Written in the front: The blogger is a "little mountain pig" who has devoted himself to the training business after actual development and experience. His nickname is taken from "Peng Peng" in the cartoon "The Lion King". He always treats the surrounding people with an optimistic and positive attitude. thing. My technical route has gone all the way from a Java full-stack engineer to the field of big data development and data mining. Now I have achieved some success. I would like to share with you what I have gained in the past. I hope it will be helpful to you on the way of learning. At the same time, the blogger also wants to build a complete technical library through this attempt. Any exceptions, errors, and precautions related to the technical points of the article will be listed at the end. You are welcome to provide materials in various ways.
- Please criticize and point out any mistakes in the article, and correct them in time.
- If you have any questions you want to discuss and learn, please contact me: [email protected].
- The style of publishing articles varies from column to column, and they are all self-contained. Please correct me if there are any deficiencies.
Installation and use of Sqoop
Keywords in this article: Sqoop, big data, components, data import, data export
Article Directory
1. Introduction to Sqoop
Sqoop is a tool for transferring data between Hadoop and relational databases, providing a fast and easy way to import large amounts of data from relational databases to Hadoop Distributed File System (HDFS), or from Hadoop Export to a relational database.
1. Function of the software
The full name of Sqoop is SQL-to-Hadoop, which is an open source project mainly used in the field of big data processing. It can realize two-way transmission of data between Hadoop and relational databases, such as importing data from MySQL, Oracle and other relational databases into HDFS , or exporting data from HDFS to relational databases. Sqoop supports a variety of data sources, and provides a wealth of data import and export options, and also supports common big data components such as Hive and HBase .
2. Software features
- Support multiple data sources, such as MySQL, Oracle, SQL Server, PostgreSQL, etc.;
- Import and export data through the command line without writing complex codes;
- Support incremental import, only need to import updated data;
- Support data compression to save storage space;
- Support data conversion during import and export.
3. Life cycle
Although Sqoop has retired into Attic in June 2021 , the current level of use is still relatively high. The software that supports the same type of functions includes NiFi , Flink , Spark , Talend , StreamSets , etc. If necessary, I will introduce it to you.

Two, Sqoop installation
1. Version selection
Sqoop provides two main versions:
- 1.4.x: Can be used in production environment, the last version is 1.4.7
- 1.9.77: Sqoop2 is not compatible with 1.4.x version, not suitable for production environment
2. Software download
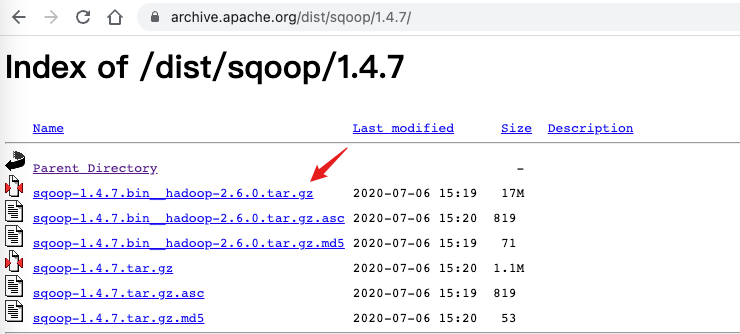
3. Installation configuration
- Pre-environment
Sqoop is written based on Java and requires a JDK environment to run.
- other components
Sqoop supports the import and export operations of multiple data sources. This article takes MySQL, HDFS, and Hive as examples. The relevant environment needs to be deployed first. If necessary, you can refer to: Install MySQL 8.0 on Ubuntu - APT (video at the end)
Hadoop
3.x modes Deployment - Ubuntu
Hive 3.x Installation Deployment - Ubuntu
- Unzip and install
tar -zvxf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
- Environment variable configuration
Edit the user environment variable file .bashrc [Take the Ubuntu system as an example].
export SQOOP_HOME=/home/hadoop/sqoop-1.4.7.bin__hadoop-2.6.0
export PATH=$PATH:$SQOOP_HOME/bin
export HIVE_CONF_DIR=$HIVE_HOME/conf
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HIVE_HOME/lib/*
When it comes to Hive-related operations, Sqoop needs to be able to read the location of the Hive configuration file. You need to make HIVE_CONF_DIR point to the path where the Hive configuration file is located, and add the Hive lib directory to HADOOP_CLASSPATH , and refresh the environment variables after the configuration is complete.
