Related articles:
[Redis Interview] Summary of Basic Questions (Part 1)
[Redis Interview] Summary of Basic Questions (Part 2)
For basic knowledge of redis, see the column: Redis
interview
- 1. Introduce the implementation scheme of redis cluster
- 2. Talk about the underlying data structure of the hash type
- 3. Introduce the underlying data structure of the zset type
- 4. How to use redis to implement distributed sessions
- 5. How to use Redis to implement a distributed lock?
- 6. Talk about the understanding of Bloom filter
- 7. How should multiple redis be designed to resist high concurrent access?
- 8. What is the application scenario of redis?
- 9. Why doesn't Zset use balanced trees such as red-black trees?
- 10. What is RedisObject?
- 11. Cache update strategy
- 12. Redis network model
- 13. How is the client routed?
1. Introduce the implementation scheme of redis cluster
Partition scheme of redis cluster:
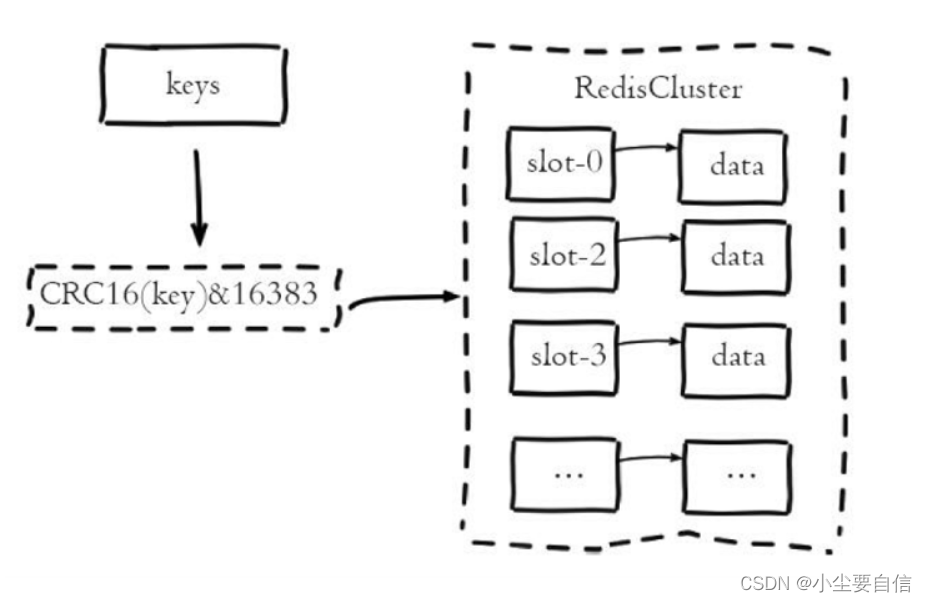
Redis cluster uses virtual slotting to realize data fragmentation. It maps all keys to 0-16383 integer data slots according to the hash function. Each node is responsible for maintaining a part of the slots and the mapped key-value data , virtual slot features:
1. Decoupling the relationship between data and nodes simplifies the difficulty of node expansion and contraction;
2. The node itself maintains the mapping relationship of slots, and does not require clients or proxy services to maintain slot partition metadata
3. Supports mapping queries between nodes, slots, and keys, and is used for
data sharding logic in Redis clusters in scenarios such as data routing and online scaling :
The function of redis clusters limits
the redis cluster solution. There are some usage restrictions
1. The key batch support is limited: such as mset, mget, currently only supports batch operations on keys with the same slot value, for keys mapped to different slot values, there may be multiple operations due to the execution of mset, mget and other operations 2. The support for key transaction operations is limited
: transaction operations on the same node are supported;
3. Key is the minimum granularity of data partitioning, so a large key-value pair (hash, list, etc.) Mapped to different nodes;
4. Does not support multiple database spaces: redis under a single machine supports 16 databases, and only one database, namely DBO, can be used under a cluster; 5. The
replication structure only supports one layer, and the slave node can only copy the master node, not Support nested tree replication structure;
Redis cluster communication scheme:
Redis cluster adopts P2P Gossip (rumour) protocol. The working principle of Gossip protocol is that nodes communicate and exchange information with each other continuously. After a period of time, all nodes will know the complete information of the cluster. This method is similar to message dissemination, and the process is as follows:
1. Each node in the cluster will open a separate tcp channel for communication between nodes, and the communication port will add 10000 to the base port; 2.
Each node will select several nodes to ping messages through specific rules in a fixed period ;
3. Nodes that receive ping messages respond with pong messages
. The main responsibility of the Gossip protocol is to exchange information, and the carrier of information exchange is to send gossip messages between nodes. Gossip messages are divided into: meet messages, ping messages, and pong messages , fail message, etc.;
meet message: used to notify new nodes to join, the message sender notifies the receiver to join the current cluster, after the meet' message communication is completed normally, the receiving point will join the cluster and perform periodic ping messages, pong messages
Ping message: The most frequently exchanged message in the cluster. Each node in the cluster sends ping messages to multiple other nodes per second to detect whether the nodes are online and exchange status information with each other. The ping message packs its own node and some other nodes. Status information of the node;
pong message: After receiving the meet and ping message, it will reply to the sender as a response to confirm the normal communication of the message. The pong message encapsulates its own status data, and the node can also broadcast its own pong message to the cluster to notify the entire The cluster updates its own state information.
Fail message: When a node judges that a node in the cluster is offline, it will send a fail message to the cluster, and other nodes will update the corresponding node to the offline state after receiving the fail message;
2. Talk about the underlying data structure of the hash type
The hash object has two encoding schemes. When the following conditions are met at the same time, the hash object adopts ziplist, otherwise it adopts hashtable encoding; the
number of key-value pairs stored in the hash object is less than 512
keys in all key-value pairs stored in the hash object and value, the string length of which is less than 64 bytes.
