
In today’s Internet business, the most widely used database is undoubtedly the relational database MySQL. The reason for using the word "or" is because the domestic database field has also made some great progress in recent years, such as TIDB, OceanBase, etc. Distributed databases, but they have not yet formed absolute coverage, so at this stage, we still have to continue to learn MySQL database to deal with some problems encountered in the work, and the investigation of the database part during the interview.
Today's content will talk to you about the core issues of concurrency control, transactions, and storage engines in the MySQL database. The knowledge graph involved in this content is shown below:

Concurrency control
Concurrency control is a huge topic. As long as there are multiple requests to modify data at the same time in a computer software system, concurrency control problems will arise, such as multi-thread security in Java. Concurrency control in MySQL mainly discusses how the database controls the concurrent reading and writing of table data.
For example, there is a table useraccount whose structure is as follows:
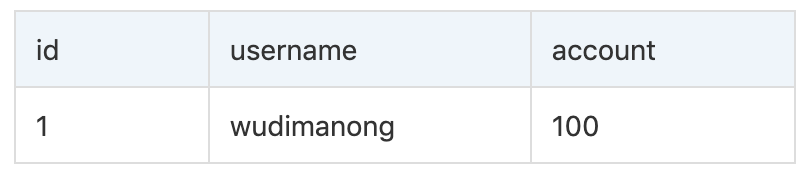
At this time, if the following two SQL statements initiate a request to the database at the same time:
SQL-A:
update useraccount t set t.account=t.account+100 where username='wudimanong';
SQL-B:
update useraccount t set t.account=t.account-100 where username='wudimanong'
When all the above statements are executed, the correct result should be account=100, but in the case of concurrency, such a situation may occur:
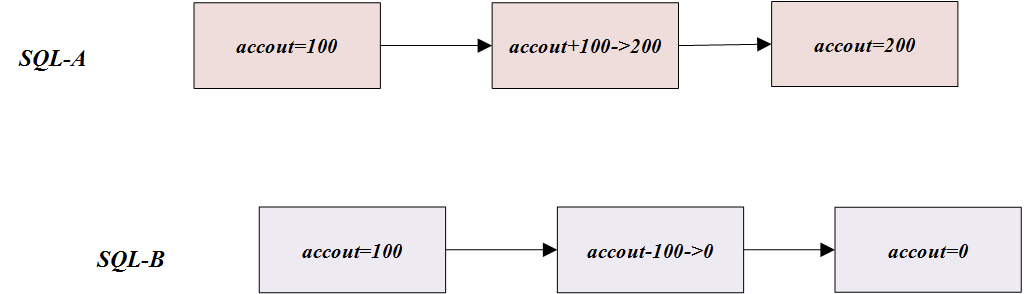
So how is concurrency control in MySQL? In fact, like most concurrency control methods, the lock mechanism is also used in MySQL to achieve concurrency control.
1. MySQL lock type
In MySQL, concurrency control is mainly achieved through "read-write locks".
**Read lock: **Also called share lock, multiple read requests can share a lock to read data at the same time without blocking.
**Write lock: **Also called exclusive lock, the write lock will exclude all other requests to acquire the lock and will block until the write is completed and the lock is released.
The read-write lock can achieve parallel read and read, but cannot achieve parallel read, write, and write. The transaction isolation that will be mentioned later is achieved based on the read-write lock!
2. MySQL lock granularity
The above-mentioned read-write locks are divided according to the lock type of MySQL, and the granularity that the read-write locks can impose is mainly reflected in tables and rows in the database, also known as table locks and row locks. ) .
Table lock (table lock) : It is the most basic locking strategy in MySQL. It locks the entire table, so that the overhead of maintaining the lock is minimal, but it will reduce the efficiency of reading and writing the table. If a user implements a write operation (insert, delete, update) to the table through a table lock, then first needs to obtain a write lock that locks the table, then in this case, other users' reading and writing to the table will be blocked . Under normal circumstances, statements such as "alter table" will use table locks.
Row locks : Row locks can support concurrent reads and writes to the greatest extent, but the overhead of database maintenance locks will be relatively large. Row locks are the most commonly used lock strategy in our daily life. Generally, row-level locks in MySQL are implemented by specific storage engines, not at the MySQL server level (table locks will be implemented at the MySQL server level).
