Click the card below to follow the " CVer " official account
AI/CV heavy dry goods, delivered in the first time
Click to enter —>【ReID】WeChat Technology Exchange Group
Research overview:
The purpose of the ReID task is to retrieve instances with the same ID as a given query from a large number of images.
Pairwise loss functions play a key role in ReID tasks. Existing methods are based on a dense sampling mechanism, that is, each instance is used as an anchor to sample its positive and negative samples to form a triplet. This mechanism inevitably introduces some positive pairs with little visual similarity, which affects the training effect. In order to solve this problem, we propose a novel loss paradigm called Sparse Pairwise (SP) loss. In the ReID task, a small number of suitable sample pairs are selected for each class of the mini-batch to construct a loss function (as shown in 1). Based on the proposed loss framework, we further propose an adaptive positive mining strategy that can dynamically adapt to changes within different categories. Extensive experiments show that SP loss and its adaptive variant AdaSP loss outperform other pairwise loss methods on multiple ReID datasets and achieve state-of-the-art performance.
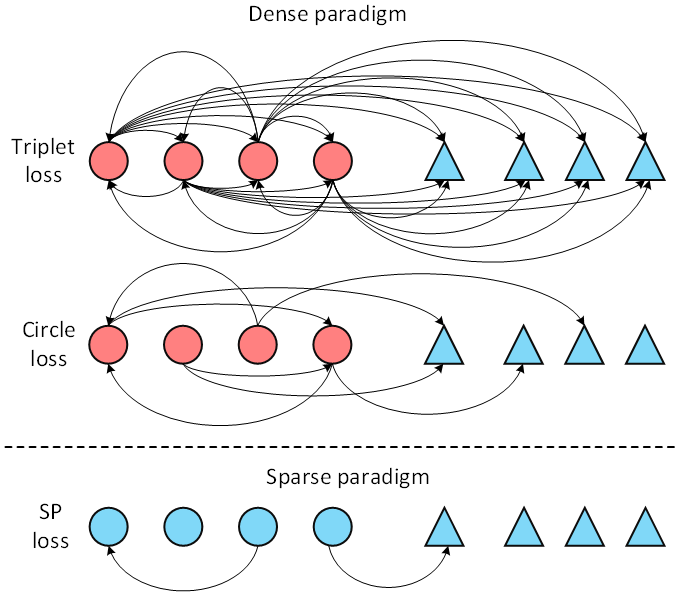
Figure 1. Difference between Sparse pairwise loss and Dense pairwise loss

Adaptive Sparse Pairwise Loss for Object Re-Identification
Paper address: https://arxiv.org/abs/2303.18247
Github address (open source):
https://github.com/Astaxanthin/AdaSP
Research motivation:
In the ReID task, due to illumination changes, viewing angle changes, and occlusions, the visual similarity of different instances in the same class will be very low (as shown in Figure 2), so the instances with low visual similarity (we call them harmful positive pair) will have a negative impact on the learning process of feature representation, so that the training converges to the local minimum point. Existing methods use each sample as an anchor to densely sample positive sample pairs to construct a metric loss function, which will inevitably introduce a large number of bad pairs to affect the training results. Based on this, we propose a sparse pairwise loss function to reduce the sampling probability of bad pairs, thereby alleviating the adverse effects of bad pairs in the training process.

