and high concurrent access.
20. How is Redis Cluster fragmented?
Redis Cluster uses the hash slot sharding strategy to map data to a hash slot from 0 to 16383 according to the hash value of the key name, and then assign each hash slot to a different node for storage .
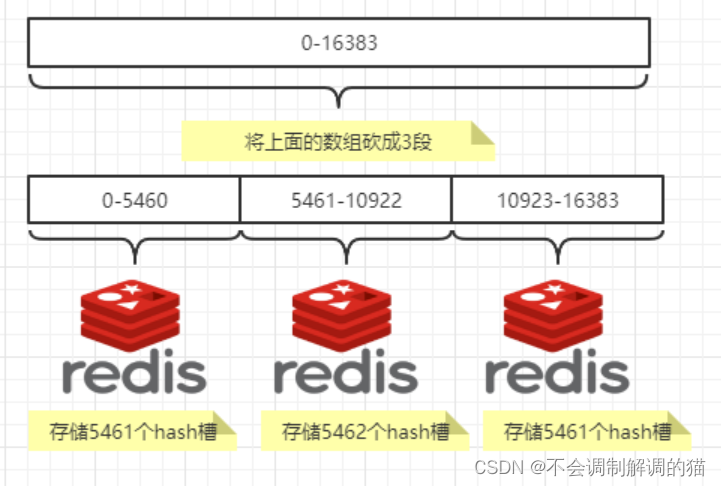
Specifically, Redis Cluster will allocate a certain number of hash slots to each node, and each hash slot corresponds to a key-value pair. When the client sends a command, Redis Cluster will assign the command to the node where the corresponding hash slot is located for processing according to the hash value of the key name involved in the command.
For example, if a Redis Cluster cluster has 3 nodes A, B, and C, and each node is allocated 5461 hash slots, then hash slots 0 to 5460 belong to node A, 5461 to 10921 belong to node B, and 10922 to 16383 belongs to node C. When the client sends a SET key1 value1 command, Redis Cluster will calculate the hash value of key1 and distribute the command to the node where the corresponding hash slot is located for processing. If the hash value of key1 is in the range of 0 to 5460, then the command will be assigned to node A for processing.
The hash slot sharding strategy can ensure the balanced distribution of data stored in each node, and also ensure the scalability of the cluster. When expansion or contraction is required, only the hash slots need to be redistributed to new nodes. In addition, the hash slot sharding strategy can also ensure that the data between nodes is independent of each other, avoiding the risk of a single point of failure.
21. Why is there 16384 hash slots in Redis Cluster?
The "communication" between Redis instances will exchange "slot information" with each other. If there are too many slots (meaning that the network packet will become larger), the network packet will become larger, which means that the bandwidth of the network will be "excessively occupied". The author of Redis believes that the cluster In general, there will be no more than 1,000 instances, so 16,384 instances can be selected, which can reasonably disperse the data to different instances in the Redis cluster without causing excessive bandwidth usage when exchanging data.
22. How to determine which hash slot should be distributed for a given key?
In a Redis cluster, each key is mapped to a hash slot, and the following steps can be followed to determine the hash slot for a given key:
-
To calculate the hash value for the key, the hash function used is the CRC16 checksum algorithm, which returns a 16-bit unsigned integer.
-
Divide this 16-bit unsigned integer by the number of hash slots (default is 16384), take the remainder, and the result is the number of the hash slot to which the key should be mapped.
For example, for a key "hello", the hash slot number to which it should be mapped can be calculated according to the following steps:
-
Calculate the CRC16 checksum value of "hello" to be 2229.
-
Taking the remainder of 2229 to 16384 yields 1093, so the key "hello" should be mapped to hash slot number 1093.
23. Does Redis Cluster support redistribution of hash slots?
Yes, Redis Cluster supports redistribution of hash slots, also known as "resharding". During the operation of Redis Cluster, you may encounter situations such as new nodes, node failures, and node expansion. These changes may cause the distribution of hash slots to be uneven, thereby affecting the performance and availability of the cluster.
To solve this problem, Redis Cluster provides a mechanism called "resharding", which can redistribute hash slots so that they are evenly distributed on new nodes. Specifically, the resharding process is as follows:
-
Adding a new node: When a new node joins the cluster, its number of hash slots will be distributed equally among all nodes.
