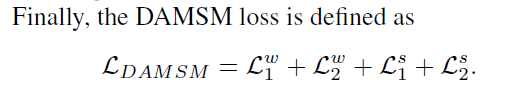AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks 笔记
The task of this article is, "according to the text description" generate an image. It is a conventional common practice to condition vectors encoding the entire sentence, random Gaussian noise samples \ (Z \) by stitching through the convolutional neural network (the GAN, variation from coding etc.) on the samples to generate an image. The problem is found in this article: the entire sentence only by coding to generate images will ignore some of the information fine-grained, and these fine-grained information is determined (such as color, shape, etc.) by the word level.
The solution is to introduce mechanisms attention to the word of the build process, this mechanism requires the attention of the relevant word corresponding to the image area match up, if I let myself go to match the design of this relationship, my first reaction is the first lot of manual annotation (manual box according to the first word out of the area corresponding to the image), then so do we need light marked a huge manpower and time (especially on such a large data set COCO ...).
AttnGAN no additional label data set, using the generated process \ (C \ Times N \ N Times \) Feature Map, there \ (N ^ {2} \ ) positions. Each position is a vector dimension \ (C \) , in order to show a correlation between the position of a word in a sentence, it may be a position vector inner product vector and the word / sentence with a position vector in accordance with all of the words vector inner product of the sum to obtain a weight (related) to the right to a coefficient word, the word characterizing a certain position and may be represented as a weighted vector of all words.

method
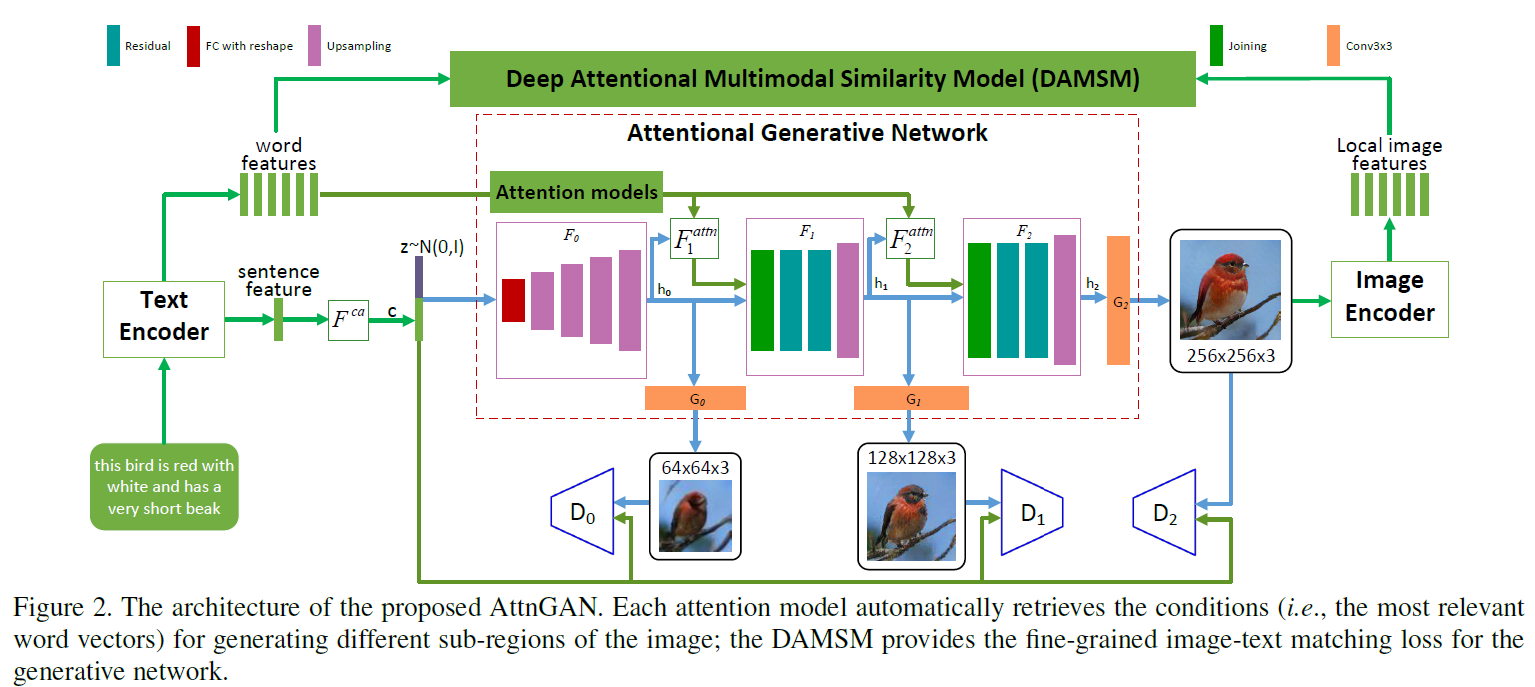
Model comprises two portions,
- Attention generation network