3. Multi-version concurrency control (MVCC)
MVCC (MultiVersion Concurrency Control), multi-version concurrency control. In most MySQL transaction engines (such as InnoDB), row-level locks are not simply implemented, otherwise there will be such a situation: "During the period when data A is updated by a certain user (acquiring row-level write lock), other users Reading this piece of data (acquiring a read lock) will be blocked ". But the reality is obviously not the case. This is because the MySQL storage engine is based on the consideration of improving concurrency performance. Through MVCC data multi-version control, read and write separation is achieved, so that data can be read without locks and read and write parallel.
Take the MVCC implementation of the InnoDB storage engine as an example:
InnoDB's MVCC is implemented by storing two hidden columns behind each row of records. Of these two columns, one holds the creation time of the row, and the other holds the expiration time of the row. Of course, what they store is not the actual time value, but the system version number. Every time a new transaction is opened, the system version number will be automatically incremented; the system version number at the beginning of the transaction will be used as the version number of the transaction to compare with the version number of each row of the query.
The main means that MVCC relies on in MySQL are " undo log and read view ".
-
undo log: undo log is used to record multiple versions of a row of data.
-
read view: used to determine the visibility of the current version of the data
The undo log will be introduced later in the transaction. The schematic diagram of the read and write principle of MVCC is as follows: The
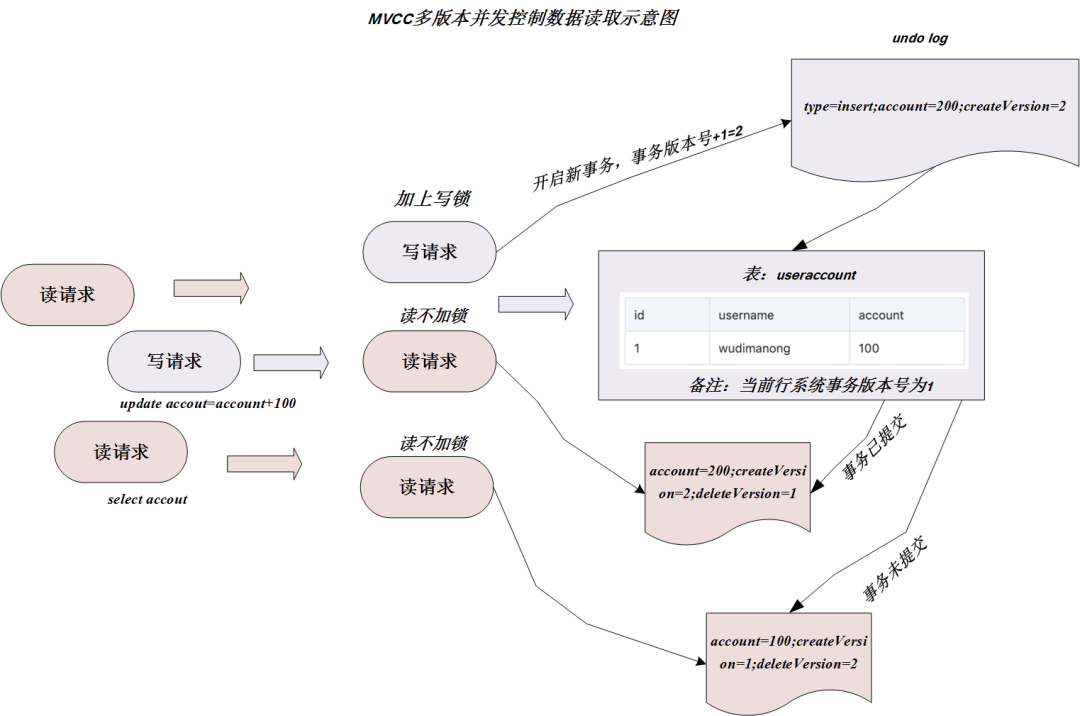
above figure demonstrates the MySQL InnoDB storage engine. Under the REPEATABLE READ (repeatable read) transaction isolation level, two additional system version numbers are saved (row creation version number, row deletion version number) Realize MVCC, so that most read operations can be read without additional lock. This design makes data reading operations easier and better performance.
So how does the data read operation in MVCC mode ensure that the data is read correctly? Taking InnoDB as an example, each row of records will be checked according to the following two conditions when selecting:
-
Only find data rows whose version number is less than or equal to the current transaction version. This ensures that the rows read by the transaction either existed before the transaction started, or were inserted or modified by the transaction itself.
