Table of contents
2.2. Transaction isolation level
2.2.1. Three kinds of data consistency problems
2.3. How to set the isolation level
3.1. The relationship between locks and transactions
3.4.5. Change row lock to table lock
1 Overview
The so-called concurrency control is to avoid data consistency problems such as dirty data caused by multiple sessions concurrently accessing the database. MySQL provides a series of mechanisms for us to perform concurrency control.
Essentially, MySQL uses two types of locks for concurrency control, one is a table lock, which locks the entire table; the other is a row lock, which locks a certain data row.
Usually, when we use it, we seldom directly operate locks, because MySQL has already packaged them well for us. Directly using the innodb engine + transactions can perform concurrency control very well. The bottom layer of transactions actually relies on row locks.
This article will talk about transactions first, then table locks and row locks, but in fact, in general, MySQL performs concurrency control, which is row locks and table locks. The bottom layer of transactions uses row locks, but transactions are too important, so they are taken out separately. Talk as an independent chapter.
2. Affairs
2.1. What is a transaction
Note: Only the InnoDB engine supports transactions, so the discussions related to transactions in this article are all under the InnoDB engine by default.
In actual use, there will be such a scenario. We hope that several SQLs will either succeed or fail at the same time. Some cannot succeed and some fail.
For example, when placing an online shopping order, the two SQLs of generating the order and deducting the inventory must be guaranteed to either succeed or fail. It cannot be said that the generation of the order is successful, but the deduction of the inventory fails, or that the deduction of the inventory is successful but the generation of the order fails. Any of the above situations will generate dirty data. If one of the two fails, the other one also needs to be executed unsuccessfully to ensure the correctness of the data.
Transactions are created to satisfy the need to bundle multiple transactions together, with the same success and failure. In the process of implementing transactions, people find that in order to achieve the effects we mentioned above, four points must be achieved:
- Atomicity
- Consistent
- Isolation
- Durable
That is the well-known ACID, which is called the four characteristics of transactions in many places.
1. Atomicity:
A transaction is an atomic operation unit, and all modifications to data are either executed or not executed at all.
2. Consistency:
Data in a database is always going from one state to another, there can be no intermediate states. Continuing to take the online shopping order as an example, the data in the database at the beginning is in the A state, after the transaction is executed, the inventory is deducted, and the new order is added, the data state is in the B state. The database can only go from A to B. Inventory, no order generated, or an intermediate state such as an order is generated, but inventory is not deducted.
3. Isolation:
Modifications made by a transaction are not visible to other transactions until they are committed. It is easy to understand that dirty data will be generated without guaranteeing isolation. For example:
A's bank account has 400, and there are two transactions, and the data between them is visible, that is, one transaction modifies the data, and other transactions can be seen regardless of whether they are submitted or not.
Transaction 1, A transfers 200 to B:
- A's account deducts 200
- B's account adds 200
Transaction 2, A transfers 200 to C:
- A's account deducts 200
- C's account adds 200
If transaction 2 is executed interspersedly within the time gap between steps 1 and 2 in transaction 1, then before the execution of step 2 of transaction 1, A’s account has been deducted twice 200, and the balance is 0, and C’s account 200 more.
At this time, if there is an error in the second step of transaction 1 and rollback, then A's account will return to the state before the execution of the first step of transaction 1, that is, A's account will be restored to 400. In the end, C's account increased by 200 for no reason.
4. Persistence:
After the transaction is completed, its modification to the data is permanent, even if the system is powered off or restarted, it will not change.
2.2. Transaction isolation level
2.2.1. Three kinds of data consistency problems
In the absence of isolation, there are three data consistency problems between things:
- Dirty read: Transaction A reads the data updated by transaction B, and then B rolls back the operation, then the data read by A is dirty data
- Non-repeatable read: Transaction A reads the same data multiple times, and transaction B updates and submits the data during the multiple reads of transaction A, resulting in inconsistent results when transaction A reads the same data multiple times.
- Phantom reading: System administrator A changes the grades of all students in the database from specific scores to ABCDE grades, but system administrator B inserts a record of specific scores at this time. After the modification, system administrator A finds that there are still If a record has not been changed, it seems to be hallucinating, which is called phantom reading.
2.2.2. Four isolation levels
The isolation level can be understood as the strictness of isolation. MySQL is not fixed to make each transaction unreadable, but specifies isolation levels of various strengths.