The compressed list encoding uses a compressed linked list as the underlying implementation, while the hashtable uses a dictionary as the underlying implementation.
Compressed list:
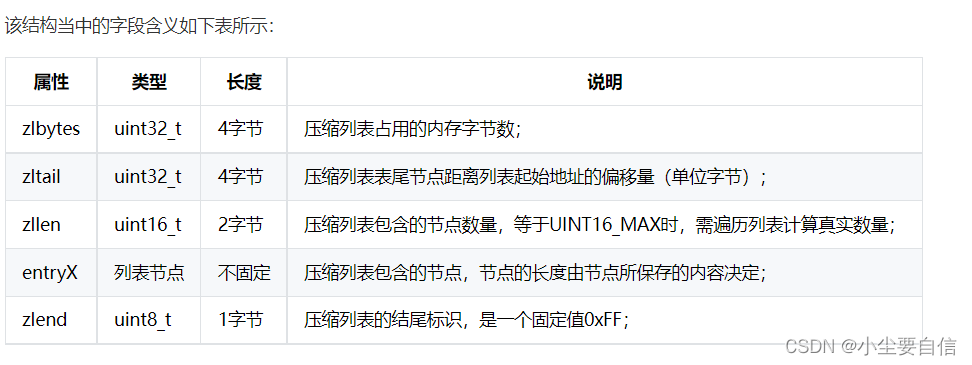
It is a linear data structure designed by redis to save memory. It is composed of A series of contiguous memory blocks with special encoding. A compressed linked list can contain any number of nodes. Each node can store a byte array or an integer. The previous_entry_length (


pel) attribute is in bytes and records the previous entry of the current node The length of the node, which itself occupies 1 byte or 5 bytes:
If the length of the previous node is less than 254 bytes, the length of the "pel" attribute is 1 byte, and the length of the previous node is stored in this byte;
If the length of the previous node reaches 254 bytes, the length of the "pel" attribute is 5 bytes, the first byte of which is set to 0xFE, and the next four bytes are used to save the length of the previous node;
Based on the "pel" attribute, the program can calculate the start address of the previous node based on the start address of the current node through pointer arithmetic, so as to realize the traversal operation from the end of the table to the head of the table.
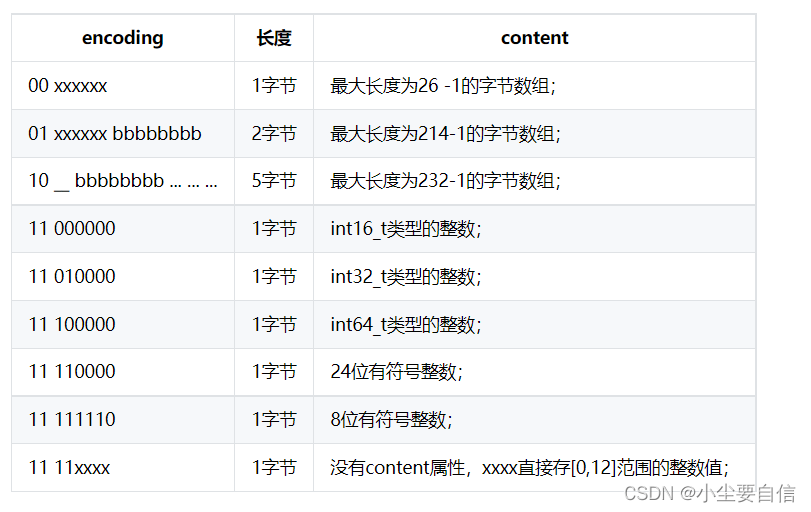
The content attribute is responsible for saving the value of the node (byte array or integer), and its type and length are determined by the encoding attribute. Their relationship is as follows: Dictionary: also known as a hash table, is
a
data structure used to store key-value pairs
The implementation of redis dictionary mainly involves three structures: dictionary, hash table and hash table node. Each hash table node stores a key-value pair, each hash table is composed of multiple hash table nodes, and the dictionary is a further encapsulation of the hash table. The relationship between these three structures is as follows:
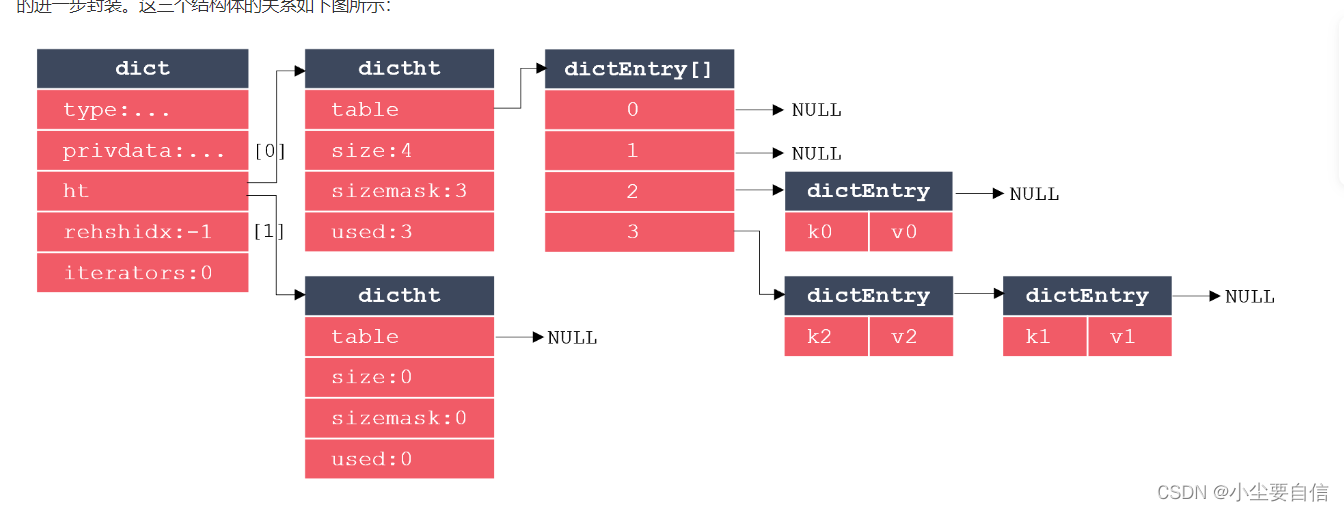
where dict represents a dictionary, dicttht represents a hash table, and dictEntry represents a hash table node. It can be seen that dictEntry is an array, because each hash table needs to store multiple hash table nodes. The dict contains 2 dictht extra hash tables for rehash. When there are too many or too few key-value pairs stored in the hash table, the size of the hash table needs to be expanded or contracted. In redis, the expansion and contraction of the hash table is achieved through rehash'. The steps to perform rehash are as follows:
1. Allocate storage space for the ht[1] hash table of the dictionary
If an expansion operation is performed, the size of ht[1] is equal to 2n of h[0].used*2. If the contraction operation is performed, the size of ht[1] is the first 2n that is greater than or equal to ht[0].used.