-
The delete version number of the row is either undefined or greater than the current transaction version number. This ensures that the rows read by the transaction are not deleted before the transaction starts.
Only records that meet the above two conditions can be returned as the result of the query! Take the logic shown in the figure as an example. In the process of changing the account to 200 in the write request, InnoDB will insert a new record (account=200), and use the current system version number as the line creation version number (createVersion=2). At the same time, the current system version number is used as the original row to delete the version number (deleteVersion=2), then there are two versions of the data copy for this data, as follows:
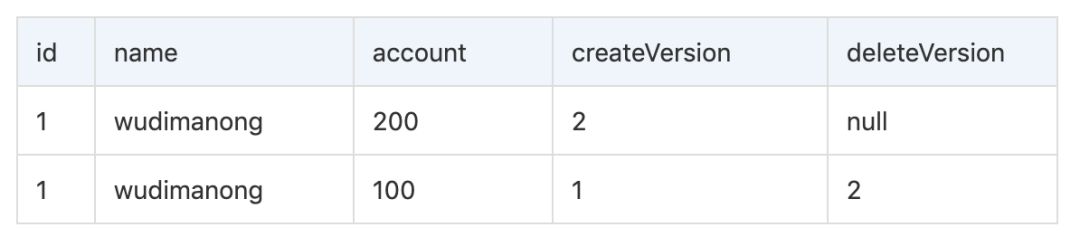
If the write operation has not ended, the transaction is for other users It is temporarily invisible. According to the Select check condition, only records with accout=100 are eligible, so the query result will return records with account=100!
The above process is the basic principle of the InnoDB storage engine on the implementation of MVCC, but later you need to pay attention to the logic of MVCC multi-version concurrency control can only work under the two transaction isolation levels " REPEATABLE READ (repeatable read) and READ COMMITED (commit read)" . The other two isolation levels are not compatible with MVCC, because READ UNCOMMITED (uncommitted read) always reads the latest data row, not the data row that conforms to the current transaction version; and SERIALIZABLE will add to all read rows The lock does not conform to the MVCC idea.
MySQL transaction
In the previous explanation about the process of MySQL concurrency control, the transaction-related content was also mentioned. Next, we will sort out the core knowledge about the transaction more comprehensively.
I believe that everyone has used database transactions in the daily development process, and they can open their mouths on the characteristics of transactions-ACID. So how is it implemented inside the transaction? In the following content, let's talk about this issue in detail with you!
1. Business overview
The effect to be achieved by the database transaction itself is mainly reflected in: **"reliability" and "concurrent processing"** these two aspects.
-
Reliability: The database must ensure that the data operation is consistent when an insert or update operation throws an exception, or the database crashes.
-
Concurrent processing: It means that when multiple concurrent requests come, and one of the requests is to modify the data, in order to avoid other requests from reading dirty data, it is necessary to isolate the read and write between transactions.
There are three main technologies to realize the MySQL database transaction function, namely log files (redo log and undo log), lock technology and MVCC.
2.redo log与undo log
Redo log and undo log are the core technologies to realize MySQL transaction function.
1)、redo log
Redo log is called redo log and is the key to achieving transaction durability. The redo log log file is mainly composed of two parts: redo log buffer (redo log buffer), redo log file (redo log file) .
In order to improve database performance in MySql, every modification will not be synchronized to disk in real time, but will be stored in a buffer pool called "Boffer Pool", and then background threads will be used to implement buffer pool and disk. Synchronization between.
If you adopt this model, there may be such a problem: if there is a downtime or power outage before the data is synchronized, then you may lose some of the modification information of the committed transaction! This situation is unacceptable for database software.
Therefore, the main function of redo log is to record the modification information of the successfully committed transaction, and it will persist the redo log to the disk in real time after the transaction is submitted, so that the redo log can be read to restore the latest data after the system restarts.