Observing the above three data consistency problems, you will find that the isolation required to solve them is increasing. MySQL provides a total of four isolation levels, and the isolation is also increasing. Corresponding to the above three problems, there are three types, plus 1 and 3 types of problems can be covered and solved:
-
Read Uncommitted (read uncommitted): The lowest isolation level that allows a transaction to read data changes that have not yet been committed by another transaction. May cause dirty read (Dirty Read) problems.
-
Read Committed (read committed): Ensure that a transaction can only read data changes that have been committed by another transaction. Prevent dirty read problems, but may cause non-repeatable read (Non-repeatable Read) problems.
-
Repeatable Read (repeatable read): Ensure that when the same data is read multiple times in the same transaction, consistent results can be obtained. Prevent dirty reads and non-repeatable reads, but may cause phantom reads (Phantom Read) problems.
-
Serializable: The highest isolation level, forcing transactions to execute serially, ensuring that dirty reads, non-repeatable reads, and phantom reads do not occur. However, the concurrency performance is poor, and it is generally not recommended to be used in a high-concurrency environment.
2.3. How to set the isolation level
The isolation level can be set in the connection string:
jdbc:mysql://localhost/mydatabase?useSSL=false&characterEncoding=utf8&transactionIsolation=隔离级别
The isolation level can be set in the session via SQL:
SET TRANSACTION ISOLATION LEVEL 隔离级别;
3. lock
3.1. The relationship between locks and transactions
Lock is a mechanism for a computer to coordinate multiple processes or threads to access a certain resource concurrently, and is used to solve the data consistency problem caused by concurrent access. In the database, in addition to the contention of traditional computing resources (such as CPU, IO, RAM), data is a resource that will be accessed concurrently. Therefore, the MySQL database also uses a lock mechanism to ensure the consistency of concurrent access to data.
The bottom layers of different isolation levels are implemented with different locks.
3.2. Classification
MySQL locks can be divided from two dimensions,
A dimension is divided into:
- row lock
- table lock
Another dimension is based on whether the lock operation is a read operation or a write operation, which is divided into:
- read lock
- write lock
3.3. Table lock
3.3.1. Overview
Both the innodb engine and myisam engine in MySQL support locking tables with the lock tables command.
3.3.2. Read lock
Read lock, a shared lock, for the locked table, all sessions can perform read operations, and all sessions cannot perform write operations. The difference between the locker and other clients is that the locker is directly not allowed to perform write operations, while the write operations of other sessions are allowed, but will be blocked and suspended. After the lock is unlocked, all suspended operation threads will compete for resources again.
Lock command:
lock tables 表名 read;Release lock command:
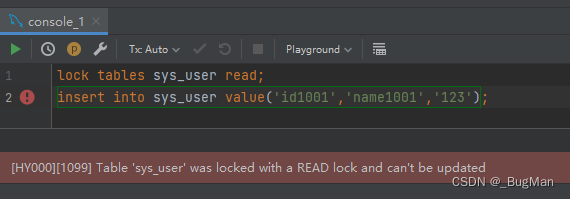
unlock tanles;The locking party does not allow write operations:
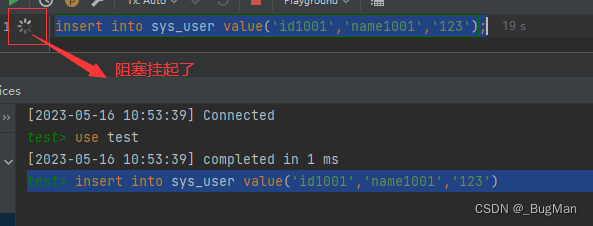
Write operations by other clients are suspended until the locker releases the lock:
3.3.3. Write lock
Write lock, exclusive lock, for the locked table, the locker can read and write, the write operation of other sessions will directly fail, and the read operation will be blocked and suspended. After unlocking, the suspended thread will compete for resources again .
