Original title: Focal Loss for Dense Object Detection
Overview
There are two main target detection frame, a detector (one-stage) and two detectors (two-stage), a detector, a simple structure, high speed, but the rate is far less accurate two level detector. The authors found that the main reason for the foreground and background of these two categories there is a big imbalance in the number of samples. The authors propose a solution to this imbalance, improved cross-entropy loss, making it easy to produce inhibition of sample classification that focus on a smaller number of sample loss is difficult to classify. Meanwhile, the author made famous RetinaNet, this network is not only fast speed and low accuracy better than two detectors, is a good target detection network.
focal loss
In general, if a sample classification, this classification is easy to sample, for example, the probability of 98%, corresponding in terms of its losses will be small. But there is a situation, if a major imbalance present in the sample, the number of samples easy classification of accounts for a large proportion, then it generates losses will account for most, it will make difficult the classification of the sample accounted for losses A minor proportion, making the model difficult training.
Authors thus propose a focal loss, to solve the problem of sample imbalance.
$$
FL (P_T) = - (. 1-P_T) ^ rlog (P_T)
$$
RetinaNet network structure
retinaNet is a simple and consistent network, it has a backbone network (backbone) and two sub-networks with specific tasks. Backbone network used to extract features, there are a lot of ready-made, can be directly used. The first sub-network to perform the classification task, the second word network to perform review tasks.
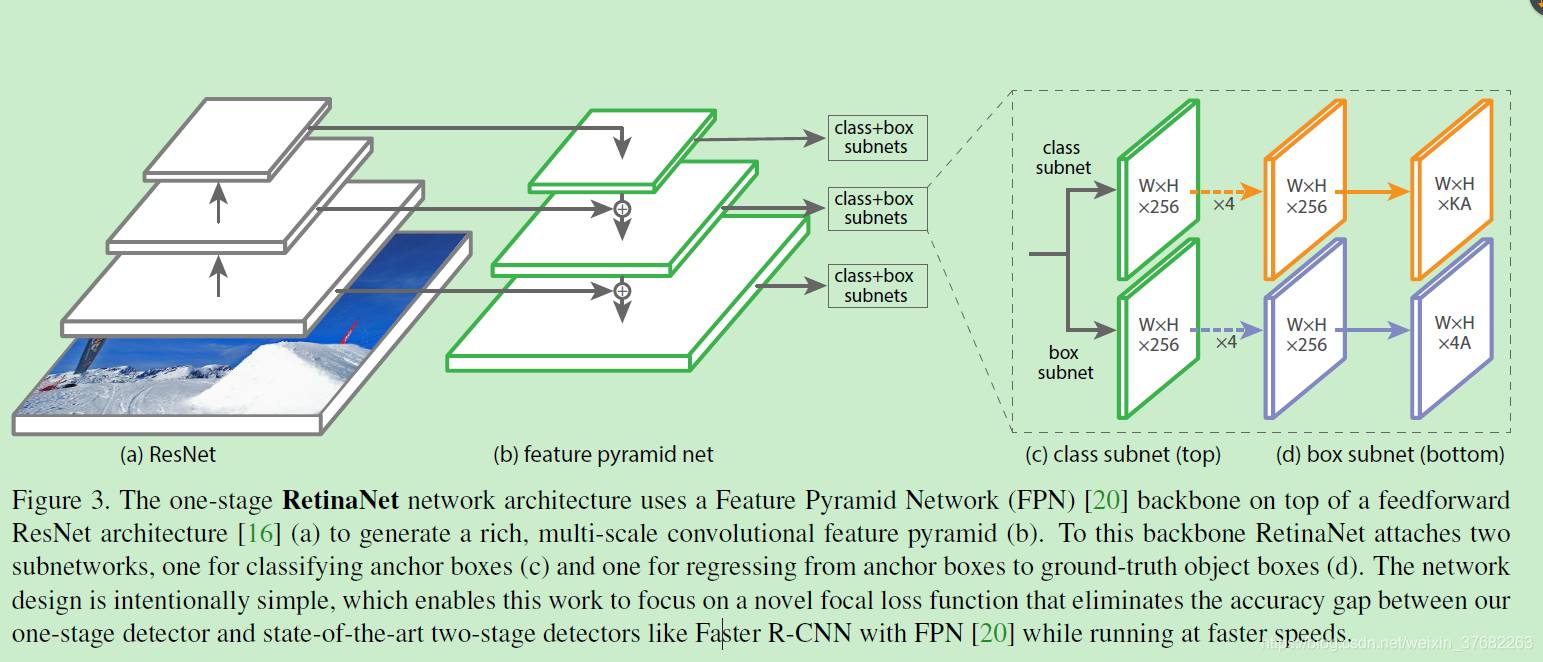
1.backbone
Using the characteristics of the pyramid (the FPN) as a backbone, it can extract the features of the different scales. Each layer of the pyramid can be used to detect objects, features may detect large objects small, small objects can be detected big feature.