Next, we take the transaction opened by SQL-A as an example to demonstrate how the redo log works, as shown in the figure below:
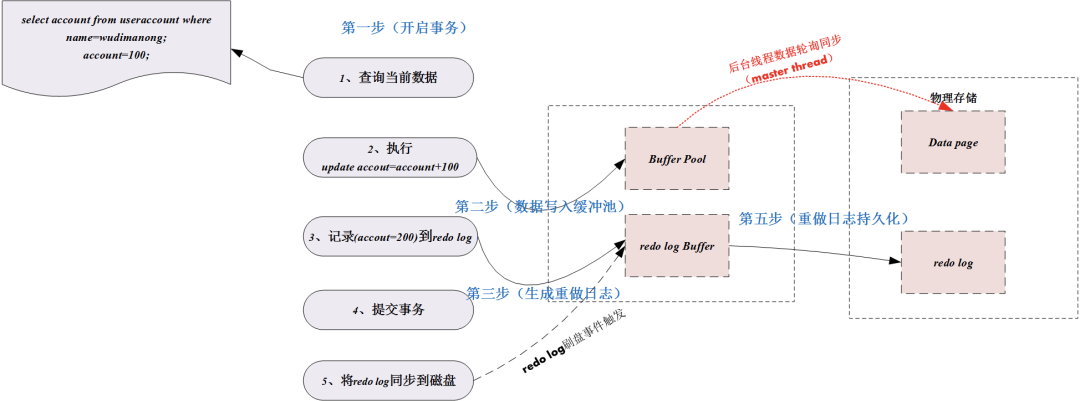
As shown in the figure above, when the transaction that modifies a row of records is opened, the MySQL storage engine removes the data from The disk is read into the buffer pool of the memory for modification. At this time, the data in the memory is modified and the data in the disk is different. This kind of difference data is also called **"dirty page"**.
In general, the storage engine does not flush dirty pages back to disk every time a dirty page is generated, but uses a background thread **"master thread"** to run roughly once every second or once every 10 seconds. The frequency to refresh the disk. In this case, if the database is down or out of power, the data that has not been flushed back to the disk may be lost.
The role of redo log is to reconcile the speed difference between memory and disk. When the transaction is submitted, the storage engine will first write the data to be modified into the redo log, then modify the real data page in the buffer pool, and refresh the data synchronization in real time. If during this process, the database is hung up, since the redo log physical log file has recorded transaction modifications, the transaction data can be recovered based on the redo log after the database is restarted.
2)、undo log
Above we talked about the redo log log, which is mainly used to restore data and ensure the persistence of committed transactions. There is another very important log type undo log in MySQL, also called rollback log. It is mainly used to record information before data is modified, which is the opposite of redo log, which records information after data is modified.
The undo log mainly records the data information of the previous version of the transaction modification. If it is rolled back due to a system error or rollback operation, the data can be rolled back to the state before it was modified according to the undo log log.
Every time data is written or modified, the storage engine will record the information before modification in the undo log.
3. The realization of the transaction
Earlier we talked about locks, multi-version concurrency control (MVCC), redo log (redo log), and rollback log (undo log), which are the basis for MySQL to implement database transactions. From the four major characteristics of transactions, the corresponding relationship is mainly reflected as follows:
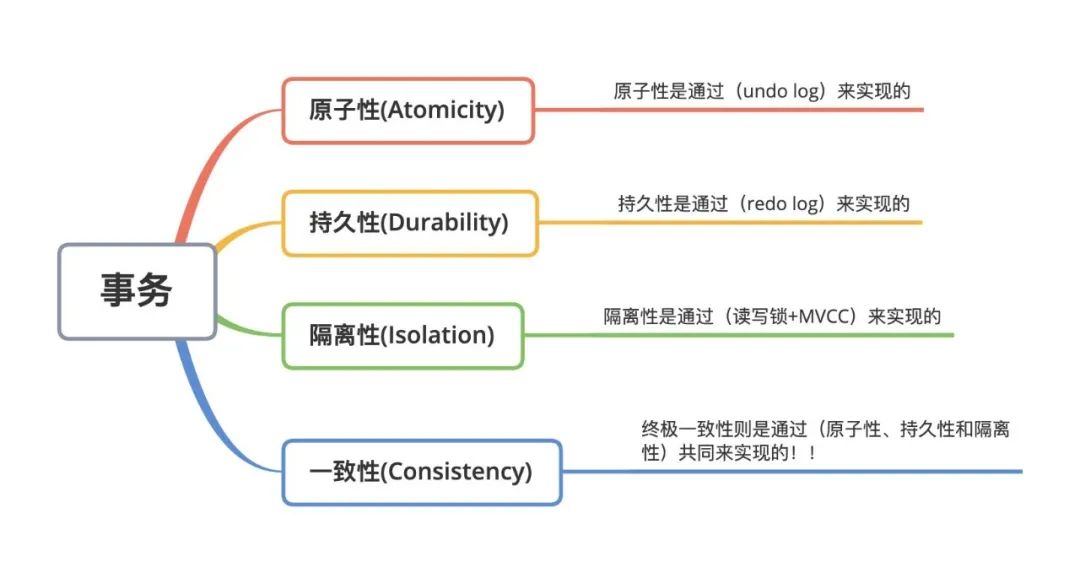
In fact, the ultimate purpose of transaction atomicity, durability, and isolation is to ensure the consistency of transaction data. ACID is just a concept, and the ultimate goal of transactions is to ensure the reliability and consistency of data.
