Table of contents
1. The difference between derivative, partial differential and gradient:
3. Gradient optimization method:
1. The point of the activation function
2. Commonly used activation functions
* sigmoid derivative (derivative):
* pytorch implementation of sigmoid function
* The derivation process of tanh
* Implementation of tanh in pytorch
3) relu (Rectified Liner Unit, adjusted linear flow unit)
Three, Loss and the gradient of Loss
1, MSE (mean square error): mean square error
* Automatic derivation using pytorch
* Note the difference between w.norm(), w.grad(), w.grad().norm():
* Implementation of softmax in pytorch
1. Gradient
1. The difference between derivative, partial differential and gradient:
1) Derivative: It is a scalar, which is the efficiency of changing in a certain direction
2) Partial differential, partial derivative: a special derivative, which is also a scalar. The direction of the independent variable of the function, the more independent variables of the function, the more partial differential.

3) Gradient, gradient: All the partial differentials are combined into a vector, which is a vector.

The length of the gradient vector represents the rate at which the function changes at the current point.
2. The role of the gradient:
1) The function uses the gradient to find the minimum value of the function
2) How to find the minimum value, through the following formula:

The learning step size is the learning rate.
The independent variable is constantly updated, and when the partial derivative (gradient) approaches 0, the function value also approaches the minimum value.
3) Example:

3. Gradient optimization method:

Different optimization methods have different efficiency and accuracy. Some are fast, and some are more accurate. It is mainly optimized in the following directions:
1) Initialization data (initialization)
Depending on the initial state, the impact on the result may be very different
If it is not clear, use the current mainstream initialization method.
2) Learning rate (learning rate)
If it is too large, the data will not converge, and if it is too small, it will increase the amount of calculation.
3) Momentum (monument)
Give the data an inertia. When the inertia reaches a certain level, it can reduce the situation that the data falls into a local minimum.
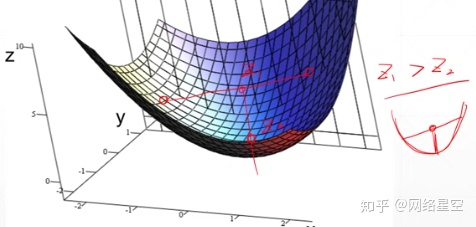
4. Convex function:
Like a bowl, at the midpoint of two points, the average value is greater than the actual value, as shown in the figure below
5. Local minima:

The solution for the case of many local minima:

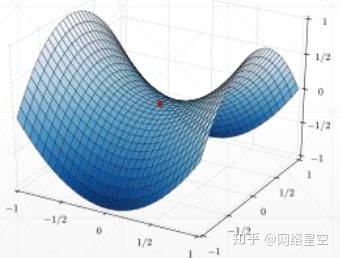
6, saddle point:
A point is a minimum value in one direction and a maximum value in another direction. As shown in the red dot in the figure below:
2. Activation function
1. The point of the activation function
1) Function
When the function value reaches a certain threshold, the activation function sets the function value to a specific value (according to the activation function formula), so as to achieve the purpose of activation

2) The activation functions are not derivable
2. Commonly used activation functions
1)sigmoid
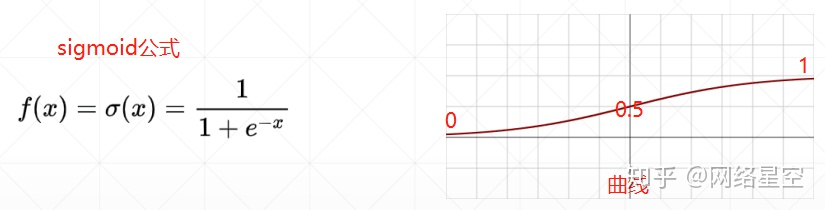
* sigmoid derivative (derivative):

* Uses of sigmoid:
a) Because the value output by sigmoid is between 0 and 1, it is suitable for probability problems; it is also suitable for RGB problems of images, because the RGB value is between 0 and 255
b) Disadvantages of sigmoid: Because the derivative of the sigmoid function approaches 0 when it is at +∞ and -∞, it will make the data update very slowly (when the loss remains unchanged for a long time), that is: the gradient dispersion problem.
* pytorch implementation of sigmoid function