The FPN resnet based on the configuration of the pyramid from the P3 to P7, ($ $ P_L smaller than the size of the input image $ 2 ^ l $ times). All layers of the pyramid, there are 256 channels.
2.Anchors
- Use Anchors with a translationally invariant properties. They range in size from $ 32 to $ 512 $ ^ 2 ^ 2 $, corresponding to P3 to P7. Anchors using 3 aspect ratio, {1: 2,1: 1,2: 1}, using three size ratio $ 2 ^ {0,2} ^ {1/3, 2/3} 2 ^ {} $. such an arrangement can improve the AP. Each anchor position number A = 3X3 = 9.
- Anchor are each assigned to a length of one-hot encoding K, K is the number of categories, including background class. And assigning a vector of length, size and positioning of the representative Frames 4.
Set the foreground block is greater than 0.5 IoU, the background frame is IoU less than 0.4, the other ignored. Anchor each has a one-hot encoding corresponding to category 1, and 0 otherwise.
3. Classification subnetwork
This is a small full convolution neural network, each spatial position will generate a prediction KA, K is the number of categories, A is the number of Anchor (9).
Note: Only one classification sub-network, all layers of the pyramid are the parameters that share a network. The following steps: extracting a characteristic from the pyramid C (256) channel, then there are four sub-network layers convolution, convolution in each layer are used in the convolution kernel followed by a final 3X3 (KA) channel convolution. Floor.4. Return subnetwork
It is also a full convolution neural network, and classification of sub-networks parallel existence, its task is to predict the box and the nearest callout box (true value, if any) regression. It has predicted 4A at each spatial location. Unlike other way, this way for the return of classification, is an independent, unknowable. This uses fewer parameters, but equally effective.
Inference and Training
infer
In order to increase the speed, the threshold value is set to 0.05, up to 1000 before the highest points of the regression prediction block. Finally, all levels of fusion predictor, using a non-maxima suppression threshold value is 0.5.
focal loss
r = 2 when the good effect, focal loss will be used in 100 000 anchors each picture, that is, focal loss is that the 100,000 anchor (after normalization) and losses generated. A parameter has a stable range. These two parameters inversely proportional relationship.
initialization
Except for the last layer of convolution, convolution of all the layers with b = 0, Gaussian weight 0.01. For the last convolution layer, b settings are different, this is to avoid when training begins, unstable phenomenon
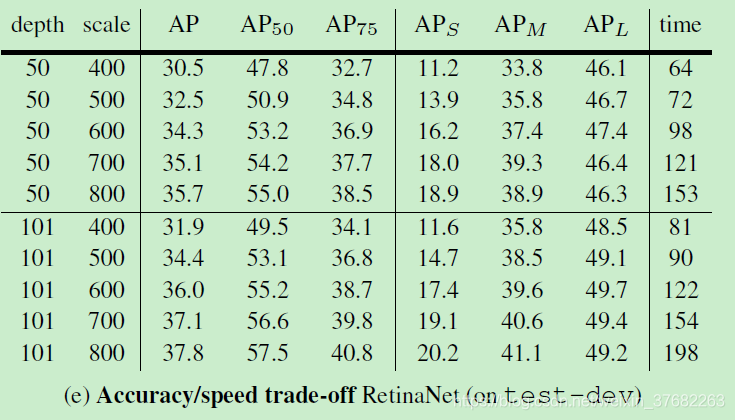
Experimental results