Next, we will analyze the implementation principle of the ACID feature of the transaction.
1), the realization of atomicity
Atomicity means that a transaction must be regarded as an indivisible smallest unit. All operations in a transaction are either executed successfully or all failed and rolled back. It is impossible for a transaction to perform only part of the operations. This is The concept of transaction atomicity.
The atomicity of MySQL database is mainly achieved through rollback operations. The so-called rollback operation is to restore the data to the original appearance when an error occurs or the rollback statement is executed explicitly, and this process needs to be carried out with the help of undo log. The specific rules are as follows:
-
Each data change (insert/update/delete) operation is accompanied by the generation of an undo log, and the rollback log must be persisted to disk before the data;
-
The so-called rollback is to perform reverse operations based on the undo log log. For example, the reverse operation of delete is insert, the reverse operation of insert is delete, and the reverse operation of update is update, etc.;
2), the realization of persistence
Persistence refers to the fact that once the transaction is committed, the changes made will be permanently saved in the database. At this time, the modified data will not be lost even if the system crashes.
The durability of the transaction is mainly achieved through the redo log. The redo log log can make up for the data difference caused by cache synchronization, mainly because it has the following characteristics:
-
Redo log storage is sequential, while cache synchronization is a random operation;
-
Cache synchronization is based on data pages, and the size of data transmitted each time is larger than the redo log;
For the logic of redo log to achieve transaction persistence, please refer to the content of redo log earlier in this article!
3), the realization of isolation
Isolation is the most complicated of the ACID characteristics of transactions. Four isolation levels are defined in the SQL standard. Each isolation level specifies the modification in a transaction. Those are visible between transactions and those are invisible.
There are four MySQL isolation levels (from low to high):
-
READ UNCOMMITED (read uncommitted);
-
READ COMMITED
-
REPEATABLE READ (repeatable read)
-
SERIALIZABLE (Serializable)
The lower the isolation level, the higher the degree of concurrency that the database can perform, but the greater the complexity and overhead of the implementation. As long as you thoroughly understand the isolation level and its implementation principles, it is equivalent to understanding the transaction isolation in ACID.
As mentioned earlier, the purpose of atomicity, persistence, and isolation is ultimately to achieve data consistency, but isolation is different from the other two. Atomicity and persistence are mainly to ensure the reliability of data. For example, data recovery after downtime and data rollback after errors. The core goal of isolation is to manage the access sequence of multiple concurrent read and write requests to achieve safe and efficient access to database data, which is essentially a trade-off game between data security and performance.
High-reliability isolation level, low concurrency performance (for example, SERIALIZABLE isolation level, because all reads and writes will be locked); low reliability, high concurrency performance (for example, READ UNCOMMITED, because reads and writes are not locked at all).
Next, we will analyze the characteristics of these four isolation levels separately:
READ UNCOMMITTED
Under the READ UNCOMMITTED isolation level, even if the modification in a transaction has not been committed, it is visible to other transactions, which means that the transaction can read uncommitted data.