- software configuration
Rename $SQOOP_HOME/conf/sqoop-env-template.sh to sqoop-env.sh :
mv sqoop-env-template.sh sqoop-env.sh
Complete the environment configuration information to support HDFS and Hive, and add the configuration of HBase and Zookeper [remove the front #]:
export HADOOP_COMMON_HOME=/path/to/hadoop_home
export HADOOP_MAPRED_HOME=/path/to/hadoop_home
export HIVE_HOME=/path/to/hive_home
Optional: comment lines 135-147 of $SQOOP_HOME/bin/configure-sqoop to reduce some output information

3. Data import and export
Data import generally refers to importing data into a big data environment. Here, a relational database is used as a data source for demonstration. During the import process, since the bottom layer is implemented using JDBC, the driver jar package required to connect to the database needs to be placed in the lib directory of Sqoop before use .
Data export generally refers to exporting statistical results or calculation task results to business systems to display or support other business logic. During the export process, the target is generally a relational database, and the driver jar package also needs to be prepared .
0. Environment preparation
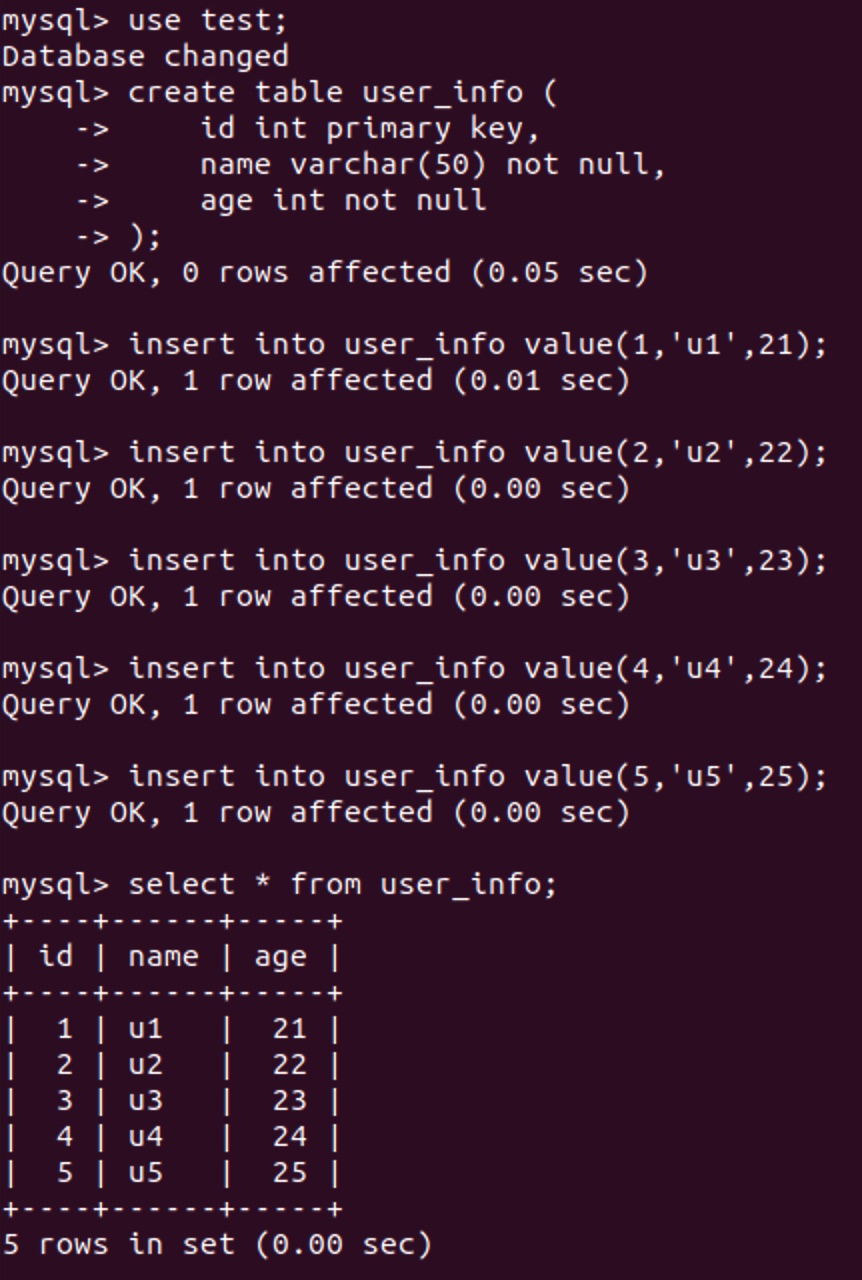
Taking the MySQL database as an example, first prepare a test data table, put it in the test database, and insert some sample data.