2. Migrate the data stored in ht[0] to ht[1]
Recalculate the hash value and index value of the key, and then place the key-value pair in the specified position of the ht[1] hash table.
3. Promote the ht[1] hash table of the dictionary to the default hash table
After the migration is complete, clear ht[0] and exchange the values of ht[0] and ht[1] to prepare for the next REHASH.
When any of the following conditions are met, the program will automatically start to perform the expansion operation on the hash table:
1. The server currently does not execute the bgsave or bgrewriteof command, and the load factor of the hash table is greater than or equal to 1;
2. The server is currently executing the bgsave or bgrewriteof command, and the load factor of the hash table is greater than or equal to 5.
In order to avoid the impact of REHASH on server performance, the REHASH operation is not completed at one time, but is completed in multiple times and gradually. The detailed process of progressive REHASH is as follows:
1. Allocate space for ht[1], let the dictionary hold ht[0] and ht[1] two hash tables at the same time;
2. The index counter rehashidx in the dictionary is set to 0, indicating that the REHASH operation has officially started;
3. During REHASH, every time the dictionary is added, deleted, modified, or searched, in addition to performing the specified operations, the program will also migrate all key-value pairs located on rehashidx in ht[0] to ht[ 1], add 1 to the value of rehashidx;
4. As the dictionary is continuously accessed, at a certain moment, all key-value pairs on ht[0] are migrated to ht[1]. At this time, the program sets the rehashidx attribute value to -1 to identify the REHASH operation Finish.
During REHSH, the dictionary holds two hash tables at the same time, and the access at this time will be processed according to the following principles:
1. Newly added key-value pairs are all saved in ht[1];
2. Other operations such as deletion, modification, and search will be performed on the two hash tables, that is, the program first tries to access the data to be operated in ht[0], if it does not exist, access it in ht[1], and then Process the accessed data accordingly
3. Introduce the underlying data structure of the zset type
There are two encoding schemes for ordered collection objects. When the following conditions are met at the same time, the collection object adopts ziplist, otherwise it adopts skiplist encoding 1. The
number of elements saved in the ordered collection does not exceed 128
2. The members of all elements saved in the ordered collection The lengths are all less than 64 bytes
. The ziplist-encoded ordered set adopts the compressed list as the underlying implementation, and the skiplist-encoded ordered set adopts the zset structure as the underlying implementation.
Among them, zset is a compound structure, which is implemented internally by dictionaries and table adjustments. Its source code is as follows.
Dict saves the mapping relationship from members to branches, and zsl saves all set elements from small to large according to the score. In this way, When accessing the ordered set according to the members, you can directly get the value from the dict, and when you access the ordered set list according to the range of the score, you can directly get the value from the zsl, using the space-for-time strategy.
To sum up, the underlying data structures of zset objects include: compressed lists, dictionaries, and jump lists
Jump lists:
The search complexity of the jump table is O(logN) on average, and O(N) at worst. The efficiency is comparable to that of a red-black tree, but far simpler than that of a red-black tree. The jump table is based on the linked list, and the search efficiency is improved by adding indexes.
The complexity of inserting and deleting in an ordered linked list is O(1), while the complexity of searching is O(N). Example: If you want to find an element with a value of 60, you need to compare it backwards from the first element in turn, a total of 6 comparisons are required, as shown in the figure below: The

jump table selects some nodes from the ordered linked list to form a new linked list. And use it as the primary index of the original linked list. Then select some nodes from the primary index to form a new linked list, and use it as the secondary index of the original linked list. By analogy, there can be multi-level indexes, as shown in the figure below:
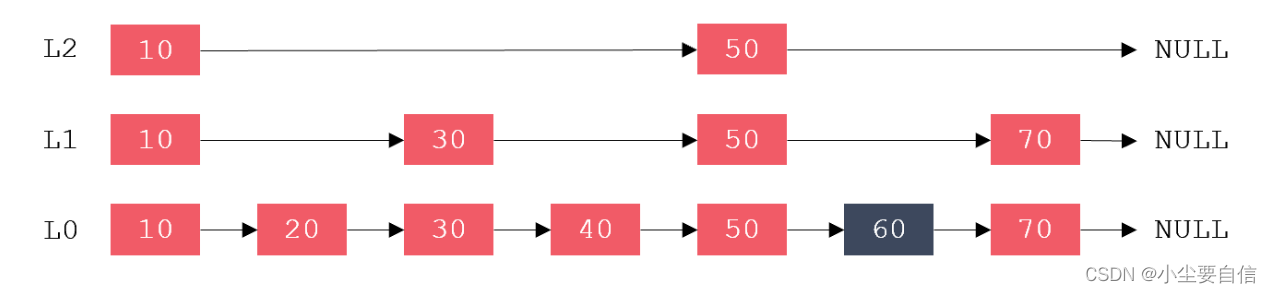
When searching for a jump table, it first searches from the upper layer. If the value of the next node is greater than the target value, or the next pointer points to NULL, it will go down one layer from the current node and continue to search backwards. , so that the search efficiency can be improved.