Because reading does not add locks, write operations modify data during the reading process will cause "dirty reads". The uncommitted read isolation level read and write diagram is as follows:
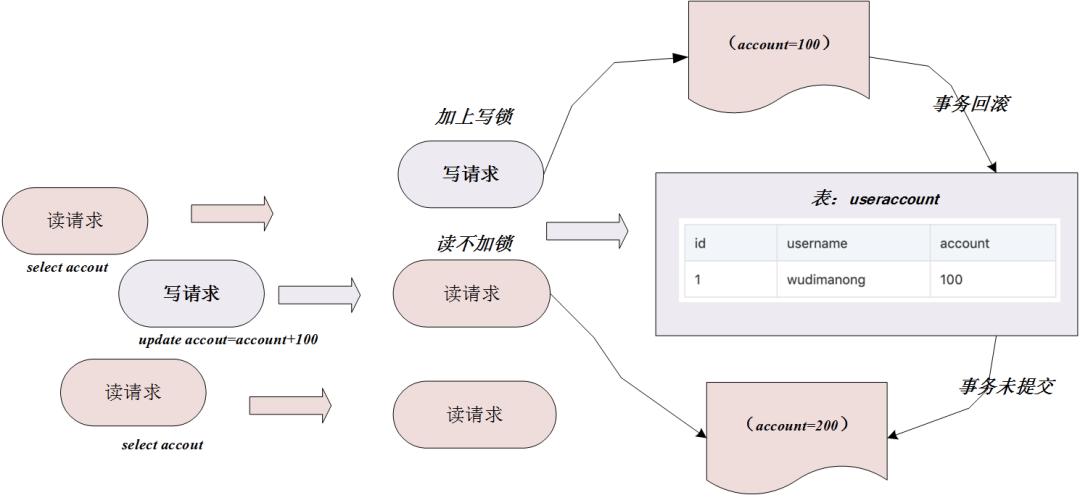
as shown in the figure above, the write request changes the account to 200, and the transaction is not committed at this time; but the read request can read the uncommitted transaction data account=200; then the write request transaction fails Roll back account=100; then the data with account=200 read by the read request at this time is dirty data.
The advantage of this isolation level is parallel read and write and high performance; but the disadvantage is that it is easy to cause dirty reads. Therefore, this isolation level is not generally adopted in the MySQL database!
READ COMMITED
This transaction isolation level is also called ** "non-repeatable read or commit read". **Its characteristic is that all modifications of a transaction before it is committed are invisible to other transactions; other transactions can only read the committed changes.
This isolation level looks perfect and is in line with most logical scenarios, but this transaction isolation level will have the problems of "non-repeatable" and "phantom reading".
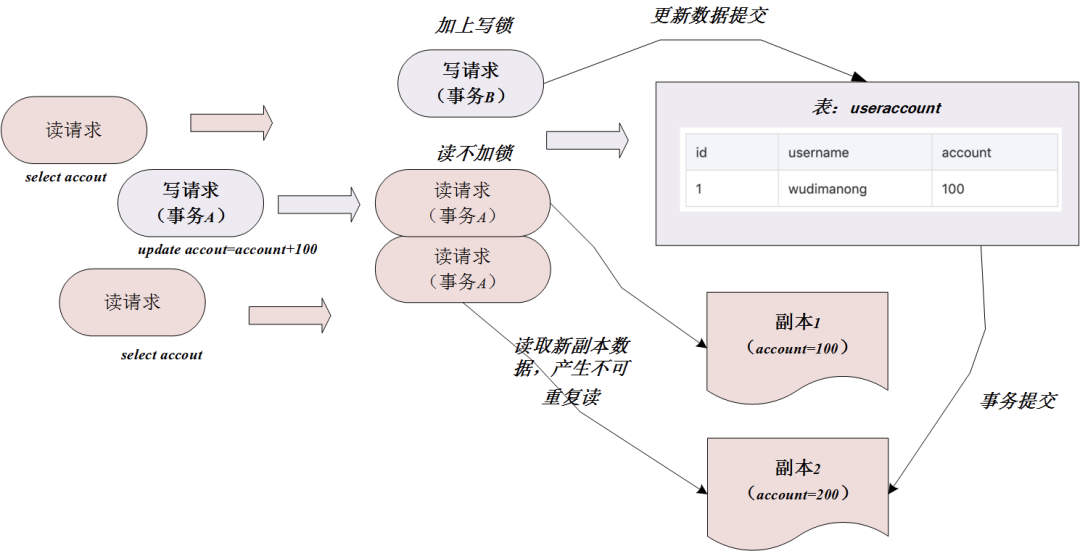
**Non-rereadable: ** refers to the data of the same row read multiple times in a transaction, but the result is different. For example, transaction A reads the data of row a, and transaction B modifies the data of row a at this time and commits the transaction, then the next time transaction A reads the data of row a, it is found that it is different from the first time!