use test;
create table user_info (
id int primary key,
name varchar(50) not null,
age int not null
);
insert into user_info value(1,'u1',21);
insert into user_info value(2,'u2',22);
insert into user_info value(3,'u3',23);
insert into user_info value(4,'u4',24);
insert into user_info value(5,'u5',25);
1. Import to HDFS
To store data in HDFS in the form of files, the relevant parameters of connecting to the data source [that is, connection string, user name, password], the target of data reading [data table name], and the storage location of data output are mainly used .
sqoop import \
--connect jdbc:mysql://localhost:3306/test \
--username root \
--password root \
--table user_info \
--columns "id,name,age" \
--target-dir /user/hadoop/user_info \
--m 1
- Use a slash to break the line: usually the sqoop command is relatively long, you can use spaces to separate the parameters, or use a slash to break the line
- Whole table import: If you want to import all data to HDFS [without any filtering], you only need to specify the table name
- Fixed column import: If you only want to import certain columns, you can use the columns parameter to specify
- Output path: The last level directory of the output directory should not exist, it will be created automatically during execution
- Number of tasks: Sqoop will perform distributed processing when executing tasks. If not specified, the number of concurrently executing Map tasks is 4


2. Import to Hive
If you want to import data into Hive and continue to perform HQL operations, you can easily implement it by adding some parameters:
sqoop import \
--connect jdbc:mysql://localhost:3306/test \
--username root \
--password root \
--table user_info \
--columns "id,name,age" \
--hive-import \
--hive-database test \
--hive-table user_info \
--hive-overwrite \
--delete-target-dir \
--m 1
- Import to Hive: Use hive-import to declare that this is an operation to import Hive
- Specify the target database: can be merged into hive-table , such as test.user_info