Figure 2. Intra-class differences at different levels on the Pedestrian ReID dataset
Method introduction: Our proposed sparse pairwise loss function (named SP loss) samples only one positive sample pair and one negative sample pair for each class. Among them, the negative sample pair is the most difficult negative sample pair between this category and all other categories, and the positive sample pair is the least difficult positive pair (least-hard mining) in the hard positive pair set of all samples:
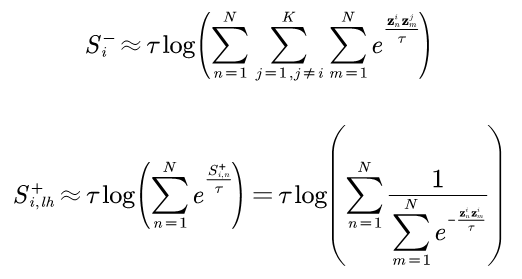
From a geometric point of view, the hypersphere with the distance of the hardest positive pair as the radius is the largest sphere that can cover all the samples in the class, and the hypersphere with the distance of the least difficult positive pair in the hard positive pair set as the radius is the largest ball that can vice versa. The smallest sphere of all in-class samples is shown in Figure 3. Using the smallest ball can effectively avoid the impact of the too difficult harmful positive pair on the training process. We theoretically prove that for a mini-batch, the expected proportion of the positive sample pair sampled by our method is smaller than that of Triplet. - Dense sampling methods like BH and Circle.
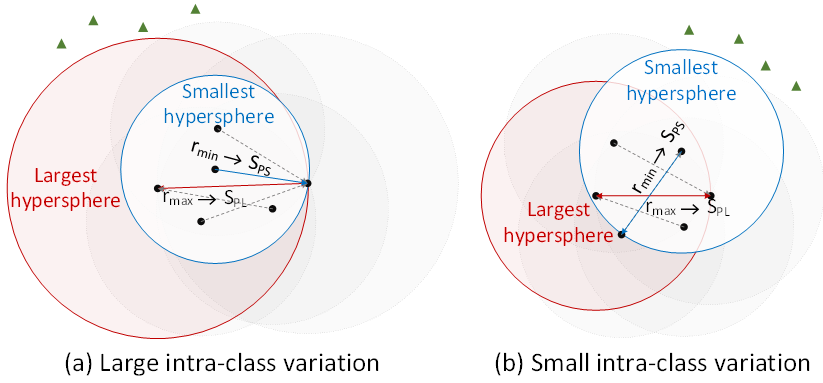
Figure 3. Maximum and minimum covered spheres under different levels of intraclass variance.
In order to adapt to different categories that may have different intra-class differences, we added an adaptive strategy to form AdaSP loss on the basis of SP loss:
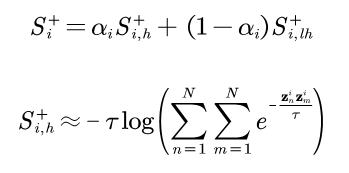

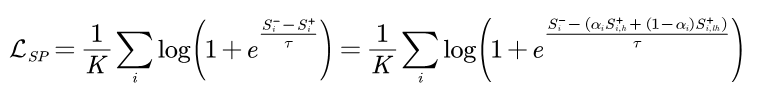
The loss adapts to different intra-class differences by dynamically adjusting the similarity of the positive sample pairs used to construct the loss.
Experimental results:
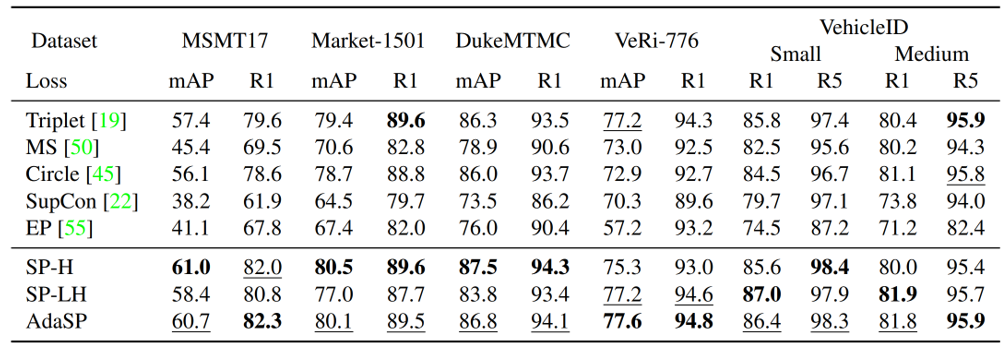
We validate the effectiveness of AdaSP loss on multiple pedestrian ReID datasets (including MSMT17, Market1501, DukeMTMC, CUHK03) and vehicle ReID datasets (including VeRi-776, VehicleID, VERIWild). The experimental results show that AdaSP loss exceeds Triplet-BH, Circle, MS, Supcon, EP and other existing measurement loss functions when used alone, as shown in Table 1; AdaSP loss is used in different backbone networks (including ResNet-50/101/152, The ReID performance on ResNet-IBN, MGN, ViT, DeiT) is better than that of Triplet-BH; in addition, AdaSP loss combined with the classification loss function achieves State-of-the-art performance on the ReID task.
Table 1. Performance comparison of different metric loss functions on different datasets
For details, please refer to the original text.
Click to enter —> [ReID and Transformer] WeChat technology exchange group
The latest CVPP 2023 papers and code download
Background reply: CVPR2023, you can download the collection of CVPR 2023 papers and code open source papers
Background reply: Transformer review, you can download the latest 3 Transformer review PDFs
ReID和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-ReID或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如ReID或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看