The realization of the skip table mainly involves two structures: zskiplist and zskiplistNode, and their relationship is shown in the figure below:

Among them, the blue table represents zskiplist, and the red table represents zskiplistNode. zskiplist has pointers to the head and tail nodes, and the length of the list, the highest level in the list. The head node of zskiplistNode is empty, it does not store any real data, it has the highest level, but this level is not recorded in zskiplist.
4. How to use redis to implement distributed sessions
In web development, we will store the user's login information in the session, and the session is dependent on the cookie, that is, the server will assign him a unique id when creating the session, and create a cookie in response to store this session, when the client receives the cookie, it will automatically save the sessionid, and automatically carry the sessionid in the next visit, then the server can get the corresponding session through the sessionid, so as to identify the user's identity. Today's Internet applications,

basically All adopt the distributed deployment method, that is, the application is deployed on multiple servers, and the unified request distribution is performed through nginx. The servers are isolated from each other, and their sessions are not shared, which leads to the problem of session synchronization, as shown in the following figure:
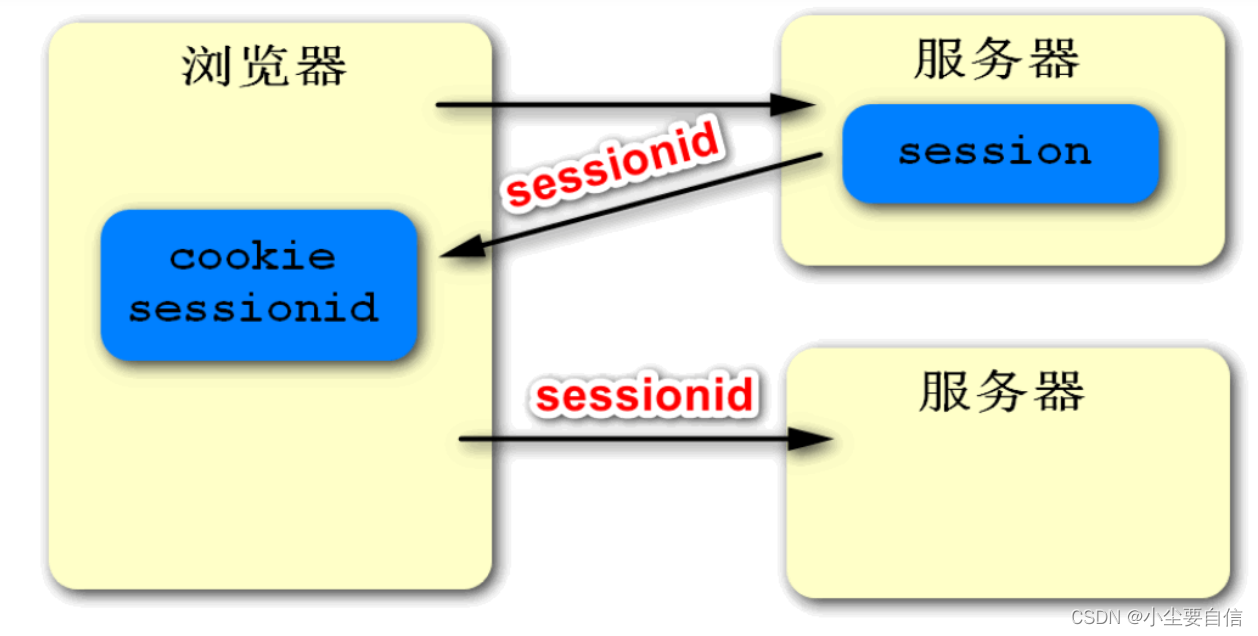
If the client accesses the server for the first time and the request is distributed to server A, server A will create a session for the client. If the client accesses the server again and the request is distributed to server B, since the session does not exist in server B, the user's identity cannot be verified, resulting in an inconsistency problem.
There are many ways to solve this problem, such as coordinating multiple servers to keep their sessions synchronized. Binding processing can also be done when distributing requests, that is, a certain IP is fixedly assigned to the same server. But these methods are more troublesome, and there is a certain consumption in performance. A more reasonable way is to use a high-performance cache server like Redis to implement distributed sessions.
From the above description, we can see that we use the session to save the user's identity information, essentially doing two things. The first is to save the user's identity information, and the second is to verify the user's identity information. If you use other means to achieve these two goals, then you don't need session, or we use session in a broad sense.
The specific implementation idea is as shown in the figure below. We add two programs on the server side:
The first is the process of creating a token, which is to create a unique identity for the user when he first visits the server, and use a cookie to encapsulate this identity and send it to the client. Then when the client accesses the server next time, it will automatically carry this identity, which is the same as the SESSIONID, but it is implemented by ourselves. Also, before returning the token, we need to store it for subsequent verification. And this token cannot be saved locally on the server, because other servers cannot access it. Therefore, we can store it in a place other than the server, then Redis is an ideal place.
