TorchScript Interpretation (4): Alias Analysis in Torch jit - Zhihu (zhihu.com)
The TorchScript series continues to be updated, let everyone wait for a long time. In the previous study, we have mastered some basic concepts of torch jit, learned how to convert a model written in python to torchscript and ONNX; and have been able to use some easy-to-use tools to generate passes and optimize the model .
OpenMMLab: Interpretation of TorchScript (1): Getting to know TorchScript for the first time
Some readers can write more complex and powerful passes to meet optimization needs, but more complex code means more potential risks, such as Data Hazards. And alias analysis is a tool to help us avoid some risks and write a safer pass. Today we will take you to get to know it together.
What is Alias Analysis
Torch jit has a lot of built-in passes to help us complete various optimizations, and users can also define their own passes to achieve specific purposes. This flexibility is convenient for us to optimize the model, but it is not without limitations. Take the following code and the corresponding visual image as an example:
def forward(self, x, y):
x = x + 1
x.add_(x)
return x + y
# graph(%self : __torch__.TestModel,
# %x.1 : Tensor,
# %y.1 : Tensor):
# %4 : int = prim::Constant[value=1]() # create_model.py:19:16
# %x0.1 : Tensor = aten::add(%x.1, %4, %4) # create_model.py:19:12
# %8 : Tensor = aten::add_(%x0.1, %x0.1, %4) # create_model.py:20:8
# %11 : Tensor = aten::add(%x0.1, %y.1, %4) # create_model.py:21:15
# return (%11)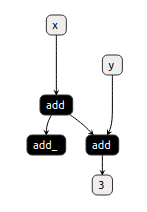
The neural network will form a calculation graph Graph. In principle, if a Node in a Graph cannot reach the output node through any path, then this is a useless node and can be optimized (deleted). For example, the node in the figure above add_ . This optimization is often called dead code elimination (DeadCodeElimination). It can be seen from the code that add_ the node is an inplace operation, which will update the value of x, and if it is deleted, it will cause wrong calculation results.
As can be seen from line 11 in the above code, add_ the output of is %8, if we know that it actually shares the same memory space %8 as its input , then we will avoid deleting this node to ensure the correctness of the optimization. %x0.1This is the role of Alias Analysis .
We can verify it with the following code:
#include <torch/csrc/jit/ir/alias_analysis.h>
#include <torch/script.h>
int main(int argc, char* argv[]) {
auto model = torch::jit::load(argv[1]); // 读取模型
auto graph = model.get_method("forward").graph(); // 提取计算图
torch::jit::AliasDb aliasdb(graph); // 创建AliasDb对象
aliasdb.dump(); // 可视化分析结果
return 0;
}
This program uses the alias analysis tool AliasDb provided by PyTorch to analyze the Graph of the forward function of the input model and visualize the analysis results. We input the model just now, and the result is as follows:
===1. GRAPH===
graph(%self : __torch__.TestModel,
%x.1 : Tensor,
%y.1 : Tensor):
%4 : int = prim::Constant[value=1]() # create_model.py:19:16
%x0.1 : Tensor = aten::add(%x.1, %4, %4) # create_model.py:19:12
%8 : Tensor = aten::add_(%x0.1, %x0.1, %4) # create_model.py:20:8
%11 : Tensor = aten::add(%x0.1, %y.1, %4) # create_model.py:21:15
return (%11)
===2. ALIAS DB===
%x.1 points to: WILDCARD for type Tensor
%y.1 points to: WILDCARD for type Tensor
%8 points to: %x0.1
%self points to: WILDCARD for type __torch__.TestModel
===3. Writes===
%8 : Tensor = aten::add_(%x0.1, %x0.1, %4) # create_model.py:20:8
%x0.1, You can see that there is such a line under ALIAS DB: %8 points to: %x0.1. Through this tool, you can know that the value %8 actually referenced participates in the calculation of the network output, so the calculation should not be deleted.%x0.1%x0.1%8
AliasDb
AliasDb is an alias analysis tool provided by PyTorch. With the help of AliasDb, we can analyze the relationship of each data node in the calculation graph to avoid potential wrong optimization.