- Attention similar multimodal model (DAMSM, a matching network)
注意力生成网络包含多个阶段的生成(这里是三次生成,只要计算资源足,还可以加), coarse-to-fine的图像生成模式。 DAMSM需要在真实的数据对上预训练,相当于给生成网络加了一个监督信息,使生成的图像能像真实图像那样与相应的文本匹配。
Attentional Generative Network(注意力生成网络)
输入文本,经过Text Encoder(用的是双向LSTM)编码输出“整句特征”(global sentence vector)\(\bar{e}\) 和拼接起来的“单词特征” \(e \in \mathbb{R}^{D \times T}\)。 \(\bar{e}\) 经过 Conditioning Augmentation(具体可以看stackgan和vae的文章,目的是为了降维以及增加多样性) 进行降维转换来作为条件向量,用 \(F^{ca}\) 来表示Conditioning Augmentation操作。
第一次的image features的生成过程为:
\[ h_{0} = F_{0}(z, F^{ca}(\bar{e})) \]
从图中可以看出\(F_{0}\)代表着一系列的上采样操作,但还没有生成最后的图像,输出了一个隐含特征\(h_{0}\)。这个隐含特征已经初具图像的位置和物体信息。后面的生成过程为:
\[ h_{i} = F_{i}(h_{i-1}, F^{attn}_{i}(e,h_{i-1})) \]
这里面最重要的就是\(F_{i}^{attn}\)的操作,也是作者所提出的创新点,即如何将单词信息融入到生成的过程中去,而且不同单词对于图像中不同区域的attention作用也是不同的。先来看看\(F^{attn}_{i}\)的操作,输入是单词向量矩阵 \(e\) 以及前一阶段所得到的image features \(h_{i-1}\)(\(h \in \mathbb{R}^{\hat{D} \times N}\))。单词向量要经过一次乘积转换(可以加个全连接层)来改变维度到\(\hat{D}\)维,\(e^{'}=Ue\) where \(U\in\mathbb{R}^{\hat{D}\times D}\),与image features的维度保持一致, 有助于后面进行内积操作计算相似性。 \(h\) 中的每一列其实都代表着图像的一个sub-region,其中\(N=\sqrt{N}\times \sqrt{N}\)。对于第 \(j\) 个sub-region,用句子中所有的单词向量来进行表示,那么相关的单词向量应具有更大的权重,不相关的单词向量与其的相关权重应很小,每个sub-region进行单词向量加权和的结果称为“word-context”(相当于加入了具有侧重点的文本condition)。每一个sub-region与所有的单词向量权重计算以及最后的word-context计算过程为
\[ c_{j} = \sum\limits_{i=0}\limits^{T-1}\beta_{j,i}e^{'}_{i}, where \beta_{j,i}=\frac{exp(s^{'}_{j,i})}{\sum_{k=0}^{T-1}exp(s^{'}_{j,k})} \]
\(s^{'}_{j,i}=h^{T}_{j}e^{'}_{i}\), \(\beta_{j,i}\)表示当生成图像第\(j\)个子区域时,第\(i\)个单词所获得的关注程度。\(c_{j}\)代表着第\(j\)个子区域的word-context向量,\(F^{attn}\)就是为了生成所有子区域的word-context向量:\(F^{attn}(e,h)=(c_{0},c_{1},\ldots,c_{N-1})\in \mathbb{R}^{\hat{D}\times N}\)。
图像的生成是根据Image features \(h_{i}\)
\[ \hat{x_{i}}=G_{i}(h_{i}) \]
在注意力生成网络里的损失也就是常规的conditionGAN损失的变种(包含带有文本条件与不带有条件):
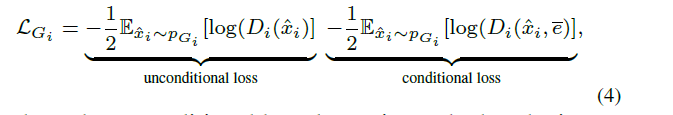
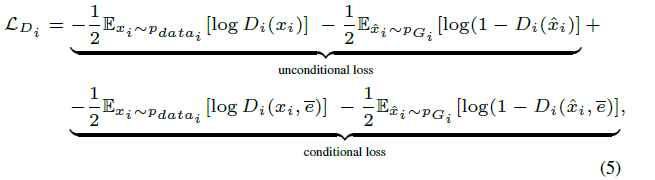