- Specify the target data table: when importing, the table will be automatically built according to the data source structure
- Overwrite import: If specified, the previous data will be overwritten, if not specified, the default is append import
- Clear target path: Temporary files will be written in the HDFS current user folder during execution. Add this parameter to clear the directory first to avoid manual clearing when the task fails
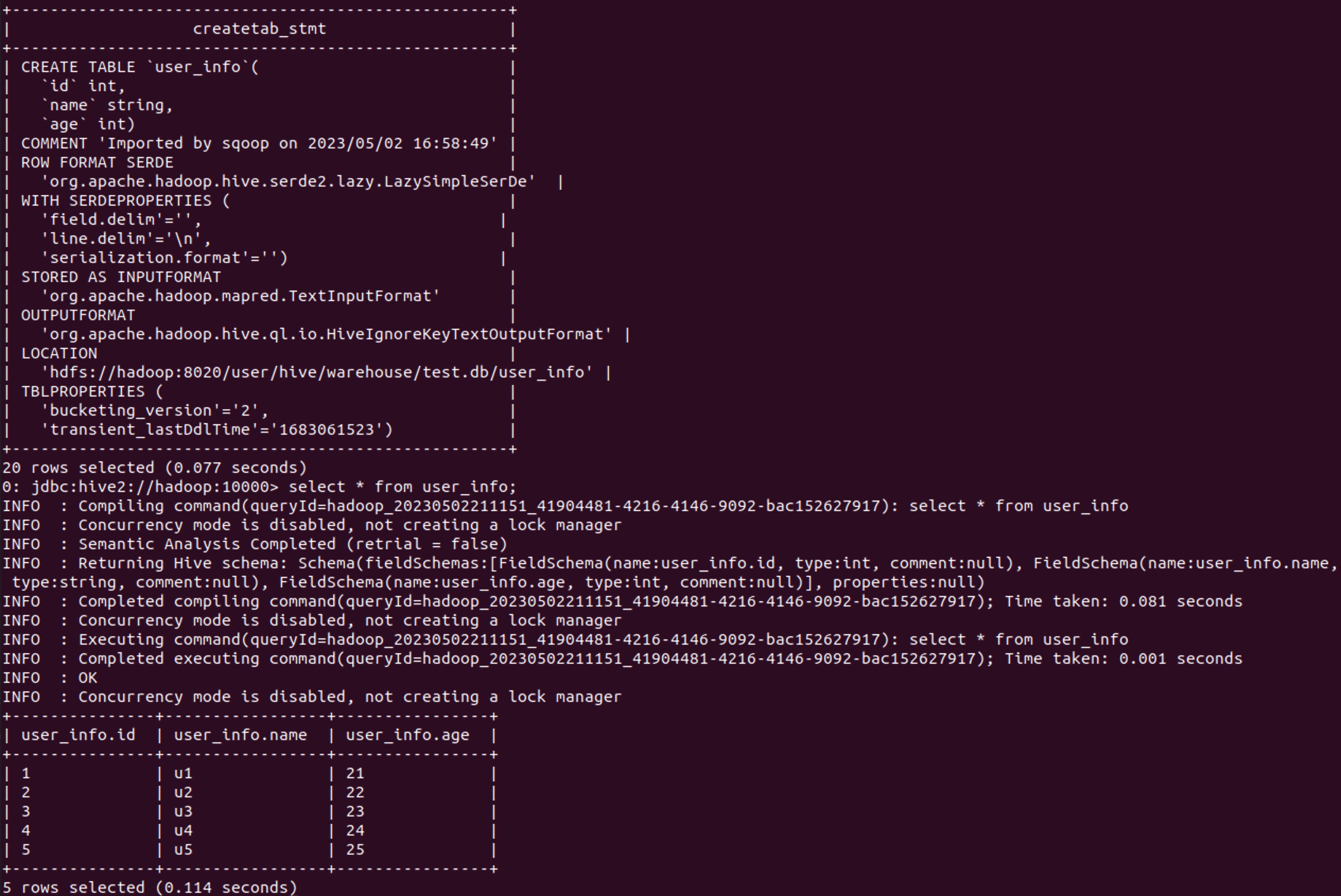
As can be seen from the table creation statement, the table is automatically created during the Sqoop import process, and the matching data structure will be automatically used. You can also manually create the table in Hive before importing the data.
3. Export from HDFS
If you need to export data to a relational database, you need to prepare a table first, as follows:
create table user_info_hdfs (
id int primary key,
name varchar(50) not null,
age int not null
);
To ensure that the data can meet the constraints of the data table, use the following command:
sqoop export \
--connect jdbc:mysql://localhost/test \
--username root \
--password root \
--table user_info_hdfs \
--export-dir /user/hadoop/user_info \
--input-fields-terminated-by ',' \
--m 1
- Data export: use export to indicate that this is an export task
- Export target: the table at this time refers to the table name of the target relational database
- Data source directory: use export-dir to specify the location of the data file on HDFS [all data under the folder will be imported]
- Data separator: It is necessary to correctly specify the separator between columns in order to place the data in the corresponding position correctly

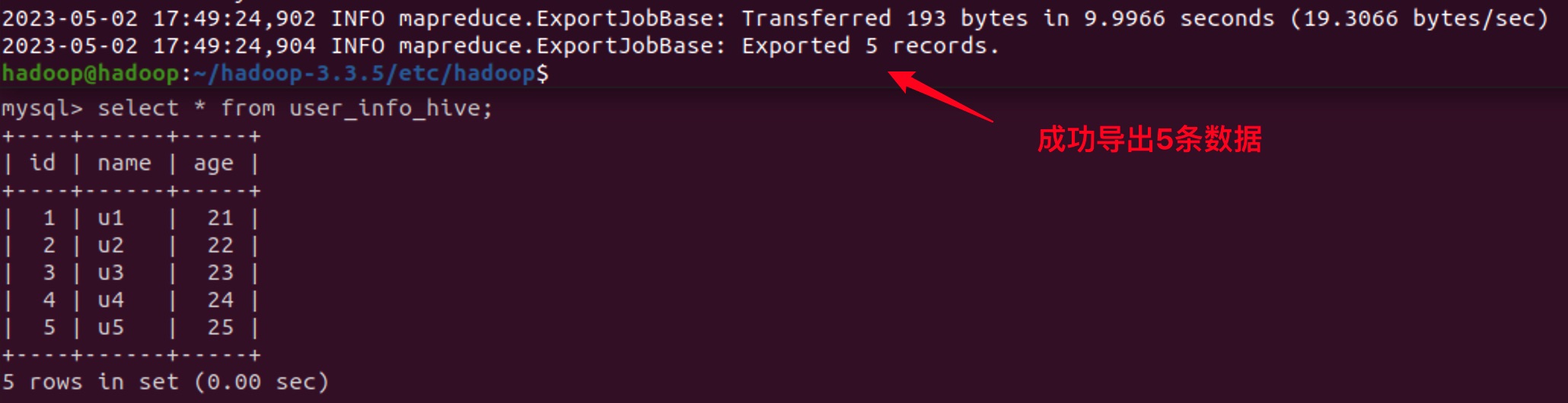
4. Export from Hive
Create a table in the database to receive Hive exported data:
create table user_info_hive (
id int primary key,
name varchar(50) not null,
age int not null
);
To ensure that the data can meet the constraints of the data table, use the following command:
sqoop export \