Lock command:
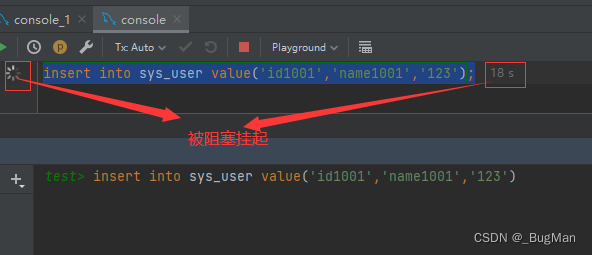
lock tables 表名 write;The read and write operations of other sessions are blocked and suspended until the locker releases the lock:
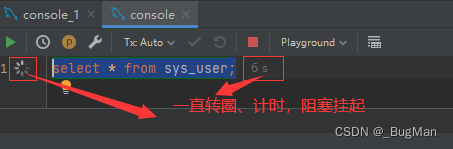
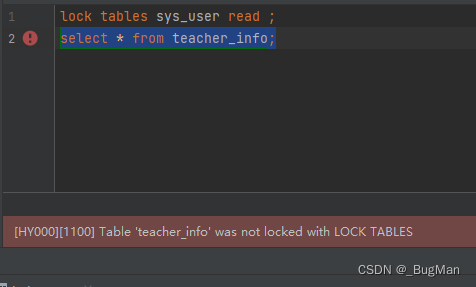
3.3.4. Protection mechanism
In read locks and write locks, the locker can only read the table that is currently locked by itself. This is a protection mechanism of MySQL, in order to force the locker to give a statement, how long the lock is going to be, and not give a statement. Do not let go.
3.4. Row lock
3.4.1. Overview
There are two biggest differences between innodb and myIsam, one is to support transactions, and the other is to support row-level locks.
3.4.2. What is MVCC
There is no explicit declaration method for row locks, but hidden in the default implementation. MVCC is the default concurrency control mechanism of the MySQL InnoDB storage engine, which uses table locks.
There are several approaches to concurrency control,
The first type: lock-based concurrency control. When programmer B starts to modify the data, he adds a lock to the data. Programmer A reads it again at this time, but finds that it cannot be read. It is in a waiting state and can only wait for B to complete the operation. Read data, which ensures that A will not read an inconsistent data, but this will affect the efficiency of the program.
The second type: MVCC, when each user connects to the database, what he sees is a database snapshot at a specific time. Before B’s transaction is committed, A always reads the database snapshot at a specific time. After reading the data modification in transaction B, the modified content of B will not be read until transaction B is committed.
MVCC is actually the key to realizing transactions. There will be articles dedicated to in-depth discussion on the realization of transactions in the future, which will not be expanded here.
3.4.3. Use of mvcc
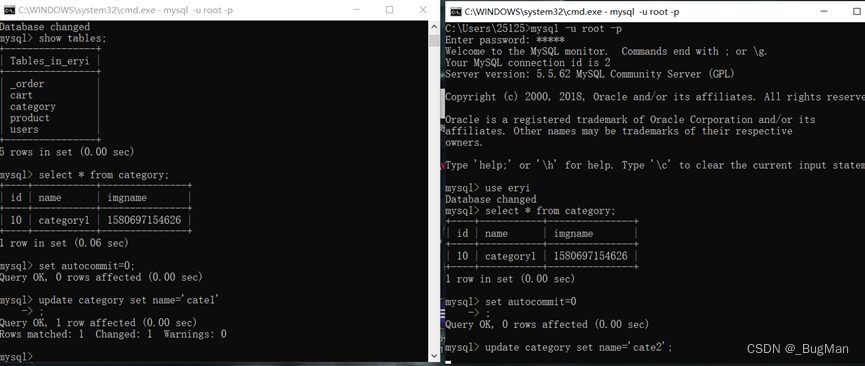
First of all, one thing that needs to be corrected is that many places say that mvcc is triggered by manual submission, which is misleading. The MVCC mechanism is effective regardless of manual submission or automatic submission, but manual submission is more intuitive to observe the mvcc process.
Here, for the sake of intuition, we also take manual submission as an example. First, you can turn off automatic submission by setting autocommit=0. After each execution of sql after closing, the database will be affected only by manual submission through the commit command, otherwise it will only affect the data snapshot of the current operator. In the innodb engine, other clients who want to view the latest data must also perform a synchronization through the commit command (because the default isolation level of innodb is repeatable read).
When a session modifies a row of data, before committing, other sessions will block and suspend the modification of the row of data until the session commits first.
3.4.4. Gap lock
When using range condition matching, InnoDB will add "range lock" to the index of existing data records that meet the conditions (range lock is a special row lock). For records whose key value is within the condition range but does not exist, it is called a gap ( GAP), innodb will also lock this gap, this mechanism is called "gap lock".

3.4.5. Change row lock to table lock
Row locks are escalated to table locks whenever a full table scan is required.
Because MySQL doesn't know which row to lock, it will lock the entire table and then perform a full table scan.
There are no more than two types of full table scans:
- Not indexed.
- Index invalid.