**Phantom Reading:** refers to a transaction that retrieves data according to the same query conditions, but the data results retrieved multiple times are different. For example, transaction A retrieves data with condition x=0 for the first time and obtains 5 records; at this time, transaction B inserts a piece of data with x=0 into the table and submits the transaction; then transaction A uses condition x= for the second time 0 When searching the data, it was found that 6 records were obtained!
So why do non-repeatable reads and phantom reads occur under the READ COMMITED isolation level?
In fact, the non-repeatable read transaction isolation level also uses the MVCC (multi-version concurrency control) mechanism we mentioned earlier. But the MVCC mechanism under the READ COMMITED isolation level will generate a new system version number every time you select, so each select operation in the transaction reads not a copy but a different copy of the data, so in each Between selects, if other transactions update and submit the data we read, then non-repeatable reads and phantom reads will occur.
The reason for non-repeatable read is as follows:
REPEATABLE READ
The transaction isolation level REPEATABLE READ, also called repeatable read, is the default transaction isolation level of the MySQL database. Under this transaction isolation level, the results of multiple reads within a transaction are consistent. This isolation level can avoid query problems such as dirty reads and non-repeatable reads.
The realization of this transaction isolation level is mainly to use the read-write lock + MVCC mechanism. The specific schematic diagram is as follows:
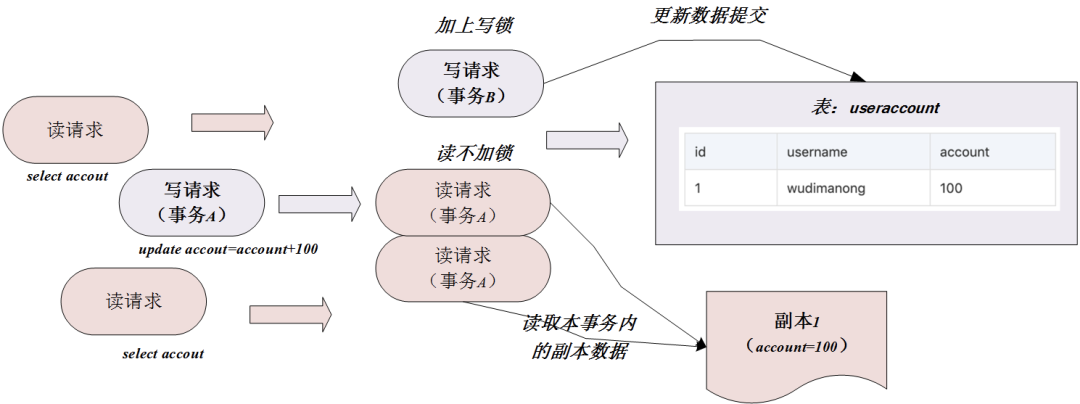
As shown in the figure above, the MVCC mechanism under the transaction isolation level does not generate a new system version number for each query within a transaction, so multiple queries within a transaction, data copies are One, so there is no non-repeatable read problem. For more details about MVCC under this isolation level, please refer to the previous content!
But it should be noted that this isolation level solves the problem of non-repeatable reads, but does not solve the problem of phantom reads, so if there is a conditional query in transaction A, another transaction B adds or deletes the data of the condition during this period. Commit the transaction, then it will still cause transaction A to produce phantom reads. So you need to pay attention to this problem when using MySQL!
SERIALIZABLE
This isolation level is the simplest to understand, because it will add exclusive locks to read and write requests, so it will not cause any data inconsistency, but the performance is not high, so there are few databases that use this isolation level!
4), the realization of consistency
Consistency mainly refers to the consistency of database data through rollback, recovery and isolation under concurrent conditions! The atomicity, persistence and isolation described above are ultimately to achieve consistency!
MySQL storage engine
In the previous content, we respectively described the content of MySQL concurrency control and transactions, but in fact, the specific details of concurrency control and transactions are implemented by the MySql storage engine. The most important and distinctive feature of MySQL is its storage engine architecture. This architecture design that separates data processing and storage allows users to select the corresponding storage engine according to performance, characteristics, and other specific requirements.