MemoryDAG
MemoryDAG is a storage graph object, which is used by AliasDb to maintain dependencies between data. According to the source code https://github.com/pytorch/pytorch/blob/master/torch/csrc/jit/ir/alias_analysis.h . AliasDb receives a calculation graph Graph, and then creates a storage graph MemoryDAG. There is a corresponding relationship between this MemoryDAG and Graph, as shown in the following table:
| Graph | MemoryDAG | |
| picture | The Graph object maintains the structure of the calculation graph and describes the data flow during calculation | The MemoryDAG object maintains the storage graph structure and describes the reference (pointing) relationship between elements |
| node | Node represents each independent calculation, and the input and output are Value objects | Element represents the data storage information of one (or more) Value objects, including whether they refer to other Elements |
| side | The Use object indicates which Nodes the Value will be used by | The MemoryLocations object indicates which other Elements the Element may refer to |
Here are a few points to note:
- Element may not only point to Value, but may also be a container class or a wildcard, etc.
- There is not necessarily a one-to-one correspondence between Element and Value. For example, a branch structure
if condition: val=A else: val=Ballows Element to point to any one of A and B. - Based on the above reasons, the Element pointed to by MemoryLocations only represents one possibility.
When AliasDb receives a Graph, it will build the corresponding MemoryDAG object according to the information provided in the FunctionSchema of each Node to facilitate subsequent analysis.
If you don't remember what FunctionSchema is, you can review the basic knowledge in Torch jit tracer implementation analysis
view The FunctionSchema is as follows:
view(Tensor(a) self, int[] size) -> Tensor(a)
You can see that there is a mark in the first parameter self and the output (a) , indicating that the output may be an alias of the parameter self.
The following is the code representing a calculation graph Graph, and the visualization of the corresponding storage graph MemoryDAG:
@torch.jit.script
def foo(a : Tensor, b : Tensor):
c = 2 * b
a += 1
if a.max() > 4:
r = a[0]
else:
r = b[0]
return c, r
AliasDb can be used to easily query which Values other than output will be read or written by a Node , as shown in the following code. This is particularly important, as it relates to how we address data hazards in the future.
===3. Writes===
%8 : Tensor = aten::add_(%x0.1, %x0.1, %4) # create_model.py:20:8
%x0.1, There are many operations that may generate aliases. For example, if you use AliasDb for the following code 1, you will find some alias relationships as shown in code 2.
| def forward(self, x, y): # input x = x + 1 x.add_(x) # inplace operation y = y[0] # slice or select z = [x, y] # container class w = torch. cat(z) return w code 1 |
===2. ALIAS DB=== %x.1 points to: WILDCARD for type Tensor %8 points to: %x0.1 %z.1 contains: %x0.1%y0.1, %y.1 points to: WILDCARD for type Tensor %self points to: WILDCARD for type __torch__.TestModel %y0.1 points to: %y.1 代码2 |
It can be seen that the input of the graph, the operation of inplace, the slice and the use of the container class will create an alias relationship, and not only Tensor may have an alias relationship. In the above example, z is a list, which is also in the AliasDb record. So which types will AliasDb pay attention to?
mutable and wildcard sets
AliasDb introduces the concept of modifiable types (mutable) and non-modifiable types (immutable). The former refers to those data types whose internal values can change, such as Tensor, List, etc., and the type of the original object can be edited without creating a new object through operations such as inplace operation or append. And those types like int and string are immutable, and AliasDb can simply skip this part without analyzing it.
The Tuple type is special. If the internal elements are all immutable types, such as Tuple[int], then it is also an immutable type; if there is a mutable type inside, such as Tuple[Tensor], then it will also become a mutable type. Obviously, the fewer Values of the mutable type, the more likely the optimization will succeed.
In the object of mutable type, part will point to WILDCARD for type xxx, take the following code as an example:
%x.1 points to: WILDCARD for type Tensor
%y.1 points to: WILDCARD for type Tensor
%self points to: WILDCARD for type __torch__.TestModel This kind of object is called a wildcard set (wildcardSet), which means "the alias relationship of this value cannot be determined". For example, in the above code, x and y come from external input, and it is impossible to determine whether they share storage resources only by analyzing the Graph. If an object is marked as pointing to a wildcard set, many optimizations involving it should be avoided to prevent errors.
Data Hazards
With the above knowledge, we can write some safer passes. In the process of writing passes, AliasDb is most often used to solve data risk problems (Data Hazards).