The second is the procedure of verifying the token, that is, when the user accesses the server again, we obtain its previous identity, then we need to verify whether the identity exists. The verification process is very simple, we can know the result after trying to get it from Redis.
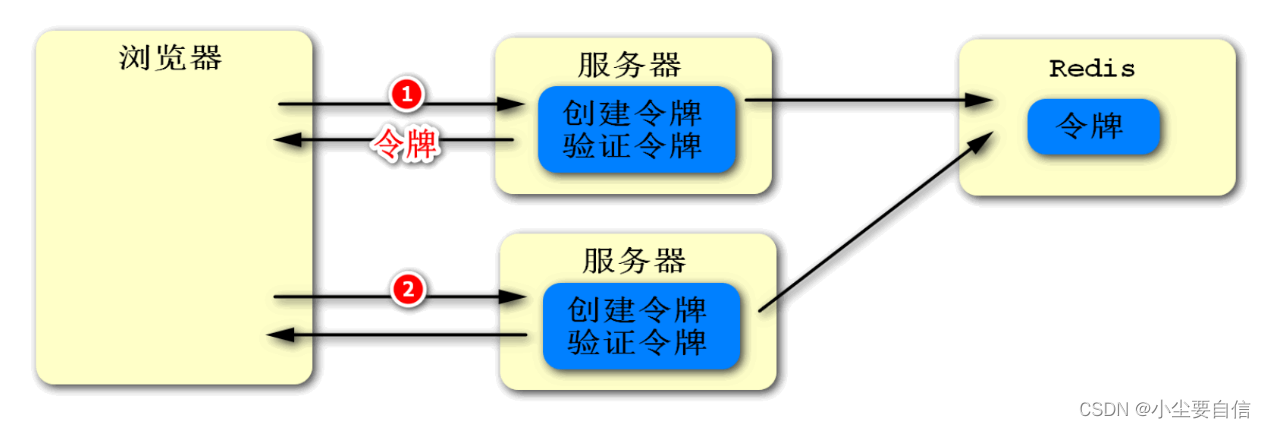
5. How to use Redis to implement a distributed lock?
When do you need distributed locks?
In a distributed environment, when multiple servers modify the same resource concurrently, distributed locks are required to avoid competition. Then why can't you use the lock that comes with Java? Because the lock in Java is designed for multi-threading, it is only limited to the current JRE environment. However, multiple servers are actually multiple processes and different JRE environments, so the lock mechanism that comes with Java is invalid in this scenario.
How to implement distributed locks?
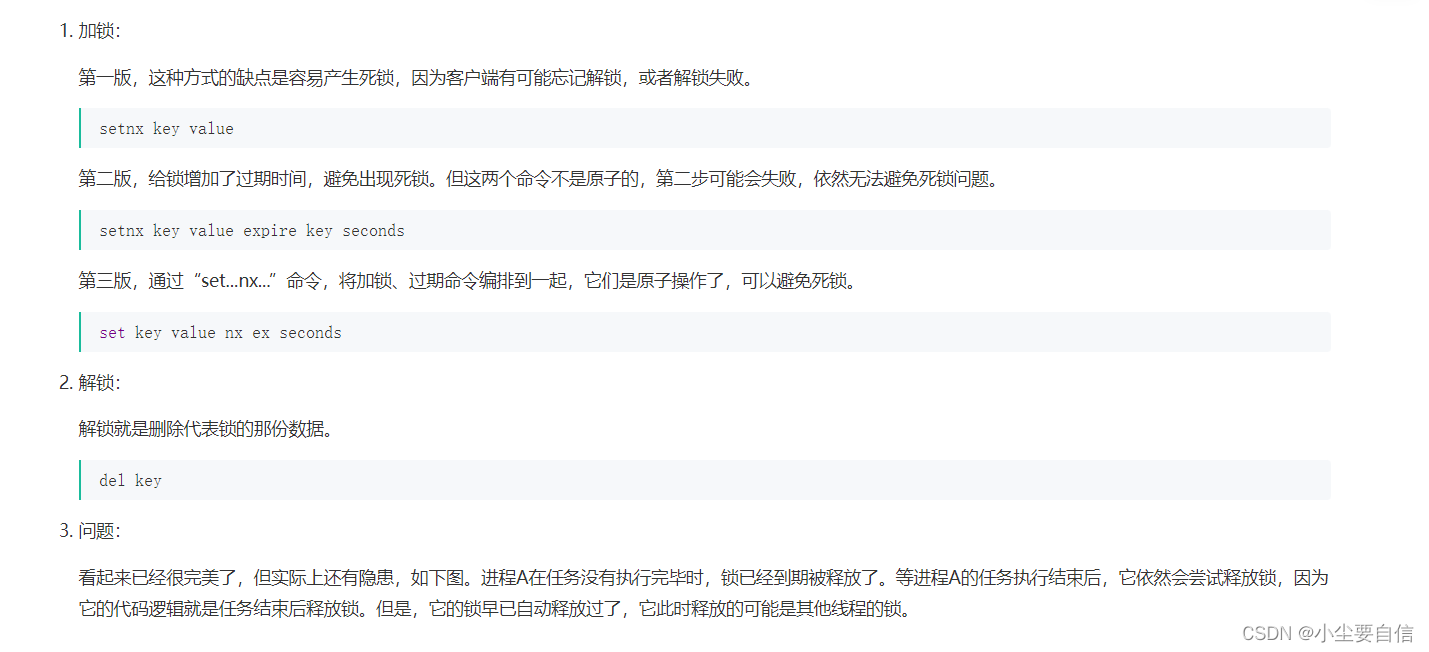
Using Redis to implement distributed locks is to store a piece of data representing locks in Redis, usually using strings. The idea of implementing distributed locks and the optimization process are as follows:
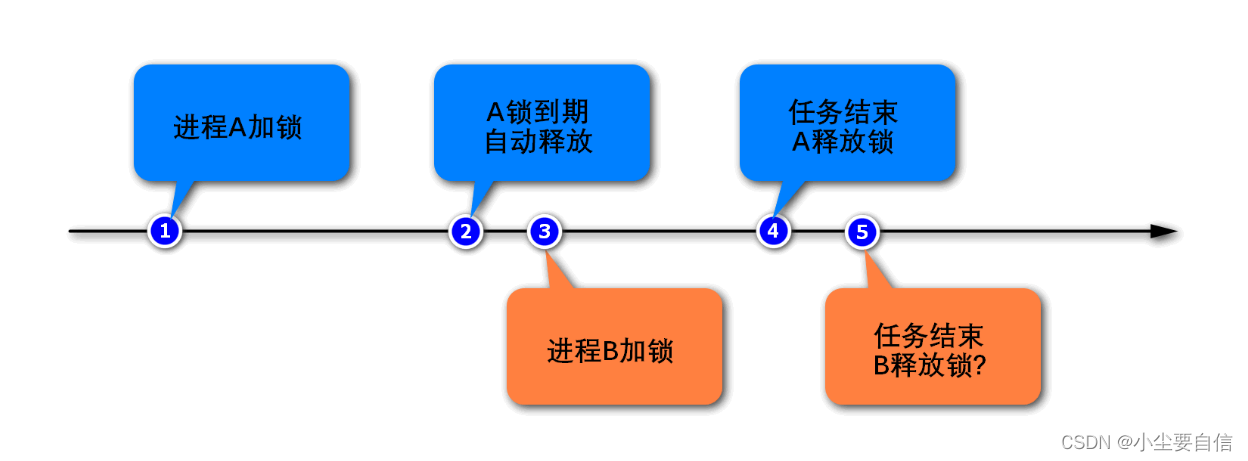
To solve this problem, we need to solve two things:
1. When locking, it is necessary to set an identifier for the lock, and the process must remember this identifier. When the process is unlocked, it must be judged that the lock held by itself can be released, otherwise it cannot be released. A random value can be assigned to the key to serve as the identification of the process.
2. When unlocking, you must first judge and then release. These two steps need to ensure atomicity, otherwise if the second step fails, a deadlock will occur. However, the acquisition and deletion commands are not atomic, which requires the use of Lua scripts to weave the two commands together through the Lua script, and the execution of the entire Lua script is atomic.
According to the above ideas, the optimized command is as follows:
# 加锁 set key random-value nx ex seconds # 解锁 if redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("del",KEYS[1]) else return 0 end
Distributed lock based on RedLock algorithm:
The implementation of the above distributed lock is based on a single master node. Its potential problems are shown in the figure below. If process A successfully locks the master node, and then the master node goes down, the slave node will be promoted to the master node. If process B locks the result on the new master node at this time, and then the original master node restarts and becomes a slave node, two locks will appear in the system at the same time, which violates the uniqueness principle of locks.
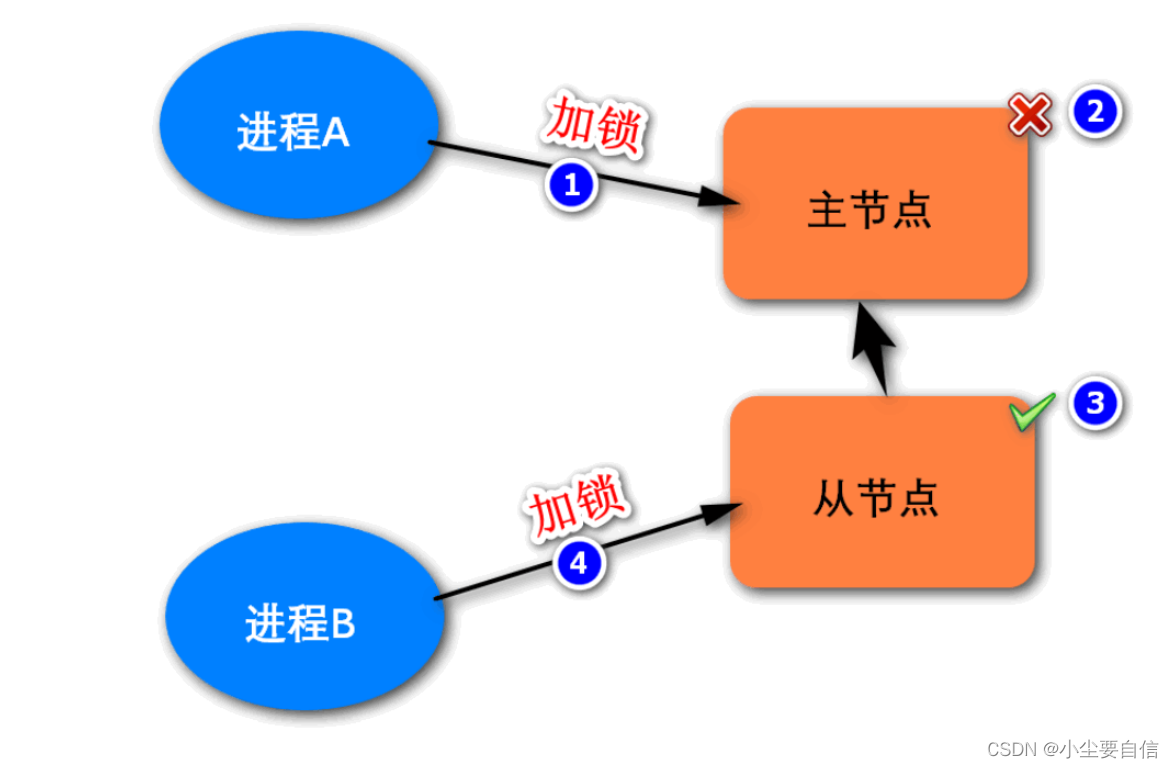
In short, implementing distributed locks on the architecture of a single master node cannot guarantee high availability. To ensure the high availability of distributed locks, multiple nodes can be implemented. There are many such schemes, and the official suggestion given by Redis is to use the implementation scheme of the RedLock algorithm. The algorithm is based on multiple Redis nodes, and its basic logic is as follows:
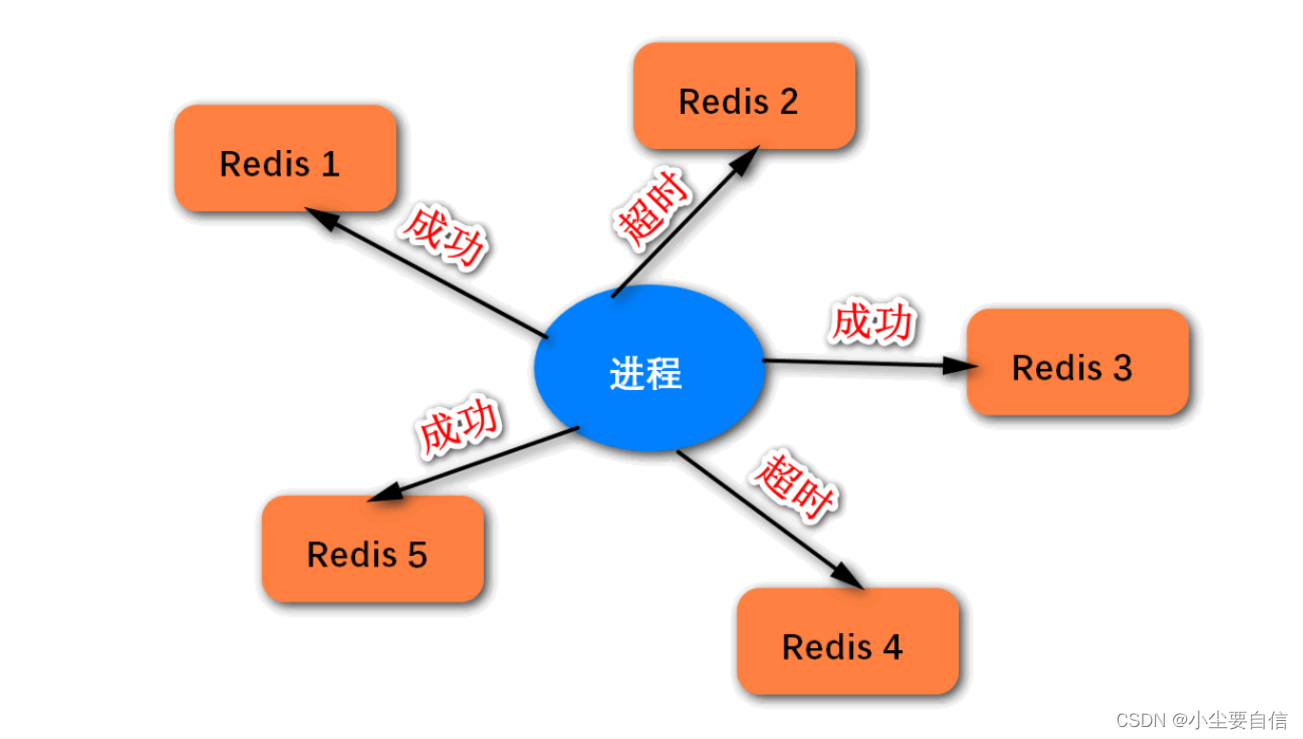
These nodes are independent of each other, and there is no master-slave replication or cluster coordination mechanism;
Locking: lock N instances with the same KEY, as long as more than half of the nodes succeed, the locking is deemed successful;
Unlock: send DEL command to all instances to unlock;
The schematic diagram of the RedLock algorithm is as follows. We can implement the algorithm by ourselves, or use the Redisson framework directly.
6. Talk about the understanding of Bloom filter
The Bloom filter can estimate whether the data actually exists at a very low cost. For example: when recommending news to users, to remove duplicate news, you can use the Bloom filter to determine whether it has been recommended.
The core of the Bloom filter consists of two parts:
1. A large bit array