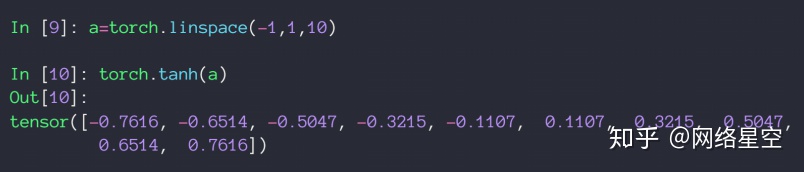
2)tanh

The output value is between [-1, 1]
It is used more in RNN
* The derivation process of tanh
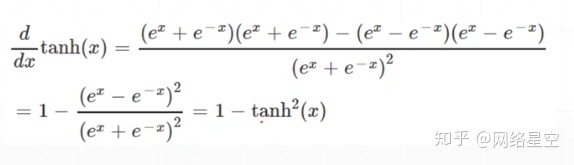
* Implementation of tanh in pytorch
3) relu (Rectified Liner Unit, adjusted linear flow unit)
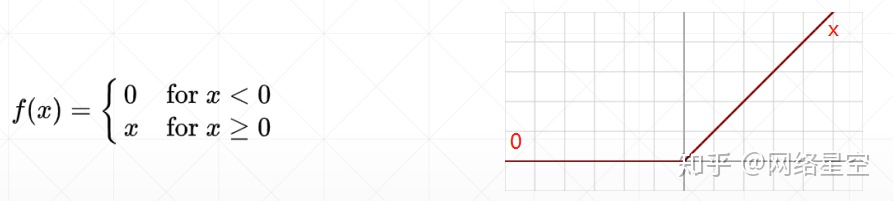
* It has been proved by a large number of experiments that the relu function is very suitable for deep learning.
Because: when z<0, the gradient is 0, and when z>0, the gradient is 1. Because in the backward propagation, because the gradient is 1, it is very convenient to calculate the gradient for searching the optimal solution, and it will not be enlarged and reduced, and it is difficult for gradient dispersion and gradient explosion to occur. So this function is preferred in neural networks.
* Implementation of relu in pytorch

Three, Loss and the gradient of Loss
1, MSE (mean square error): mean square error

The solution method of mse in pytorch: torch.norm().pow(2) #Remember the square
* MSE derivation

* Automatic derivation using pytorch
1) Method 1:
Use torch.autograd.grad()

2) Law 2:
Use mse.backward()

* Note the difference between w.norm(), w.grad(), w.grad().norm():
w.norm() is the square root of the mean square error
w.grad() is the derivative
w.grad().norm() is the square root of the mean square error of the derivative
2、Cross Entropy Loss:

Softmax:
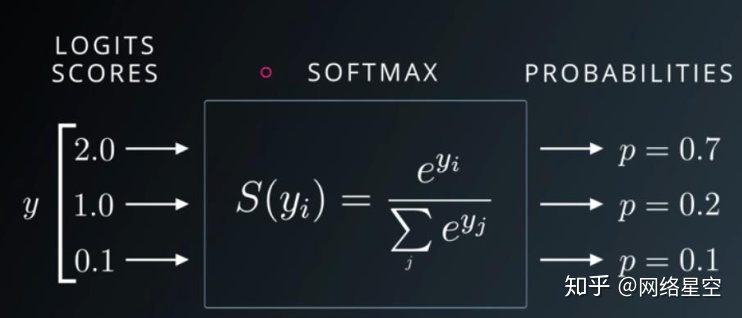
* softmax features:
1) The range of all values output is 0~1
2) The sum of all probabilities equals 1. (Note: sigmoid function, the sum of all probabilities is generally not equal to 1)
Index of the maximum output probability.
3) It will widen the gap between the original values.
* softmax derivation:


1) When i=j

2) When i ≠ j

3) Comprehensive

* Implementation of softmax in pytorch

The last 4 lines in the above figure respectively represent: δp1/δai, δp2/δai (i∈[0, 2]) partial derivative