Deep Attentional Multimodal Similarity Model(匹配模型)
这一部分的提出相当于额外加了一个文本-图像匹配的监督信息,由于DAMSM是在真实数据集上预训练好的(即真实图像与相关的文本匹配损失会比较小),在输入生成的图像与相关的文本信息时,它会倒逼着注意力生成网络生成更加真实且与文本相关的图像。在这一模型中,从两个部分来计算匹配损失,分别是基于整个句子的和基于逐个单词的。
图像编码器(image encode)将图像下采样到feature matrix \(f\in \mathbb{R}^{768\times 289}\)(这是从\(768\times 17\times 17\) reshape 过来的),为了度量图像与文本的相似性,文本与图像的特征维度应保持一致,在这里,是将图像的特征进行转换与单词向量的维度保持一致:
\[ v=Wf, \bar{v}=\bar{W}\bar{f} \]
\(v\)是图像特征转换过之后的特征\(v\in \mathbb{R}^{D\times 289}\),\(\bar{v}\in \mathbb{R}^{D}\)表示图像的全局向量,\(\bar{f}\)是从Inception-v3网络的最后一层(全连接分类层)提取出来的,作为全局特征。
经过维度统一之后,下面的单词层面的匹配操作类似于attention生成过程中的word-context计算过程,只不过这里是针对每个单词计算出相应的sub-region的加权和,也就是说每个单词都有个视觉信息的加权表征。计算过程如下:
\[ s=e^{T}v \]
\(s\in \mathbb{R}^{T\times 289}\),表示单词与sub-region的内积来度量相似性。这里搞了一个归一化,说是能提升效果
\[ \bar{s}_{i,j} = \frac{exp(s_{i,j})}{\sum_{k=0}^{T-1}exp(s_{k,j})} \]
也就是针对同一个sub-region,所有单词相似性的归一化。
针对每一个单词所有的sub-region视觉信息加权和称为“region-context”向量,记作\(c_{i}\),计算过程为
\[ c_{i}=\sum_\limits{j=0}^\limits{288}\alpha_{j}v_{j}, where \alpha_{j}=\frac{exp(\gamma_{1}\bar{s}_{i,j})}{\sum_{k=0}^{288}exp(\gamma_{1}\bar{s}_{i,k})} \]
\(\gamma_{1}\)表示对于相关的sub-regions扩大它的影响(相似性值越大的占的比重更大)。这样每一个单词都有一个对应的region-context视觉信息,可以进行单词-视觉信息相关的匹配度量,这里用余弦距离来衡量差异
\[ R(c_{i},e_{i})=(c_{i}^{T}e_{i})/(||c_{i}||||e_{i}||) \]
基于单词层面来衡量整个图像与文本的相似性
\[ R(Q,D)=log\left(\sum_\limits{i=1}^\limits{T-1}exp(\gamma_{2}R(c_{i},e_{i}))\right)^{\frac{1}{\gamma_{2}}} \]
之所以用这个形式,是为了突出最相关的word-to-region-context pair,用\(\gamma_{2}\)来调节突出程度,当\(\gamma_{2} \rightarrow \infty\) 时,上式结果
趋近于\(\max_{i=1}^{T-1}R(c_{i},e_{i})\)。
DAMSM的监督标签是"图片与整个句子是否匹配"。用图片去匹配句子,目标函数的后验概率形式为
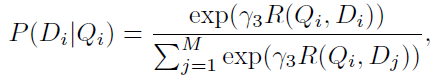
\(Q\)表示图像,\(D\)表示句子
基于单词水平的匹配损失函数为:
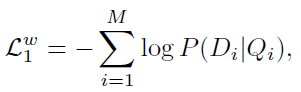
对应的,在以句子匹配图像的情况下,损失函数为
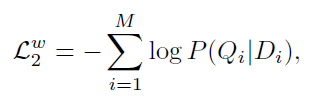
另外,基于整个句子的匹配损失设计与上面的类似,不同点是直接用全局向量计算相似距离。
\[ R(Q,D)=(\bar{v}^{T}\bar{e}/\left(||\bar{v}||||\bar{e}||\right)) \]