2. Several different hash functions, each of which can calculate the hash value evenly.
Working principle:
1. Add key , each hash function uses this key to calculate a hash value, then calculates a position based on the hash value, and sets this position in the bit array to 1
2. When asking for a key: each hash function uses This key calculates a hash value, then calculates a position, and then compares the values of these hash functions in the corresponding positions in the bit array
**If one of these positions is 0, this value does not exist
** If all positions are 1, it means that it is very likely to exist. The reason why it is not 100% is because it may also be caused by calculation
7. How should multiple redis be designed to resist high concurrent access?
Redis cluster is a distributed solution of redis. It was officially launched in version 3.0. It effectively solves the distributed requirements of redis. When encountering bottlenecks such as stand-alone memory, concurrency, and traffic, you can use the cluster architecture solution to achieve load balancing. .
The redis cluster uses virtual machine slots to implement data sharding. It maps all constructions to integer slots of 0-16383 according to the hash function. The calculation formula is slot=crc16(key)&16383. Each node is responsible for maintaining a part of the slots. As well as the key-value data mapped by the slot, the virtual slot partition has the following characteristics:
1. Decoupling the relationship between data and nodes simplifies the difficulty of node expansion and contraction
2. The node itself maintains the mapping relationship of slots without the need for a client Or the proxy service maintains slot partition metadata
3. Supports mapping queries between nodes, slots, and keys, for scenarios such as data routing and online scaling.
8. What is the application scenario of redis?
There are too many scenarios where Redis is used in Internet products. Here are several data types of Redis:
1) String: cache, current limit, distributed lock, counter, distributed session, etc.
