1 Introduction
When we create jenkins tasks, sometimes a task needs to call multiple subtasks to complete. For example, when we compile a certain image, the image consists of multiple components. Then we can create a main task and multiple subtasks. The main task is responsible for calling each subtask and summarizing the results of each subtask, while the subtask is responsible for compiling each single component.
The relationship between main tasks and subtasks is as follows:

Each subtask is independent and has its own workspace.
Several concepts need to be distinguished here:
Tasks and jobs: Simply put, we can create multiple tasks on jenkins, each of which performs a different function. Every time a task is executed, it becomes a job, corresponding to a jobnum
Upstream task and downstream task: If the main task triggers (that is, calls) a subtask, then the main task becomes an upstream task, and naturally the subtask can become a downstream task.
Examples are as follows:
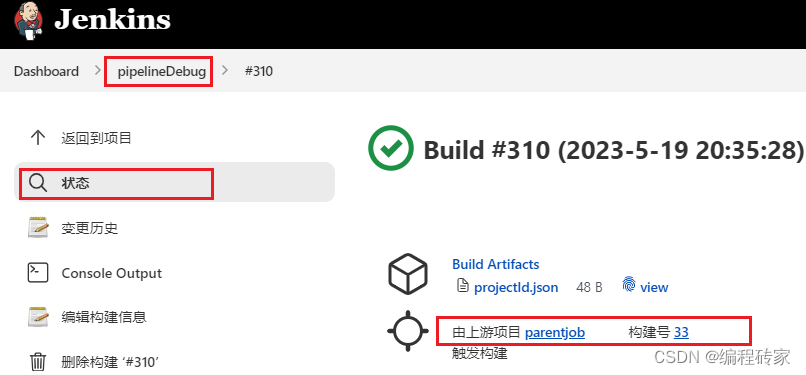
You can see that the current task name shown in the figure below is pipelineDebug. The jobnum built by this task is #310. This build is triggered by the upstream task (ie, the main task), and the corresponding upstream jobnum is 33.
2. How to call subtasks in the main task
From the above example, we see that the upstream task parentjob triggers the downstream task pipeDebug. So how to achieve it?
An example of a declarative script is as follows:
The basic format of the call is:
build job:"projectName", parameters:params
Simply put, only the name of the downstream task and the parameters passed to the downstream task are required.
pipeline {
agent any
parameters {
string(name: 'project_name', defaultValue: 'guest_os_image/windows/cloud_app/asp', description: '项目jar名称')
string(name: 'version', defaultValue: 'test', description: '部署环境')
string(name: 'user_name', defaultValue: 'aqsc', description: '操作系统登录名')
booleanParam(name: 'dryrun', defaultValue: true)
}
stages{
stage('test') {
steps {
script {
def myjob
myjob = build job :'pipelineDebug',parameters:[string(name: 'project', value: '/asp'),
string(name: 'version', value: 'dev')]
copyArtifacts( fingerprintArtifacts: true, projectName: 'pipelineDebug', selector: specific(job.getNumber().toString()))
}
}
}
}
}3. How does the upstream task obtain the result of the downstream task?
3.1 Upstream tasks copy files from downstream tasks
As mentioned earlier, each subtask was independent before. Although there is a call-to-call relationship between the upstream task and the downstream task, their workspaces are independent and generally run on different servers. There is isolation between. So how does the upstream task obtain the results of the downstream task?
A plugin is needed here: Copy Artifact
If the plugin is not installed, it needs to be installed before it can be used.

After installing the plug-in, the downstream task only needs to upload the file, and the upstream task only needs to copy the file , so that the upstream task can obtain the result of the downstream task.
If the downstream task generates a projectId.json, the upstream task needs to obtain the json file, as follows:
In the downstream task (pipeDebug), add a line of code to upload the file:
// 下游任务中上传文件
archiveArtifacts artifacts: 'projectId.json'The upstream task copies the uploaded file:
def job
job = build job :'pipelineDebug',parameters:[string(name: 'project', value: '/asp'),
string(name: 'version', value: 'dev')]
// 上游任务复制文件
copyArtifacts( fingerprintArtifacts: true, projectName: 'pipelineDebug', selector: specific(job.getNumber().toString()))Through the above two operations, it is realized. The file projectId.json in the downstream task is copied to the workspace of the upstream task .
3.2 The principle of upstream tasks copying files from downstream tasks
The previous section mentioned how upstream tasks copy files from downstream tasks. The operation is very simple, so now briefly talk about the principle of this implementation.
To understand this principle, you only need to figure out two questions:
Where is the so-called upload file of the downstream task uploaded? Where does the upstream task copy files from?
This may seem like two problems, but it's actually one.
The answer is the uploaded jenkins website, or the computer where the jenkin website is located.
Because different tasks can be created and triggered on the jenkins website, if the files are copied to the jenkins website, then naturally different tasks can share files.
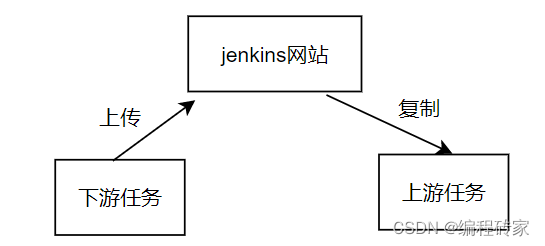
Because of this, we can see the uploaded file on the jenkins interface of the downstream task and can download it. As shown below:
