Reference code: https://github.com/yhenon/pytorch-retinanet
1. Loss function
1) Principle
A core contribution point of this paper is focal loss. The total loss is still divided into two parts, one is classification loss and the other is regression loss.
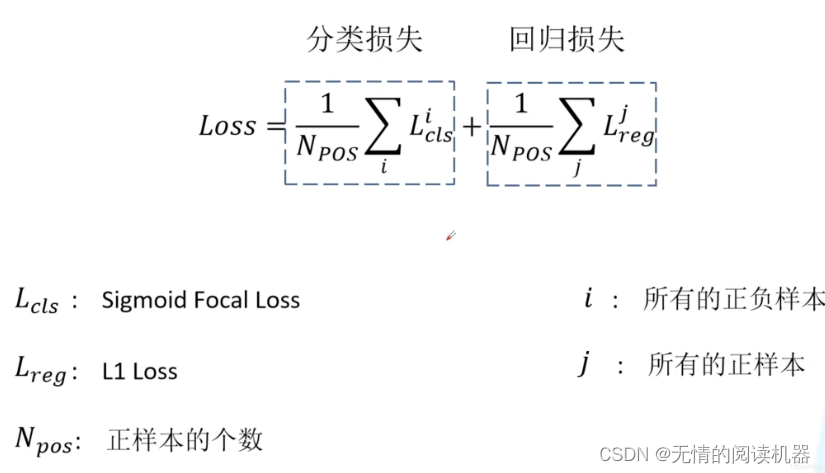
Before talking about the classification loss, let's review the binary cross entropy loss (binary_cross_entropy).

The calculation code is as follows:
import numpy as npy_true = np.array([0., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
y_pred = np.array([0.2, 0.8, 0.8, 0.8, 0.8, 0.8, 0.8, 0.8, 0.8, 0.8])my_loss = - y_true * np.log(y_pred) - (1 - y_true) * np.log(1 - y_pred)
mean_my_loss = np.mean(my_loss)
print("mean_my_loss:",mean_my_loss)![]()
Call the function calculation that comes with pytorch
import torch.nn.functional as F
import numpy as np
import torchtorch_pred = torch.tensor(y_pred)
torch_true = torch.tensor(y_true)
bce_loss = F.binary_cross_entropy(torch_pred, torch_true)
print('bce_loss:', bce_loss)

Now back to focal loss, the origin of Focal loss is binary cross entropy.
The cross-entropy loss of the two classifications can also be expressed as follows, where y∈{1,-1}, 1 means that the candidate box is a positive sample, and -1 means that it is a negative sample:

For convenience, the following formula can be defined:
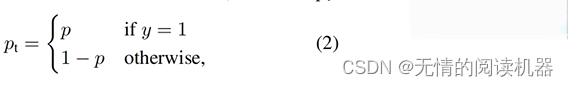
Then the problem comes, the application scenario is as follows:
In the one-stage object detection model, there are about a dozen to dozens of candidate boxes (positive samples) that can match the target in a picture, and then there are no matching candidate boxes (negative samples) from the fourth power of 10 to five power. Most of these negative samples are simple and easy-to-divide samples, which have no effect on the training samples, but submerge the samples that are helpful for training.
For example, there are 50 positive samples, the loss is 3, and the negative samples are 10000, the loss is 0.1
Then 50x3 = 150, 10000x0.1=1000

Therefore, in order to balance the cross entropy, the coefficient αt is used. When it is a positive sample, αt = α, and when it is a negative sample, αt=1-α, α∈[0,1]
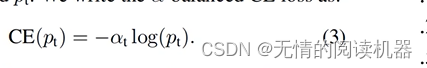
αt can balance the weight of positive and negative samples, but it cannot distinguish which are difficult samples and which are easy samples (whether it is helpful for training).
So continue to introduce the formula, which solves the problem of the ease of distinguishing samples:

Finally, the two formulas are combined to form the final formula.

The expanded form is as follows
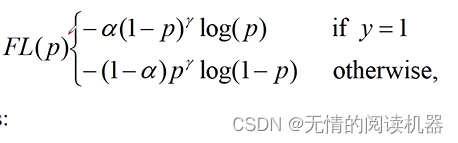
Now look at the effect, p represents the probability that the predicted candidate frame is a positive sample, y is whether the candidate frame is actually a positive sample or a negative sample, CE is the loss calculated by ordinary cross entropy, FL is the focal loss, and rate is the reduction ratio. It can be seen that the rate of the indistinguishable samples in the last two rows is very small.

2) Code
import numpy as np
import torch
import torch.nn as nn
class FocalLoss(nn.Module):
#def __init__(self):
def forward(self, classifications, regressions, anchors, annotations):
alpha = 0.25
gamma = 2.0
# classifications是预测结果
batch_size = classifications.shape[0]
# 分类loss
classification_losses = []
# 回归loss
regression_losses = []
# anchors的形状是 [1, 每层anchor数量之和 , 4]
anchor = anchors[0, :, :]
anchor_widths = anchor[:, 2] - anchor[:, 0] # x2-x1
anchor_heights = anchor[:, 3] - anchor[:, 1] # y2-y1
anchor_ctr_x = anchor[:, 0] + 0.5 * anchor_widths # 中心点x坐标
anchor_ctr_y = anchor[:, 1] + 0.5 * anchor_heights # 中心点y坐标
for j in range(batch_size):
# classifications的shape [batch,所有anchor的数量,分类数]
classification = classifications[j, :, :]
# classifications的shape [batch,所有anchor的数量,分类数]
regression = regressions[j, :, :]
bbox_annotation = annotations[j, :, :]
bbox_annotation = bbox_annotation[bbox_annotation[:, 4] != -1]
classification = torch.clamp(classification, 1e-4, 1.0 - 1e-4)
if bbox_annotation.shape[0] == 0:
if torch.cuda.is_available():
alpha_factor = torch.ones(classification.shape).cuda() * alpha
alpha_factor = 1. - alpha_factor
focal_weight = classification
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
bce = -(torch.log(1.0 - classification))
# cls_loss = focal_weight * torch.pow(bce, gamma)
cls_loss = focal_weight * bce
classification_losses.append(cls_loss.sum())
regression_losses.append(torch.tensor(0).float().cuda())
else:
alpha_factor = torch.ones(classification.shape) * alpha
alpha_factor = 1. - alpha_factor
focal_weight = classification
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
bce = -(torch.log(1.0 - classification))
# cls_loss = focal_weight * torch.pow(bce, gamma)
cls_loss = focal_weight * bce
classification_losses.append(cls_loss.sum())
regression_losses.append(torch.tensor(0).float())
continue
# 每个anchor 与 每个标注的真实框的iou
IoU = calc_iou(anchors[0, :, :], bbox_annotation[:, :4]) # num_anchors x num_annotations
# 每个anchor对应的最大的iou (anchor与grandtruce进行配对)
# 得到了配对的索引和对应的最大值
IoU_max, IoU_argmax = torch.max(IoU, dim=1)
#import pdb
#pdb.set_trace()
# compute the loss for classification
# classification 的shape[anchor总数,分类数]
targets = torch.ones(classification.shape) * -1
if torch.cuda.is_available():
targets = targets.cuda()
# 判断每个元素是否小于0.4 小于就返回true(anchor对应的最大iou<0.4,那就是背景)
targets[torch.lt(IoU_max, 0.4), :] = 0
# 最大iou大于0.5的anchor索引
positive_indices = torch.ge(IoU_max, 0.5)
num_positive_anchors = positive_indices.sum()
assigned_annotations = bbox_annotation[IoU_argmax, :]
targets[positive_indices, :] = 0
targets[positive_indices, assigned_annotations[positive_indices, 4].long()] = 1
if torch.cuda.is_available():
alpha_factor = torch.ones(targets.shape).cuda() * alpha
else:
alpha_factor = torch.ones(targets.shape) * alpha
alpha_factor = torch.where(torch.eq(targets, 1.), alpha_factor, 1. - alpha_factor)
focal_weight = torch.where(torch.eq(targets, 1.), 1. - classification, classification)
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
bce = -(targets * torch.log(classification) + (1.0 - targets) * torch.log(1.0 - classification))
# cls_loss = focal_weight * torch.pow(bce, gamma)
cls_loss = focal_weight * bce
if torch.cuda.is_available():
cls_loss = torch.where(torch.ne(targets, -1.0), cls_loss, torch.zeros(cls_loss.shape).cuda())
else:
cls_loss = torch.where(torch.ne(targets, -1.0), cls_loss, torch.zeros(cls_loss.shape))
classification_losses.append(cls_loss.sum()/torch.clamp(num_positive_anchors.float(), min=1.0))
# compute the loss for regression
if positive_indices.sum() > 0:
assigned_annotations = assigned_annotations[positive_indices, :]
anchor_widths_pi = anchor_widths[positive_indices]
anchor_heights_pi = anchor_heights[positive_indices]
anchor_ctr_x_pi = anchor_ctr_x[positive_indices]
anchor_ctr_y_pi = anchor_ctr_y[positive_indices]
gt_widths = assigned_annotations[:, 2] - assigned_annotations[:, 0]
gt_heights = assigned_annotations[:, 3] - assigned_annotations[:, 1]
gt_ctr_x = assigned_annotations[:, 0] + 0.5 * gt_widths
gt_ctr_y = assigned_annotations[:, 1] + 0.5 * gt_heights
# clip widths to 1
gt_widths = torch.clamp(gt_widths, min=1)
gt_heights = torch.clamp(gt_heights, min=1)
targets_dx = (gt_ctr_x - anchor_ctr_x_pi) / anchor_widths_pi
targets_dy = (gt_ctr_y - anchor_ctr_y_pi) / anchor_heights_pi
targets_dw = torch.log(gt_widths / anchor_widths_pi)
targets_dh = torch.log(gt_heights / anchor_heights_pi)
targets = torch.stack((targets_dx, targets_dy, targets_dw, targets_dh))
targets = targets.t()
if torch.cuda.is_available():
targets = targets/torch.Tensor([[0.1, 0.1, 0.2, 0.2]]).cuda()
else:
targets = targets/torch.Tensor([[0.1, 0.1, 0.2, 0.2]])
negative_indices = 1 + (~positive_indices)
regression_diff = torch.abs(targets - regression[positive_indices, :])
regression_loss = torch.where(
torch.le(regression_diff, 1.0 / 9.0),
0.5 * 9.0 * torch.pow(regression_diff, 2),
regression_diff - 0.5 / 9.0
)
regression_losses.append(regression_loss.mean())
else:
if torch.cuda.is_available():
regression_losses.append(torch.tensor(0).float().cuda())
else:
regression_losses.append(torch.tensor(0).float())
return torch.stack(classification_losses).mean(dim=0, keepdim=True), torch.stack(regression_losses).mean(dim=0, keepdim=True)
3) Calculation process of classification loss
Suppose a picture has n anchors, m grandtrue, and L categories
1. Get the IOU of the anchor and each grandtrue
# 每个anchor 与 每个标注的真实框的iou
IoU = calc_iou(anchors[0, :, :], bbox_annotation[:, :4]) # num_anchors x num_annotations
2. Get the largest IOU of each anchor, and the corresponding grandtrue
IoU_max, IoU_argmax = torch.max(IoU, dim=1)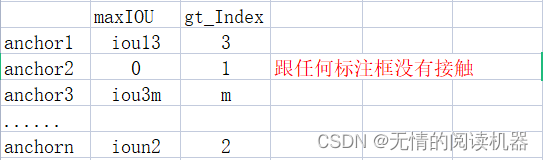
3. Initialize a classification target result table, the default value is -1
targets = torch.ones(classification.shape) * -1 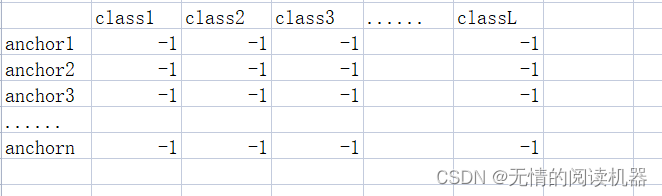
4. If the maximum IOU of an anchor is <0.4, then its corresponding classification is all 0
targets[torch.lt(IoU_max, 0.4), :] = 0Example: iou3m = 0.3, ioun2 = 0.2
At this point, the above classification result table updates the classification results of anchor3 and anchor

5. Associate each anchor with the corresponding grandtruce information, where parameter 5 is the predicted category
# 最大iou大于0.5的anchor索引
positive_indices = torch.ge(IoU_max, 0.5)
num_positive_anchors = positive_indices.sum()
assigned_annotations = bbox_annotation[IoU_argmax, :]
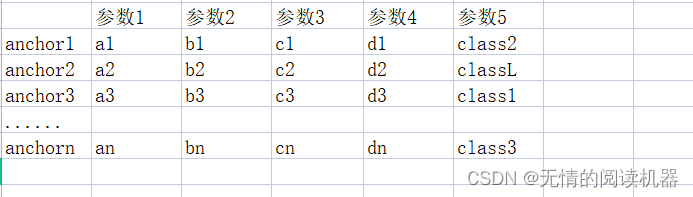 6. If the maximum IOU of the anchor>0.5, then according to parameter 5, modify the corresponding classification result table to one-hot form
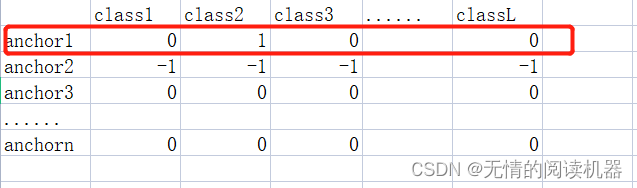
6. If the maximum IOU of the anchor>0.5, then according to parameter 5, modify the corresponding classification result table to one-hot form
targets[positive_indices, :] = 0
targets[positive_indices, assigned_annotations[positive_indices, 4].long()] = 1For example iou12 = 0.6, parameter 5 = class2
Modify the classification result table
7. Get the weight part of the loss
alpha_factor = torch.where(torch.eq(targets, 1.), alpha_factor, 1. - alpha_factor)
focal_weight = torch.where(torch.eq(targets, 1.), 1. - classification, classification)
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
α table, replace the place of 0 with 1-α, and the place of 1 with α

The p table replaces the original probability of 0 and 1 with 1-p

The elements of the weight table are the product of the corresponding elements of the two tables
8. Get the loss part of the loss
bce = -(targets * torch.log(classification) + (1.0 - targets) * torch.log(1.0 - classification))
9. Get preliminary loss results
cls_loss = focal_weight * bce10. Where the classification result table was originally -1, the corresponding loss becomes 0
For example, the maximum iou of anchor2 is 0.45, between 0.4 and 0.5, we will not calculate his loss, ignore it
if torch.cuda.is_available():
cls_loss = torch.where(torch.ne(targets, -1.0), cls_loss, torch.zeros(cls_loss.shape).cuda())
else:
cls_loss = torch.where(torch.ne(targets, -1.0), cls_loss, torch.zeros(cls_loss.shape))11. Summary of losses
classification_losses.append(cls_loss.sum()/torch.clamp(num_positive_anchors.float(), min=1.0))2. Network structure
Overall, the network uses the FPN model
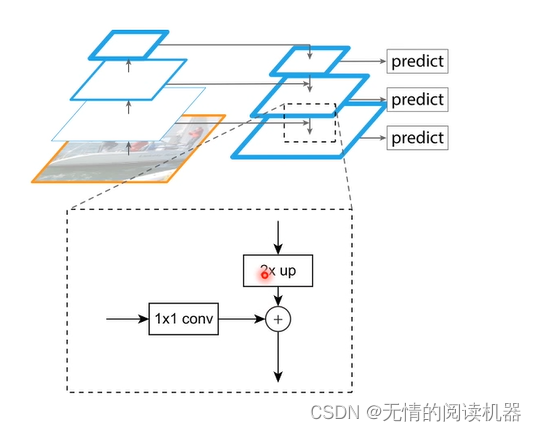
 This structure can also be changed (can be changed flexibly), as shown below
This structure can also be changed (can be changed flexibly), as shown below

The model looks like this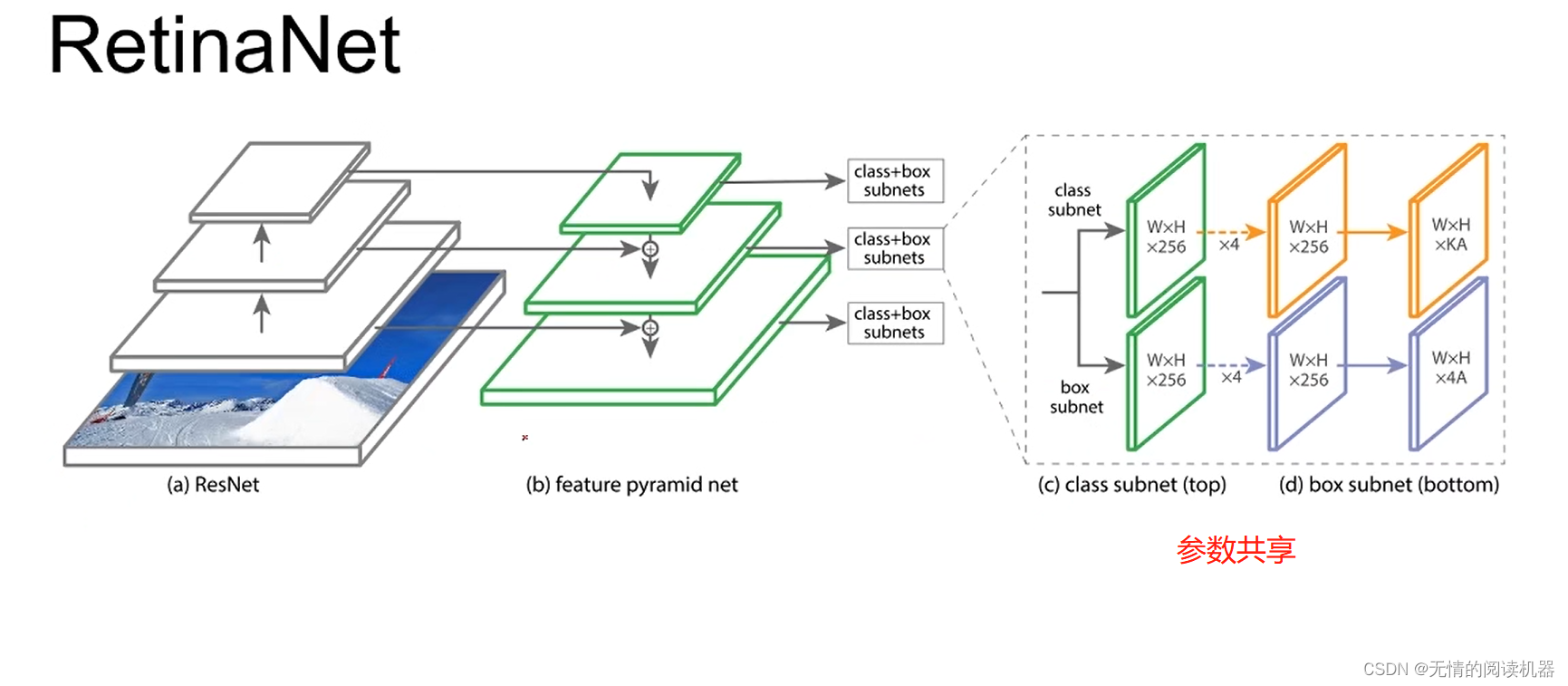
There are 9 anchors for each position, three shapes x three ratios
K is the number of categories, A is the number of each position anchor
4A, 4 are four parameters that can determine the position and size of the anchor.
3. Code explanation:
1. FPN branch part

self.P5_1 = nn.Conv2d(C5_size, feature_size, kernel_size=1, stride=1, padding=0)
self.P5_upsampled = nn.Upsample(scale_factor=2, mode='nearest')
self.P5_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=1, padding=1)
self.P4_1 = nn.Conv2d(C4_size, feature_size, kernel_size=1, stride=1, padding=0)
self.P4_upsampled = nn.Upsample(scale_factor=2, mode='nearest')
self.P4_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=1, padding=1)
self.P3_1 = nn.Conv2d(C3_size, feature_size, kernel_size=1, stride=1, padding=0)
self.P3_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=1, padding=1) 
self.P6 = nn.Conv2d(C5_size, feature_size, kernel_size=3, stride=2, padding=1) 
self.P7_1 = nn.ReLU()
self.P7_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=2, padding=1)forward
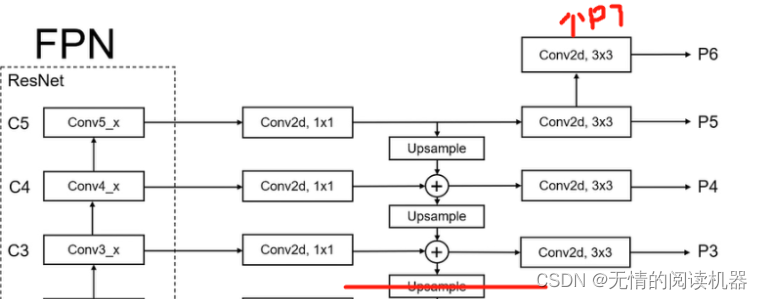
def forward(self, inputs):
#inputs 是主干模块conv3、conv4、conv5的输出
C3, C4, C5 = inputs
P5_x = self.P5_1(C5)
P5_upsampled_x = self.P5_upsampled(P5_x)
P5_x = self.P5_2(P5_x)
P4_x = self.P4_1(C4)
P4_x = P5_upsampled_x + P4_x
P4_upsampled_x = self.P4_upsampled(P4_x)
P4_x = self.P4_2(P4_x)
P3_x = self.P3_1(C3)
P3_x = P3_x + P4_upsampled_x
P3_x = self.P3_2(P3_x)
P6_x = self.P6(C5)
P7_x = self.P7_1(P6_x)
P7_x = self.P7_2(P7_x)
return [P3_x, P4_x, P5_x, P6_x, P7_x]
2. Return from the network

class RegressionModel(nn.Module):
def __init__(self, num_features_in, num_anchors=9, feature_size=256):
super(RegressionModel, self).__init__()
#其实num_features_in就等于256
self.conv1 = nn.Conv2d(num_features_in, feature_size, kernel_size=3, padding=1)
self.act1 = nn.ReLU()
self.conv2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act2 = nn.ReLU()
self.conv3 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act3 = nn.ReLU()
self.conv4 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act4 = nn.ReLU()
#4个参数就能确定anchor的大小
self.output = nn.Conv2d(feature_size, num_anchors * 4, kernel_size=3, padding=1)
def forward(self, x):
out = self.conv1(x)
out = self.act1(out)
out = self.conv2(out)
out = self.act2(out)
out = self.conv3(out)
out = self.act3(out)
out = self.conv4(out)
out = self.act4(out)
out = self.output(out)
# out is B x C x W x H, with C = 4*num_anchors
out = out.permute(0, 2, 3, 1)
#相当于展平了,-1的位置相当于所有anchor的数目
return out.contiguous().view(out.shape[0], -1, 4)3. Classification network

class ClassificationModel(nn.Module):
def __init__(self, num_features_in, num_anchors=9, num_classes=80, prior=0.01, feature_size=256):
super(ClassificationModel, self).__init__()
self.num_classes = num_classes
self.num_anchors = num_anchors
self.conv1 = nn.Conv2d(num_features_in, feature_size, kernel_size=3, padding=1)
self.act1 = nn.ReLU()
self.conv2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act2 = nn.ReLU()
self.conv3 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act3 = nn.ReLU()
self.conv4 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act4 = nn.ReLU()
self.output = nn.Conv2d(feature_size, num_anchors * num_classes, kernel_size=3, padding=1)
self.output_act = nn.Sigmoid()
def forward(self, x):
out = self.conv1(x)
out = self.act1(out)
out = self.conv2(out)
out = self.act2(out)
out = self.conv3(out)
out = self.act3(out)
out = self.conv4(out)
out = self.act4(out)
out = self.output(out)
out = self.output_act(out)
# out is B x C x W x H, with C = n_classes + n_anchors
out1 = out.permute(0, 2, 3, 1)
batch_size, width, height, channels = out1.shape
out2 = out1.view(batch_size, width, height, self.num_anchors, self.num_classes)
return out2.contiguous().view(x.shape[0], -1, self.num_classes)4. Backbone network, training and prediction process
1. Network structure

After conv1 is reduced by 4 times, after conv2 remains unchanged, conv3, v4, and v5 are all reduced by two times, p5 to p6 are reduced by two times, and p6 to p7 are reduced by two times
p3 is reduced to the 3rd power of 2 relative to the picture, p4 is reduced to the 4th power of 2 relative to the picture, and so on
class ResNet(nn.Module):
#layers是层数
def __init__(self, num_classes, block, layers):
self.inplanes = 64
super(ResNet, self).__init__()
#这个是输入 conv1
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
#这是c2
self.layer1 = self._make_layer(block, 64, layers[0])
#这是c3
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
#这是c4
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
#这是c5
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
#得到c3、c4、c5输出的通道数
if block == BasicBlock:
fpn_sizes = [self.layer2[layers[1] - 1].conv2.out_channels, self.layer3[layers[2] - 1].conv2.out_channels,
self.layer4[layers[3] - 1].conv2.out_channels]
elif block == Bottleneck:
fpn_sizes = [self.layer2[layers[1] - 1].conv3.out_channels, self.layer3[layers[2] - 1].conv3.out_channels,
self.layer4[layers[3] - 1].conv3.out_channels]
else:
raise ValueError(f"Block type {block} not understood")
#创建FPN的分支部分
self.fpn = PyramidFeatures(fpn_sizes[0], fpn_sizes[1], fpn_sizes[2])
#创建回归网络
self.regressionModel = RegressionModel(256)
#创建分类网络
self.classificationModel = ClassificationModel(256, num_classes=num_classes)
self.anchors = Anchors()
self.regressBoxes = BBoxTransform()
self.clipBoxes = ClipBoxes()
self.focalLoss = losses.FocalLoss()
#权重初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
prior = 0.01
self.classificationModel.output.weight.data.fill_(0)
self.classificationModel.output.bias.data.fill_(-math.log((1.0 - prior) / prior))
self.regressionModel.output.weight.data.fill_(0)
self.regressionModel.output.bias.data.fill_(0)
#冻结bn层参数更新,因为预训练的参数已经很好了
self.freeze_bn()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = [block(self.inplanes, planes, stride, downsample)]
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def freeze_bn(self):
'''Freeze BatchNorm layers.'''
for layer in self.modules():
if isinstance(layer, nn.BatchNorm2d):
layer.eval()2. Training process and prediction process
1) Adjustment of the anchor
The generated prediction value regression [batch, the number of anchors, 4] regression[:, :, 0] and [:, :, 1] are used to move the anchor center point [:, :, 2] and [:, :, 3 ] is used to change the length of the frame
import torch.nn as nn
import torch
import numpy as np
# 生成的预测值 regression [batch, anchor的数量,4] regression[:, :, 0]和[:, :, 1]用来移动anchor中心点 [:, :, 2]和[:, :, 3]用来改变框子的长度
class BBoxTransform(nn.Module):
def __init__(self, mean=None, std=None):
super(BBoxTransform, self).__init__()
if mean is None:
if torch.cuda.is_available():
self.mean = torch.from_numpy(np.array([0, 0, 0, 0]).astype(np.float32)).cuda()
else:
self.mean = torch.from_numpy(np.array([0, 0, 0, 0]).astype(np.float32))
else:
self.mean = mean
if std is None:
if torch.cuda.is_available():
self.std = torch.from_numpy(np.array([0.1, 0.1, 0.2, 0.2]).astype(np.float32)).cuda()
else:
self.std = torch.from_numpy(np.array([0.1, 0.1, 0.2, 0.2]).astype(np.float32))
else:
self.std = std
def forward(self, boxes, deltas):
#boxes就是图片所有的anchor[batch , 一张图片上anchor的总数 ,4]
widths = boxes[:, :, 2] - boxes[:, :, 0] # x2 - x1 = 宽
heights = boxes[:, :, 3] - boxes[:, :, 1] # y2 - y1 = 高
ctr_x = boxes[:, :, 0] + 0.5 * widths # x1 + 宽/2 = 中心点 x
ctr_y = boxes[:, :, 1] + 0.5 * heights # y1 + 高/2 = 中心点 y
dx = deltas[:, :, 0] * self.std[0] + self.mean[0]
dy = deltas[:, :, 1] * self.std[1] + self.mean[1]
dw = deltas[:, :, 2] * self.std[2] + self.mean[2]
dh = deltas[:, :, 3] * self.std[3] + self.mean[3]
pred_ctr_x = ctr_x + dx * widths
pred_ctr_y = ctr_y + dy * heights
pred_w = torch.exp(dw) * widths
pred_h = torch.exp(dh) * heights
pred_boxes_x1 = pred_ctr_x - 0.5 * pred_w
pred_boxes_y1 = pred_ctr_y - 0.5 * pred_h
pred_boxes_x2 = pred_ctr_x + 0.5 * pred_w
pred_boxes_y2 = pred_ctr_y + 0.5 * pred_h
pred_boxes = torch.stack([pred_boxes_x1, pred_boxes_y1, pred_boxes_x2, pred_boxes_y2], dim=2)
return pred_boxes2 total process
def forward(self, inputs):
if self.training:
img_batch, annotations = inputs
else:
img_batch = inputs
x = self.conv1(img_batch)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x1 = self.layer1(x)
x2 = self.layer2(x1)
x3 = self.layer3(x2)
x4 = self.layer4(x3)
features = self.fpn([x2, x3, x4])
#shape[batch,每次anchor总数之和,4个值]
regression = torch.cat([self.regressionModel(feature) for feature in features], dim=1)
# shape[batch,每次anchor总数之和,分类个数]
classification = torch.cat([self.classificationModel(feature) for feature in features], dim=1)
anchors = self.anchors(img_batch)
if self.training:
return self.focalLoss(classification, regression, anchors, annotations)
else:
#得到调节参数之后的框子
transformed_anchors = self.regressBoxes(anchors, regression)
#保证框子在图片之内
transformed_anchors = self.clipBoxes(transformed_anchors, img_batch)
finalResult = [[], [], []]
#每个框对应类别的置信度
finalScores = torch.Tensor([])
#框对应的分类序号:第几类
finalAnchorBoxesIndexes = torch.Tensor([]).long()
#框的坐标
finalAnchorBoxesCoordinates = torch.Tensor([])
if torch.cuda.is_available():
finalScores = finalScores.cuda()
finalAnchorBoxesIndexes = finalAnchorBoxesIndexes.cuda()
finalAnchorBoxesCoordinates = finalAnchorBoxesCoordinates.cuda()
for i in range(classification.shape[2]):
scores = torch.squeeze(classification[:, :, i])
scores_over_thresh = (scores > 0.05)
if scores_over_thresh.sum() == 0:
# no boxes to NMS, just continue
continue
scores = scores[scores_over_thresh]
anchorBoxes = torch.squeeze(transformed_anchors)
anchorBoxes = anchorBoxes[scores_over_thresh]
anchors_nms_idx = nms(anchorBoxes, scores, 0.5)
finalResult[0].extend(scores[anchors_nms_idx])
finalResult[1].extend(torch.tensor([i] * anchors_nms_idx.shape[0]))
finalResult[2].extend(anchorBoxes[anchors_nms_idx])
finalScores = torch.cat((finalScores, scores[anchors_nms_idx]))
finalAnchorBoxesIndexesValue = torch.tensor([i] * anchors_nms_idx.shape[0])
if torch.cuda.is_available():
finalAnchorBoxesIndexesValue = finalAnchorBoxesIndexesValue.cuda()
finalAnchorBoxesIndexes = torch.cat((finalAnchorBoxesIndexes, finalAnchorBoxesIndexesValue))
finalAnchorBoxesCoordinates = torch.cat((finalAnchorBoxesCoordinates, anchorBoxes[anchors_nms_idx]))
return [finalScores, finalAnchorBoxesIndexes, finalAnchorBoxesCoordinates]5. Definition of two blocks
import torch.nn as nn
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out6.anchor
1. Generate anchor function for each position
The generation of anchors is based on the original imageThe function of this function is to generate all anchors in a position, the form is (x1, y1, x2, y2) and (X1, y1) and (x2, y2) are symmetrical about the center, so given a midpoint, you can directly take (x1, y1, x2, y2) calculate the corresponding anchor
Approximate functional steps:
1. Determine the number of anchors for each position: the number of aspect ratios x the number of side length scaling ratios
2. Get the result of scaling the standard side length of the anchor: base_size x scales
3. Obtain the standard area through the above results: the square of (base_size x scales)
2. Get width and height by h = sqrt(areas / ratio) and w = h * ratio
3. Get the two coordinates (0-h/2 , 0-w/2) and (h/2 , w/2) of each anchor
4. Output anchor
def generate_anchors(base_size=16, ratios=None, scales=None):
"""
Generate anchor (reference) windows by enumerating aspect ratios X
scales w.r.t. a reference window.
"""
if ratios is None:
ratios = np.array([0.5, 1, 2])
if scales is None:
scales = np.array([2 ** 0, 2 ** (1.0 / 3.0), 2 ** (2.0 / 3.0)])
#每个位置的anchor总数 n种规模 * m种比例
num_anchors = len(ratios) * len(scales)
# 初始化anchor的参数 x,y,w,h
anchors = np.zeros((num_anchors, 4))
# scale base_size
#np.tile(scales, (2, len(ratios))).T结果如下:
#[[1. 1. ]
# [1.25992105 1.25992105]
# [1.58740105 1.58740105]
# [1. 1. ]
# [1.25992105 1.25992105]
# [1.58740105 1.58740105]
# [1. 1. ]
# [1.25992105 1.25992105]
# [1.58740105 1.58740105]]
# shape (9, 2)
#设置anchor的w、h的基础大小(1:1)
anchors[:, 2:] = base_size * np.tile(scales, (2, len(ratios))).T
# 计算anchor的基础面积
#[area1,area2,area3,area1,area2,area3,area1,area2,area3]
areas = anchors[:, 2] * anchors[:, 3]
# correct for ratios
#利用面积和宽高比得到真正的宽和高
#根据公式1: areas / (w/h) = areas / ratio = hxh => h = sqrt(areas / ratio)
# 公式2:w = h * ratio
#np.repeat(ratios, len(scales))) = [0.5,0.5,0.5 ,1,1,1,2,2,2]
# 最终的效果就是 面积1的高宽,面积2的高宽,面积3的高宽
anchors[:, 2] = np.sqrt(areas / np.repeat(ratios, len(scales)))
anchors[:, 3] = anchors[:, 2] * np.repeat(ratios, len(scales))
# 转换anchor的形式 (x_ctr, y_ctr, w, h) -> (x1, y1, x2, y2)
# 左上角为中心点,形成9个anchor
anchors[:, 0::2] -= np.tile(anchors[:, 2] * 0.5, (2, 1)).T
anchors[:, 1::2] -= np.tile(anchors[:, 3] * 0.5, (2, 1)).T
return anchorsThe demonstration steps and effects are as follows:
pyramid_levels = [3, 4, 5, 6, 7]
strides = [2 ** x for x in pyramid_levels]
sizes = [2 ** (x + 2) for x in pyramid_levels]
ratios = np.array([0.5, 1, 2])
scales = np.array([2 ** 0, 2 ** (1.0 / 3.0), 2 ** (2.0 / 3.0)])num_anchors = len(ratios) * len(scales)
anchors = np.zeros((num_anchors, 4))anchors[:, 2:] = 16 * np.tile(scales, (2, len(ratios))).T