For example: For example, if we want to insert a certain Node A before Node B, if B modifies the value of the variable type parameter x, and A wants to read the modified value of x, this insertion may cause errors. As shown in the code below:
# 原图,对B的写在对A的读之前
graph(...):
...
B: write(x)
...
A: read(x)
...
=> # 不合法的转换!A会读取到错误的值!
graph(...):
...
A: read(x)
B: write(x)
... Determining whether this type of read order change is legal requires knowing whether there is any overlap in the data space read and written between Nodes. getReads The and function is provided in AliasDb , and a Node is passed in as a parameter, and a MemoryLocations object is returned, indicating which mutable variables the Node will read/write. If you call and getWrites on the above A and B respectively, you will find that there is an overlap in the MemoryLocations between them (intersects), this exchange should not take place. As shown in the following code:getReadsgetWrites
auto loc_a = alias_db.getReads(A);
auto loc_b = alias_db.getWrites(B);
bool valid = !loc_a.intersects(loc_b);
moveAfterTopologicallyValid Functions are provided in AliasDb moveBeforeTopologicallyValid to help us accomplish this task more easily. This task will check before moving, if the move is found to be legal, it will be moved. Here we first introduce the concept of a working set (WorkingSet).
A WorkingSet is a collection of Nodes, any Node in the collection satisfies:
- Either have a direct connection in the Graph to at least one other Node in the set.
- Either there are intersects of reading and writing MemoryLocations with at least one other Node in the collection (must be a read and a write).
If a Node and WorkingSet outside the set satisfy one of the above relationships, then we say that the Node " depends " (dependOn) on the WorkingSet.
WorkingSet can assist us in legality checking, consider the example of moveAfter:
Assuming that we want to toMove move to the immediate movePoint front, there are two situations:
toMoveaftermovePoint_toMovebeforemovePoint_
First, we need to construct a WorkingSet, and then toMove insert it WorkingSet, and then traverse all the nodes toMovebetween movePoint (not including movePoint ) n, if n depends on this WorkingSet, then insert it.
If it is case 1, move directly according to the way in the comments below:
// `movePoint` <dependencies> |
// <dependencies> -> `toMove` | `toMove` 和依赖一起移动
// `toMove` `movePoint` |
If it is case 2, which is toMove before movePoint , then toMove finally WorkingSet remove from this. Before removing, this is WorkingSet checked for legality:
- If
movePointyou depend on theWorkingSet - If any node
WorkingSetin (including ) has side effects, such as inplace operationtoMove
If there is any one of the above two situations, it is considered that the move is illegal and the move will not be executed.
After the legality check is passed, it will be moved according to the method in the annotation below:
// `toMove` `toMove` |
// <dependencies> -> `movePoint` | `toMove` 和依赖被分开
// `movePoint` <dependencies> |
WorkingSet All Nodes involved in the move include . Such moves are safe and will not cause read-write conflicts.
The content introduced above is encapsulated in the following function, and you can judge whether the move is legal according to the return value:
bool success = moveBeforeTopologicallyValid(A, B);
// 如果 move 合法则进行move,返回true。否则不进行任何操作,返回false。 Summarize
While the flexibility of Jit pass brings convenience to model optimization, it also introduces some risks, and the alias analysis tool AliasDb is one of the powerful tools to solve these risks. AliasDb uses MemoryDAG to manage memory, distinguish between mutable and immutable data types, and help us avoid data risks. Combining the knowledge of the previous two chapters, you should have a preliminary understanding of the generation and optimization of the jit model. In the future, we will start with practical examples and introduce how MMDeploy uses these tools to optimize models, so stay tuned.
https://github.com/open-mmlab/mmdeploygithub.com/open-mmlab/mmdeploy
Series Portal
OpenMMLab: Interpretation of TorchScript (1): Getting to know TorchScript for the first time
OpenMMLab: Interpretation of TorchScript (4): Alias analysis in Torch jit
OpenMMLab: Introduction to Model Deployment (1): Introduction to Model Deployment
OpenMMLab: Introduction to Model Deployment Tutorial (2): Solving Difficulties in Model Deployment
OpenMMLab: Introductory Tutorial for Model Deployment (3): PyTorch to ONNX Detailed Explanation