2) Hash: user information, user home page visits, combined query, etc.
3) List: simple queue, watch list timeline.
4) Set: like, dislike, label, etc.
5) ZSet: leaderboard, friend relationship list.
9. Why doesn't Zset use balanced trees such as red-black trees?
1) Jump table range query is simpler than balanced tree operation. Because the balanced tree needs to use in-order traversal to query the maximum value when the minimum value is queried. The jump list only needs to traverse the linked list of the first layer after finding the minimum value.
2) The deletion and insertion of the balanced tree requires corresponding adjustments to the subtrees, while the skip table only needs to modify the adjacent nodes.
3) The query operation of jump list and balanced tree is O(logN) time complexity.
4) On the whole, the difficulty of implementing the jump table algorithm is lower than that of the balanced tree.
10. What is RedisObject?
We know that the bottom layer of Redis implements many advanced data structures, such as simple dynamic strings, double-ended linked lists, dictionaries, compressed lists, jump lists, integer sets, etc. However, Redis does not directly use these data structures to implement the database of key-value pairs, but wraps a layer of RedisObject (object) on top of these data structures, which are the five data structures we often say: string objects, List objects, hash objects, collection objects, and sorted collection objects.
typedef struct redisObject {
// 类型
unsigned type:4;
// 编码,即对象的底层实现数据结构
unsigned encoding:4;
// 对象最后一次被访问的时间
unsigned lru:REDIS_LRU_BITS;
// 引用计数
int refcount;
// 指向实际值的指针
void *ptr;
} robj;
This has two advantages:
1) Through different types of objects, Redis can judge whether an object can execute the command according to the type of the object before executing the command.
2) According to different usage scenarios, different implementations can be set for objects to optimize memory or query speed.
11. Cache update strategy
Best practices for cache update strategies:
Low consistency requirements: use the memory elimination mechanism that comes with Redis
High consistency requirements: active update, and overtime elimination as a bottom-up solution
Read operation:
A cache hit returns directly
If the cache misses, query the database and write to the cache, set the timeout
Write operation:
Write to the database first, then delete the cache
To ensure the atomicity of database and cache operations
12. Redis network model
User space and kernel space
In order to avoid user applications causing conflicts or even kernel panics, user applications are separated from the kernel:
The addressing space of a process is divided into two parts: kernel space and user space.
User space can only execute limited commands (Ring3), and cannot directly call system resources, and must be accessed through the interface provided by the kernel.
Kernel space can execute privileged commands (Ring0) and call all system resources.
In order to improve IO efficiency, the Linux system will add buffers in both user space and kernel space:
When writing data, the user buffer data should be copied to the kernel buffer, and then written to the device.
When reading data, read data from the device to the kernel buffer, and then copy it to the user buffer.
13. How is the client routed?
Since the data in the Redis cluster is stored in fragments, how do we know which node a certain key exists on? That is, we need a query route that returns the address of the machine that stores the key value based on a given key.
The conventional implementation method is to use the proxy scheme shown in the figure below, that is, to use a central node (such as the NameNode in HDFS) to manage all metadata, but the biggest problem brought about by such a scheme is that the proxy node is easy to become an access bottleneck, when the concurrent reading and writing is high, the proxy node will seriously slow down the performance of the entire system.
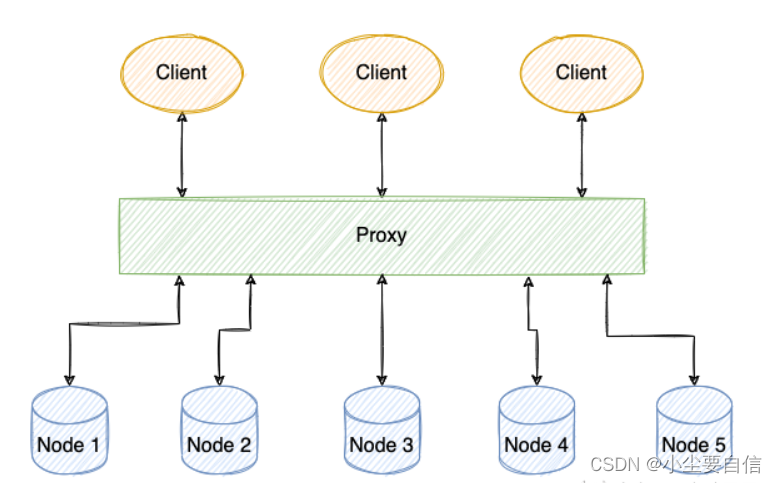
Redis does not choose to use a proxy, but the client connects directly to each node. Each node of Redis stores the state of the entire cluster, and an important piece of information in the cluster state is the responsible node for each bucket. In the specific implementation, Redis uses a clusterNode array slots whose size is fixed to CLUSTER_SLOTS to save the responsible node of each bucket.
typedef struct clusterNode {
...
unsigned char slots[CLUSTER_SLOTS/8];
...
} clusterNode;
typedef struct clusterState {
// slots记录每个桶被哪个节点存储
clusterNode *slots[CLUSTER_SLOTS];
...
} clusterState;
In cluster mode, when Redis receives any key-related command, it first calculates the bucket number corresponding to the key, and then finds the corresponding node according to the bucket. If the node is itself, it processes the key command; otherwise, it replies with a MOVED redirection error and notifies the client Request the correct node, this process is called MOVED redirection. The redirection information includes the bucket corresponding to the key and the address of the node responsible for the bucket. Based on this information, the client can initiate a request to the correct node.