-
Node failure: When a node fails, its hash slots are reassigned to other nodes.
-
Node expansion: When a node needs to be expanded, it can request the cluster administrator to allocate some hash slots for it, and the administrator assigns these hash slots to the node.
In these operations, Redis Cluster will use some algorithms to ensure the uniform distribution of hash slots. For example, when adding new nodes or failover, the cluster will try to adjust the number of hash slots of different nodes to almost the same level.
It should be noted that the resharding operation may have an impact on the performance and availability of the cluster, so it should be performed when necessary to avoid reassigning hash slots too frequently.
24. Can Redis Cluster provide services during capacity expansion and contraction?
During the expansion or shrinkage of Redis Cluster, the cluster can still provide services, but it may have a certain impact on the performance and availability of the cluster.
When the cluster needs to be expanded, new nodes are added to the cluster and hash slots are reassigned. During this process, the performance of the cluster may be affected to a certain extent, because a large amount of data transmission and synchronization between nodes is required. If the amount of data is large, this process may last for a long time, during which the response time of the cluster may slow down, and some data inconsistencies may occur.
Similarly, when the cluster needs to shrink, some nodes will be removed and hash slots will be reassigned. This process may degrade the performance and availability of the cluster, because removing nodes requires extensive data migration and synchronization, and this process may also be time-consuming.
In order to minimize the impact on the cluster, some measures can be taken to optimize the expansion or shrinkage process, such as using technologies such as online migration or incremental synchronization to reduce the amount of data transfer between nodes, or operate when the cluster load is light . In addition, when performing expansion or contraction operations, you should try to avoid performing multiple operations at the same time, so as not to affect the stability and performance of the cluster.
25. How do nodes in Redis Cluster communicate?
Communication via the Gossip protocol;
Newly joined node: The Gossip protocol sends a "Meet message" to the old node. The old node will reply "Pong message". Subsequent new nodes will periodically send "ping" to the old node, and the old node will reply "pong" to ensure that the connection is maintained
Meet 消息,用于通知新节点加入。就好像上面例子中提到的新节点上线会给老节点发送 Meet 消息,表示有“新成员”加入。
Ping 消息,这个消息使用得最为频繁,该消息中封装了自身节点和其他节点的状态数据,有规律地发给其他节点。
Pong 消息,在接受到 Meet 和 Ping 消息以后,也将自己的数据状态发给对方。同时也可以对集群中所有的节点发起广播,告知大家的自身状态。
Fail 消息,如果一个节点下线或者挂掉了,会向集群中广播这个消息。The purpose of communication is to ensure that each node has the corresponding relationship between slot data of other nodes, and each node has a ClusterState, which records the corresponding relationship between all slots and nodes. No matter which node in the cluster the Redis client accesses, it can be routed to the corresponding node

MOVED redirection request: request to a redis node, find that the slot is not in the server, then return the moved command, tell the redis client which node should be requested to rewrite and send the request to the node
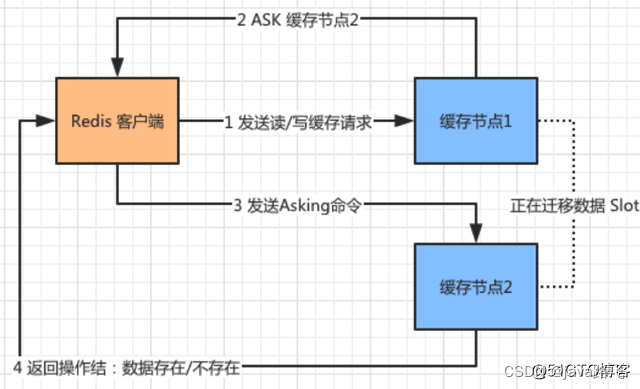
ASK redirection request: The Redis client sends a request to "Cache Node 1". At this time, "Cache Node 1" is migrating data to "Cache Node 2". If the corresponding Slot is not hit, it will return an ASK redirection to the client Request and tell the address of "cache node 2".
The client sends an Asking command to "cache node 2" to ask whether the required data is on "cache node 2", and "cache node 2" returns the result of whether the data exists after receiving the message.