Even so, the InnoDB storage engine is chosen when using MySQL database in most cases, but this does not prevent us from properly understanding the characteristics of other storage engines. Next, I will give you a brief summary, as follows:
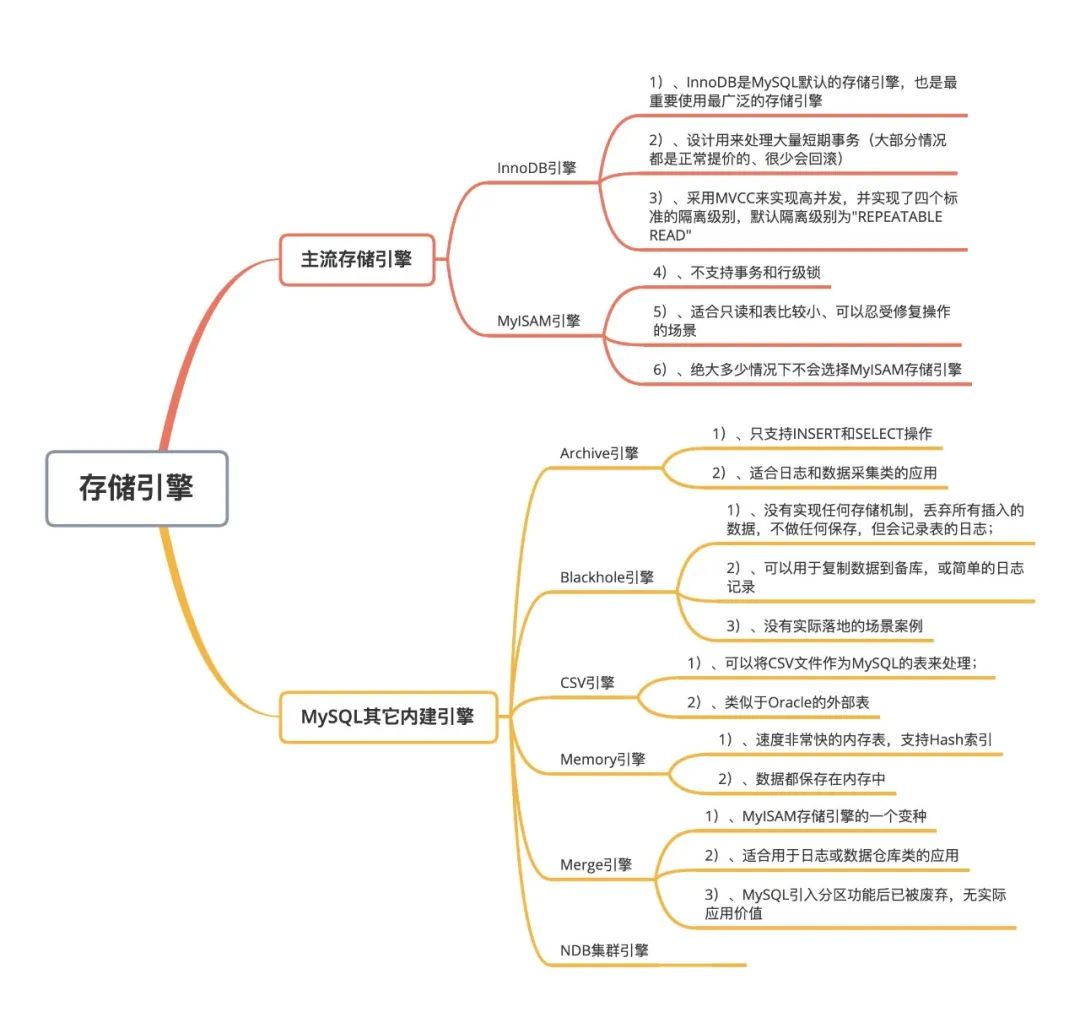
Above we briefly summarized the general characteristics of MySQL's various storage engines and their general applicable scenarios, but in fact, in addition to the InnoDB storage engine, you rarely see others in Internet business. The figure of the storage engine. Although MySQL has a variety of built-in storage engines for specific scenarios, most of them have corresponding alternative technologies. For example, log applications now have Elasticsearch, while data warehouse applications now have Hive, HBase and other products. As for memory databases, there are MangoDB. NoSQL data products such as, Redis, etc., so only InnoDB can play for MySQL!
Write at the end
Welcome everyone to pay attention to my public account [The wind and waves are calm as code ], a large number of Java-related articles, learning materials will be updated in it, and the sorted materials will also be placed in it.
If you think the writing is good, just like it and add a follower! Pay attention, don’t get lost, keep updating! ! !