--connect jdbc:mysql://localhost/test \
--username root \
--password root \
--table user_info_hive \
--export-dir /user/hive/warehouse/test.db/user_info \
--input-fields-terminated-by "$(echo -e '\u0001')" \
--m 1
- Data file directory: When exporting data from Hive, you also need to specify the path where the data file is located. By default, the home directory of Hive is /user/hive/warehouse , which is the path where the default database of Hive is located. All other databases will exist in folders with the database name .db , and the data tables will be stored in folders named after the table names under the corresponding databases. You can also view the path information by using the show create table {tableName} command in Hive .
- Data separator: When importing and exporting data, you should pay special attention to the problem of data separator, which will directly affect whether the data can be parsed normally or the task can be successfully executed. By default, if you use Hive or Sqoop to automatically create a table and do not manually specify the separator, the column separator is \u0001 and the row separator is \n . In general, it is recommended to specify the column delimiter by yourself [when Hive creates a table or imports data], otherwise you need to use the above command to correctly specify the character whose ASCII code value is 1.
5. Security Policy Issues
The following error [ AccessControlException ] will occur when performing tasks related to Hive :

This error will not affect the operation of the program. If it needs to be processed, just add a rule to the Java security policy.
# 进入到jre的安全策略文件夹
cd /usr/lib/jvm/java-8-openjdk-arm64/jre/lib/security
# 编辑安全策略文件
sudo vi java.policy
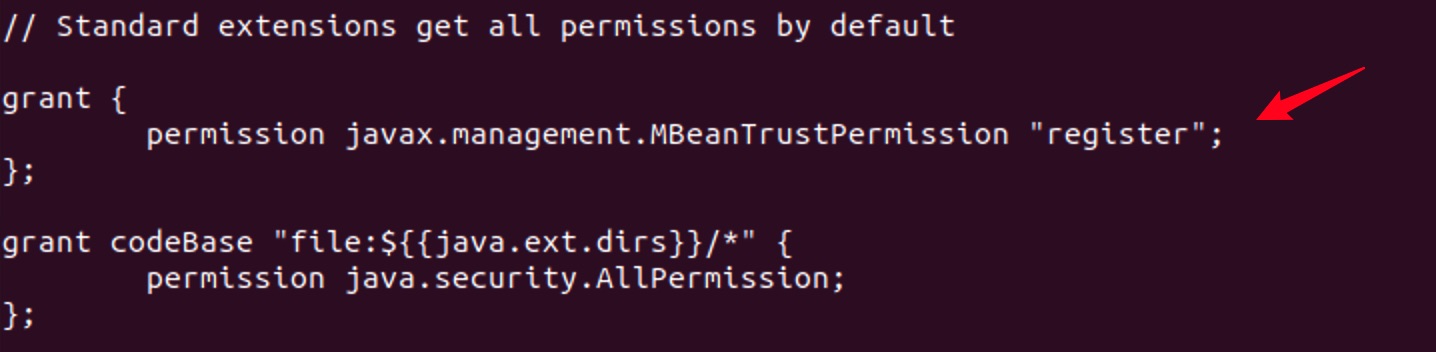
Save and exit the file after adding the following:
grant {
permission javax.management.MBeanTrustPermission "register";
};
Scan the QR code below, join the official CSDN fan WeChat group, you can communicate with me directly, and there are more benefits~