print("anchor的w、h的基础大小(1:1): ")
print(anchors[:, 2:])
areas = anchors[:, 2] * anchors[:, 3]
print("基础面积:" )
print(areas)
anchors[:, 2] = np.sqrt(areas / np.repeat(ratios, len(scales)))
anchors[:, 3] = anchors[:, 2] * np.repeat(ratios, len(scales))
print("宽度:")
print(anchors[:, 2])
print("高度:")
print(anchors[:, 3])
anchors[:, 0::2] -= np.tile(anchors[:, 2] * 0.5, (2, 1)).T
anchors[:, 1::2] -= np.tile(anchors[:, 3] * 0.5, (2, 1)).T
print("一个位置生成的anchor如下")
print("个数为:",anchors.shape[0] )
print(anchors)
2. Generate anchor for each position
The basic idea is still: the generation of the anchor is based on the original image
To realize the above idea, the most important thing is to get the scaling ratio (step size) between the feature map and the original image, such as stride=8, then if the size of the original image is (image_w, image_h) then the feature map will be reduced relative to the size of the original image It is (image_w/8, image_h/8) (the calculation result is upsampled)
Then the position of each anchor is determined by the feature map
x1∈( 0,1,2,3......image_w/8) y1∈( 0,1,2,3......image_h/8)
The position where the anchor is generated is c_x1 = x1+0.5, c_y1 = y1+0.5
Because the generation of the anchor is based on the original image, the position of the anchor in the feature map must be enlarged to the original image, that is, the position of the anchor generated on the original image is c_x = c_x1 * stride, c_y = c_y1 * stride
def shift(shape, stride, anchors):
shift_x = (np.arange(0, shape[1]) + 0.5) * stride
shift_y = (np.arange(0, shape[0]) + 0.5) * stride
shift_x, shift_y = np.meshgrid(shift_x, shift_y)
shifts = np.vstack((
shift_x.ravel(), shift_y.ravel(),
shift_x.ravel(), shift_y.ravel()
)).transpose()
# add A anchors (1, A, 4) to
# cell K shifts (K, 1, 4) to get
# shift anchors (K, A, 4)
# reshape to (K*A, 4) shifted anchors
A = anchors.shape[0]
K = shifts.shape[0]
all_anchors = (anchors.reshape((1, A, 4)) + shifts.reshape((1, K, 4)).transpose((1, 0, 2)))
all_anchors = all_anchors.reshape((K * A, 4))
return all_anchorsAt the code level (anchors.reshape((1, A, 4)) + shifts.reshape((1, K, 4)).transpose((1, 0, 2)))
Broadcast mechanism using vector addition
The dimension of vector a1 is (k, 1, 4), which means that there are K positions, each position has 1 piece of data, and each piece of data has 4 parameters (center point)
The dimension of the vector a2 is (1, A, 4), which means 1 position, each position has A data, and each data has 4 parameters (position coordinates of the anchor relative to the center point)
Where k is to generate anchors at k positions of the image, and A is to generate several anchors for each position
First, a2 needs to copy the (A,4) vector k times in the 0th dimension (for each position)
Then a1 is copied A times (4) down in the first dimension (for each anchor copy at each position)
3. The image anchor generation process
The final output shape is [1, the sum of the number of anchors in each layer, 4]
class Anchors(nn.Module):
def __init__(self, pyramid_levels=None, strides=None, sizes=None, ratios=None, scales=None):
super(Anchors, self).__init__()
#提取的特征
if pyramid_levels is None:
self.pyramid_levels = [3, 4, 5, 6, 7]
#步长,在每层中,一个像素等于原始图像中几个像素
if strides is None:
self.strides = [2 ** x for x in self.pyramid_levels] #这个参数设置我没看懂
#每层框子的基本边长
if sizes is None:
self.sizes = [2 ** (x + 2) for x in self.pyramid_levels] #这个参数设置我也没看懂
#长宽比例
if ratios is None:
self.ratios = np.array([0.5, 1, 2])
#边长缩放比例
if scales is None:
self.scales = np.array([2 ** 0, 2 ** (1.0 / 3.0), 2 ** (2.0 / 3.0)])
def forward(self, image):
#image是原图 shape为 batch,channel,w,h
#这一步是获得宽和高
image_shape = image.shape[2:]
image_shape = np.array(image_shape)
#‘//’是向下取整 整个式子相当于向上取整,因为不满1步的也要算1步
#图像大小除以步长
#在对应的每一层中,原图在该层对应的大小
image_shapes = [(image_shape + 2 ** x - 1) // (2 ** x) for x in self.pyramid_levels]
# 创建x1,y1 x2,y2 anchor的位置坐标
all_anchors = np.zeros((0, 4)).astype(np.float32)
for idx, p in enumerate(self.pyramid_levels):
#传入该层anchor的基本边长,生成对应大小的anchor
anchors = generate_anchors(base_size=self.sizes[idx], ratios=self.ratios, scales=self.scales)
# 传入生成的anchor,和该层相对于原图的大小
shifted_anchors = shift(image_shapes[idx], self.strides[idx], anchors)
# 循环遍历完成之后,all_anchors的shape为 [每层anchor数量之和, 4]
all_anchors = np.append(all_anchors, shifted_anchors, axis=0)
# 最后输出的形状是 [1, 每层anchor数量之和 , 4]
all_anchors = np.expand_dims(all_anchors, axis=0)
if torch.cuda.is_available():
return torch.from_numpy(all_anchors.astype(np.float32)).cuda()
else:
return torch.from_numpy(all_anchors.astype(np.float32))7.dataset
Take csvdataset as an example

